接上篇博客,這周主要學習了GraphSAGE,GAT,R-GCN 三種GNN的變體模型,從空域的角度出發,對節點的嵌入表征進行了深入的研究,(本文作為筆者的學習筆記,如有錯誤,希望各位讀者批評指正) - - 更新時間:2020年11月8日
[學習筆記(1)]深入淺出了解GCN原理(公式+代碼)
[學習筆記(2)]深入淺出了解GNN的幾種變體
目錄
- GraphSAGE(SAmple and aggreGatE)
- 聚合函式
- 引數學習
- 代碼
- 總結
- GAT(Graph Attention Networks)
- 總結
- R-GCNs(Relational Graph Convolutional Networks)
- 任務
- 總結
- 思考
- 參考文獻
??再上一章的內容里,我們主要從頻域的角度推匯出了圖卷積的一般運算式,通過簡化最終得到了圖卷積公式(1),從空域視角來看,其本質就是一個 迭代式地聚合鄰居節點的程序,這種模型聚合的設計,大大加強了 大規模圖資料的適應性,基于此思想的設計,一些GNN的變體框架也相繼提出,這些框架從更加統一的層面,抽象出了GNN的運算式,本章我們簡單介紹幾種 GNN的變體,這些變體從空域卷積出發,對節點的embedding以及邊關系的資訊歸納有了更強大的表達能力,
H ( l + 1 ) = σ ( D ~ ? 1 2 A ~ D ~ ? 1 2 H ( l ) W ( l ) ) ( 1 ) \qquad\qquad\qquad\qquad \qquad H^{(l+1)}=\sigma(\tilde{D}^{-\frac{1}{2}}\tilde{A}\tilde{D}^{-\frac{1}{2}}H^{(l)}W^{(l)})\qquad\qquad\qquad \quad\qquad\qquad(1) H(l+1)=σ(D~?21?A~D~?21?H(l)W(l))(1)
GraphSAGE(SAmple and aggreGatE)
??GraphSAGE是基于之前圖嵌入Transductive學習的一些缺點,提出的一個Inductive的演算法,目前為止,大多數現有的使用圖卷積網路生成節點嵌入的方法僅應用于具有固定圖的轉換,其本質上都是transductive.(直推式)的方式,對于每個節點的嵌入,使用全域的節點資訊,每次迭代所有的訓練樣本貢獻一次梯度,而無法做到min-batch的訓練方式,這在很多實際大規模資料的應用場景下是無法實作的,同時這種方式,對于 "unseen"的節點 并不能很好的表示,每次增加新的節點,圖結構就會發生變換,為了與新加入的節點對齊,得到修正后的embedding,需要重新訓練整個新的資料集,基于以上幾點的考慮,作者推出了GraphSAGE (SAmple and aggreGatE),一種Inductive的方式對node嵌入學習,
聚合函式
??在GCN的模型中,節點在第K層的特征,只與其鄰居K-1層的特征有關,這種區域特性,使得節點在每一層的特征,只與其K階子圖有關,運用在大規模的圖資料中,我們就只需要考慮每個節點的K階鄰居即可,而不需要一次性訓練全域的資訊,
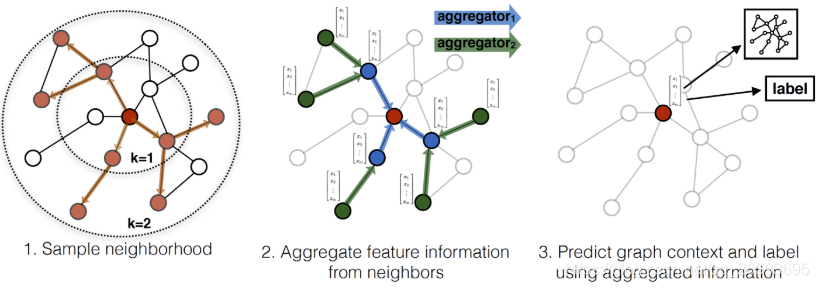
??考慮現實世界中,資料節點的度往往呈指數級增長,這樣會使得計算和存盤代價變的不可控制,所以GraphSAGE采用有放回的均勻隨機采樣,從而固定選擇鄰接節點的數量,事實上我們還可以采用其他形式的分布,或者自適應的方式來選取鄰接節點,
這里先直接附上論文中的演算法步驟,演算法的具體實施流程如下所示:
??Embedding generation (i.e., forward propagation) algorithm ,該流程描述了如何使用聚合函式對節點的鄰居資訊進行聚合,從而生成目標節點的embedding,

每一次的迭代,每層的源節點都會從它的區域鄰居聚合資訊,迭代次數越多,聚合節點的資訊范圍就越廣,直接看上述流程可能還不是很清楚,接下來我會貼出代碼和注釋,并對演算法流程中的聚合與連接操作進行講解,
我們來看看聚合操作,GraphSAGE聚合節點的操作需要滿足以下三點:
- 聚合操作后維度保存一致
- 聚合的節點需要具有排列不變性,我們了解的影像和序列資料,前者包含空間順序,后者包含時序順序,而圖資料本身是無序的資料結構
- 聚合操作必須可導
論文中,作者主要提出了三種聚合方式:
由于原文中的公式我自認為寫的不是很清楚,感興趣的讀者可以自行閱讀原文 (Inductive Representation Learning on Large Graphs),這里我根據代碼中給出的計算方法,重新寫了計算表達公式,將三種形式的聚合以及兩種連接方式統一到了一個運算式:
A
g
g
s
u
m
:
h
v
K
=
σ
(
{
h
v
K
?
