編碼知識
一、Unicode與多位元組(ANSI )
(1)Windows中,Unicode也稱為寬位元組,多位元組也稱為窄位元組; VS中默認使用Unicode編碼,在專案屬性>>配置屬性>>常規>>字符集中可選擇Unicode字符集或者多位元組字符集
(2) Unicode與多位元組函式版本、字符、字串型別的區別
Win32 API中大部分引數有字串的函式都有兩個版本
| 以A結尾,代表多位元組版本 | 以W結尾,代表Unicode版本 | 根據版本自動選擇的 |
|---|---|---|
| 如:CreateEventA | 如:CreateEventW | 如:CreateEvent |
C運行庫也有很多類似的函式
| 多位元組版本 | Unicode版本 | 自適應版本 |
|---|---|---|
| strcpy | wcscpy | _tcscpy |
| strcat | wcscat | _tscscat |
| strlen | wcslen | _tcslen |
函式有兩種,所以字符也有兩種
| 多位元組字符 | Unicode字符 | 自適應字符 |
|---|---|---|
| char | wchar_t | TCHAR |
(3) 常見Win32字串型別
LPSTR、LPWSTR、LPTSTR、LPCTSTR
LP前綴,代表指標;STR后綴代表字串
LPSTR:代表多位元組
LPWSTR:代表Unicode
LPTSTR:T自適應
LPCTSTR:C代表const+T代表自適應
備注:變數型別使用自適應型別后如LPTSTR,相關字串需要用TEXT()進行包裹
const char* str = "hello";
const wchar_t* wstr = L"hello";
const TCHAR* tstr = TEXT("hello");
(4)關于_T()
#ifdef _UNICODE
#define _T(X) L ## X //Unicode版本
#else
#define _T(X) X //多位元組版本
#endif
(5)Unicode與多位元組的選擇
1.Unicode程式環境適應能力強,不會出現亂碼問題
2.Unicode程式運行速度比多位元組程式快,原因:Windows內部都是使用Unicode編碼,多位元組函式會將引數轉碼后交給Unicode函式
3.控制后臺可使用多位元組,GUI程式最好使用Unicode
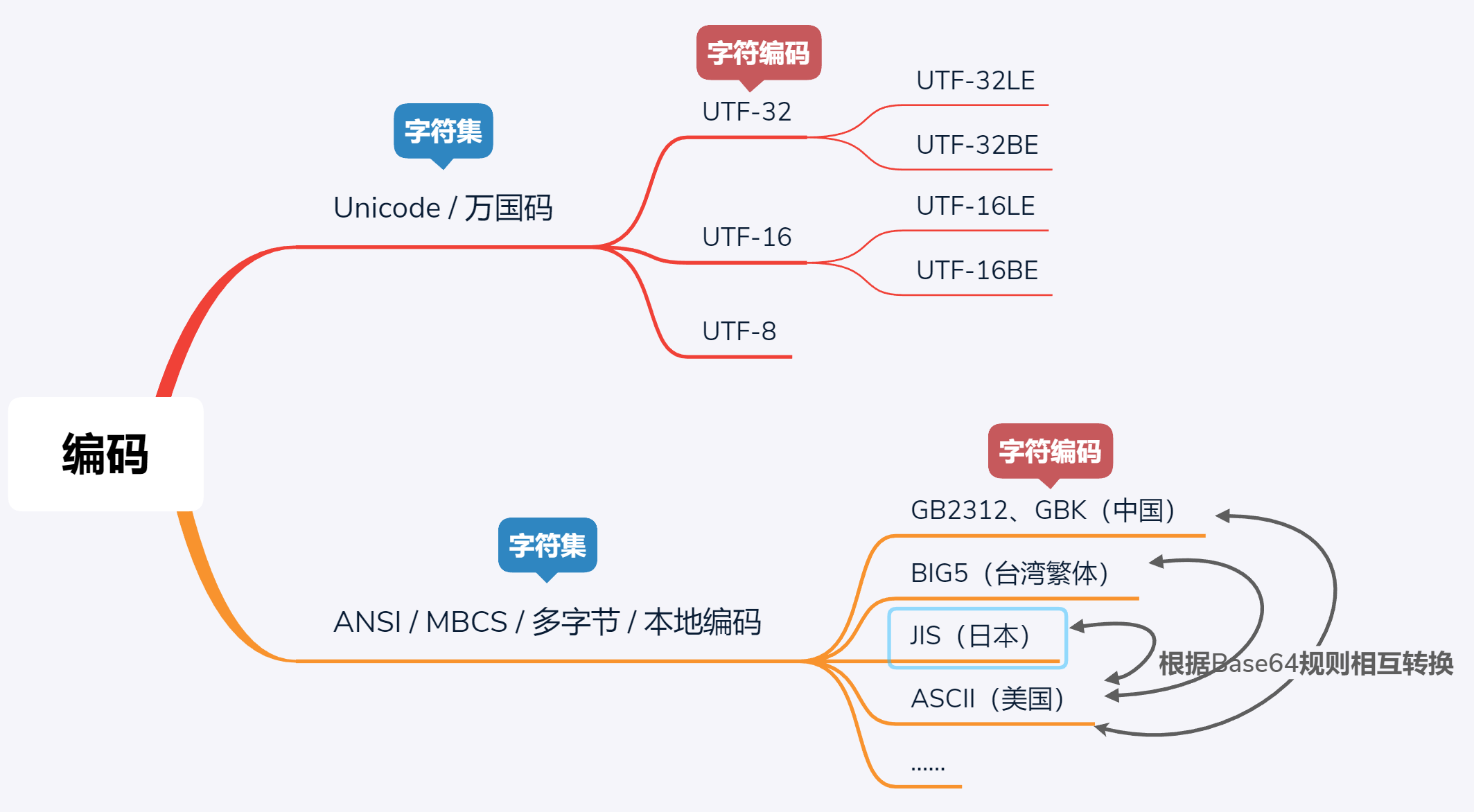
二、Unicode
(1)Unicode實作方式:UTF-32
