作者|Louis Teo
編譯|VK
來源|Towards Data Science
你有沒有讀過很多的報告,而你只想對每個報告做一個快速的總結摘要?你是否曾經遇到過這樣的情況?
摘要已成為21世紀解決資料問題的一種非常有幫助的方法,在本篇文章中,我將向你展示如何使用Python中的自然語言處理(NLP)創建個人文本摘要生成器,
前言:個人文本摘要器不難創建——初學者可以輕松做到!
什么是文本摘要
基本上,在保持關鍵資訊的同時,生成準確的摘要,而不失去整體意義,這是一項任務,
摘要有兩種一般型別:
- 抽象摘要>>從原文中生成新句子,
- 提取摘要>>識別重要句子,并使用這些句子創建摘要,
應該使用哪種總結方法
我使用提取摘要,因為我可以將此方法應用于許多檔案,而不必執行大量(令人畏懼)的機器學習模型訓練任務,
此外,提取摘要法比抽象摘要具有更好的總結效果,因為抽象摘要必須從原文中生成新的句子,這是一種比資料驅動的方法提取重要句子更困難的方法,
如何創建自己的文本摘要器
我們將使用單詞直方圖來對句子的重要性進行排序,然后創建一個總結,這樣做的好處是,你不需要訓練你的模型來將其用于檔案,
文本摘要作業流
下面是我們將要遵循的作業流…
匯入文本>>>>清理文本并拆分成句子>>洗掉停用詞>>構建單詞直方圖>>排名句子>>選擇前N個句子進行提取摘要
(1) 示例文本
我用了一篇新聞文章的文本,標題是蘋果以5000萬美元收購AI初創公司,以推進其應用程式,你可以在這里找到原始的新聞文章:https://analyticsindiamag.com/apple-acquires-ai-startup-for-50-million-to-advance-its-apps/
你還可以從我的Github下載文本檔案:https://github.com/louisteo9/personal-text-summarizer
(2) 匯入庫
# 自然語言工具包(NLTK)
import nltk
nltk.download('stopwords')
# 文本預處理的正則運算式
import re
# 佇列演算法求首句
import heapq
# 數值計算的NumPy
import numpy as np
# 用于創建資料幀的pandas
import pandas as pd
# matplotlib繪圖
from matplotlib import pyplot as plt
%matplotlib inline
(3) 匯入文本并執行預處理
有很多方法可以做到,這里的目標是有一個干凈的文本,我們可以輸入到我們的模型中,
# 加載文本檔案
with open('Apple_Acquires_AI_Startup.txt', 'r') as f:
file_data = https://www.cnblogs.com/panchuangai/p/f.read()
這里,我們使用正則運算式來進行文本預處理,我們將
(A)用空格(如果有的話…)替換參考編號,即[1]、[10]、[20],
(B)用單個空格替換一個或多個空格,
text = file_data
# 如果有,請用空格替換
text = re.sub(r'\[[0-9]*\]',' ',text)
# 用單個空格替換一個或多個空格
text = re.sub(r'\s+',' ',text)
然后,我們用小寫(不帶特殊字符、數字和額外空格)形成一個干凈的文本,并將其分割成單個單詞,用于詞組分數計算和構詞直方圖,
形成一個干凈文本的原因是,演算法不會把“理解”和“理解”作為兩個不同的詞來處理,
# 將所有大寫字符轉換為小寫字符
clean_text = text.lower()
# 用空格替換[a-zA-Z0-9]以外的字符
clean_text = re.sub(r'\W',' ',clean_text)
# 用空格替換數字
clean_text = re.sub(r'\d',' ',clean_text)
# 用單個空格替換一個或多個空格
clean_text = re.sub(r'\s+',' ',clean_text)
(4) 將文本拆分為句子
我們使用NLTK sent_tokenize方法將文本拆分為句子,我們將評估每一句話的重要性,然后決定是否應該將每一句都包含在總結中,
sentences = nltk.sent_tokenize(text)
(5) 洗掉停用詞
停用詞是指不給句子增加太多意義的英語單詞,他們可以安全地被忽略,而不犧牲句子的意義,我們已經下載了一個檔案,其中包含英文停用詞
這里,我們將得到停用詞的串列,并將它們存盤在stop_word 變數中,
# 獲取停用詞串列
stop_words = nltk.corpus.stopwords.words('english')
(6) 構建直方圖
讓我們根據每個單詞在整個文本中出現的次數來評估每個單詞的重要性,
我們將通過(1)將單詞拆分為干凈的文本,(2)洗掉停用詞,然后(3)檢查文本中每個單詞的頻率,
# 創建空字典以容納單詞計數
word_count = {}
# 回圈遍歷標記化的單詞,洗掉停用單詞并將單詞計數保存到字典中
for word in nltk.word_tokenize(clean_text):
# remove stop words
if word not in stop_words:
# 將字數保存到詞典
if word not in word_count.keys():
