前言
String應該是Java使用最多的類吧,很少有Java程式沒有使用到String的,在Java中創建物件是一件挺耗費性能的事,而且我們又經常使用相同的String物件,那么創建這些相同的物件不是白白浪費性能嗎,所以就有了StringTable這一特殊的存在,StringTable叫做字串常量池,用于存放字串常量,這樣當我們使用相同的字串物件時,就可以直接從StringTable中獲取而不用重新創建物件,那么,StringTable都有哪些特性呢?接下來就讓我們好好探討一下StringTable,
String的一些特性
String的不可變性
在講介紹StringTable之前,就不得不提一下String的不可變性,因為只有當String是不可變的才使得StringTable的實作成為可能,當我們定義一個字串時:
String s = "hello";這時候,“hello”就被存放在StringTable中,而變數s是一個參考,s指向了StringTable中的“hello”,
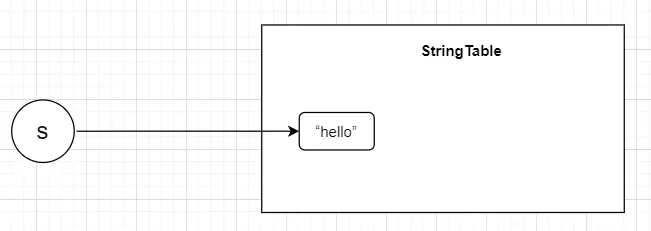
當我們把s的值改一下,改成”hello world“
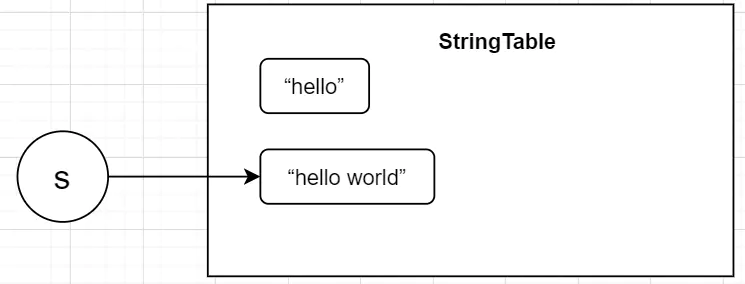
String s = "hello";
s = "hello world";這時候,并不是原先s指向的”hello“的值改變為了”hello world“,而是指向了一個新的字串,
如何去驗證是指向了一個新的字串而不是修改其內容呢,我們可以列印一下hash值看看,
String s = "hello";
System.out.println(System.identityHashCode(s));
s = "hello world";
System.out.println(s.hashCode());
s = "hello";
System.out.println(System.identityHashCode(s));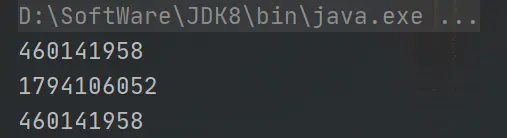
可以看到,第一次和第三次的hash值一樣,第二次hash值和其它兩次不同,說明確實是指向了一個新的物件而不是修改了String的值,
那么**String是怎么實作不可變的呢?**我們來看一下String類的原始碼:
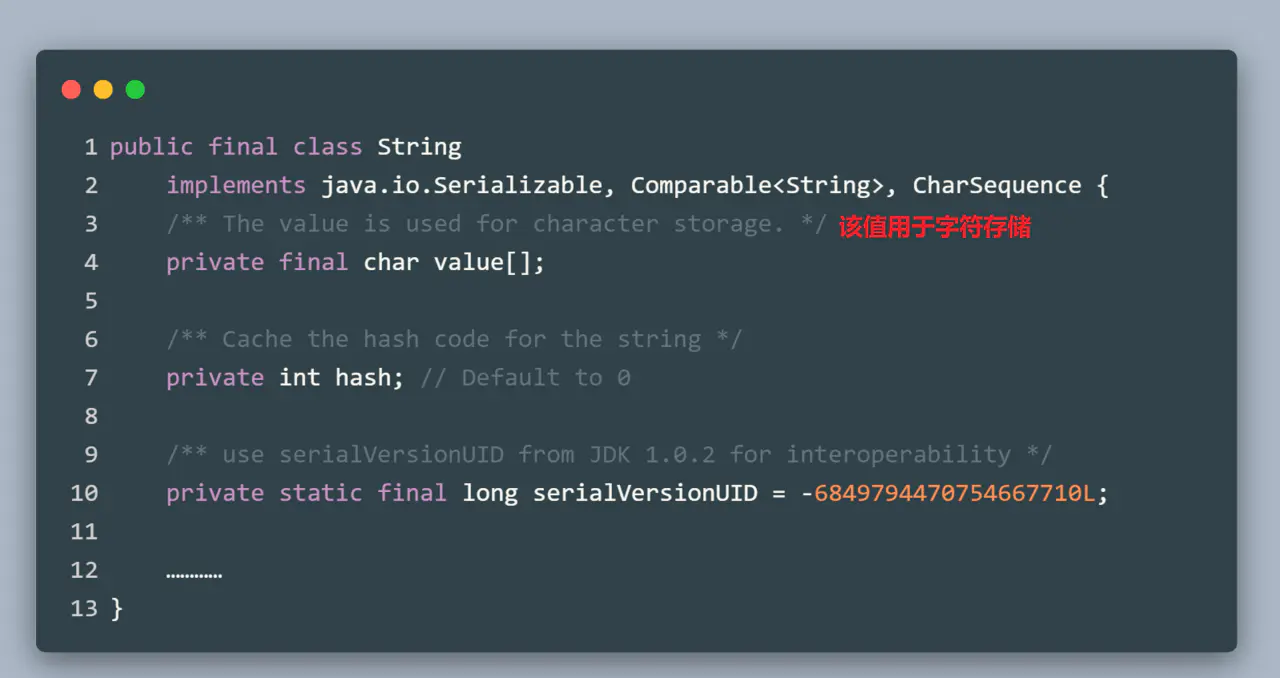
