2017的經典論文,Learning without Forgetting(LwF),在多篇論文中被用作實驗比較的經典演算法,作者認為Fine Tuning / Duplicating and Fine Tuning / Feature Extraction / Joint Training這幾種基于修改引數的演算法均存在性能或效率不高的問題,實驗證明,作者提出的LwF演算法可以克服上述演算法的不足,

LwF實作增量學習的核心是對引數的更新方法,文章介紹并比較了幾種經典增量學習的演算法Fine Tuning / Duplicating and Fine Tuning / Feature Extraction / Joint Training,如圖:
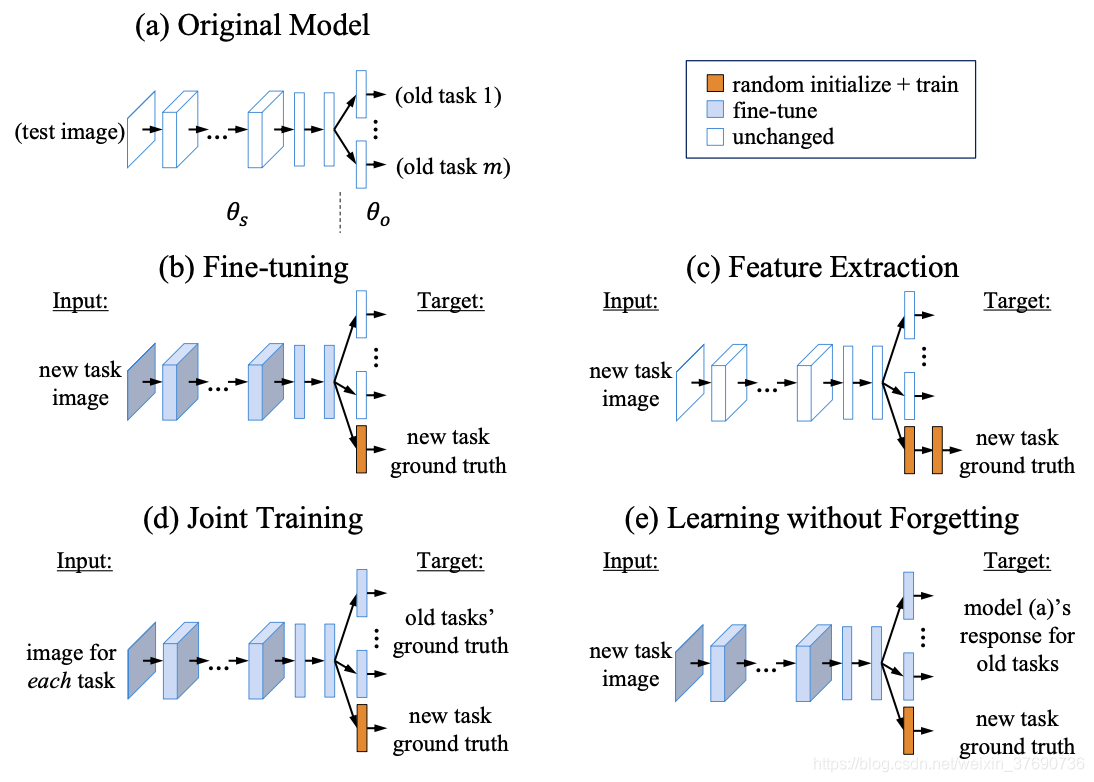
- 以CNN模型為例,圖中
代表卷積層和全連接層的共享引數,
代表先前學習的任務的特定引數,
代表新任務的特定引數,
- (a)代表無增量學習能力的原始模型,所有的引數均不會更新,
- (b)代表微調演算法,在增量學習階段,
- (c)代表特征提取演算法,在增量學習階段,
- (d)代表聯合訓練演算法,在增量學習階段,聯合優化
- (e)代表作者提出的LwF演算法,在增量學習階段,先用
LwF演算法偽代碼如下:

和
代表新資料的值和標簽,
- 初始階段:模型用舊的
,同時隨機初始化代表新任務的特定引數
- 增量階段是一個重復多次直至Loss函式最小的程序,期間使用
,使用
,
LwF與聯合訓練(Joint learning)的異同:
聯合訓練需要用到舊任務的資料和標簽,而LwF使用新資料和上一次模型的預測輸出
,
實驗中,增量資料采用不同的資料集,LwF對新類別資料的分類準確率較高且能克服舊類別資料災難性遺忘問題,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/209601.html
標籤:AI
下一篇:如何做好技術型銷售