word_count[word] = 1
else:
word_count[word] += 1
讓我們繪制單詞直方圖并查看結果,
plt.figure(figsize=(16,10))
plt.xticks(rotation = 90)
plt.bar(word_count.keys(), word_count.values())
plt.show()
讓我們把它轉換成橫條圖,只顯示前20個單詞,下面有一個helper函式,
# helper 函式,用于繪制最上面的單詞,
def plot_top_words(word_count_dict, show_top_n=20):
word_count_table = pd.DataFrame.from_dict(word_count_dict, orient = 'index').rename(columns={0: 'score'})
word_count_table.sort_values(by='score').tail(show_top_n).plot(kind='barh', figsize=(10,10))
plt.show()
讓我們展示前20個單詞,
plot_top_words(word_count, 20)
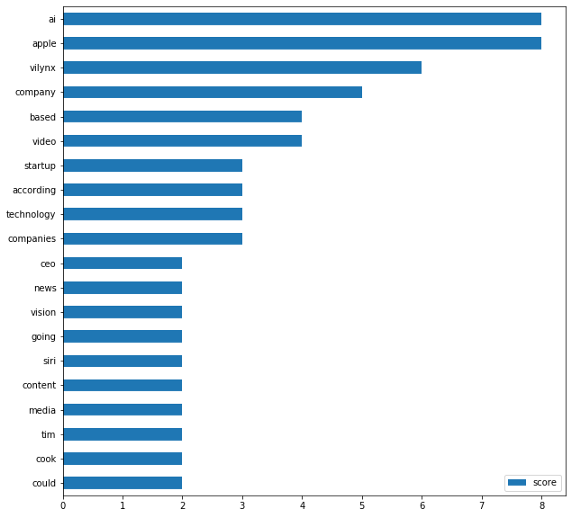
從上面的圖中,我們可以看到“ai”和“apple”兩個詞出現在頂部,這是有道理的,因為這篇文章是關于蘋果收購一家人工智能初創公司的,
(7) 根據分數排列句子
現在,我們將根據句子得分對每個句子的重要性進行排序,我們將:
-
洗掉超過30個單詞的句子,認識到長句未必總是有意義的;
-
然后,從構成句子的每個單詞中加上分數,形成句子分數,
高分的句子將排在前面,前面的句子將形成我們的總結,
注意:根據我的經驗,任何25到30個單詞都可以給你一個很好的總結,
# 創建空字典來存盤句子分數
sentence_score = {}
# 回圈通過標記化的句子,只取少于30個單詞的句子,然后加上單詞分數來形成句子分數
for sentence in sentences:
# 檢查句子中的單詞是否在字數字典中
for word in nltk.word_tokenize(sentence.lower()):
if word in word_count.keys():
# 只接受少于30個單詞的句子
if len(sentence.split(' ')) < 30:
# 把單詞分數加到句子分數上
if sentence not in sentence_score.keys():
sentence_score[sentence] = word_count[word]
else:
sentence_score[sentence] += word_count[word]
我們將句子-分數字典轉換成一個資料框,并顯示sentence_score,
注意:字典不允許根據分數對句子進行排序,因此需要將字典中存盤的資料轉換為DataFrame,
df_sentence_score = pd.DataFrame.from_dict(sentence_score, orient = 'index').rename(columns={0: 'score'})
df_sentence_score.sort_values(by='score', ascending = False)

(8) 選擇前面的句子作為摘要
我們使用堆佇列演算法來選擇前3個句子,并將它們存盤在best_quences變數中,
通常3-5句話就足夠了,根據檔案的長度,可以隨意更改要顯示的最上面的句子數,
在本例中,我選擇了3,因為我們的文本相對較短,
# 展示最好的三句話作為總結
best_sentences = heapq.nlargest(3, sentence_score, key=sentence_score.get)
讓我們使用print和for loop函式顯示摘要文本,
print('SUMMARY')
print('------------------------')
# 根據原文中的句子順序顯示最上面的句子
for sentence in sentences:
if sentence in best_sentences:
print (sentence)
這是到我的Github的鏈接以獲取Jupyter筆記本,你還將找到一個可執行的Python檔案,你可以立即使用它來總結你的文本:https://github.com/louisteo9/personal-text-summarizer
讓我們看看演算法的實際操作!
以下是一篇題為“蘋果以5000萬美元收購人工智能創業公司(Apple Acquire AI Startup)以推進其應用程式”的新聞文章的原文(原文可在此處找到):https://analyticsindiamag.com/apple-acquires-ai-startup-for-50-million-to-advance-its-apps/
In an attempt to scale up its AI portfolio, Apple has acquired Spain-based AI video startup — Vilynx for approximately $50 million.