1
?
θ
1
d
×
m
}
∪
A
g
g
r
e
g
a
t
e
{
h
u
K
?
1
,
?
u
∈
N
(
v
)
}
?
θ
2
d
×
m
)
.
(
2
)
Agg^{sum} :h^{K}_v=\sigma( \{h^{K-1}_v \cdot \theta_1^{d\times m} \} \cup Aggregate\{ h^{K-1}_u,\forall u\in \mathcal{N}(v)\}\cdot \theta_2^{d\times m}). \qquad\qquad(2)
Aggsum:hvK?=σ({hvK?1??θ1d×m?}∪Aggregate{huK?1?,?u∈N(v)}?θ2d×m?).(2)
其中:
- 第K次迭代的源節點 h v K h^K_v hvK? 的embedding由第k-1次迭代的節點 h v K ? 1 h^{K-1}_v hvK?1? 與其采樣的鄰居節點 h u K ? 1 h_u^{K-1} huK?1?聚合表示后的連接得到,
- 聚合
A
g
g
r
e
g
a
t
e
Aggregate
Aggregate操作可分為
MEAN,MAX和LSTM三種聚合方式 -
∪
\cup
∪分為兩種連接方式,一種是
SUM直接相加,另一種是CONCAT特征維度上拼接,這種連接方式可以看作是不同搜索深度或GraphSAGE演算法層之間的Skip connection(跳躍連接)的簡單形式,它可以顯著提高模型性能, - σ \sigma σ是sigmoid函式,做非線性變換
- θ \theta θ是可學習的引數矩陣
簡單補充說明下文中提到的三種Aggregate操作:
Mean aggregator.:
平均聚合算子,逐元素求和取平均,這種操作是GCN中圖卷積傳導的線性近似,
LSTM aggregator
LSTMs 的聚合器有加更強大的表達能力,但是,LSTMs不是symmetric的,不具有permutation invariant(排列不變性),因為LSTM的輸入是以序列的方式處理,具有時序性,因此,需要先對鄰居節點順序隨機打亂,然后將鄰居序列的embedding作為LSTM的輸入,
Pooling aggregator
類似于影像中的池化操作,elementwise級別的 max-pooling操作來跨鄰集聚合資訊,
引數學習
基于圖的有監督學習方式,這里就不過多說明,通過GraphSAGE得到的節點embedding,配合下游多個任務使用,監督學習的形式可根據任務的不同設定不同的目標函式即可,比如節點分類任務可使用交叉熵損失函式,
基于圖的無監督學習方式,傾向于使得相鄰的頂點有相似的表示,同時也會使相互遠離的頂點的表示差異變大:
J
g
(
z
u
)
=
?
l
o
g
(
σ
(
z
u
T
z
v
)
)
?
Q
?
E
v
n
~
P
n
(
v
)
l
o
g
(
σ
(
?
