標題無意冒犯,就是覺得這個廣告挺好玩的
上面這張思維導圖喜歡就拿走,反正我也學不了這么多
文章目錄
- 前言
- 歡迎來到我們的圈子
- 開手練習:爬取網上書店
- 第一步:找到最小公共父標簽
- 第二步:找到單個目標所在標簽
- 第三步:代碼與自動化
- 第四步:填充網址
- 小爬蟲撲空啦
- json串
- Network
- 重要圖示介紹
- 操作流程
- json
- why json?
- how json?
- 小爬蟲又來啦
- 易容術:請求頭Request Headers
- 什么是Request Headers
- 如何添加Request Headers
- 進擊吧!小爬蟲
- 小爬蟲被騙啦
- 帶參請求資料
- 強行灌輸知識點
前言
前期回顧:我要偷偷學Python(第八天)
上一篇呢,上一篇我們了解了一下網頁的基本結構,并且通過對網頁的分析抓取了一點資料出來,
但是我們就這么滿足了嗎?這顯然是不可能的,你見過哪個爬蟲就爬幾個字嘛,
所以今天,我們來一次性爬上一大波資料!!!
我行,你也行!!!

插播一條推送:(如果是小白的話,可以看一下下面這一段)
歡迎來到我們的圈子
我建了一個Python學習答疑群,有興趣的朋友可以了解一下:這是個什么群
群里已經有四百多個小伙伴了哦!!!
直通群的傳送門:傳送門
本系列文默認各位有一定的C或C++基礎,因為我是學了點C++的皮毛之后入手的Python,這里也要感謝齊鋒學長送來的支持,
本系列文默認各位會百度,學習‘模塊’這個模塊的話,還是建議大家有自己的編輯器和編譯器的,上一篇已經給大家做了推薦啦?
我要的不多,點個關注就好啦
然后呢,本系列的目錄嘛,說實話我個人比較傾向于那兩本 Primer Plus,所以就跟著它們的目錄結構吧,
本系列也會著重培養各位的自主動手能力,畢竟我不可能把所有知識點都給你講到,所以自己解決需求的能力就尤為重要,所以我在文中埋得坑請不要把它們看成坑,那是我留給你們的鍛煉機會,請各顯神通,自行解決,
哎,怪我孤陋寡聞,實在找不到適合我們這個階段的網站,我的爬蟲又不斷地讓人捏死,只好借鑒別人的栗子了,,,
開手練習:爬取網上書店
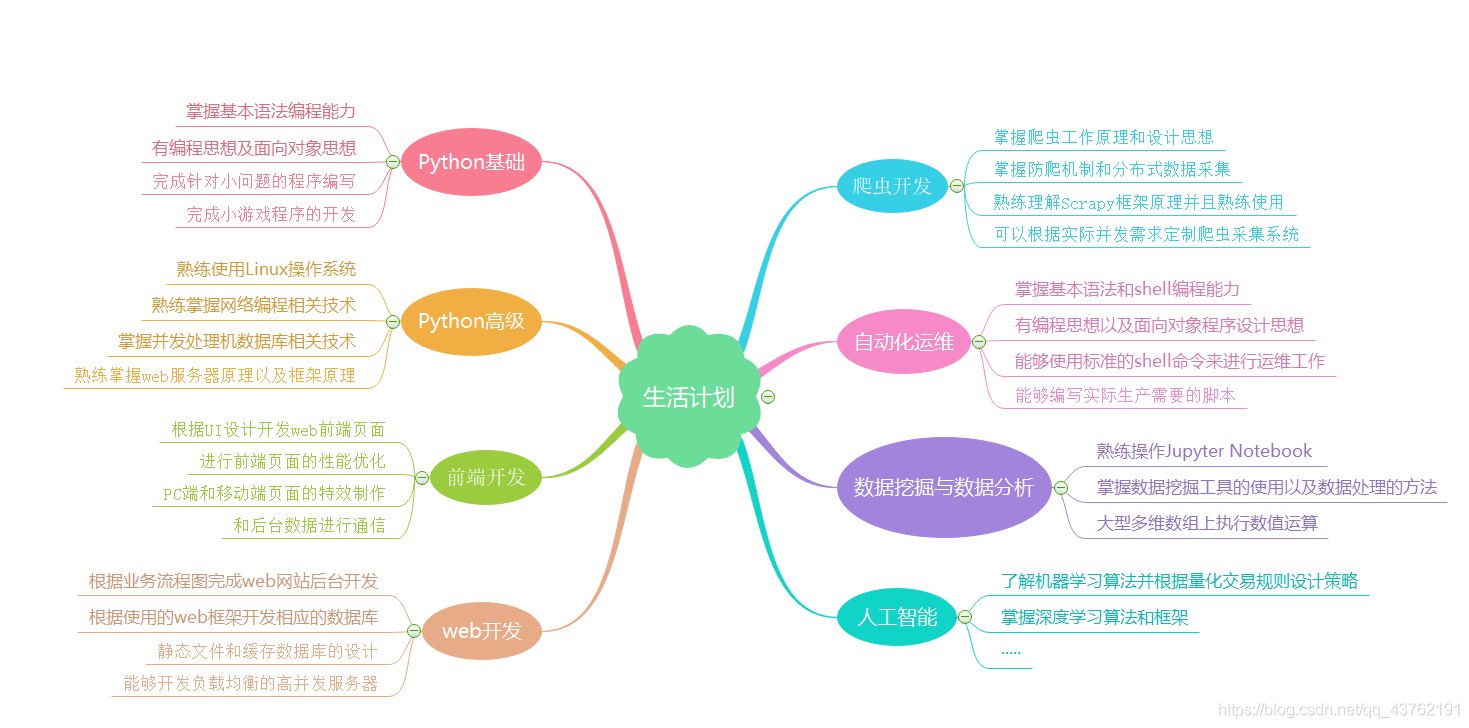
目標網址:http://books.toscrape.com/
任務:爬取目標網址中的分類目錄:
干!
