語法:explain select …
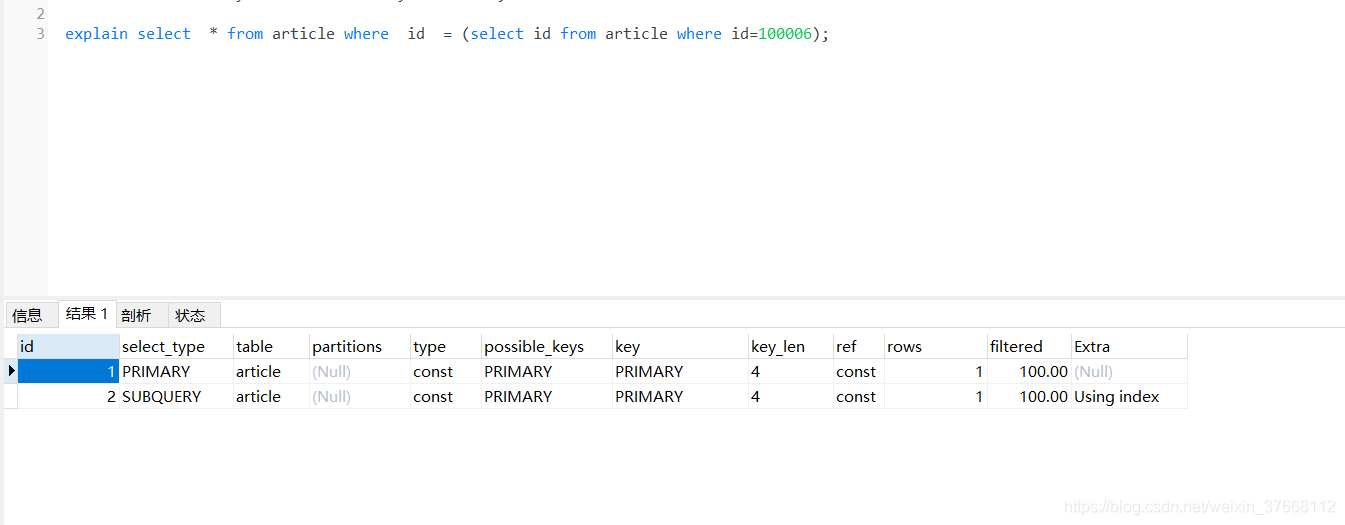
ID:SELECT識別符,id值越高,執行級別越高,如果ID相同,執行順序由上到下
SELECT_TYPE:select 陳述句的型別
常用值:
SIMPLE:簡單查詢 不涉及 join 查詢以及 子查詢
PRIMARY:主查詢或者是外層的查詢
SUBQUERY:子查詢
UNION 與 UNION RESULT:聯合查詢
TYPE(重點指標):訪問型別,表示 MYSQL在表中找到所需行的方式 ,優化最好能達到range級別 甚至是REF級別
常用值:
ALL: 全表掃描
INDEX: 遍歷整個索引樹,如果有出現回表問題 就不出現這個型別
RANGE: 使用索引 檢索 給定范圍的行,一般where 中出現 between in > <
REF:非唯一性索引掃描,索引訪問但可能回傳多個符合條件的行