z
u
T
z
v
n
)
)
(
3
)
\qquad J_g(z_u)=-log(\sigma(z_u^Tz_v))-Q\cdot {\mathbb{E}_{v_n \thicksim P_n(v)}} log(\sigma(-z^T_uz_{v_n})) \qquad\qquad\qquad \qquad (3)
Jg?(zu?)=?log(σ(zuT?zv?))?Q?Evn?~Pn?(v)?log(σ(?zuT?zvn??))(3)
- v v v是 u u u通過定長隨機游走可達的鄰居, Z v , Z u Z_v,Z_u Zv?,Zu?是GraphSAGE得到的節點embedding
- P n ( v ) P_n(v) Pn?(v)是一個負采樣分布
- Q Q Q定義為負采樣個數
節點表示 z u z_u zu?是從包含在節點的本地鄰居的特征中生成的,而不是為每個節點訓練一個唯一的嵌入表示,節點之間的相似度,通過點積來表示,這個運算式作為無監督學習的方式,可為下游任務作為一個預訓練的服務,在有監督學習中的任何一個損失函式都可以將其替換,
代碼
代碼部分主要參考GraphSage示例
??首先需要對鄰居節點采樣,我們維護一個節點及其鄰居對應關系的表,比如{0:[2,4],1:[2,5]…} ,每個節點都列出其對應的鄰居,我們通過sampling和multihop_sampling來實作批次的鄰居節點采樣操作,
def sampling(src_nodes, sample_num, neighbor_table):
"""根據源節點采樣指定數量的鄰居節點,注意使用的是有放回的采樣;
某個節點的鄰居節點數量少于采樣數量時,采樣結果出現重復的節點
Arguments:
src_nodes {list, ndarray} -- 源節點串列
sample_num {int} -- 需要采樣的節點數
neighbor_table {dict} -- 節點到其鄰居節點的映射表
Returns:
np.ndarray -- 采樣結果構成的串列
"""
results = []
for sid in src_nodes:
# 從節點的鄰居中進行有放回地進行采樣
res = np.random.choice(neighbor_table[sid], size=(sample_num, ))
results.append(res)
return np.asarray(results).flatten()
def multihop_sampling(src_nodes, sample_nums, neighbor_table):
"""根據源節點進行多階采樣
Arguments:
src_nodes {list, np.ndarray} -- 源節點id
sample_nums {list of int} -- 每一階需要采樣的個數
neighbor_table {dict} -- 節點到其鄰居節點的映射
Returns:
[list of ndarray] -- 每一階采樣的結果
"""
sampling_result = [src_nodes]
for k, hopk_num in enumerate(sample_nums):
hopk_result = sampling(sampling_result[k], hopk_num, neighbor_table)
sampling_result.append(hopk_result)
return sampling_result
其次是網路中的Aggregator的聚合操作,接收采樣后的neighor_feature,shape=(batch_size,neighor_nums,feature_dim),對其在第二個維度neighor_nums上聚合.
class NeighborAggregator(nn.Module):
def __init__(self, input_dim, output_dim,
use_bias=False, aggr_method="mean"):
"""聚合節點鄰居
Args:
input_dim: 輸入特征的維度
output_dim: 輸出特征的維度
use_bias: 是否使用偏置 (default: {False})
aggr_method: 鄰居聚合方式 (default: {mean})
"""
super(NeighborAggregator, self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.use_bias = use_bias
self.aggr_method = aggr_method
self.weight = nn.Parameter(torch.Tensor(input_dim, output_dim))
if self.use_bias:
self.bias = nn.Parameter(torch.Tensor(self.output_dim))
self.reset_parameters()
def reset_parameters(self):
init.kaiming_uniform_(self.weight)
if self.use_bias:
init.zeros_(self.bias)
def forward(self, neighbor_feature):
if self.aggr_method == "mean":
aggr_neighbor = neighbor_feature.mean(dim=1) #聚合
elif self.aggr_method == "sum":
aggr_neighbor = neighbor_feature.sum(dim=1)
elif self.aggr_method == "max":
aggr_neighbor = neighbor_feature.max(dim=1)
else:
raise ValueError("Unknown aggr type, expected sum, max, or mean, but got {}"
.format(self.aggr_method))
neighbor_hidden = torch.matmul(aggr_neighbor, self.weight)
if self.use_bias:
neighbor_hidden += self.bias
return neighbor_hidden
def extra_repr(self):
return 'in_features={}, out_features={}, aggr_method={}'.format(
self.input_dim, self.output_dim, self.aggr_method)
聚合后的資料,執行Skip connection的連接,如上文提到的sum或concatenate操作,
class SageGCN(nn.Module):
def __init__(self, input_dim, hidden_dim,
activation=F.relu,
aggr_neighbor_method="mean",
aggr_hidden_method="sum"):
"""SageGCN層定義
Args:
input_dim: 輸入特征的維度
hidden_dim: 隱層特征的維度,
當aggr_hidden_method=sum, 輸出維度為hidden_dim
當aggr_hidden_method=concat, 輸出維度為hidden_dim*2