有沒有思路?沒思路看我講,
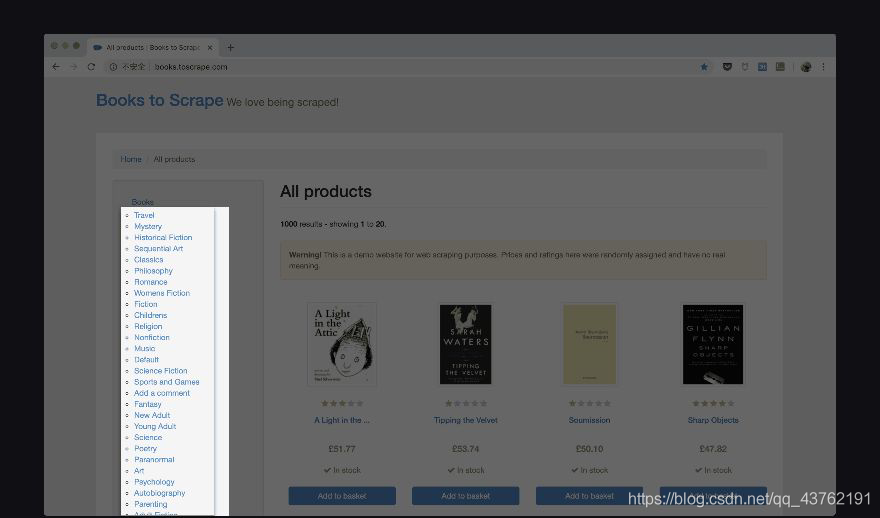
第一步:找到最小公共父標簽
這個會找吧:
第一步,點亮匹配按鈕(以后我就叫它匹配按鈕了)
第二步,把滑鼠放到要選的區域,注意,要顏色完全覆寫住你要選的區域,覆寫不住調整滑鼠位置,
第三步,左擊滑鼠,定位代碼,
第四步,再看一眼那行標簽是不是最小且公共的了,有虛線,可以看到那行標簽管到哪一層,
其實你再認真找一下,就會發現我們上面圖中標出的區域并不是最小的,最小的是那個< ul >,
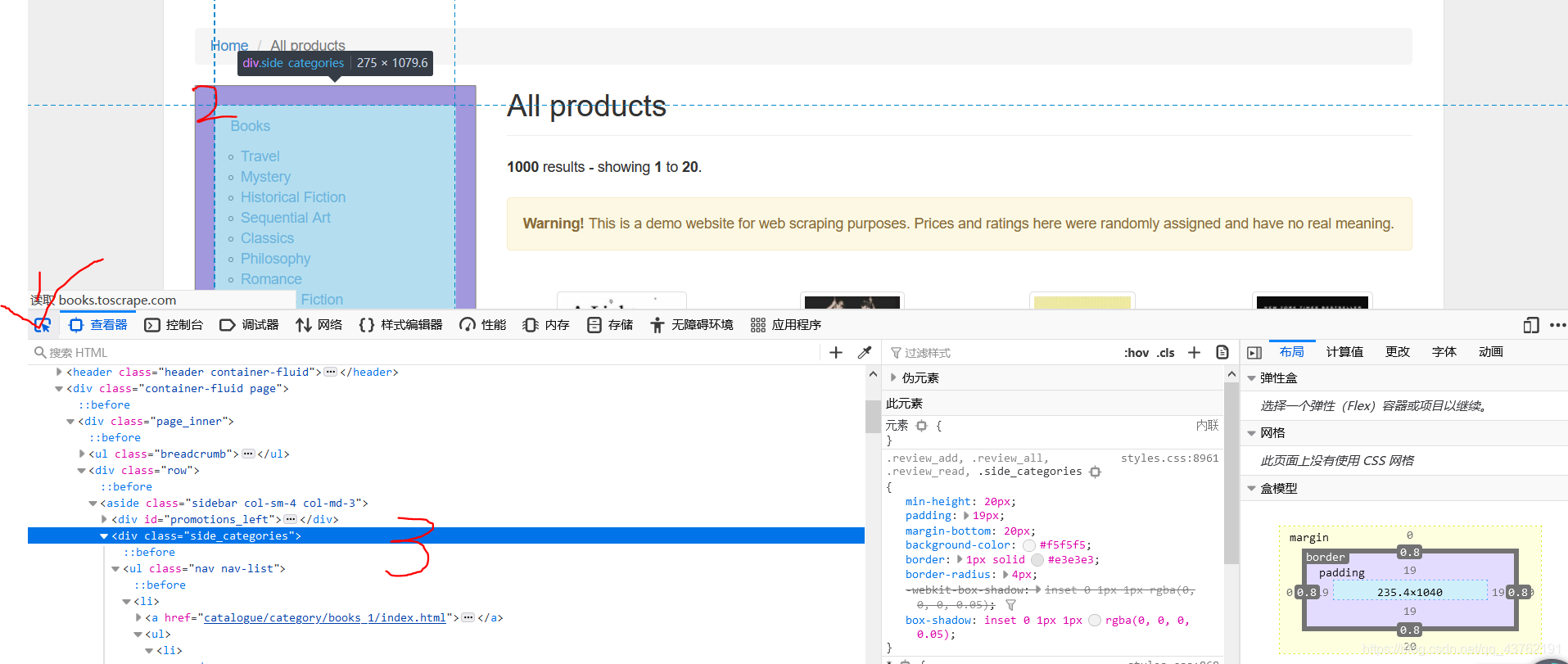
第二步:找到單個目標所在標簽
第二步怎么走啊?第一步可以理解吧,第一步做完事要為“find_all”服務的,一籃子全撈出來,那第二步自然是要一個一個揀出來嘛,為“find”服務,
那具體怎么做就不用我再說了吧,參照上一步,
來我帶你打開一個標簽看一下:
看到沒,層次分明,
第三步:代碼與自動化
第三步自然就要把目標值取出來了嘛,我們順便把網址也取了吧,
import requests
from bs4 import BeautifulSoup
res = requests.get('http://books.toscrape.com/')
soup = BeautifulSoup(res.text,'html.parser')
items = soup.find('ul',class_ = 'nav nav-list').find('ul').find_all('li') #我驚奇的發現,還有這種騷操作
for item in items:
kind = item.find('a')
print('分類'+kind.text.strip()+'\n網址'+kind['href']+'\n')
這樣打出來你會發現那根本不是一個完整的網址,這要怎么辦呢?
第四步:填充網址
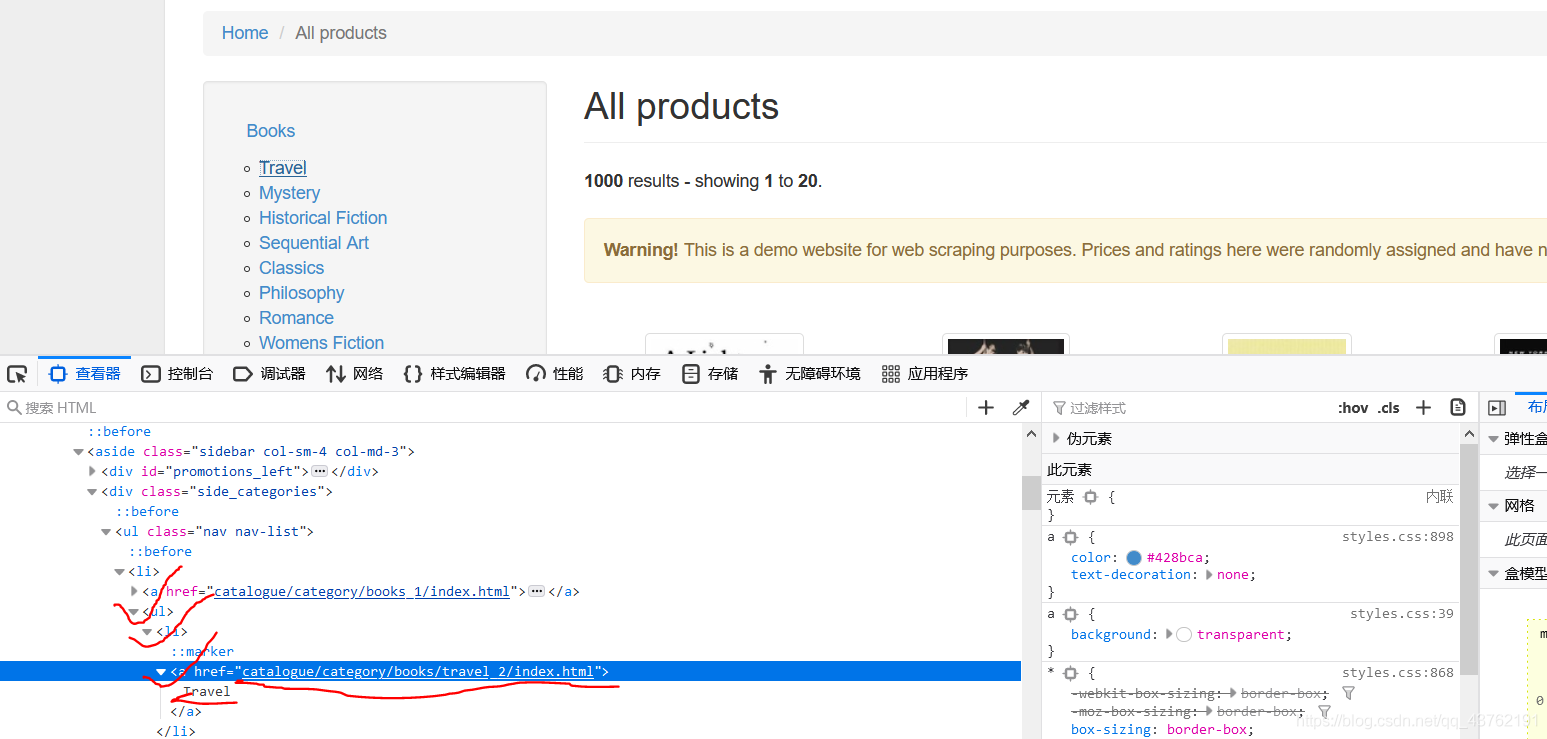
其實你打開一個目錄,就會發現它的網址長這樣:(這里我打開的是第一個目錄)
http://books.toscrape.com/catalogue/category/books/travel_2/index.html
這有什么特點呢?咱把它分開:
http://books.toscrape.com/
catalogue/category/books/travel_2/index.html
好,現在再問你看到了什么?