Reported by Bloomberg, the AI startup — Vilynx is headquartered in Barcelona, which is known to build software using computer vision to analyse a video’s visual, text, and audio content with the goal of “understanding” what’s in the video. This helps it categorising and tagging metadata to the videos, as well as generate automated video previews, and recommend related content to users, according to the company website.
Apple told the media that the company typically acquires smaller technology companies from time to time, and with the recent buy, the company could potentially use Vilynx’s technology to help improve a variety of apps. According to the media, Siri, search, Photos, and other apps that rely on Apple are possible candidates as are Apple TV, Music, News, to name a few that are going to be revolutionised with Vilynx’s technology.
With CEO Tim Cook’s vision of the potential of augmented reality, the company could also make use of AI-based tools like Vilynx.
The purchase will also advance Apple’s AI expertise, adding up to 50 engineers and data scientists joining from Vilynx, and the startup is going to become one of Apple’s key AI research hubs in Europe, according to the news.
Apple has made significant progress in the space of artificial intelligence over the past few months, with this purchase of UK-based Spectral Edge last December, Seattle-based Xnor.ai for $200 million and Voysis and Inductiv to help it improve Siri. With its habit of quietly purchasing smaller companies, Apple is making a mark in the AI space. In 2018, CEO Tim Cook said in an interview that the company had bought 20 companies over six months, while only six were public knowledge.
摘要如下:
SUMMARY
------------------------
In an attempt to scale up its AI portfolio, Apple has acquired Spain-based AI video startup — Vilynx for approximately $50 million.
With CEO Tim Cook’s vision of the potential of augmented reality, the company could also make use of AI-based tools like Vilynx.
With its habit of quietly purchasing smaller companies, Apple is making a mark in the AI space.
結尾
祝賀你!你已經在Python中創建了你的個人文本摘要器,我希望,摘要看起來很不錯,
原文鏈接:https://towardsdatascience.com/report-is-too-long-to-read-use-nlp-to-create-a-summary-6f5f7801d355
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/211578.html
標籤:其他
上一篇:pandas高效實作條件邏輯