EQ_REF:多表連接中 使用了 primary_key 或 unique key作為關聯條件
CONST:通過索引一次就能找到,通常是primary_key 或 unique索引列查找
SYSTEM:表中只有一條資料的查詢 NULL:
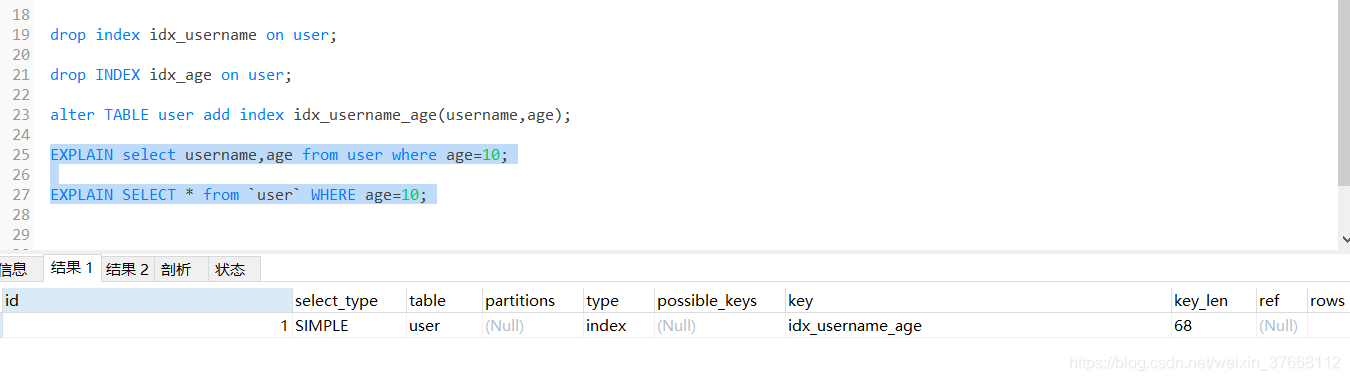

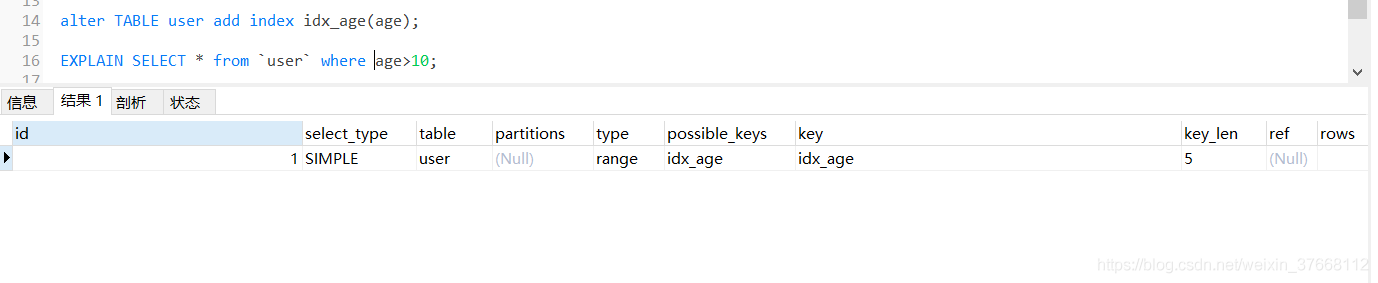
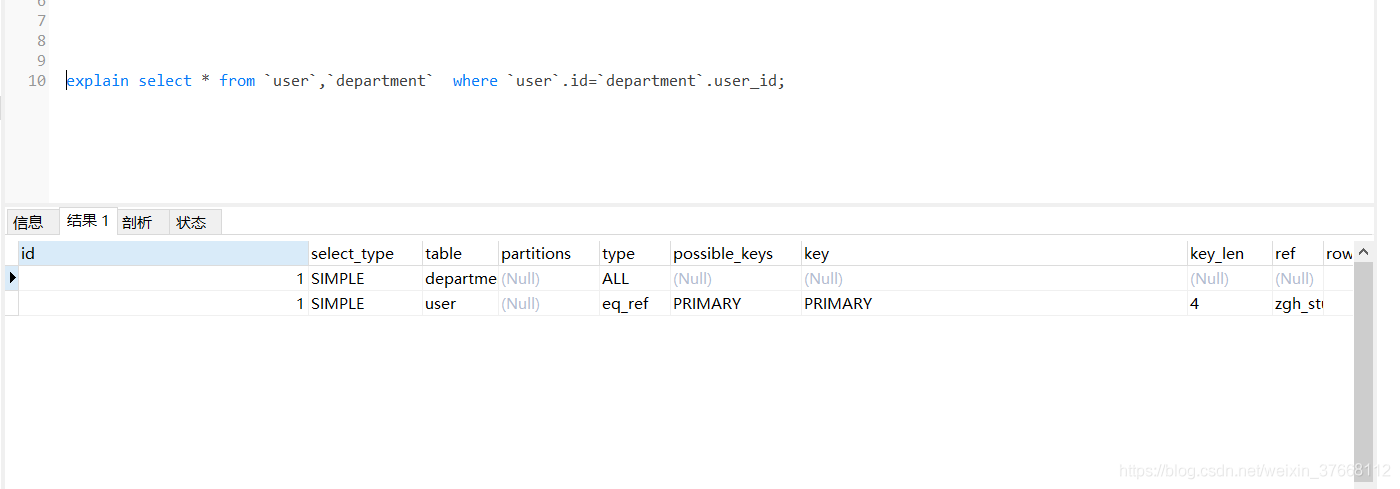
POSSIBLE_KEYS:可能使用到的索引
KEY:使用的索引(重點指標)
KEY_LEN:索引的長度(不是重點指標)
計算方法:
型別位元組(int +4 ; varchar(10) 10個字符 utf8 30個位元組 gbk 20個位元組 ) + 可變長(+2)+允許為空(+1)