這兩部分是不是都能找到出處!!
好,現在我們微調一下上面的代碼:
import requests
from bs4 import BeautifulSoup
url = 'http://books.toscrape.com/'
res = requests.get(url)
soup = BeautifulSoup(res.text,'html.parser')
items = soup.find('ul',class_ = 'nav nav-list').find('ul').find_all('li') #我驚奇的發現,還有這種騷操作
for item in items:
kind = item.find('a')
print('分類:'+kind.text.strip()+'\n網址:'+url+kind['href']+'\n')
第一題到此告一段落、
小爬蟲撲空啦
學完這些之后,我就想著去爬我的CSDN評論了,不過一頓操作下來:
目標網址:https://lion-wu.blog.csdn.net/article/details/108858689
標題:MySQL見聞錄 – 入門之旅
目標:評論區
gogogo!!!
好,定位代碼段:
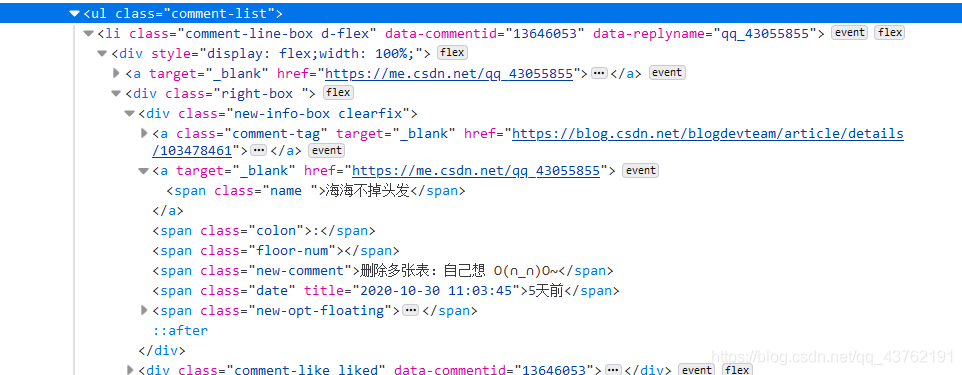
好,層層爬取(演示效果,不然我才不一層一層撥開):
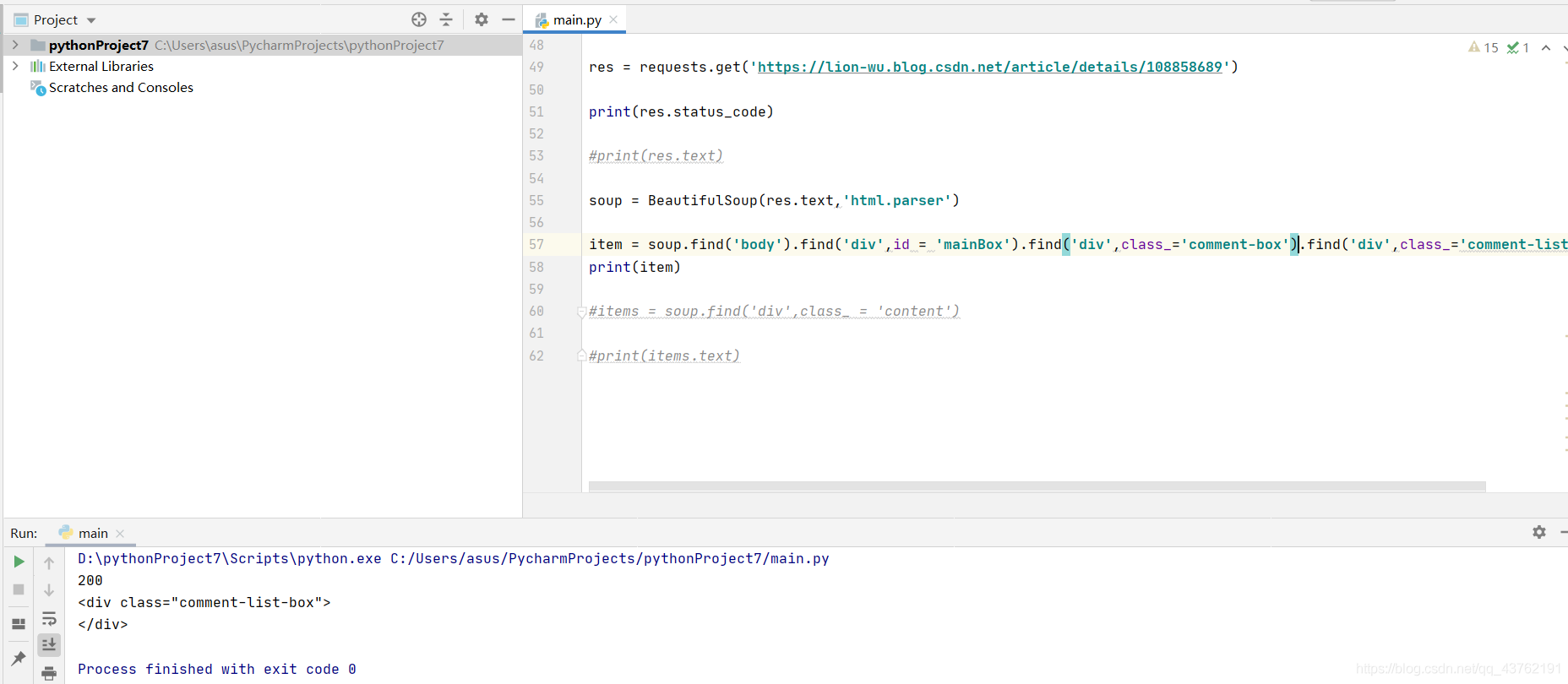
好,結果顯示為空,
可以去列印出爬下來的網頁源代碼:res,然后翻一翻,你會驚奇的發現,評論部分被隱藏了!!!
