排序演算法千千萬萬, 重新復習一下.
排序演算法使用的情況非常多, 而且大部分情況不只是對數字(int, float, double等)進行排序, 而是通過斷言(Predicate)進行元素排序, 比如字符陣列按照頭文字的英文順序排序之類的, 就需要使用比較排序才能進行, 所以我們看到的常用演算法都是比較排序的.
比較排序就是根據兩個元素的對比, 獲得回傳來決定重排的順序, 大部分語言提供的排序都有斷言, 比如C#的:
var list = new System.Collections.Generic.List<int>(); list.Sort((_l, _r) => { if(_l > _r) { return 1; } if(_l < _r) { return -1; } return 0; });
或者Lua的:
local compare_func = function(v1, v2) return v1 < v2 end local t = {} table.sort(t, compare_func);
下面看看幾種常用排序演算法:
一. 選擇排序. 原理就像體育課排隊一樣, 小朋友亂站成一排, 從中找到最矮的叫他站到排頭, 再從排頭之外找出最矮的站到第二位置, 以此類推. 代碼如下:
/// <summary> /// 選擇排序 /// </summary> /// <param name="array"></param> public static void SelectSort_BigEnd(int[] array) { for(int i = 0; i < array.Length; i++) { int minVal = array[i]; int minIndex = i; for(int j = i + 1; j < array.Length; j++) { int compareValue =https://www.cnblogs.com/tiancaiwrk/p/ array[j]; if(minVal > compareValue) { minIndex = j; minVal = compareValue; } } if(minIndex != i) { array[minIndex] = array[i]; array[i] = minVal; } } }
復雜度啊什么的, 一般演算法都沒有突破O(n2), 都差不多, 之所以它們是常用演算法, 是因為它不使用額外記憶體, 也不進行大量記憶體移動操作, 很簡單就能實作排序, 多快好省.
像這樣的演算法, 就可以擴展成為通用演算法了, 試試把它改成泛型的:
/// <summary> /// 選擇排序 -- 泛型版本 /// </summary> /// <typeparam name="T"></typeparam> /// <param name="array"></param> /// <param name="predicate"></param> public static void SelectSort<T>(T[] array, System.Func<T, T, int> predicate) { if(predicate != null) { for(int i = 0; i < array.Length; i++) { var baseVal = array[i]; int baseIndex = i; for(int j = i + 1; j < array.Length; j++) { var compareValue =https://www.cnblogs.com/tiancaiwrk/p/ array[j]; int compareResult = predicate.Invoke(baseVal, compareValue); if(compareResult > 0) { baseIndex = j; baseVal = compareValue; } } if(baseIndex != i) { array[baseIndex] = array[i]; array[i] = baseVal; } } } }
因為語意而調整了一些變數的名稱, 并且修改了比較的方法, 通過斷言來進行比較, 跟List的比較方法已經差不多了, 這個函式不一定是正確的, 只是說明這種排序可以成為泛型排序使用.
測驗一下:
// 加個列印Log方便看 public static void PrintArray<T>(this T[] array) { string info = "{ "; for(int i = 0; i < array.Length; i++) { info += ((array[i]) + ","); } info += " }"; UnityEngine.Debug.Log(info); } // 呼叫 var array = new int[] { 5, 2, 3, 4, 1, 6 }; SelectSort<int>(array, (_l, _r) => { if(_l > _r) { return 1; } if(_l < _r) { return -1; } return 0; }); array.PrintArray();
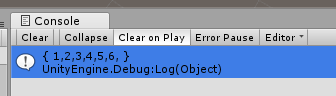
正確排序了, 把順序反一下看看:
// 呼叫 var array = new int[] { 5, 2, 3, 4, 1, 6 }; SelectSort<int>(array, (_l, _r) => { if(_l > _r) { return -1; } // 反了 if(_l < _r) { return 1; } // 反了 return 0; }); array.PrintArray();
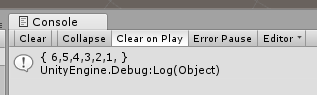
恩, 正確. 接下來幾個都是比較排序演算法, 跟這個差不多.
