相信喜歡機器學習、深度學習的小伙伴對神經網路這個詞肯定不陌生,那么什么是神經網路呢?它可以用來做什么呢?怎么做呢?今天好好總結一下,

一、神經網路是什么?
是一種模仿生物神經網路的結構和功能的數學模型或計算模型,神經網路由大量的人工神經元聯結進行計算,大多數情況下人工神經網路能在外界資訊的基礎上改變內部結構,是一種自適應系統,現代神經網路是一種非線性統計性資料建模工具,常用來對輸入和輸出間復雜的關系進行建模,或用來探索資料的模式,
典型的網路結構為:
至于輸入層是什么,隱藏層是什么,輸出層是什么,怎么輸入,怎么輸出,下面會寫,先了解了神經網路的基本結構,

二、神經網路可以用來做什么
舉2個栗子
貓狗分類:有一大堆貓、狗照片,把每一張照片送進一個機器里,機器需要判斷這幅照片里的東西是貓還是狗,
手寫數字識別:將手寫的圖片讀入到機器中,機器自動判定這個數字是什么,
簡單地說,就是對圖片的一個識別和一個簡單的分類,
為了更方便理解神經網路,在介紹神經網路之前先來介紹一下感知機,
三、感知機
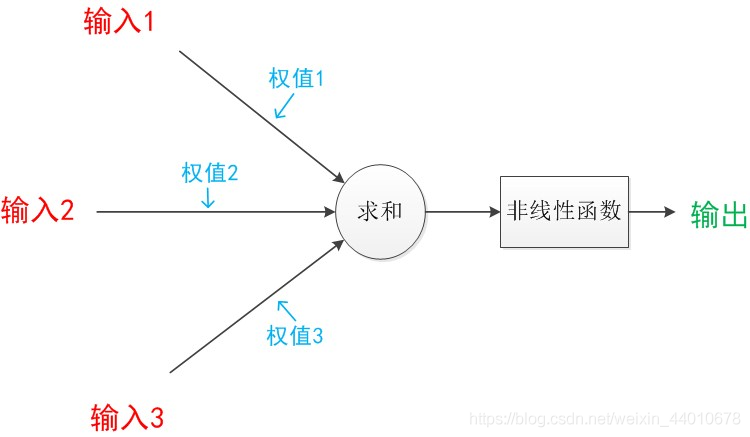
感知機:計算機模擬大腦經行資訊處理的程序,有n個輸入資料,通過權重與各資料之間的計算和,比較激活函式結果,得出輸出,解決分類問題,
其結構如下圖,是不是和線性回歸比較像,線性回歸是y=w1x1+w2x2+……+wnxn+b,而感知機和它及其類似,感知機通過輸出來判定是哪一類,