那怎么辦呢?接下來那就進入我們今天的第一個知識點了–json串,
json串
依舊是別人的栗子,我來講給大家懂,
網頁源代碼里沒有我們想要的資料,那它究竟藏到了哪里呢?
想找到答案,需要用到一項新技能——翻找Network!
還記得我一開始就叫大家用谷歌瀏覽器嗎?現在就體現出優勢了,
Network
首先,打開一個界面,這里我選擇了志炫的歌單,我比較喜歡他的歌,
小白請跟我來,因為你并不知道哪些網頁是用json 傳輸什么資料的,所以練習的時候不要自己亂找網頁,
https://y.qq.com/portal/search.html#page=1&searchid=1&remoteplace=txt.yqq.top&t=song&w=%E6%9E%97%E5%BF%97%E7%82%AB
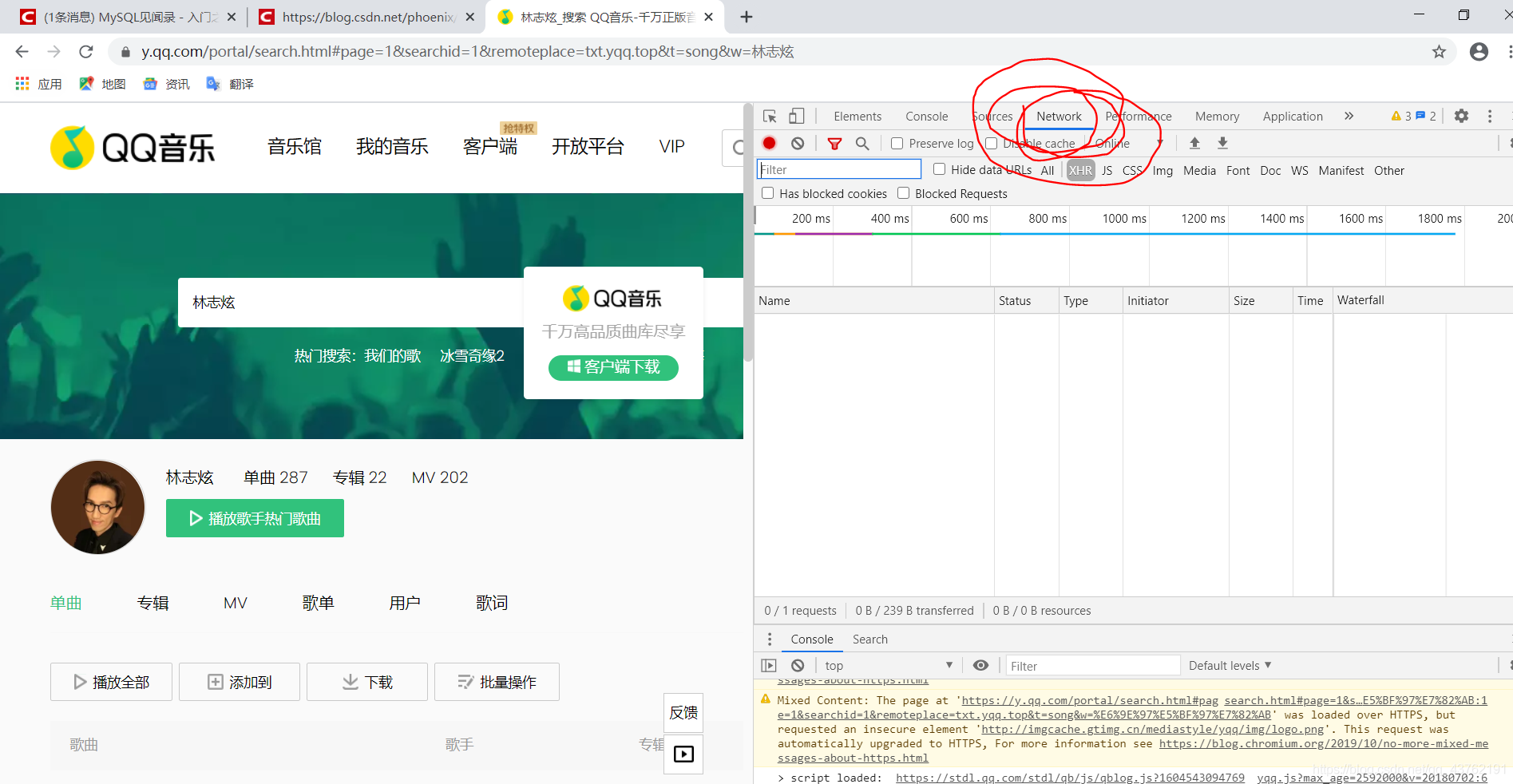
這個界面應該會打開吧,怕大家看不到,我特地多圈了幾圈,兄弟們,點它、
好,然而并沒有發生什么,
那不急,我們重新加載一下這個歌單界面,找到空白處,右擊,重新加載,
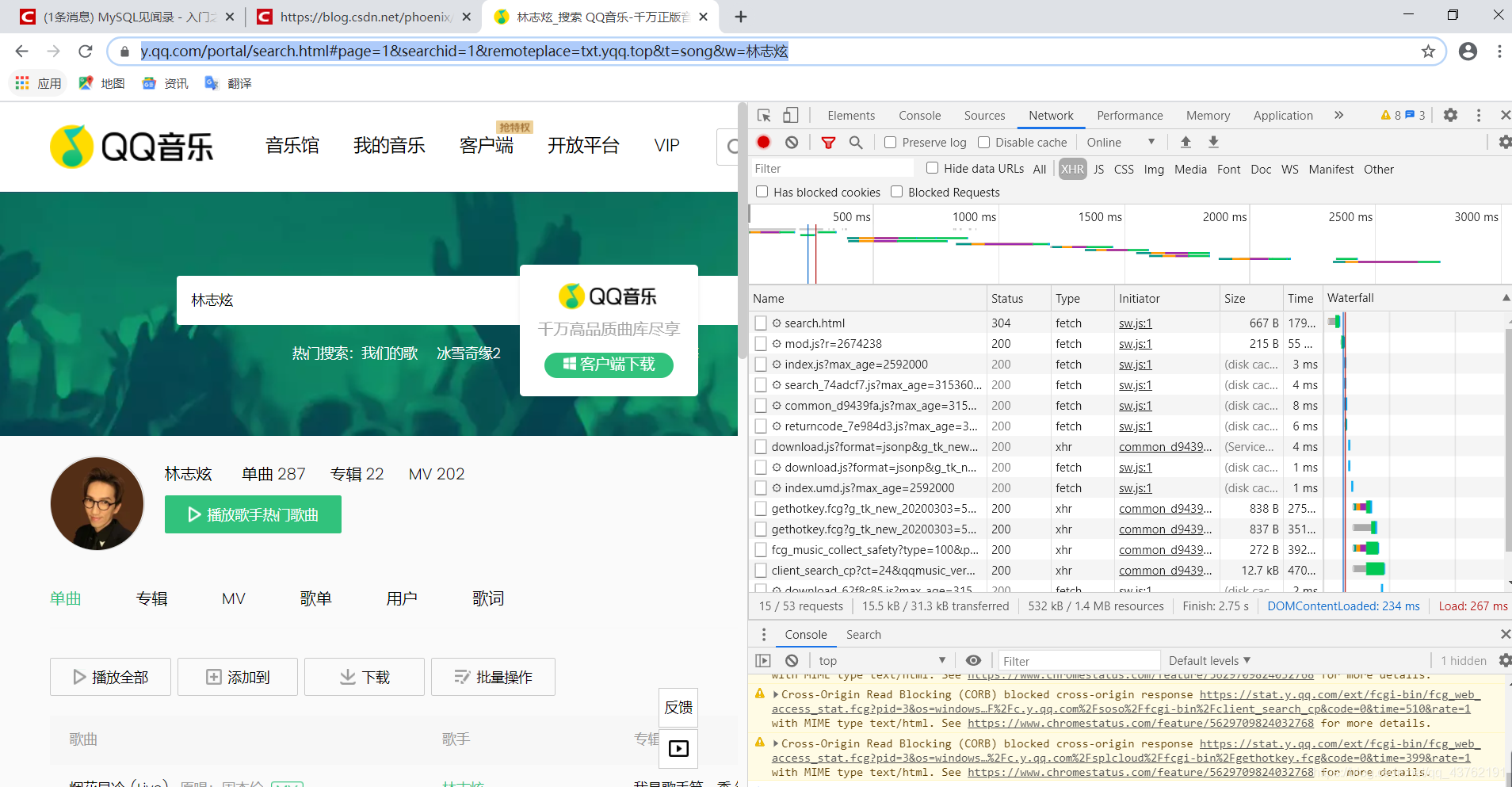
這時候你會看到這么一個界面,
你用別的瀏覽器試試,會是什么效果,我用火狐試過,找是可以找,一片亂碼而已,