二. 插入排序. 插入排序就像打撲克牌, 摸完牌之后把最右邊的一張牌放到最左邊作為一個新陣列, 一直繼續這個程序, 把最右邊的牌按大小插入左邊那組牌中, 直到插完. 代碼如下:
/// <summary> /// 插入排序 /// </summary> /// <param name="array"></param> public static void InsterSort_BigEnd(int[] array) { int tailIndex = array.Length - 1; for(int i = 1; i < array.Length; i++) { var insertValue =https://www.cnblogs.com/tiancaiwrk/p/ array[tailIndex]; int insertIndex = i; for(int j = 0; j < i; j++) { if(array[j] > insertValue) { insertIndex = j; break; } } array[tailIndex] = array[i]; // 末尾元素交換 for(int index = i; index > insertIndex; index--) { array[index] = array[index - 1]; // 已經排序的段位移 } array[insertIndex] = insertValue; } }
它也是不需要額外記憶體的, 只進行元素交換就行了. 這個[插入排序]和前面的[選擇排序]就是很典型的兩個對比:
1. 從進行元素對比的數量來看, [選擇排序]從開始到結束, 每次對比的數量是越來越少的, 因為無序陣列中元素越來越少, 只選無序陣列最小的加到有序陣列的后面即可. 而插入排序需要進行的對比是越來越多的, 因為從無序陣列選擇一個元素, 插入到有序陣列里面, 有序陣列元素越來越多, 插入就需要對比越來越多, 可是因為有序陣列不一定需要所有元素都進行對比(看代碼, 當找到插入位置時就break了, 與原始序列相關), 所以元素對比數量來看[插入排序]占優.
[選擇排序] = [(n-1) + (n-2) + (n-3) +.....1] 次的對比, 約為n2/2次, 固定次數
[插入排序] Max = [選擇排序 : n2/2次] , Min = [n] 次的對比, 在對比數量上可能比[選擇排序]更快
2. 從記憶體移動的數量來看, [選擇排序]只需要最小的記憶體移動即可完成排序, 因為只需要把元素插入有序佇列的末尾即可, 而[插入排序]因為要維持有序佇列的順序, 可能進行大量的記憶體移動, 從記憶體移動的角度來看[選擇排序]占優.
[選擇排序] Min = [0] , Max = 2n 次的記憶體移動, 移動次數上比[插入排序]占優
[插入排序] Min =[選擇排序 : 2n次], Max = [2n + [(n-1) + (n-2) + (n-3) +.....1]] => [2n + n2/2] 次的記憶體移動
單從這兩方面來看, 它就很有代表性了, 一個是資料對比方面有優勢, 一個是在記憶體移動方面有優勢, 這就要根據使用環境來選擇了, 如果兩個元素的對比很耗費時間的話(比如字串的對比), 使用[插入排序]比較有優勢, 簡單的對比的話[選擇排序]有優勢.
我們一般的程式對性能不是很敏感的話, 對它們的差別不用很糾結, 系統自帶的就行了, 真正用到的地方可能就是各種壓榨性能的單片機了, 軍方之類的.
三. 冒泡排序. 出鏡率最高的排序演算法, 哪哪都能看到, 原理就是通過相鄰元素對比, 把大的放到右邊, 最大的數就會像水里的氣泡一樣慢慢移動到末尾, 然后再來N次, 就能把所有元素按照順序排列了. 代碼如下:
/// <summary> /// 冒泡排序 /// </summary> public static void BuddleSort_BigEnd(int[] array) { for(int i = 0, imax = array.Length - 1; i < imax; i++) { int jmax = array.Length - i; for(int j = 1; j < jmax; j++) { var lVal = array[j - 1]; var rVal = array[j]; if(lVal > rVal) { array[j - 1] = rVal; array[j] = lVal; } } } }
代碼之簡單, 所以才成了天天拿出來說的演算法了吧, 整理一下邏輯, 看看第二重回圈里面, 就是從左往右, 把大的數放在右邊, 這樣回圈完一次之后, 陣列中最大的數就被放在陣列的末尾了, 其實跟[選擇排序]是有點像的, 可是它又進行了多次記憶體移動, 這也有[插入排序]的影子, 其實它簡單的代碼包含了兩種演算法的優缺點, 在每次內回圈之后也等于對原有陣列進行了更接近正確排序的操作, 這樣經過N次回圈之后就能得到正確陣列了.
PS: 其實并不一定需要這么多次外回圈才能得到正確陣列, 因為每次回圈都進行了排序, 在不同情況下需要的回圈次數不同, 這就保證了記憶體移動的開銷, 可是沒有辦法減少無用的資料比較程序, 如果有一個檢測機制檢測什么時候陣列已經全排好了, 是可以提升性能的, 比如這樣:
public static void BuddleSort_BigEnd_CheckFunc(int[] array, int minSortCount, System.Func<int[], bool> succCheckFunc) { for(int i = 0, imax = array.Length - 1; i < imax; i++) { int jmax = array.Length - i; for(int j = 1; j < jmax; j++) { var lVal = array[j - 1]; var rVal = array[j]; if(lVal > rVal) { array[j - 1] = rVal; array[j] = lVal; } } if((i + 1) >= minSortCount) { if(succCheckFunc.Invoke(array)) { UnityEngine.Debug.Log("應該回圈 " + imax + "次"); UnityEngine.Debug.Log("退出回圈時已經回圈 " + (i + 1) + "次"); return; } } } }
在上面添加了一個超過minSortCount回圈次數之后進行順序檢測的邏輯, 如果陣列已經是正確順序了, 就退出回圈. 測驗代碼如下:
int[] array = new int[] { 5, 2, 3, 4, 1, 6, 2 }; BuddleSort_BigEnd_CheckFunc(array, 3, (_array) => { for(int i = _array.Length - 1; i >= 0; i--) { var maxVal = _array[i]; for(int j = 0; j < i; j++) { if(array[j] > maxVal) { return false; } } } return true; }); array.PrintArray();
輸出資訊表示跳出了回圈, 并且順序是對的.
