本文主要介紹一些Python的正則運算式,像圖形資料庫、正則運算式等作為知識圖譜構建的基礎,還是有必要知道一下的,這幾篇博客都屬于為以后打基礎,關注專欄《知識圖譜系列》了解更多關于知識圖譜的內容~
目錄
一、簡介
二、re.match函式
2.1 函式介紹
2.2 示例
三、re.search函式
3.1 函式介紹
3.2 示例
四、檢索和替換
4.1 函式介紹
4.2 repl引數是非函式的示例
4.3 repl引數是函式的示例
五、re.compile函式
5.1 函式介紹
5.2 示例
六、findall函式
6.1 函式介紹
6.2 示例
七、re.finditer函式
7.1 函式介紹
7.2 示例
八、re.split函式
8.1 函式介紹
九、其他
9.1 正則運算式修飾符-可選標志
9.2 正則運算式模式
一、簡介
Python自1.5版本起增加了re模塊,它提供 Perl風格的正則運算式模式,正則運算式是一個特殊的字符序列,它能幫助你方便的檢查一個字串是否與某種模式匹配,re模塊使Python語言擁有全部的正則運算式功能,compile函式根據一個模式字串和可選的標志引數生成一個正則運算式物件,該物件擁有一系列方法用于正則運算式匹配和替換,re模塊也提供了與這些方法功能完全一致的函式,這些函式使用一個模式字串做為它們的第一個引數,接下來,我們來具體看一下這些函式,
二、re.match函式
2.1 函式介紹
re.match函式嘗試從字串的起始位置匹配一個模式,如果不是起始位置匹配成功的話,match()就回傳none;如果匹配成功,就回傳一個匹配的物件,其語法格式如下:
re.match(pattern, string, flags=0)相關引數說明如下:

我們可以使用group(num) 或 groups() 匹配物件函式來獲取匹配運算式,

2.2 示例
import re
if __name__ == '__main__':
test_data = "This is a test data: My name is xzw."
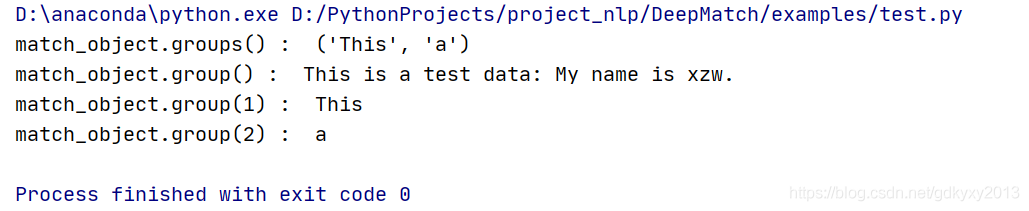
match_object = re.match(r'(.*) is (.*?) .*', test_data, re.M | re.I)
if match_object:
print("match_object.groups() : ", match_object.groups())
print("match_object.group() : ", match_object.group())
print("match_object.group(1) : ", match_object.group(1))
print("match_object.group(2) : ", match_object.group(2))
else:
print("No match!!")輸出這個結果,我們可以看到如下內容:
三、re.search函式
3.1 函式介紹
re.search函式會在字串內查找模式匹配,直到找到第一個匹配,其語法為:
re.search(pattern, string, flags=0)函式引數說明如下:

同樣的,匹配成功re.search方法回傳一個匹配的物件,否則回傳None,
3.2 示例
import re
if __name__ == '__main__':
test_data = "This is a test data: My name is xzw."
match_object = re.search( r'(.*) name (.*?) .*', test_data, re.M|re.I)
if match_object:
print("match_object.groups() : ", match_object.groups())
print("match_object.group() : ", match_object.group())
print("match_object.group(1) : ", match_object.group(1))
print("match_object.group(2) : ", match_object.group(2))
else:
print("No match!!")函式運行結果如下:

注意:re.match函式只匹配字串的開始,如果字串開始不符合正則運算式,則匹配失敗,函式回傳None;而re.search函式匹配整個字串,直到找到一個匹配,
下面來看一個例子,用來區分兩者的區別,
import re
if __name__ == '__main__':
test_data = "This is a test data: My name is xzw."
search_object = re.search(r'name', test_data, re.M | re.I)
if search_object:
print("search_object.group() : ", search_object.group())
else:
print("No search!!")
match_object = re.match(r'name', test_data, re.M | re.I)
if match_object:
print("match_object.group() : ", match_object.group())
else:
print("No match!!")輸出結果如下:

四、檢索和替換
4.1 函式介紹
re.sub函式用于替換字串中的匹配項,其語法如下:
re.sub(pattern, repl, string, max=0)其中,repl引數可以是一個函式,
4.2 repl引數是非函式的示例
import re
if __name__ == '__main__':
phone = "187-1111-1111 # 這是一個移動的電話號碼"
# 洗掉字串中的注釋內容
number = re.sub(r'#.*$', "", phone)
print("phone: ", number)
# 洗掉非數字(-)的字串
number = re.sub(r'\D', "", phone)
print("phone: ", number)運行結果為:

4.3 repl引數是函式的示例
import re
def multiply(match_num):
'''
將匹配到的數字乘以2
:param match_num: 匹配到的數字
:return: 回傳處理后的結果
'''
value = int(match_num.group('value'))
return str(value * 2)
if __name__ == '__main__':
s = '12354HFD567'
print(re.sub('(?P<value>\d+)', multiply, s))運行結果如下所示:

五、re.compile函式
5.1 函式介紹
compile函式用于編譯正則運算式,生成一個正則運算式( Pattern )物件,供 match() 和 search() 這兩個函式使用,其語法為:
re.compile(pattern[, flags])引數解釋如下:
(1)pattern: 一個字串形式的正則運算式
(2)flags: 可選,表示匹配模式,比如忽略大小寫,多行模式等,具體引數為:
re.I 忽略大小寫
re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依賴于當前環境
re.M 多行模式
re.S 即為 . 并且包括換行符在內的任意字符(. 不包括換行符)
re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依賴于Unicode字符屬性資料庫
re.X 為了增加可讀性,忽略空格和 # 后面的注釋5.2 示例
import re
if __name__ == '__main__':
pattern = re.compile(r'\d+') # 用于匹配至少一個數字
m1 = pattern.match('aaa123bbb456ccc789') # 查找頭部,沒有匹配
print(m1)
m2 = pattern.match('aaa123bbb456ccc789', 2, 10) # 從'a'的位置開始匹配,沒有匹配
print(m2)
m3 = pattern.match('aaa123bbb456ccc789', 3, 10) # 從'1'的位置開始匹配,正好匹配
print(m3)
print(m3.group(), m3.start(), m3.end(), m3.span())運行結果如下所示:

在上面的示例中,當匹配成功時回傳一個Match物件,其中:group([group1, …]) 方法用于獲得一個或多個分組匹配的字串,當要獲得整個匹配的子串時,可直接使用 group() 或 group(0);start([group]) 方法用于獲取分組匹配的子串在整個字串中的起始位置(子串第一個字符的索引),引數默認值為 0;end([group]) 方法用于獲取分組匹配的子串在整個字串中的結束位置(子串最后一個字符的索引+1),引數默認值為 0;span([group])方法回傳 (start(group), end(group)),
六、findall函式
6.1 函式介紹
在字串中找到正則運算式所匹配的所有子串,并回傳一個串列,如果沒有找到匹配的,則回傳空串列,其語法為:
findall(string[, pos[, endpos]])引數說明如下:
1、string: 待匹配的字串,
2、pos: 可選引數,指定字串的起始位置,默認為0,
3、endpos: 可選引數,指定字串的結束位置,默認為字串的長度,6.2 示例
import re
if __name__ == '__main__':
pattern = re.compile(r'\d+') # 查找數字
result1 = pattern.findall('This is a test data: My name is xzw.')
result2 = pattern.findall('dhfsa3bn45tdfs', 0, 10)
print(result1)
print(result2)運行結果如下:

七、re.finditer函式
7.1 函式介紹
和findall函式類似,在字串中找到正則運算式所匹配的所有子串,并把它們作為一個迭代器回傳,其語法為:
re.finditer(pattern, string, flags=0)7.2 示例
import re
if __name__ == '__main__':
iter = re.finditer(r"\d+", "vfdkl4teree87693n2342ln")
for match in iter:
print(match.group())運行結果如下:

八、re.split函式
8.1 函式介紹
split 方法按照能夠匹配的子串將字串分割后回傳串列,其語法如下:
re.split(pattern, string[, maxsplit=0, flags=0])其引數說明如下:

九、其他
9.1 正則運算式修飾符-可選標志
正則運算式可以包含一些可選標志修飾符來控制匹配的模式,修飾符被指定為一個可選的標志,多個標志可以通過按位 OR(|) 它們來指定,

9.2 正則運算式模式
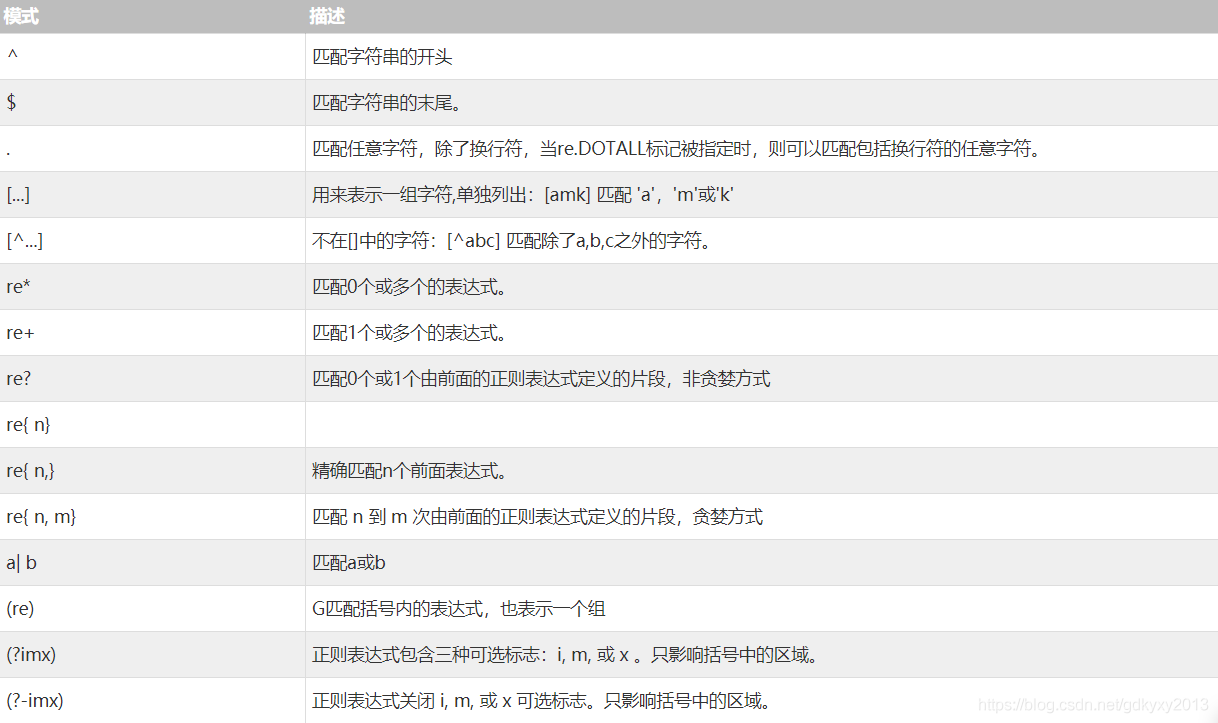
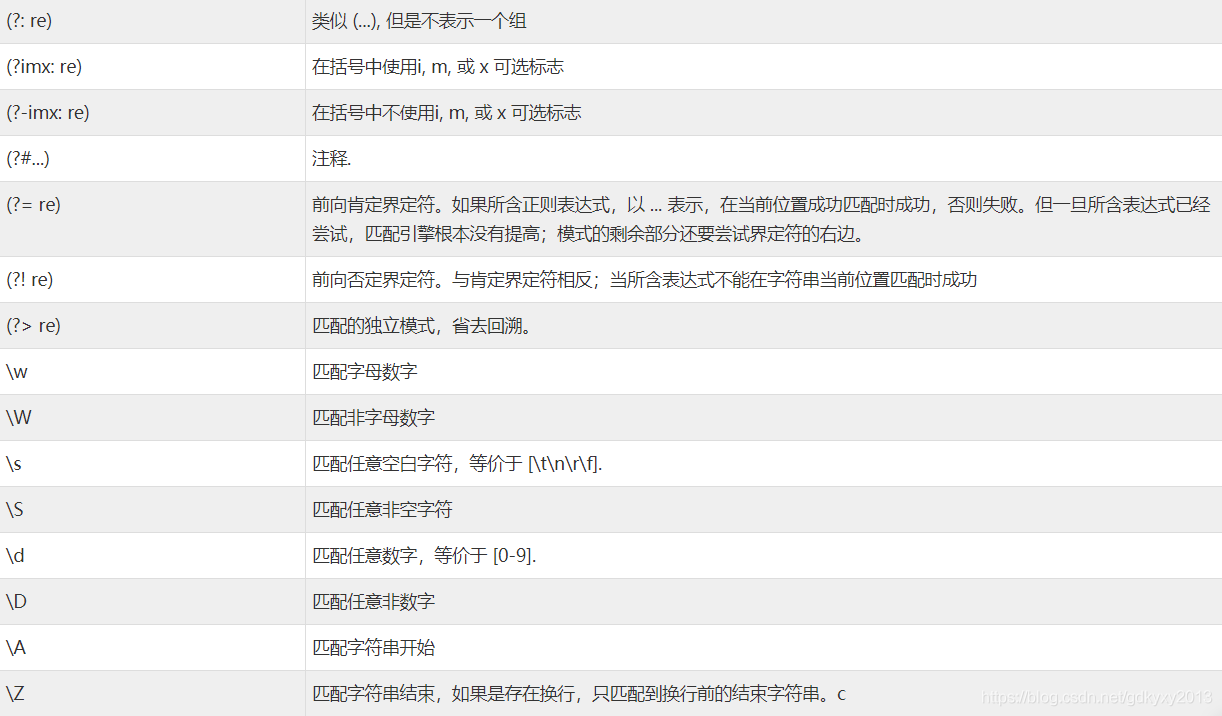
模式字串使用特殊的語法來表示一個正則運算式:字母和數字表示他們自身,一個正則運算式模式中的字母和數字匹配同樣的字串,多數字母和數字前加一個反斜杠時會擁有不同的含義,標點符號只有被轉義時才匹配自身,否則它們表示特殊的含義,反斜杠本身需要使用反斜杠轉義,由于正則運算式通常都包含反斜杠,所以最好使用原始字串來表示它們,模式元素(如 r'/t',等價于'//t')匹配相應的特殊字符,下表圖列出了正則運算式模式語法中的特殊元素,如果你使用模式的同時提供了可選的標志引數,某些模式元素的含義會改變,

本文到此已經接近尾聲了,本文主要講述了Python的正則運算式,其中參考了W3CSchool的教程,你們在此程序中遇到了什么問題,歡迎留言,讓我看看你們都遇到了什么問題~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/212838.html
標籤:其他