Network的功能是:記錄在當前頁面上發生的所有請求,現在看上去好像空空如也的樣子,這是因為Network記錄的是實時網路請求,現在網頁都已經加載完成,所以不會有東西,
我們點擊一下重繪,瀏覽器會重新訪問網路,這樣就會有記錄,
好,走到這里了,我覺得我有必要介紹一下這個頁面上幾個比較重要的東西,
重要圖示介紹
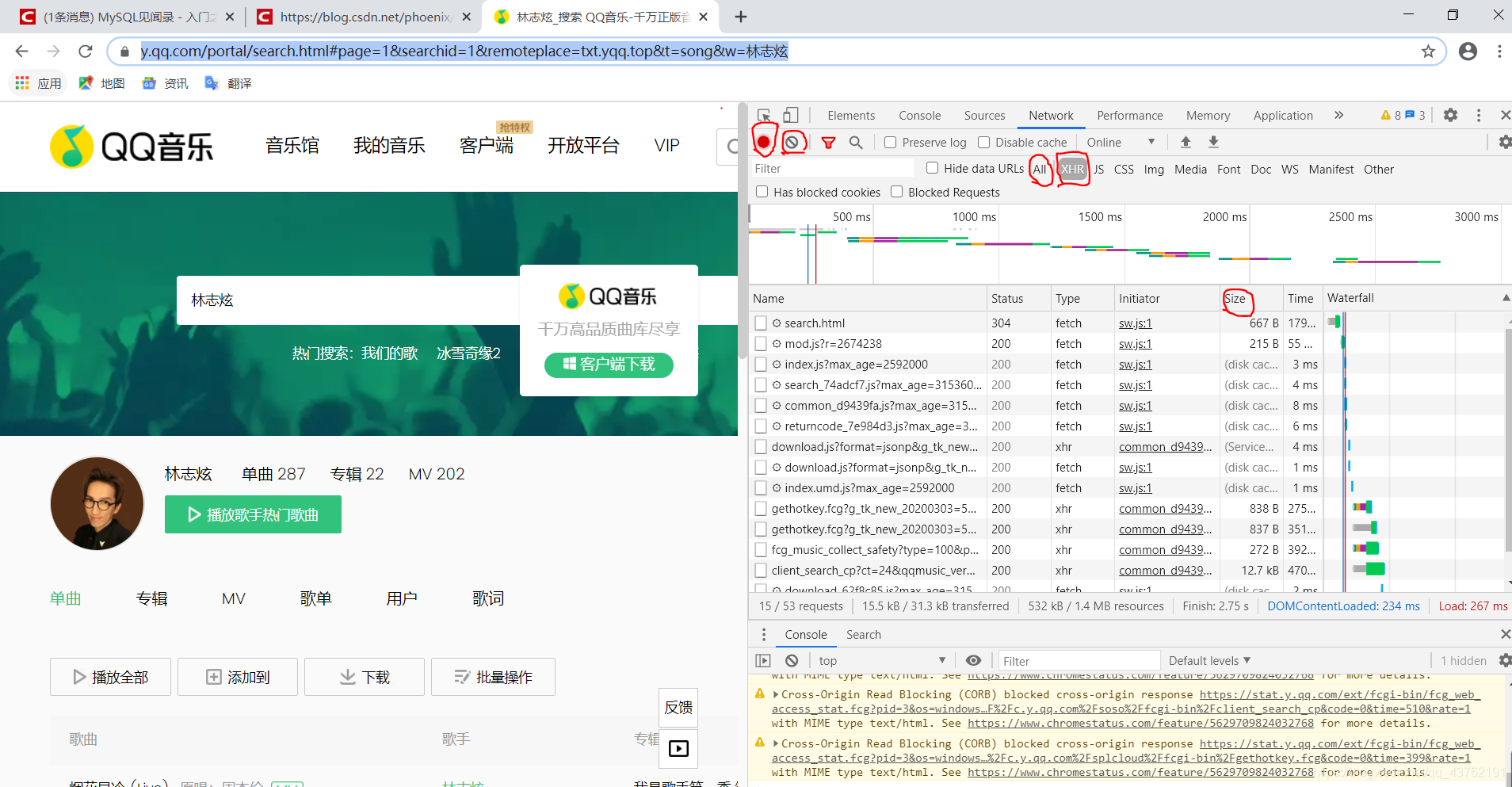
從左往右看啊,紅色的圓鈕是啟用Network監控(默認高亮打開),灰色圓圈是清空面板上的資訊,右側勾選框Preserve log(放大鏡旁邊那個),它的作用是“保留請求日志”,如果不點擊這個,當發生頁面跳轉的時候,記錄就會被清空,所以,我們在爬取一些會發生跳轉的網頁時,會點亮它,
再往右是對請求進行分類查看,我們最常用的是:ALL(查看全部)/XHR(僅查看XHR)
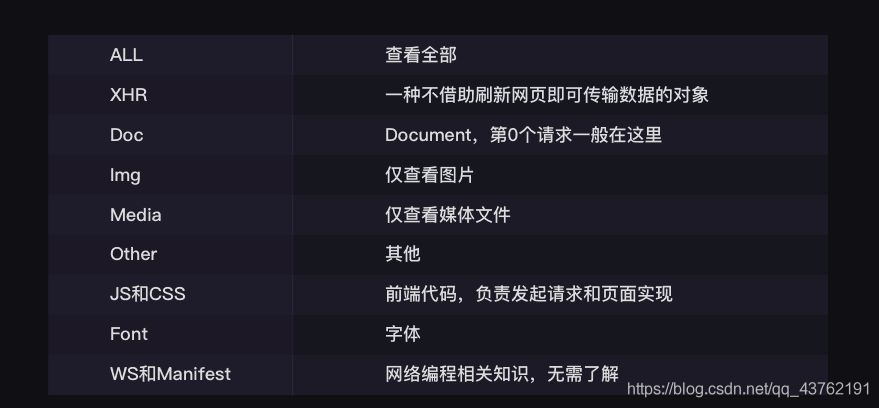
哎,不廢話了,上操作流程吧,
操作流程
首先,我們要找的東西是文本嘛,那怎么辦呢?直接點XHR就好了,
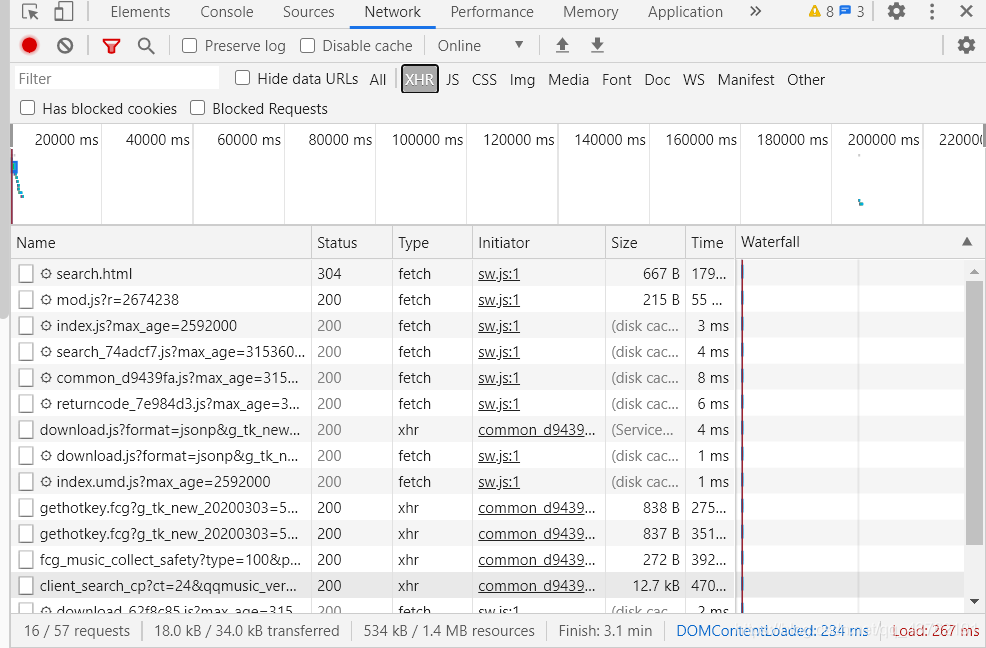
好,現在這么多東西了,我就直接跟你說要的東西就在這里面,你要怎么找?一個一個點開嗎?你會發現很多都是傳一些邊角料,再然后,你會發現那些邊角料都比目標文案要小很多,所以就直接找size最大的那個點進去就好,