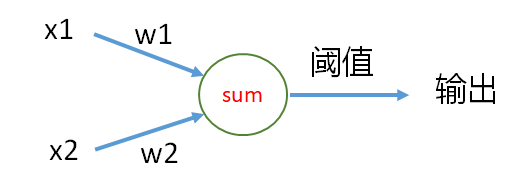
為了簡單理解,我們先來看一個例子,
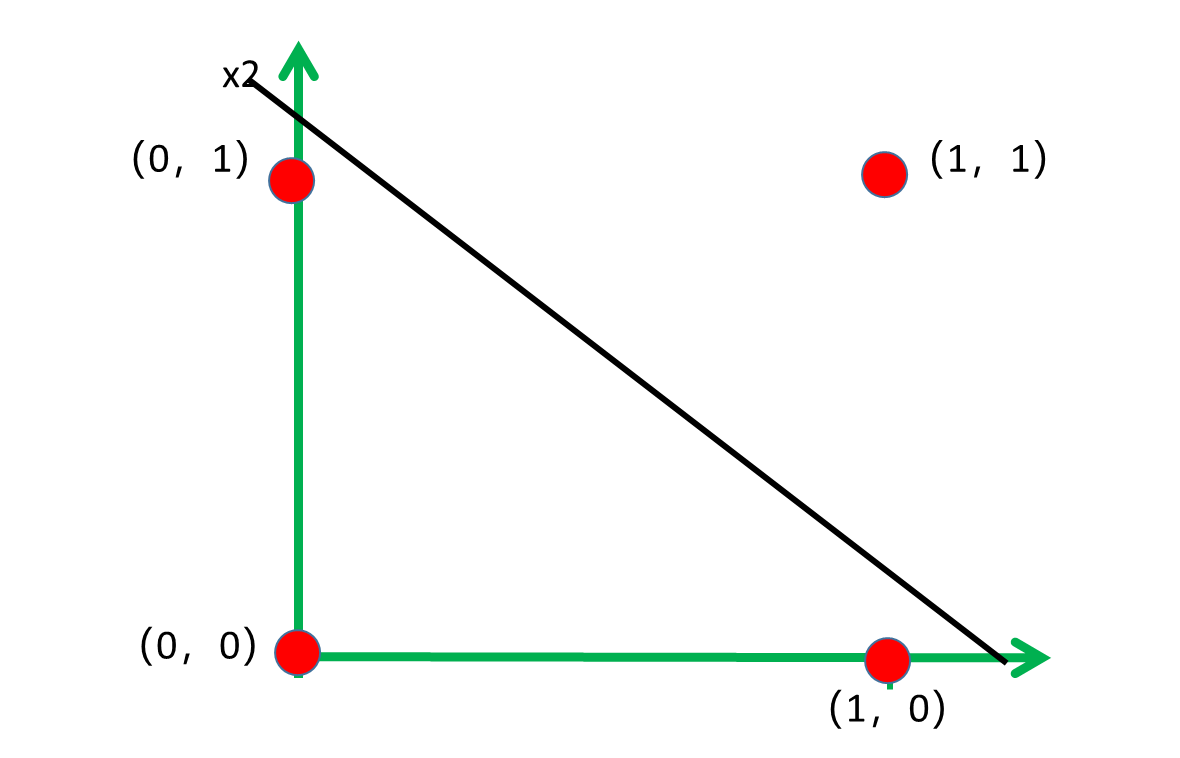
假設給定兩個特征x1,x2,設定權重w1=1,w2=1,設定閾值為1.5,那么計算后可知(0,1)、(1,0)的結果為1,小于1.5,(0,0)的結果為0,小于1.5,(1,1)的結果為2,大于1.5,所以就把四個樣本點分為了2類,其中的黑線就為分類線,但是很顯然這個線是不唯一的,那如何來確定呢,繼續看,
好了,上面我們已經用感知機解決了一個簡單的二分類問題,那么肯定大家有疑問,如果我要解決三類、四類、更多類的問題怎么辦呢?
當然是要畫兩條線了,但是兩條線是怎么畫出來的呢?用兩個感知機!
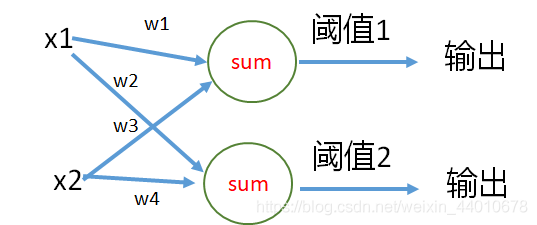
有兩個感知機也就意味著有了兩個權重,有了兩個輸出,即有了兩條線
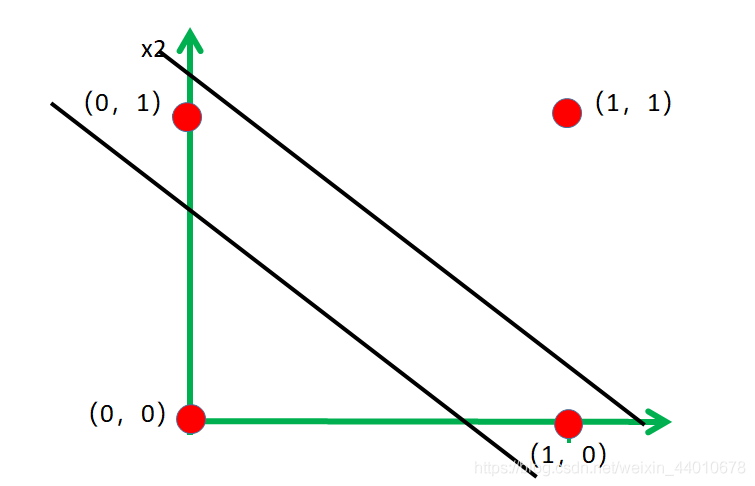
多分類,需要多個感知機即可,如果想要更形象的了解是如何進行分類的,可以來玩一下這個網站
好了,到現在感知機的內容算是結束了,明白了吧,

但是感知機和我們的神經網路有什么關系呢?我們要講的是神經網路啊,別急!