以4個byte為編碼單元進行定長存盤,調度器一次性下發4個byte進行存盤任務
主要有兩種方式:
大端法UTF-32BE:地址由小向大增加,而資料從高位往低位放 ,在網路上傳輸資料普遍采用的都是大端
小端法UTF-32LE:地址由小向大增加,而資料從低位往高位放,在英特爾處理器,Windows10作業系統,采用小端法,

(2)UTF-16
也有大小端模式
UTF-16 LE是windows上默認的Unicode編碼方式,使用wchar_t表示,所有wchar_t *型別的字串(包括硬編碼在.h/.cpp里的字串字面值)
char chinese[] = "你";
//大小為3個byte,一個char存盤結束符,兩個char存盤漢字字符‘你’ 1char:1byte
wchar_t wchinese[] = L"你";
//大小為4個byte, 一個wchar_t存盤結束符,一個wchar_t存盤漢字字符‘你’ 1wchar_t:2byte(window下)
auto size = sizeof(chinese); // 3 byte
auto wsize = sizeof(wchinese); // 4 byte
auto len = strlen(chinese); // 2個字符(除去結束符)
auto wlen = wcslen(wchinese); // 1個字符(除去結束符)
優勢:就是大多數情況下一個wchar_t表示一個字符(包括中文字符)
坑:char *型別的字面值,最終記憶體使用何種編碼方式完全取決于當前檔案的編碼方式
備注:在Windows上應該銘記沒有char / std::string這種型別的字符/字串,只有wchar_t / char16_t / std::wstring / std::u16string
(3)UTF-8
優勢:無位元組序的概念,不用考慮大小端問題,適用與字串的網路資料傳輸
劣勢:如上代碼,一個char并不能表示一個漢字字符,往往需要兩個char
三、ANSI
(1)概念
可以認為ANSI / MBCS (多位元組字符集) / 本地編碼是同一個概念,不同的國家和地區制定了不同的標準,有GB2312、GBK、GB18030、Big5、Shift_JIS 等各自的編碼標準,ASCII就是美國國家的ANSI標準,一個國家的代碼到另一個國家使用,有可能由于編碼標準不一致,導致亂碼,于是才有了萬國碼Unicode,各國通用,
總結
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/21141.html
標籤:其他
上一篇:書單