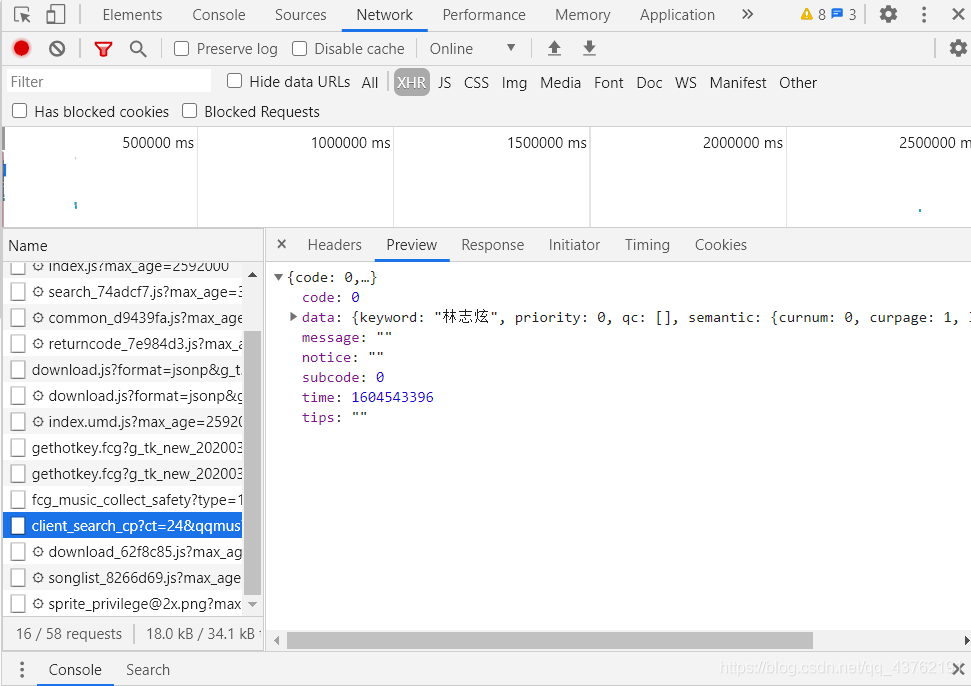
咱也不繞彎子了,進去之后直接點Preview,

好,Preview點進去之后自己玩一玩,看看里面都是些啥,
看完之后,回來,跟我點開旁邊的Headers,
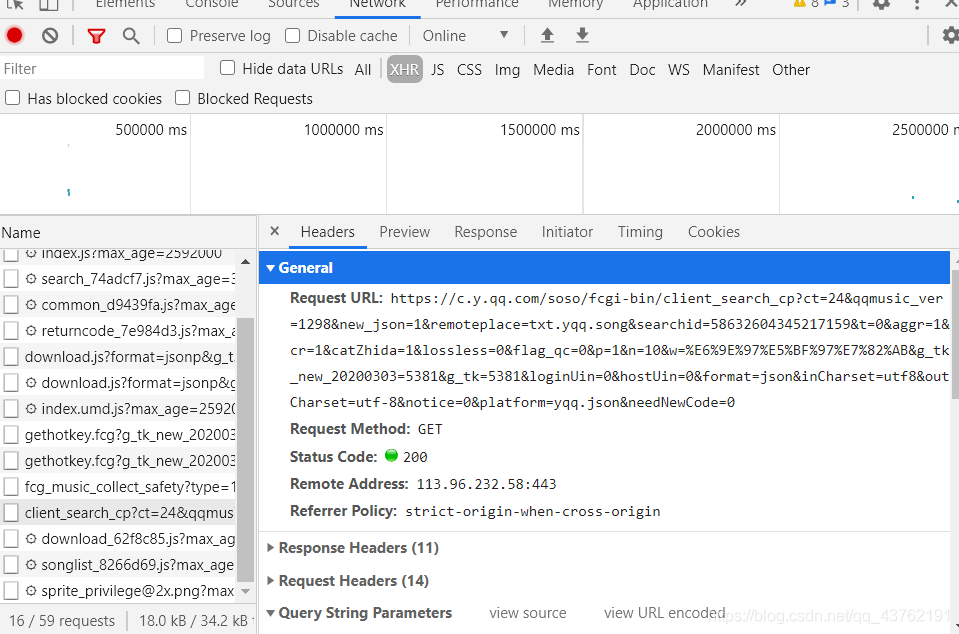
好,看到了什么?一個網址是吧,復制它,打開它,是不是和Preview里面的一模一樣,只是排版亂了些,
我就不貼了啊,密集恐懼癥就別點開了,
這說明什么?這說明我們要爬的網址其實是這個,
注:如果這個網址打不開,那就不用爬了,人家并不想讓你爬,
那么,對于這份XHR來說:這個XHR是一個字典,鍵data對應的值也是一個字典;在該字典里,鍵song對應的值也是一個字典;在該字典里,鍵list對應的值是一個串列;在該串列里,一共有20個元素;每一個元素都是一個字典;在每個字典里,鍵name的值,對應的是歌曲名,
會不會亂?我覺得不會啊,除非你沒有一步一步實操跟進,
講到這里還沒有講到 json串 啊,你先把這個網頁爬出來,列印出來看看,是一個又有點像字典,又有點像字串的玩意兒,
這玩意兒就是json串了,
json
why json?