感知機是神經網路的基礎,簡單地說,神經網路就是由多個感知機運算組成的,其實感知機就是神經元,
四、神經網路
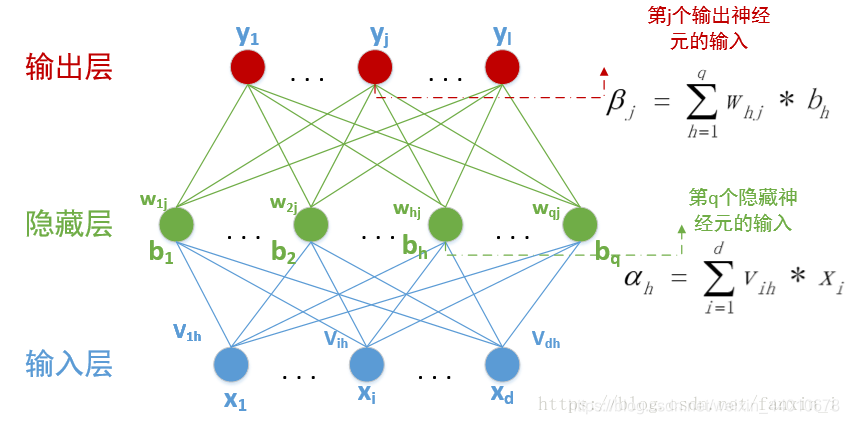
神經網路的結構:輸入層、隱藏層、輸出層,
神經網路的特點:
- 輸入向量的維度的輸入神經元的個數相同
- 每個連接層都有個權值
- 同一層神經元之間沒有連接
- 由輸入層、隱層、輸出層組成
- 第N層和N-1層的所有神經元連接,也叫全連接,
4.1神經網路作業流程
大家都知道神經網路進行圖片分類很厲害,但是圖片怎么輸入呢,我們之前不都是直接輸入的特征嗎?