68 =( age int 4個 + username varchar 20*3個) + (2個 username varchar 可變長)+(1個 age允許為空 + 1個 username允許為空)
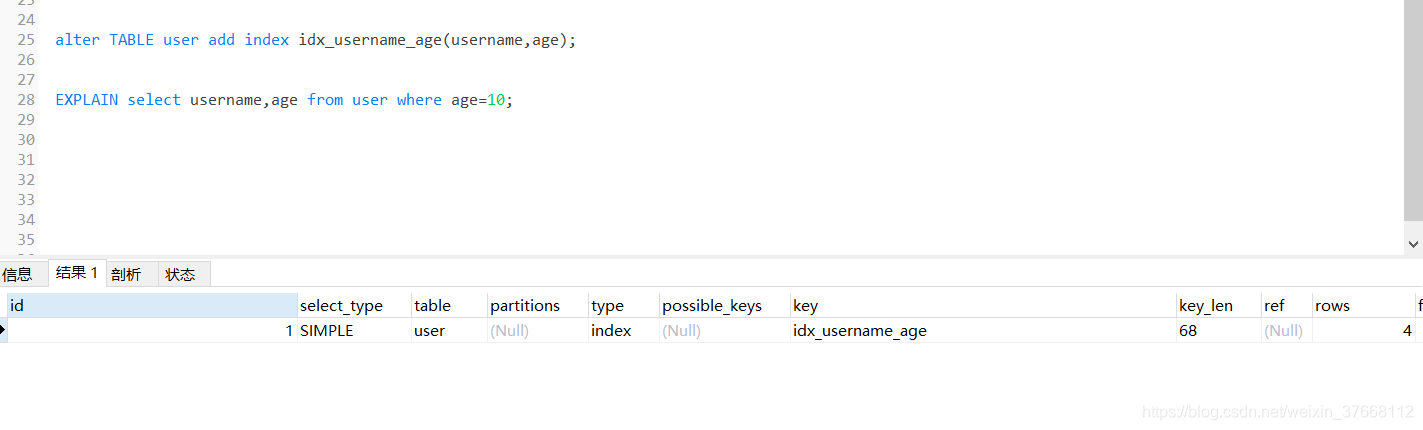
REF:哪一列被使用了,const表示該列等于某個常數
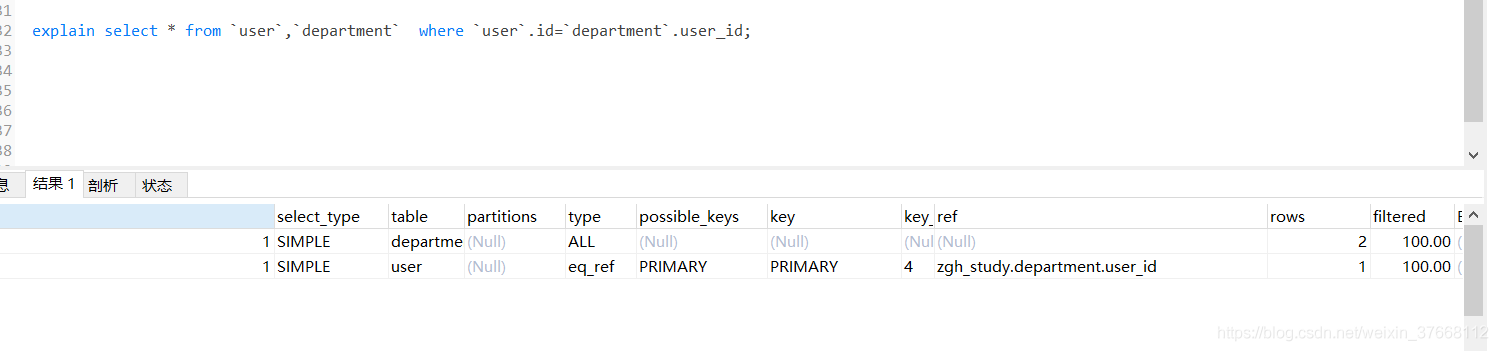
ROWS:查詢SQL陳述句掃描的資料量 不是很準確 屬于 約等于,當使用索引時候 rows的值不應該超過全表資料的 1/3 (重點指標)
EXTRA:額外的資訊(重點指標)
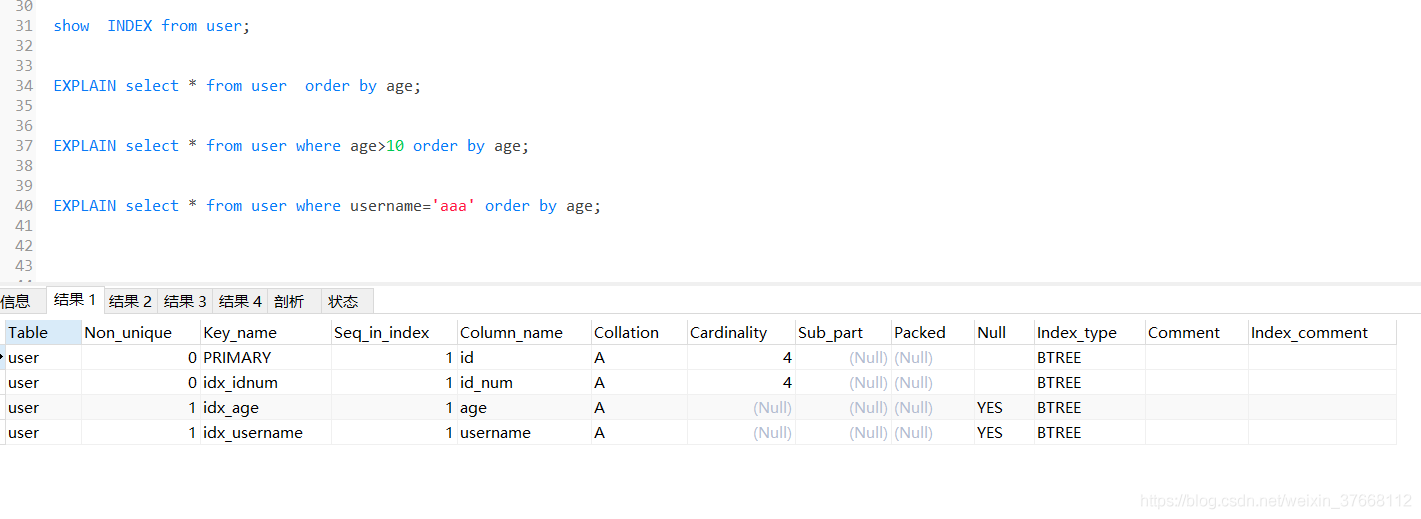