答案很簡單,因為不是所有的編程語言都能讀懂Python里的資料型別(如,串列/字典),但是所有的編程語言,都支持文本(比如在Python中,用字串這種資料型別來表示文本)這種最樸素的資料型別,
如此,json資料才能實作,跨平臺,跨語言作業,
而json和XHR之間的關系:XHR用于傳輸資料,它能傳輸很多種資料,json是被傳輸的一種資料格式,就是這樣而已,
我們總是可以將json格式的資料,轉換成正常的串列/字典,也可以將串列/字典,轉換成json,
how json?
方法很簡單,請求到資料之后,使用json()方法即可成功讀取,接下來的操作,就和串列/字典相一致,
import requests
# 參考requests庫
res_music = requests.get('https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=67818388354301120&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=%E6%9E%97%E5%BF%97%E7%82%AB&g_tk_new_20200303=5381&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0')
# 呼叫get方法,下載這個字典
json_music = res_music.json()
# 使用json()方法,將response物件,轉為串列/字典
print(json_music)
# 列印json_music的資料型別
所以接下來怎么辦呢?
import requests
# 參考requests庫
res_music = requests.get('https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=67818388354301120&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=%E6%9E%97%E5%BF%97%E7%82%AB&g_tk_new_20200303=5381&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0')
# 呼叫get方法,下載這個字典
json_music = res_music.json()
# 使用json()方法,將response物件,轉為串列/字典
list_music = json_music['data']['song']['list']
# 一層一層地取字典,獲取歌單串列
for music in list_music:
# list_music是一個串列,music是它里面的元素
print(music['name'])
# 以name為鍵,查找歌曲名
print('所屬專輯:'+music['album']['name'])
# 查找專輯名
print('播放時長:'+str(music['interval'])+'秒')
# 查找播放時長
print('播放鏈接:https://y.qq.com/n/yqq/song/'+music['mid']+'.html\n\n')
# 查找播放鏈接
小爬蟲又來啦
這回,通過我們的一頓操作猛如虎,可算是找對了網址啊:
https://blog.csdn.net/phoenix/web/v1/comment/list/108858689?page=1&size=10&commentId=
這是第一頁的評論網址,
好極,我們開始吧,
import requests
res = requests.get('https://blog.csdn.net/phoenix/web/v1/comment/list/108858689?page=1&size=10&commentId=')
# 發起請求,填入請求頭和引數
print(res.status_code)
print(res.text)
好極,就試了下水就讓人給懟回來了,,,
莫非今天還真爬不過去了?
不知道,再說吧,,
易容術:請求頭Request Headers
服務器可能會對我們這些“投機取巧”的爬蟲做限制處理,一來可以降低服務器的訪問壓力,畢竟成千上萬次的訪問對代碼來說就是一個for回圈的事兒;二來可以攔截那些想要通過爬蟲竊取資料的競爭者,
那這就有一個問題,服務器怎么判斷訪問者是一個普通的用戶(通過瀏覽器),還是一個爬蟲者(通過代碼)呢?
這需要我們回到瀏覽器中,重新認識一個新的資訊欄:請求頭Request Headers,
什么是Request Headers
看下面這張圖
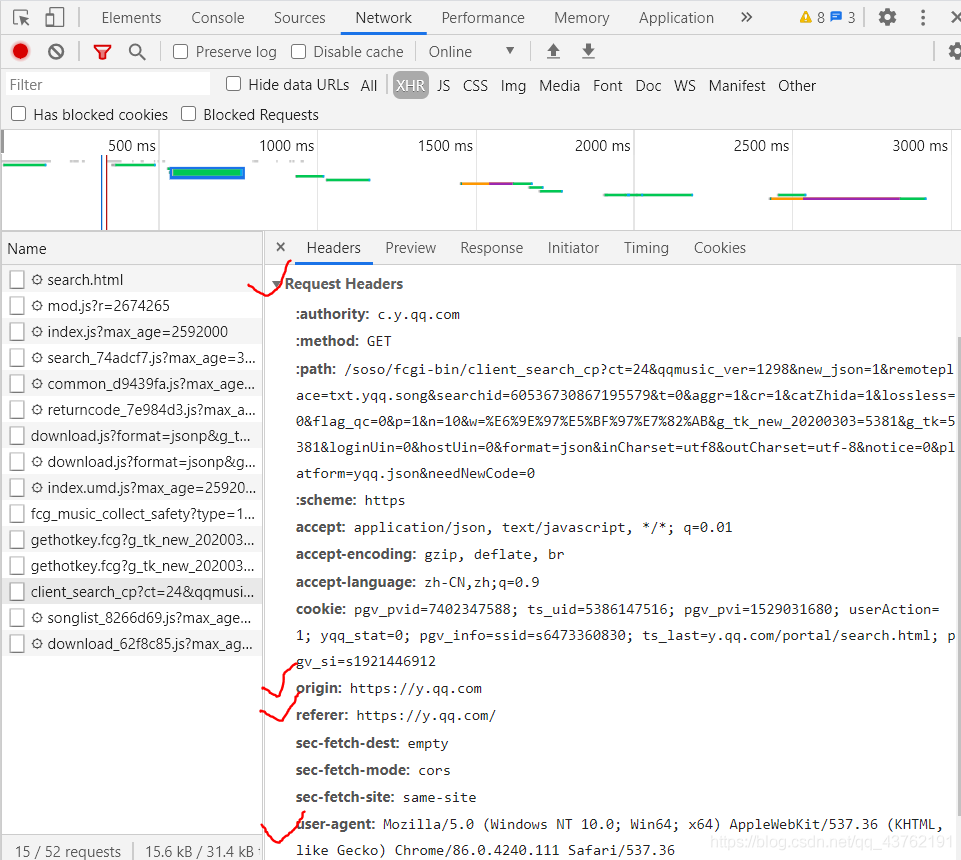
每一個請求,都會有一個Request Headers,我們把它稱作請求頭,它里面會有一些關于該請求的基本資訊,比如:這個請求是從什么設備什么瀏覽器上發出?這個請求是從哪個頁面跳轉而來?
如上圖,user-agent(中文:用戶代理)會記錄你電腦的資訊和瀏覽器版本,如果我們想告知服務器,我們不是爬蟲,而是一個正常的瀏覽器,就要去修改user-agent,倘若不修改,那么這里的默認值就會是Python,會被服務器認出來,
origin(中文:源頭)和referer(中文:參考來源)則記錄了這個請求,最初的起源是來自哪個頁面,它們的區別是referer會比origin攜帶的資訊更多些,
對于爬取某些特定資訊,也要求你注明請求的來源,即origin或referer的內容,
如何添加Request Headers
import requests
url = 'https://blog.csdn.net/phoenix/web/v1/comment/list/108858689?page=1&size=10&commentId='
headers = {
'origin':'https://lion-wu.blog.csdn.net',
# 請求來源,本案例中其實是不需要加這個引數的,只是為了演示
'referer':'https://lion-wu.blog.csdn.net/article/details/108858689',
# 請求來源,攜帶的資訊比“origin”更豐富,本案例中其實是不需要加這個引數的,只是為了演示
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'
# 標記了請求從什么設備,什么瀏覽器上發出
}
# 偽裝請求頭
res = requests.get(url,headers=headers)
好極,干!!!