activation: 激活函式
aggr_neighbor_method: 鄰居特征聚合方法,["mean", "sum", "max"]
aggr_hidden_method: 節點特征的更新方法,["sum", "concat"]
"""
super(SageGCN, self).__init__()
assert aggr_neighbor_method in ["mean", "sum", "max"]
assert aggr_hidden_method in ["sum", "concat"]
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.aggr_neighbor_method = aggr_neighbor_method
self.aggr_hidden_method = aggr_hidden_method
self.activation = activation
self.aggregator = NeighborAggregator(input_dim, hidden_dim,
aggr_method=aggr_neighbor_method)
self.weight = nn.Parameter(torch.Tensor(input_dim, hidden_dim))
self.reset_parameters()
def reset_parameters(self):
init.kaiming_uniform_(self.weight)
def forward(self, src_node_features, neighbor_node_features):
neighbor_hidden = self.aggregator(neighbor_node_features)
self_hidden = torch.matmul(src_node_features, self.weight)
if self.aggr_hidden_method == "sum": # 兩種連接方式
hidden = self_hidden + neighbor_hidden
elif self.aggr_hidden_method == "concat":
hidden = torch.cat([self_hidden, neighbor_hidden], dim=1)
else:
raise ValueError("Expected sum or concat, got {}"
.format(self.aggr_hidden))
if self.activation:
return self.activation(hidden)
else:
return hidden
def extra_repr(self):
output_dim = self.hidden_dim if self.aggr_hidden_method == "sum" else self.hidden_dim * 2
return 'in_features={}, out_features={}, aggr_hidden_method={}'.format(
self.input_dim, output_dim, self.aggr_hidden_method)
設定好一層的SAG后,我們封裝多層的GraphSage模型,這里默認引數設定的是兩層,也可以設定多層,但文章中作者表示一般2層就能達到很好的效果了.
- num_neighbors_list=[10,10] # 每階采樣鄰居的節點數設定為10
- num_layers=len(num_neighbors_list)=2,SAG卷積層數
class GraphSage(nn.Module):
def __init__(self, input_dim, hidden_dim,
num_neighbors_list):
super(GraphSage, self).__init__()
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.num_neighbors_list = num_neighbors_list
self.num_layers = len(num_neighbors_list)
self.gcn = nn.ModuleList()
self.gcn.append(SageGCN(input_dim, hidden_dim[0]))
for index in range(0, len(hidden_dim) - 2):
self.gcn.append(SageGCN(hidden_dim[index], hidden_dim[index+1]))
self.gcn.append(SageGCN(hidden_dim[-2], hidden_dim[-1], activation=None))
def forward(self, node_features_list):
hidden = node_features_list# [[0],[1],[2]]
for l in range(self.num_layers):#2
next_hidden = []
gcn = self.gcn[l]
for hop in range(self.num_layers - l):
src_node_features = hidden[hop]
src_node_num = len(src_node_features)
neighbor_node_features = hidden[hop + 1] \
.view((src_node_num, self.num_neighbors_list[hop], -1)) # 這里形狀需要reshape下
h = gcn(src_node_features, neighbor_node_features)
next_hidden.append(h)
hidden = next_hidden
return hidden[0]
def extra_repr(self):
return 'in_features={}, num_neighbors_list={}'.format(
self.input_dim, self.num_neighbors_list
)
為了讀者更好的理解,這里我舉個例子來說明迭代部分的代碼,以上述引數為例:
1、首先輸入一個mini_batch資料,shape=(batch_size,k)
2、 對其進行鄰接采樣得到neighbors_feature,由于我們是兩層的,所以采樣兩次,每個源節點得到10個鄰居節點.[(batch_size,k),(batch_size * 10,k),(batch_size * 10*10,k)]
3、在迭代階段,第K層節點由第K-1層的鄰居節點聚合連接得到.
起始
h
i
d
d
e
n
=
[
(
b
a
t
c
h
,
k
0
)
(
0
)
,
(
b
a
t
c
h
?
10
,
k
0
)
(
0
)
,
(
b
a
t
c
h
?
10
?
100
,
k
0
)
(
0
)
]
hidden=[(batch,k_0)^{(0)},(batch*10,k_0)^{(0)},(batch*10*100,k_0)^{(0)}]
hidden=[(batch,k0?)(0),(batch?10,k0?)(0),(batch?10?100,k0?)(0)]
第一次迭代后:
h
i
d
d
e
n
=
[
(
b
a
t
c
h
,
k
1
)
(
1
)
,
(
b
a
t
c
h
?