圖片的特征就是像素,打開圖片屬性可以查看像素,
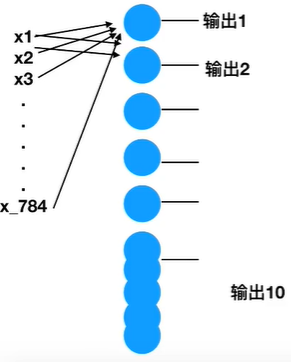
來看張圖片,這是minist手寫資料集中的一張,MINIST資料集中的每一張圖片有28*28像素點組成,即有28 * 28=724個像素點,每個像素點的值區間在0~255之間,也就是說對這樣一張圖片進行識別需要784個特征,x1,x2,x3……x784,也就是說輸入層有784個元素,下面確定全連接層(輸出層),因為數字有10類,所以最后要分成10類(0,1,2……9),所以全連接層有10個元素,至此,已經確定了輸入層和輸出層,
那么中間層怎么確定呢?不急,下面說,我們先掠過中間層,建立好一個簡單的模型,那么通過計算可以知道,需要有784*10個權重,也就是說需要7840個神經元,最后還有10個偏置,
那么輸出的10個結果是什么樣的呢?機器是不能直接輸出判斷的結果1,2,3的,而是輸出的概率,在哪一個位置輸出的概率大,則認為這張圖片是什么數字,這就需要用到softmax,
4.2 softmax選擇器
加上softmax后的結構如下圖,
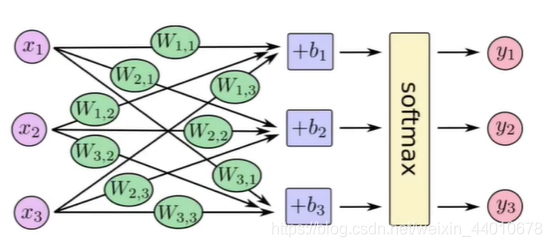
假設我們有一個陣列,V,Vi表示V中的第i個元素,那么這個元素的softmax值為:
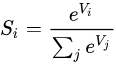 也就是說,是該元素的指數,與所有元素指數和的比值,這就是softmax的公式,
也就是說,是該元素的指數,與所有元素指數和的比值,這就是softmax的公式,
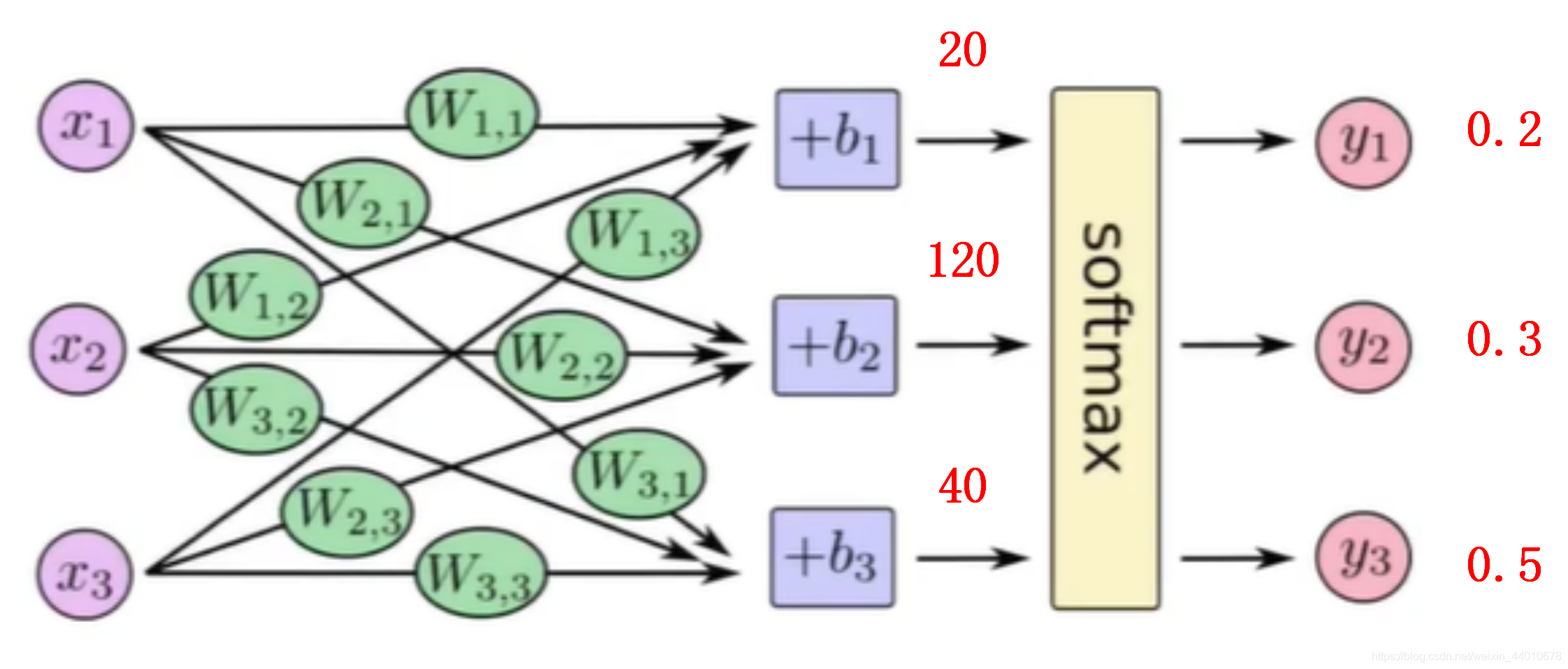
舉個例子:假設一些x1,x2,x3經過中間層、輸出層,輸出的3個數字分別為20,120,40,那么我們可以帶入到softmax公式中計算(ps:此處算出來的數都是我編的,主要是為了方便理解)
S1=e20/( e20+e120+e40)=0.2
S2=e120/( e20+e120+e40)=0.3
S3=e40/( e20+e120+e40)=0.5
計算出來的概率值和應該為1,
至此,我們已經得到了概率值,
那么有了概率之后,怎么來反映到標簽呢?用one-hot編碼,
4.3 one-hot編碼
One-Hot編碼,又稱為一位有效編碼,主要是采用N位狀態暫存器來對N個狀態進行編碼,每個狀態都由他獨立的暫存器位,并且在任意時候只有一位有效,
One-Hot編碼是分類變數作為二進制向量的表示,這首先要求將分類值映射到整數值,然后,每個整數值被表示為二進制向量,除了整數的索引之外,它都是零值,它被標記為1,
內部很繁瑣,如果想詳細了解,請百度,
下面舉個栗子幫助理解:
比如我們要手寫識別的數字1,我們需要將真實值轉化為one-hot編碼,則將1轉化為了[0,1,0,0,0,0,0,0,0,0],同理2可以轉化為[0,0,1,0,0,0,0,0,0,0]
那么現在總結一下,我們完成了哪些作業:我們有了輸入,有了輸出(概率),有了真實值,下面的問題是,如何將輸出和真實值聯系在一起,
這就需要用到交叉熵損失
4.4交叉熵損失
交叉熵是什么:交叉熵刻畫的是實際輸出(概率)與期望輸出(概率)的距離,也就是交叉熵的值越小,兩個概率分布就越接近,

比如說我們softmax后的結果為[0.11,0.22,0.13,0.14……0.12],對應的真實值one-hot編碼是[0,1,0,0,0,0,0,0,0,0],那么代入公式為H(y)=-(0log(0.11)+1log(0.22)+……)
實質就是衡量兩者的的差的大小,我們希望得到的是如果softmax后的結果為[0,1,0,0,0,0,0,0,0,0],那怎么最后得到的結果就是-1log1=0(因為其余項都是0),也就是如果交叉熵為0,那么預測百分之百正確,