進擊吧!小爬蟲
這次,我給小爬蟲進行了一波易容,可能是它長得不符合服務器的審美吧,所以次次碰壁,這次易容之后,不知道有沒有長到服務器的審美上去呢?讓我們拭目以待吧!!!
import requests
url = 'https://blog.csdn.net/phoenix/web/v1/comment/list/108858689?page=1&size=10&commentId='
headers = {
'origin':'https://lion-wu.blog.csdn.net',
# 請求來源,本案例中其實是不需要加這個引數的,只是為了演示
'referer':'https://lion-wu.blog.csdn.net/article/details/108858689',
# 請求來源,攜帶的資訊比“origin”更豐富,本案例中其實是不需要加這個引數的,只是為了演示
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'
# 標記了請求從什么設備,什么瀏覽器上發出
}
# 偽裝請求頭
res = requests.get(url,headers=headers)
print(res.status_code)
print(res.text)
bash:129$ python ~/classroom/apps-2-id-5c3d89848939b4000100e7f5/129/main.py
200
{"code":200,"message":"success","data":{"count":60,"pageCount":6,"floorCount":59,"list":[{"info":{"commentId":13646053,"articleId":108858689,"parentId":0,"postTime":"2020-10-30 11:03:45","content":"洗掉多張表:自己想 O(∩_∩)O~","userName":"qq_43055855","digg":2,"diggArr":[],"parentUserName":null,"parentNickName":null,"avatar":"https://profile.csdnimg.cn/C/B/3/3_qq_43055855","nickName":"海海不掉頭發","dateFormat":"6天前","tag":"碼皇","parentTag":null,"years":null,"vip":null,"vipIcon":null,"companyBlog":null,"companyBlogIcon":null,"flag":null,"flagIcon":null,"levelIcon":null},"sub":
我就截取一點吧,太大了,可以看出來截下來了就好,
別說了,也可以自己去決議一下,這個以我們之前學的解不了,后面我解給你看,
小爬蟲被騙啦
當服務器遇上了整容過后的小爬蟲,終于“門戶大開”,大方的給了一頁的資料,一頁的資料,一頁,,,
但是我要的是全部啊,你就給我一頁就想打發我?打發叫花子呢?
那怎么辦呢?這個死渣男,小氣得很吶,看來又要我們自己動腦筋咯,
帶參請求資料
還記得我們最開始是怎么找到評論區的包嗎?對,我沒說,我是先將頁面清空,然后請求訪問了第二個頁面,這時候就出現了一個新包,用腳指頭想都知道那就是第二個頁面的包,不過我還是想用第一個頁面,于是我就切回去了,
那我們再想想,這些資料我們是在哪里找到的?我不希望看到你們說Preview啊,想清楚啊,想這樣說的朋友,給你們一次重新組織語言的機會,
對,明明就是在Headers的General的url里面找到的嘛,Preview怎么爬?對吧,
本來不想多廢話,但是我喜歡分析url,所以就多說兩句唄,
第一個頁面的URL:https://blog.csdn.net/phoenix/web/v1/comment/list/108858689?page=1&size=10&commentId=
第二個頁面的URL:https://blog.csdn.net/phoenix/web/v1/comment/list/108858689?page=2&size=10&commentId=
第三個頁面的URL:https://blog.csdn.net/phoenix/web/v1/comment/list/108858689?page=3&size=10&commentId=
一目了然了吧,不用我再多放了,
import requests
from bs4 import BeautifulSoup
import json
headers = {
'origin':'https://lion-wu.blog.csdn.net',
# 請求來源,本案例中其實是不需要加這個引數的,只是為了演示
'referer':'https://lion-wu.blog.csdn.net/article/details/108858689',
# 請求來源,攜帶的資訊比“origin”更豐富,本案例中其實是不需要加這個引數的,只是為了演示
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'
# 標記了請求從什么設備,什么瀏覽器上發出
}
# 偽裝請求頭
for i in range(5):
res = requests.get('https://blog.csdn.net/phoenix/web/v1/comment/list/108858689?page='+str(i)+'&size=10&commentId=',headers=headers)
print(res.status_code)
soup = BeautifulSoup(res.text,'html.parser')
json_items = json.loads(soup.text)
items = json_items['data']['list']
for item in items:
print(item['info']['content'])
print('\n'+'----------'+'\n')
強行灌輸知識點
有時候呢,你會發現你抓取的幾個頁面不過是在重復(強行灌輸知識點)
那就灌一下吧,
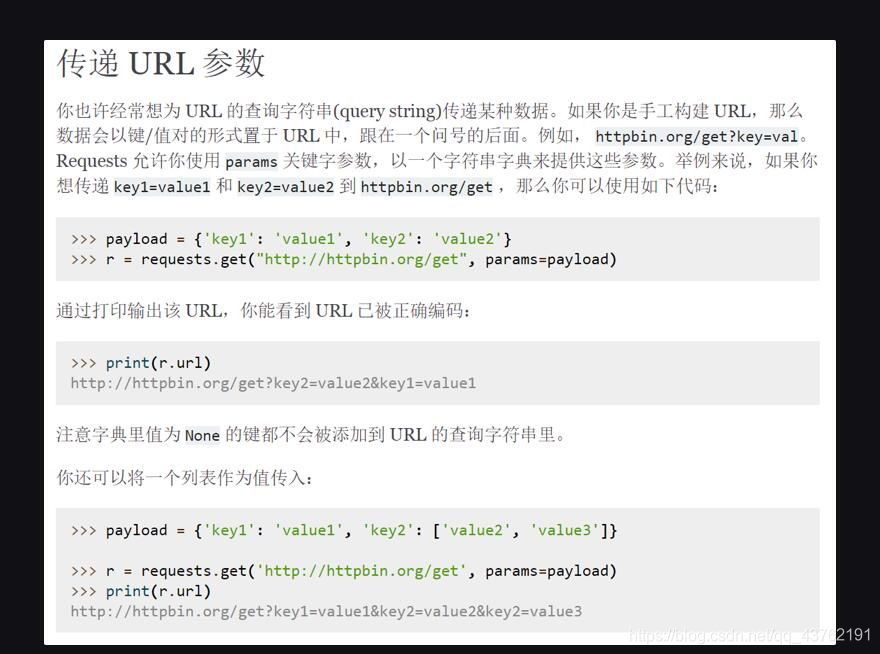
我也不知道什么是就要用上,反正先寫上,
所以,其實我們可以把Query String Parameters里的內容,直接復制下來,封裝為一個字典,傳遞給params,只是有一點要特別注意:要給他們打引號,讓它們變字串,
所以,代碼最后可能長這樣:
偽代碼
import requests
# 參考requests模塊
url = 'https://blog.csdn.net/phoenix/web/v1/comment/list/108858689'
for i in range(5):
'params' = {
'page': str(i)
'size': '10'
'commentId':
}
# 將引數封裝為字典
res_comments = requests.get(url,params=params,頭)
好極,好極,這篇就到這里啦,爽吶,
下一篇會比較輕松一些,這篇資訊量有點大啊,


轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/208753.html
標籤:其他
上一篇:看不懂代碼也能做網站(一)---效果演示以及環境搭建
下一篇:用例子理解遞回