10
,
k
1
)
(
1
)
]
hidden=[(batch,k_1)^{(1)},(batch*10,k_1)^{(1)}]
hidden=[(batch,k1?)(1),(batch?10,k1?)(1)]
第二次迭代后:
h
i
d
d
e
n
=
[
(
b
a
t
c
h
,
k
2
)
(
2
)
]
hidden=[(batch,k_2)^{(2)}]
hidden=[(batch,k2?)(2)]
于是我們就得到了batch節點經過兩次迭代聚合后的embedding表達,embedding的維度為 k 2 k_2 k2?,
總結
??GraphSAGE解決了小批量訓練的問題,對于新加入的節點也能很好的適應并跟新,使得我們在大型的圖結構資料中將模型落地成為可能,同時GraphSAGE更重要的作用是通過聚合鄰居節點,對圖節點進行有效的嵌入表示,為下游任務注入了先驗知識,
GAT(Graph Attention Networks)
??介紹了上面Inductive的學習方式來對節點聚合,接下來介紹的是圖注意力網路GAT(Graph Attention Networks),它通過注意力機制來對鄰居節點聚合,實作了對鄰居權重的自適應分配,這一機制與CV和NLP領域中多頭的self-Attention是一致的,這也是在2018年大紅大紫的Bret模型能夠強力有效提取詞嵌入表達的主要原因之一,GAT可以說是注意力機制在圖資料當中的應用,想詳細了解注意力機制的讀者,可閱讀這篇:Attention Is All You Need
??注意力機制的三要素有Query, Source 和 Attention Value,我們可以很自然地想到,將Query設定為當前中心節點,Source設定為鄰居節點,而Value就是聚合后的節點表征,
定義節點
v
i
v_i
vi?在第
l
l
l層的特征表示為
h
i
h_i
hi?,
h
i
∈
R
d
(
l
)
h_i \in R^{d(l)}
hi?∈Rd(l),
d
(
l
)
d(l)
d(l)為該層的特征維度,聚合后的新節點為
h
i
′
h_i^{'}
hi′?,
鄰居節點
v
j
v_j
vj?聚合到
v
i
v_i
vi?的權重系數
e
i
j
e_{ij}
eij?為:
e
i
j
=
a
(
W
h
i
,
W
h
j
)
e_{ij}=a(Wh_i,Wh_j)
eij?=a(Whi?,Whj?)
輸入是節點集合
h
=
{
h
?
1
,
h
?
2
.
.
.
h
?
N
}
h=\{\vec{h}_1,\vec{h}_2...\vec{h}_N\}
h={h
1?,h
2?...h
N?},
h
?
i
∈
R
F
\vec{h}_i\in \mathbb{R}^F
h
i?∈RF
輸出是新的節點集合
h
′
=
{
h
?
1
′
,
h
?
2
′
.
.
.
h
?
N
′
}
h^{'}=\{\vec{h}_1^{'},\vec{h}_2^{'}...\vec{h}_N^{'}\}
h′={h
1′?,h
2′?...h
N′?} ,
h
?
i
′
∈
R
F
′
\vec{h}_i^{'}\in \mathbb{R}^{F^{'}}
h
i′?∈RF′
W
∈
R
F
×
F
′
W\in \mathbb{R}^{F\times F^{'} }
W∈RF×F′是該層節點特征變換的權重引數.
a
(
?
)
a(\cdot)
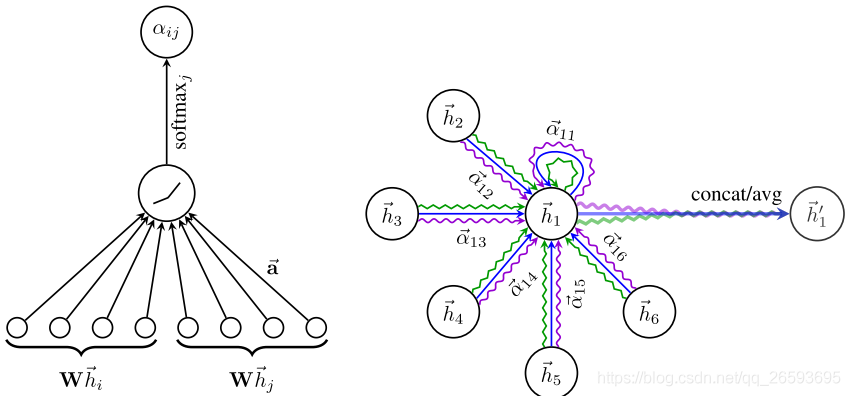
a(?)是計算兩個節點相關度的函式,比如使用內積作為相關度,文章作者選擇了一個單層的全連接層,||表示拼接操作,如Fig2 的左圖所示,圖中的
a
?