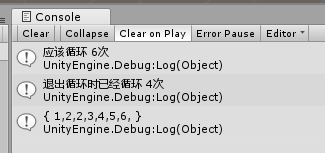
只不過檢測陣列是否正確排序的方法效率很低, 不如繼續運行冒泡排序剩下的回圈程序, 因為它的比較程序也跟選擇演算法一樣, 越到后面回圈里的比較數量越少, 所以也是"理論上可以優化"的演算法.
四. 希爾排序. 是從插入排序衍生出來的, 插入排序是它的一個特殊形式, 帶有點玄學或者統計學的味道, 原理就跟插入排序一樣:
選取一個數N作為間隔, 在原陣列中每隔N個數取出來, 組成一個陣列(0, N, 2N......)|(1, N+1, 2N+1....), 這樣可以分出N個陣列來使用插入排序, 再進行劃分(比如N/2間隔), 讓陣列有交叉資料, 這樣多次劃分之后最后N=1還是會走到最初的插入排序那一步. 所以有點玄學的成分, 因為N=1就是插入排序...
代碼如下:
/// <summary> /// 希爾排序 -- 縮小增量排序, 通過間隔取陣列排序, 間隔越來越小 /// </summary> /// <param name="array"></param> public static void ShellSort_BigEnd(int[] array) { int gap = (array.Length >> 1); while(gap > 0) { int begin = 0; while(begin < gap) { var endIndex = (array.Length - 1) - ((array.Length - 1 - begin) % gap); for(int i = begin + gap; i <= endIndex; i += gap) { var insertValue = https://www.cnblogs.com/tiancaiwrk/p/array[endIndex]; // 插入排序, 只取最后一個即可 int insertIndex = i; for(int j = begin; j < i; j += gap) { if(array[j] > insertValue) { insertIndex = j; break; } } array[endIndex] = array[i]; for(int index = i; index > insertIndex; index -= gap) { array[index] = array[index - gap]; } array[insertIndex] = insertValue; } begin++; } gap = (gap >> 1); } }
單從計算量來看, 如果一個陣列長度為10, 那么根據劃分, 第一個會劃分出gap=5的5個陣列, 第二次gap=2的兩個陣列, 和最后gap=1的原始陣列, 并且代碼中的[插入排序]不僅有比較, 還有每次內回圈至少2次的記憶體移動, 這是演算法決定的, 代碼怎樣優化都沒有辦法避免. 從時間復雜度上來看理論上為 n3/2 , 可是那是理論, 也就是說數學統計上來說它從開始到到達正確陣列的時間會比上面的排序短一些, 不過就像上面[冒泡排序]中說的, 代碼上沒有可以快速判斷陣列是否已經順序正確的檢測方法, 你必須運行完所有程序才能回傳正確結果, 所以從執行效率上來說[希爾排序]還是有玄學的成分的(幾乎可以說效率堪憂). 這就是為什么它沒有像[冒泡排序]這樣哪哪都是.
五. 快速排序. 它的原理是二分法, 先從陣列中選擇一個元素, 然后其他元素跟它做對比, 小的放左邊, 大的放右邊, 然后繼續在分出來的陣列中進行快速排序, 以此類推就能實作陣列排序了. 快速排序是一個很有優化潛力的排序方法, 可以通過良好的代碼免去使用額外的記憶體, 減少資料移動量, 演算法邏輯上資料比較的量也較少. 代碼如下:
/// <summary> /// 快速排序 /// </summary> /// <param name="array"></param> public static void QuickSort_BigEnd(int[] array) { QuickSort_BigEnd_Wrap(array, 0, array.Length - 1); } /// <summary> /// 快速排序封裝 /// </summary> /// <param name="array"></param> /// <param name="left"></param> /// <param name="right"></param> private static void QuickSort_BigEnd_Wrap(int[] array, int left, int right) { if(left < right) { var partitionIndex = QuickSort_BigEnd_Partition(array, left, right); QuickSort_BigEnd_Wrap(array, left, partitionIndex - 1); QuickSort_BigEnd_Wrap(array, partitionIndex + 1, right); } } /// <summary> /// 快速排序的磁區操作磁區操作 -- array[pivot]作為中位數, 左邊為小于它的, 右邊為大于它的, 二分法排序 /// </summary> /// <param name="array"></param> /// <param name="left"></param> /// <param name="right"></param> private static int QuickSort_BigEnd_Partition(int[] array, int left, int right) { var pivot = left; var index = pivot + 1; for(int i = index; i <= right; i++) { var iVal = array[i]; if(iVal < array[pivot]) { array[i] = array[index]; array[index] = iVal; index++; } } var tempVal = array[pivot]; array[pivot] = array[index - 1]; array[index - 1] = tempVal; return (index - 1); }
代碼仍然可以優化, 這樣的寫法已經能表達出快速排序的效果了, 它的比較數量級雖然沒有太大變化, 不過確實比其他演算法少 [(n-1) + (n-1-2) + (n1-2-4) + (n-1-2-4-8)......] 減少量是2次冪上升的, 要比[(n-1) + (n-2) + (n-3)......]要好很多, 特別是在大量資料的時候.