所以我們需要做的就是提高1類別對應的softmax后的那個數中的概率,我們希望把[0.11,0.22,0.13,0.14……0.12]中0.22那個位置的概率提高到1,從而把該標簽判定為1,
下面就是讓將交叉熵損失盡可能的小,需要通過不斷更新權重,下面就要介紹到反向傳播演算法了,
4.5 反向傳播演算法
反向傳播的作用:前向傳遞輸入信號直至輸出產生誤差,反向傳播誤差資訊更新權重矩陣,使得交叉熵最小,
反向傳播演算法的內部是復雜的,先了解這么多,一會在代碼中介紹,
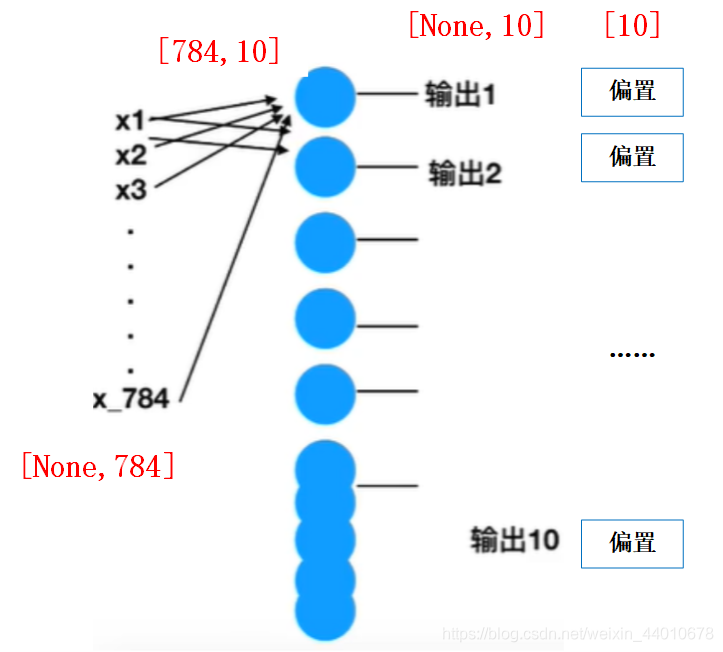
我們還要知道,神經網路是以矩陣的方式計算的,
如下圖,輸入層中的手寫圖片張數由實際確定,所以為None,但是像素是785,所以輸入層的矩陣為[None,784],又知道最后輸出的是10個結果,所以權重的個數為784*10,最后一層的矩陣為[None,10],還要記得有偏置,有10個,這便是神經網路的計算流程,
代碼
from tensorflow.examples.tutorials.mnist import input_data#tensorflow自帶資料集
import tensorflow as tf
#實作一個簡單的神經網路識別手寫數字(無中間層)
def full_connected():
mnist=input_data.read_data_sets("Mnist",one_hot=True)#下載資料集并保存在Mnist檔案中
#1、建立占位符,x[None,784],y_true[None,10]
with tf.variable_scope("data"):
x=tf.placeholder(tf.float32,[None,784])
y_true=tf.placeholder(tf.float32,[None,10])
#2、建立一個全連接層的神經網路 w[784,10],b[10]
with tf.variable_scope("fc_model"):
#隨機初始化權重和樣本
weight=tf.Variable(tf.random_normal([784,10],mean=0.0,stddev=1.0),name="w")#隨機初始化w
bias=tf.Variable(tf.constant(0.0,shape=[10]))#注意,bias為一維陣列,就是10個數,所以定義shape=[10]
y_predict=tf.matmul(x,weight)+bias#預測的結果 [None,784]*[784,10]+[10]=[None,10]
#3、求出樣本的損失值,然后求平均值
with tf.variable_scope("soft_cross"):
loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_true,logits=y_predict))#tf.nn.softmax_cross_entropy_with_logits可計算交叉熵損失
#4、反向傳播(梯度下降)
with tf.variable_scope("optimizer"):
train_op=tf.train.GradientDescentOptimizer(0.1).minimize(loss)
#5、計算準確率
with tf.variable_scope("acc"):
equal_list=tf.equal(tf.argmax(y_true,1),tf.argmax(y_predict,1))#equal_list為一個串列,即y_true與y_predict同則為1,否則為0,最后的equal_list是一個類似[0,0,0,0,1,1……]的串列