∈
R
2
F
′
\vec{a}\in\mathbb{R}^{2F^{'}}
a
∈R2F′,注意:對于節點
v
i
v_i
vi?來說,
v
i
v_i
vi?也是自己的鄰居,
e
i
j
=
L
e
a
k
y
R
e
L
U
(
a
T
[
W
h
i
∣
∣
W
h
j
]
)
(
4
)
\qquad\qquad e_{ij}=Leaky ReLU(a^T[Wh_i||Wh_j])\qquad \qquad\qquad\qquad\qquad(4)
eij?=LeakyReLU(aT[Whi?∣∣Whj?])(4)
為了使不同節點間的權重系數易于比較,我們使用softmax函式對所有計算出的權重進行歸一化:
a
i
j
=
s
o
f
t
m
a
x
i
(
e
i
j
)
=
e
x
p
(
e
i
j
)
∑
v
k
∈
N
v
i
e
x
p
(
e
i
k
)
(
5
)
\qquad a_{ij}={softmax}_i(e_{ij})=\frac{exp(e_{ij})}{\sum_{v_k\in \mathcal{N}_{v_i}} exp(e_{ik})} \qquad\qquad\qquad\qquad\quad(5)
aij?=softmaxi?(eij?)=∑vk?∈Nvi???exp(eik?)exp(eij?)?(5)
a
i
j
a_{ij}
aij?就是我們的所求,即聚合的權重系數,softmax函式保證了所有系數的和為1,將公式(4)與公式(5)合并,得到計算權重系數完整的運算式:
a
i
j
=
e
x
p
(
L
e
a
k
y
R
e
L
U
(
a
T
[
W
h
i
∣
∣
W
h
j
]
)
)
∑
v
k
∈
N
v
i
e
x
p
(
L
e
a
k
y
R
e
L
U
(
a
T
[
W
h
i
∣
∣
W
h
j
]
)
(
6
)
\qquad a_{ij}=\frac{exp(Leaky ReLU(a^T[Wh_i||Wh_j]))}{\sum_{v_k\in \mathcal{N}_{v_i}} exp(Leaky ReLU(a^T[Wh_i||Wh_j])}\qquad \qquad \quad(6)
aij?=∑vk?∈Nvi???exp(LeakyReLU(aT[Whi?∣∣Whj?])exp(LeakyReLU(aT[Whi?∣∣Whj?]))?(6)
計算完上述歸一化注意力系數后,再計算與之對應的特征的線性組合,作為每個節點的最終輸出特征,
應用非線性激活函式:
h
i
′
=
σ
(
∑
v
j
∈
N
(
v
i
)
a
i
j
W
h
j
)
(
7
)
\qquad\qquad \qquad h_i^{'}=\sigma \Big( \sum_{v_j\in \mathcal{N}(v_i)}a_{ij}Wh_j\Big) \qquad\qquad\qquad\qquad\qquad\quad(7)
hi′?=σ(vj?∈N(vi?)∑?aij?Whj?)(7)
更近一步提高注意力層的表達能力,加入多頭的注意力機制,對于上式呼叫K租相互獨立的注意力機制,最后將輸出拼接在一起,如Fig2 中右圖所示:
h
i
′
=
∣
∣
k
=
1
K
σ
(
∑
v
i
∈
N
(
v
i
)
a
i
j
(
k
)
W
k
h
j
?
)
(
7
)
\qquad\qquad\quad h_i^{'}=||^K_{k=1}\sigma\bigg( \sum_{v_i\in\mathcal{N}(v_i)}a_{ij}^{(k)}W^{k}\vec{h_{j}}\bigg) \qquad\qquad\quad(7)
hi′?=∣∣k=1K?σ(vi?∈N(vi?)∑?aij(k)?Wkhj?