六. 堆排序. 利用的是堆的概念, 看起來就像是一個二叉樹那樣的, 并且只需要保證堆的子節點小于主節點即可, 原理就是建立堆模型, 然后每次回圈都能把最大的數放到堆頂, 就和[冒泡排序]原理差不多. 代碼如下:
/// <summary> /// 堆排序 /// </summary> /// <param name="array"></param> public static void HeapSort_BigEnd(int[] array) { var heapLen = array.Length; // 建立分堆 -- 前半陣列中每個都大于后半陣列, 最大的數在堆頂 for(int i = (array.Length >> 1); i >= 0; i--) { Heapify(array, i, heapLen); } // 取出堆頂的數, 放到最后, 繼續調整堆使最大數在堆頂 for(int i = array.Length - 1; i > 0; i--) { var temp = array[0]; array[0] = array[i]; array[i] = temp; heapLen--; Heapify(array, 0, heapLen); } } /// <summary> /// 堆調整 /// </summary> /// <param name="array"></param> /// <param name="i"> 最大Index </param> private static void Heapify(int[] array, int i, int heapLen) { int left = 2 * i + 1; int right = 2 * i + 2; int largest = i; if(left < heapLen) { if(array[left] > array[largest]) { largest = left; } } if(right < heapLen) { if(array[right] > array[largest]) { largest = right; } } if(largest != i) { var temp = array[i]; array[i] = array[largest]; array[largest] = temp; Heapify(array, largest, heapLen); } }
先看Heapify邏輯, 它就是一個堆邏輯, 首先傳入陣列以及堆頂的index=>i, 然后他的子節點左右被計算出來, 然后對比哪個最大就放到 i 的位置, 這樣 i 就是父節點, left, right就是它的子節點, 然后如果被置換的子節點發生了變動(largest != i){ ... }, 那么largest這個節點下面的子節點也要重新計算, 這就是Heapify遞回呼叫的原因. 這樣就能保證所有變動都能觸發子堆的排列正確性.
而這些堆在邏輯上的關聯性就是Heapify中定義左右子節點的邏輯, int left = 2*i +1; int right = 2*i+2; 這樣關聯起來的, 因為理解比較麻煩這里打幾個Log來看看一個陣列的堆的關聯性:
int[] a = new int[11]; for(int i = 0; i < (a.Length >> 1); i++) { Debug.Log("Index:" + i + " left:" + (i * 2 + 1) + " right:" + (i * 2 + 2)); }
這是長度11的陣列, 那么根據關聯性得到的堆如下:
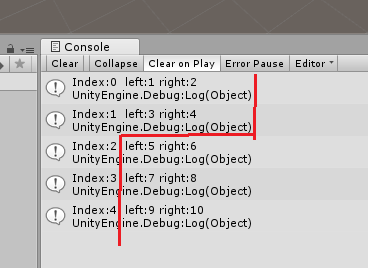
可以看到如果按照反序進行堆排序的話, 把陣列看成兩段[0-4] [5-10] 先從Index:4 left:9 right:10 開始第一個堆, 那么最大的數被放到Index=4中, 然后是Index=3, 依次類推到Index2執行完之后 Index2, Index3, Index4存盤的其中 一個就是后半段陣列中最大的值了, 然后通過Index:1 就得到[1,3,4]中最大的值了, 然后Index:0 得到[0,1,2] 中的最大值, 所以就像冒泡一樣把最大值推到了Index=0的位置, 就是這段代碼的功能:
for(int i = (array.Length >> 1); i >= 0; i--) { Heapify(array, i, heapLen); }
然后取出Index:0的數, 放在陣列末尾, 再進行類似的堆排序, 就能一個個得到最大的數了. 這樣通過很巧妙的堆關聯實作了堆排序.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/21068.html
標籤:其他
上一篇:中國能不能制作AAA游戲?
下一篇:202003告別艱難的第一季度