accuracy=tf.reduce_mean(tf.cast(equal_list,tf.float32))#把equal_list轉化為float型別,并求平均值,即為準確率
#定義初始化變數op
init_op=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init_op)
for i in range(200):
mnist_x,mnist_y=mnist.train.next_batch(50)#每次取出50個值進行訓練
sess.run(train_op,feed_dict={x:mnist_x,y_true:mnist_y})#注意,一定要用feed_dict,因為前面使用了占位符
print("訓練第%d步,準確率為:%f" %(i,sess.run(accuracy,feed_dict={x:mnist_x,y_true:mnist_y})))
return None
if __name__=="__main__":
full_connected()
在tensoboard中進行可視化完整代碼
from tensorflow.examples.tutorials.mnist import input_data#tensorflow自帶資料集
import tensorflow as tf
def full_connected():
mnist=input_data.read_data_sets("Mnist",one_hot=True)#下載資料集并保存在Mnist檔案中
#1、建立占位符,x[None,784],y_true[None,10]
with tf.variable_scope("data"):
x=tf.placeholder(tf.float32,[None,784])
y_true=tf.placeholder(tf.float32,[None,10])
#2、建立一個全連接層的神經網路 w[784,10],b[10]
with tf.variable_scope("fc_model"):
#隨機初始化權重和樣本
weight=tf.Variable(tf.random_normal([784,10],mean=0.0,stddev=1.0),name="w")#隨機初始化w
bias=tf.Variable(tf.constant(0.0,shape=[10]))#注意,bias為一維陣列,就是10個數,所以定義shape=[10]
y_predict=tf.matmul(x,weight)+bias#預測的結果 [None,784]*[784,10]+[10]=[None,10]
#3、求出樣本的損失值,然后求平均值
with tf.variable_scope("soft_cross"):
loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_true,logits=y_predict))#tf.nn.softmax_cross_entropy_with_logits可計算交叉熵損失
#4、反向傳播(梯度下降)
with tf.variable_scope("optimizer"):
train_op=tf.train.GradientDescentOptimizer(0.2).minimize(loss)
#5、計算準確率
with tf.variable_scope("acc"):
equal_list=tf.equal(tf.argmax(y_true,1),tf.argmax(y_predict,1))#equal_list為一個串列,即y_true與y_predict同則為1,否則為0,最后的equal_list是一個類似[0,0,0,0,1,1……]的串列