?)(7)
如果是最后一層的話可直接取每一頭的平均進行聚合,
總結
??GAT這是一種新型的卷積式神經網路,它利用自注意力機制對鄰居節點的重要性加以預測,使模型具有更好的性能和魯棒性,GAT在計算上不需要昂貴的matrix運算,其得到F’個特征需要的演算法復雜度為
O
(
∣
V
∣
F
F
′
+
∣
E
∣
F
′
)
O(|V|FF^{'}+|E|F^{'})
O(∣V∣FF′+∣E∣F′),可并行運算圖中的所有節點,對于鄰居節點的資訊抽取能力比LSTM要好,
優點:
- 模型有效,且魯棒性好
- 不用一次計算整張圖,可批次和并行訓練
- 具有很強的可解釋性
R-GCNs(Relational Graph Convolutional Networks)
??上面兩種模型主要是應用于同構圖和無向圖的聚合模型,而接下來介紹的R-GCN針對的是異構圖與有向圖的資料結構,它可以解決關系型資料的知識推理問題,在知識圖譜(Knowledge Graph)中有廣泛的應用前景,
關系型資料:
- 有權有向
- 節點自身屬性
知識推理:
- 物體屬性推理
- 連邊關系預測
核心公式給出如下:
h
i
i
+
1
=
σ
(
∑
r
∈
R
∑
j
∈
N
i
r
1
c
i
,
r
W
r
(
l
)
h
j
(
l
)
+
W
0
(
l
)
h
i
(
l
)
)
(
8
)
\qquad h_i^{i+1}=\sigma \Bigg ( \sum_{r\in \mathcal{R}}\sum_{j\in\mathcal{N}_i^r}\frac{1}{c_{i,r}}W_r^{(l)}h_j^{(l)}+W_0^{(l)}h_i^{(l)}\Bigg) \qquad\qquad\qquad\qquad(8)
hii+1?=σ(r∈R∑?j∈Nir?∑?ci,r?1?Wr(l)?hj(l)?+W0(l)?hi(l)?)(8)
- N i r \mathcal{N}_i^r Nir?表示與節點 v i v_i vi?具有 r r r關系的鄰居節點集合
- c i , r c_{i,r} ci,r?是歸一化因子,可學習也可自行設定,如 c i , r = ∣ N i ( r ) ∣ c_{i,r}=|\mathcal{N}_{i}^{(r)}| ci,r?=∣Ni(r)?∣
基于上述公式描述,我們可以得到以下資訊:
- 每層節點特征都是由上一層節點特征和節點的關系(邊)得到;
- 節點的鄰居節點特征和自身特征進行加權求和得到新的特征;
- 保留了節點自身的資訊考慮自環
- 與 GCN 不同的地方在于 R-GCN 會考慮邊的型別和方向
下圖 Fig4 描述了R-GCN聚合鄰居操作的示意圖
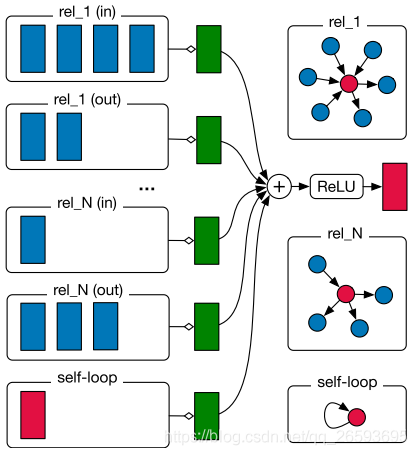
這里對于每種關系,我們用rel_i表示,同時,考慮關系的正向與反向,關系分為in 和out(有向性),每種關系 r r r對應一組鄰接的物體節點集合 { v j v_j vj?}
模型需要學習關系映射矩陣
W
r
W_r
Wr?,在一個典型的關系圖資料中,往往包含大量錯綜復雜的關系,如果為每一種關系都學習一組權重,那么R-GCN的引數將會非常龐大,同時由于不同關系的節點數量不一,重要程度不同,這大大增加了過擬合的風險,為了避免這種情況,作者提出了兩種分離的正則化方法,
1、對
W
r
W_r
Wr?進行基函式分解(basis decomposition) ,其本質就一組基的線性組合,即:
W
r
(
l
)
=
∑
b
=
1
B
a
r
b
(
l
)
V
b
(
l
)
(
9
)
\qquad \qquad W_r^{(l)}=\sum_{b=1}^Ba_{rb}^{(l)}V_b^{(l)}\qquad \qquad \qquad \qquad\qquad(9)
Wr(l)?=b=1∑B?arb(l)?Vb(l)?(9)
- V b ( l ) ∈ R d ( l + 1 ) × d ( l ) V_b^{(l)}\in R^{d^{(l+1)}\times d^{(l)}} Vb(l)?∈Rd(l+1)×d(l)為基
- a r b ( l ) a_{rb}^{(l)} arb(l)?為分解系數
- B為超參,控制基的個數
2、塊分解(block diagonal decomposition):
W
r
(
l
)
=
?