using filesort:無法利用索引進行排序,只能在外部記憶體中或磁盤中進行排序作業叫做 檔案排序,效率不怎么好, 索引在 where 中產生 order by 不會產生索引,只能利用索引進行排序,從結果2可以看出
要想不出現這個需要滿足三點:
(1)使用了索引,explain 引數key能知道
(2)order by 欄位 這個欄位必須是 在這個索引key 里面
(3)如果是使用組合索引,需要符合最左匹配原則 例如 index(username,sex,age) 查詢 where username=’‘aa’ order by age 不符合原則 還是會出現 using filesort 這個額外資訊
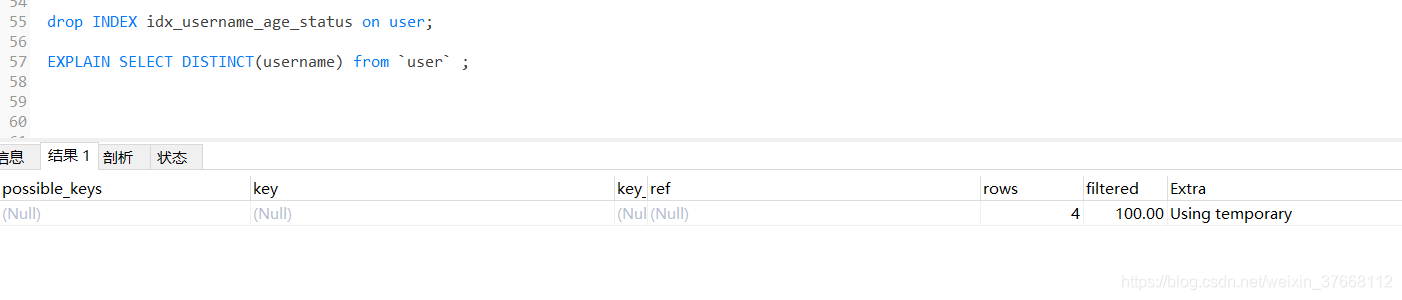
Using temporary:表中常常涉及group by union 合并 distinct 去重 還有多表查詢 order by排序 ,如果不能有 效利用索引來完成查詢,MySQL很有可能尋求通過建立內部的臨時表來執行查詢