accuracy=tf.reduce_mean(tf.cast(equal_list,tf.float32))#把equal_list轉化為float型別,并求平均值,即為準確率
#定義初始化變數op
init_op=tf.global_variables_initializer()
#在tensorboard中可視化--------------------------------------------
#收集變數(單個數字)
tf.summary.scalar("losses",loss)
tf.summary.scalar("acc",accuracy)
#收集變數(多維度變數)
tf.summary.histogram("weights",weight)
tf.summary.histogram("bias",bias)
#合并變數
merged=tf.summary.merge_all()
#tensorboard進行可視化--------------------------------------------
with tf.Session() as sess:
sess.run(init_op)
filewriter=tf.summary.FileWriter("路徑",graph=sess.graph)#建立event檔案并寫入
for i in range(200):#200為迭代步數
mnist_x,mnist_y=mnist.train.next_batch(50)
sess.run(train_op,feed_dict={x:mnist_x,y_true:mnist_y})
#寫入每步訓練值
summary=sess.run(merged,feed_dict={x:mnist_x,y_true:mnist_y})
filewriter.add_summary(summary,i)
print("訓練第%d步,準確率為:%f" %(i,sess.run(accuracy,feed_dict={x:mnist_x,y_true:mnist_y})))
return None
if __name__=="__main__":
full_connected()
可視化結果
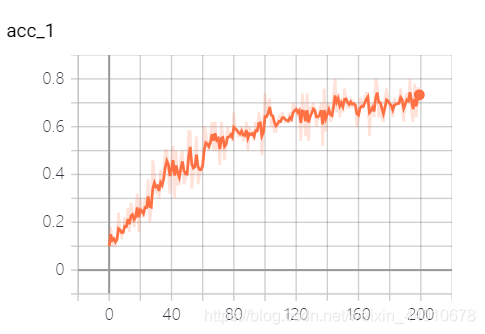
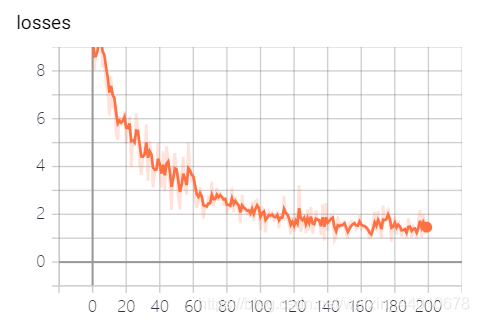
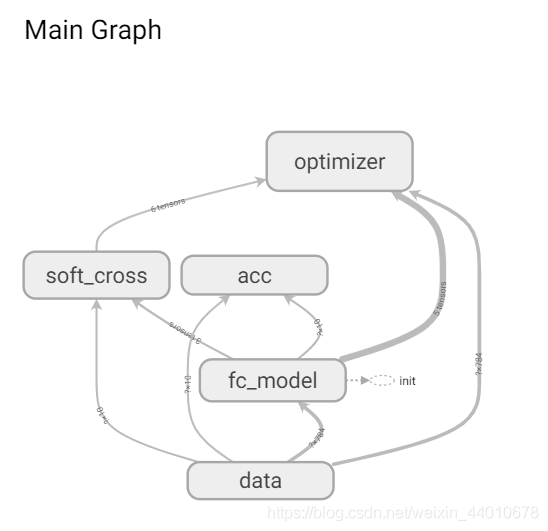
測驗代碼
FLAGS=tf.app.flags.FLAGS
tf.app.flags.DEFINE_string('f', '', 'kernel')
tf.app.flags.DEFINE_integer("is_train",1, "指定程式是預測還是訓練")
def full_connected():
mnist=input_data.read_data_sets("Mnist",one_hot=True)#下載資料集并保存在Mnist檔案中
#1、建立占位符,x[None,784],y_true[None,10]
with tf.variable_scope("data"):
x=tf.placeholder(tf.float32,[None,784])
y_true=tf.placeholder(tf.float32,[None,10])
#2、建立一個全連接層的神經網路 w[784,10],b[10]
with tf.variable_scope("fc_model"):
#隨機初始化權重和樣本