b
=
1
B
Q
b
r
(
l
)
(
10
)
\qquad\qquad W_r^{(l)}=\bigoplus_{b=1}^BQ_{br}^{(l)} \qquad \qquad \qquad\qquad \qquad\quad(10)
Wr(l)?=b=1?B?Qbr(l)?(10)
- W r ( l ) W_r^{(l)} Wr(l)?是塊對角陣 d i a g ( Q 1 r ( l ) , . . . , Q B r ( l ) ) diag(Q_{1r}^{(l)},...,Q_{Br}^{(l)}) diag(Q1r(l)?,...,QBr(l)?)其中 Q b r ( l ) ∈ R d ( l + 1 ) / B × ( d ( l ) / B ) Q_{br}^{(l)}\in\mathbb{R}^{d^{(l+1)/B}\times(d^{(l)}/B)} Qbr(l)?∈Rd(l+1)/B×(d(l)/B)
公式(10)的塊分解可以看作是對每種關系型別的權值矩陣的稀疏性約束,即假設潛在的特征可以被分組到一組變數中,這些變數在組內比在組間耦合得更緊密,
任務
??R-GCN可以作為node的編碼層,通過聚合提取圖譜中物體之間的關系,為下游任務提供節點嵌入表示,知識推理主要包括兩類任務,Entity classificatio(物體分類)與關系預測(Link prediction),由于本次主要介紹GCN的幾種變體,這里就不對如何做推斷任務過多展開,感興趣的讀者可以閱讀原文Modeling Relational Data with Graph Convolutional Networks,
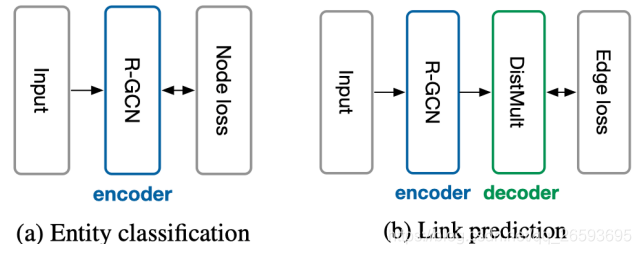
關系圖卷積的相關代碼可參考Graph Convolutional Networks for relational graphs,是基于keras框架和Theano后臺實作的,上手還是非常簡單的,
總結
??R-GCN將圖卷積運用到關系型資料當中,對異構圖和有向圖中節點之間的關系進行了有效的定義,解決了利用GCN來處理圖結構中不同邊關系對節點的影響,但是對于真實場景下的關系圖是非常復雜的,文章中雖然對關系矩陣做了分解,降低了學習引數量,但是沒有很好地考慮一些超級節點和無效關系的處理,未來的作業可以針對這部分展開,增加模型的泛化能力和魯棒性,
思考
??上述介紹的幾種GNN變體,對于節點的嵌入表示研究了不同的聚合方式,其結構的本質都是訊息傳播(鄰居節點根據一定的規則將特征或者資訊,注入到目標節點上,就是所謂的資訊傳遞機制),通過訊息傳遞的方式,能將節點資訊更準確的表達,將節點之間隱藏的關系資訊注入到節點當中,為下游任務提供了有效的先驗知識,通用的GNN模型擴展框架主要有3種型別分別是:訊息傳播神經網路(Message Passing Neural Network,MPNN)、非區域神經網路(Non-Local Neural Network,NLNN)、圖網路(Grap Network,GN), 之后有時間,將會總結這三種通用框架的一般形式,
參考文獻
[1] M. Schlichtkrull, T. N. Kipf, P. Bloem, R. van den Berg, I. Titov, and M. Welling, “Modeling Relational Data with Graph Convolutional Networks,” Lect. Notes Comput. Sci. (including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinformatics), vol. 10843 LNCS, no. 1, pp. 593–607, 2018.
[2] M. Schlichtkrull, T. N. Kipf, P. Bloem, R. van den Berg, I. Titov, and M. Welling, “Modeling Relational Data with Graph Convolutional Networks,” Lect. Notes Comput. Sci. (including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinformatics), vol. 10843 LNCS, no. 1, pp. 593–607, 2018.
[3] M. Schlichtkrull, T. N. Kipf, P. Bloem, R. van den Berg, I. Titov, and M. Welling, “Modeling Relational Data with Graph Convolutional Networks,” Lect. Notes Comput. Sci. (including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinformatics), vol. 10843 LNCS, no. 1, pp. 593–607, 2018.
[4] 《深入淺出圖神經網路:GNN原理決議》劉忠雨,李彥霖,周洋, 機械工業出版社
[5] CSDN博客:GraphSAGE:Inductive Representation Learning on Large Graphs 論文詳解 NIPS 2017
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/208962.html
標籤:其他
上一篇:python3.9下錯誤,pip安裝matplotlib卡在Building wheel for matplotlib (setup.py)..不動的原因與解決