Using where:不能使用索引進行過濾,只能類似于 using filesort只能在外部完成過濾操作
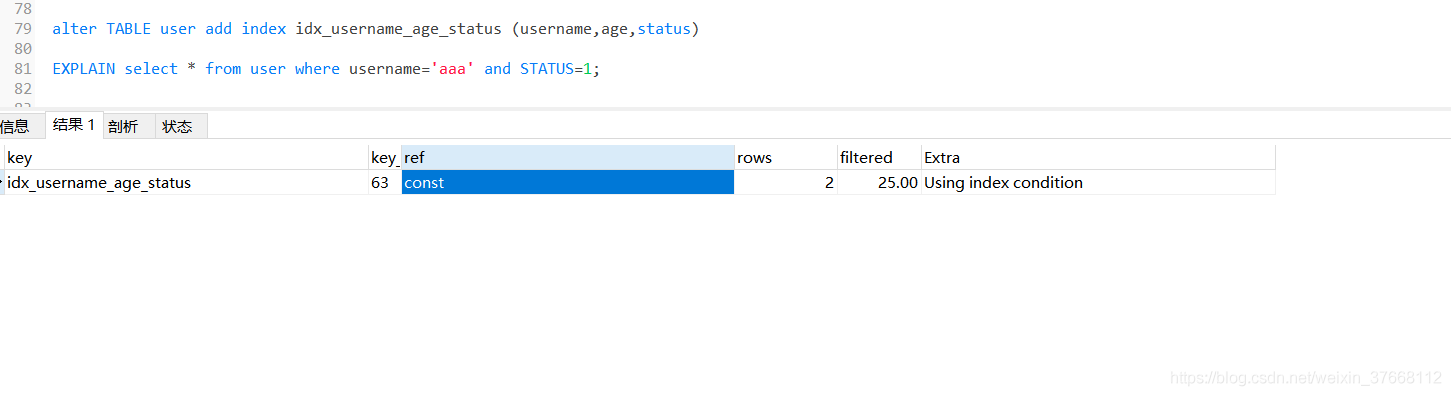
Using index condition:需要進行回表,但是使用了索引,并且需要利用索引進行資料查詢以及一些資料排序作業 (下面例子就知在 使用 username 索引情況 利用 status進一步的查詢)



USING index:效率不錯,避免回表操作,直接在索引樹能完成資料的獲取作業,如果還出現了 user where 代表 利用索引進行進一步的過濾

性能 從下往上 依次增加
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/213019.html
標籤:AI
上一篇:Mysql事務---學習筆記1