weight=tf.Variable(tf.random_normal([784,10],mean=0.0,stddev=1.0),name="w")#隨機初始化w
bias=tf.Variable(tf.constant(0.0,shape=[10]))#注意,bias為一維陣列,就是10個數,所以定義shape=[10]
y_predict=tf.matmul(x,weight)+bias#預測的結果 [None,784]*[784,10]+[10]=[None,10]
#3、求出樣本的損失值,然后求平均值
with tf.variable_scope("soft_cross"):
loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_true,logits=y_predict))#tf.nn.softmax_cross_entropy_with_logits可計算交叉熵損失
#4、反向傳播(梯度下降)
with tf.variable_scope("optimizer"):
train_op=tf.train.GradientDescentOptimizer(0.2).minimize(loss)
#5、計算準確率
with tf.variable_scope("acc"):
equal_list=tf.equal(tf.argmax(y_true,1),tf.argmax(y_predict,1))#equal_list為一個串列,即y_true與y_predict同則為1,否則為0,最后的equal_list是一個類似[0,0,0,0,1,1……]的串列
accuracy=tf.reduce_mean(tf.cast(equal_list,tf.float32))#把equal_list轉化為float型別,并求平均值,即為準確率
#定義初始化變數op
init_op=tf.global_variables_initializer()
#創建一個saver
saver=tf.train.Saver()
with tf.Session() as sess:
sess.run(init_op)
if FLAGS.is_train==1:
for i in range(200):
mnist_x,mnist_y=mnist.train.next_batch(50)#每次取出50個值進行訓練
sess.run(train_op,feed_dict={x:mnist_x,y_true:mnist_y})#注意,一定要用feed_dict,因為前面使用了占位符
print("訓練第%d步,準確率為:%f" %(i,sess.run(accuracy,feed_dict={x:mnist_x,y_true:mnist_y})))
#保存模型
saver.save(sess,"路徑/model")
else:
saver.restore(sess,"路徑/model")
for i in range(20):
x_test,y_test=mnist.test.next_batch(1)
print("第%d張圖片,手寫數字的目標是%d,預測結果是%d" %(i,sess.run(tf.argmax(y_test,1)),sess.run(tf.argmax(sess.run(y_predict,feed_dict={x:x_test,y_true:y_test}),1))))
return None
if __name__=="__main__":
full_connected()
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/208956.html
標籤:其他