從原始碼中我們可以看出,首先String類是final的,說明其不可被繼承,就不會被子類改變其不可變的特性;其次,String的底層其實是一個被final修飾的陣列,說明這個value在確定值后就不能指向一個新的陣列,這里我們要明確一點,被final修飾的陣列雖然不能指向一個新的陣列,但卻是可以修改陣列的值的:
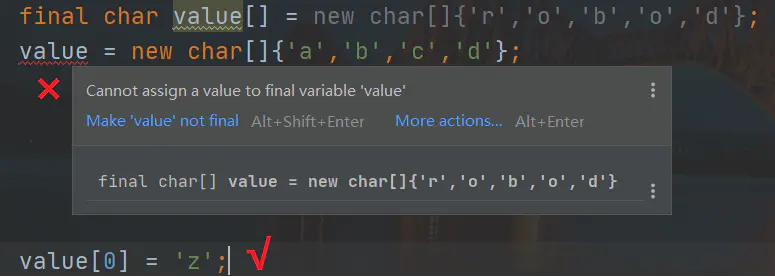
既然可以被修改,那String怎么是不可變的呢?因為String類并沒有提供任何一個方法去修改陣列的值,所以String的不可變性是由于其底層的實作,而不是一個final,
那么**String為什么要設計成不可變的呢?**我覺得是因為出于安全性的考量,試想一下,在一個程式中,有多個地方同時參考了一個相同的String物件,但是你可能只是想在一個地方修改String的內容,要是String是可變的,導致了所有的String的內容都改變了,萬一這是在一個重要場景下,比如傳輸密碼什么的,不就出大問題了嗎,所以String就被設計成了不可變的,
字串的拼接
說完了String的不可變性,再來聊一聊字串的拼接問題,看下面一段程式
public static void main(String[] args) {
String a = "hello";
String b = " world!";
String c = a+b;
}就是這么簡單了一段程式,你知道它是怎么實作的嗎?我們來看一下這段代碼對應的位元組碼指令:
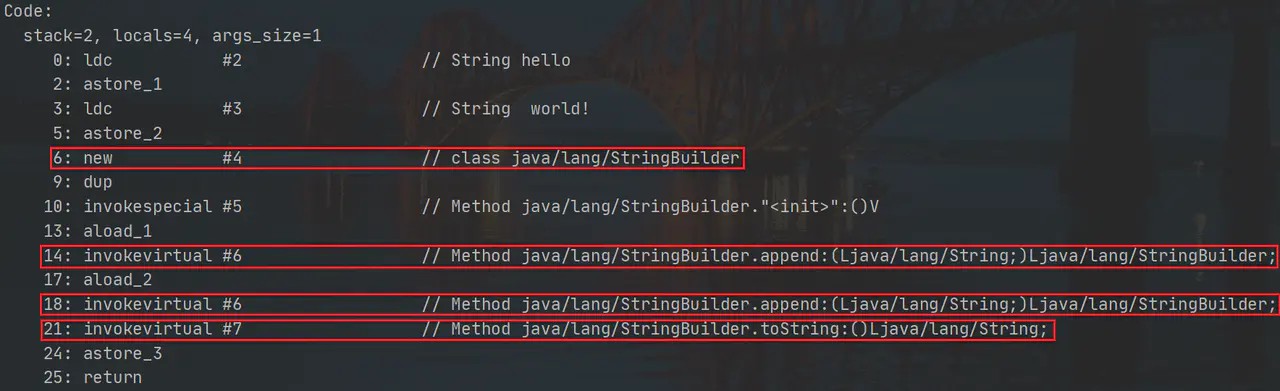
我就不一行行解釋這些位元組碼指令是什么意思了,我們重點看一下用紅色標注的幾行代碼,看不懂前面的位元組碼指令沒關系,可以看后面的注釋,可以看到,字串拼接其實就是呼叫StringBuilder的append()方法,然后呼叫了toString()方法回傳一個新的字串,
StringTable講解
字串什么時候被放入StringTable的
先來簡單介紹一下StringTable,它的底層資料結構是HashTable,每個元素都是key-value結構,采用了陣列+單向鏈表的實作方式,
再來看下面一段代碼:
public static void main(String[] args) {
-> String a = "hello";
String b = " world!";
String c = "hello world!";
}在類加載后,“hello”這些字串僅僅是當作符號被加載進了運行時常量池中,還沒有成為字串物件,這是因為Java中的字串采用了延遲加載的機制,就是程式運行到具體某一行的時候再去加載,比如當程式運行到箭頭所指向的那一行時,“hello”會從一個符號變成一個字串物件,然后去StringTable中找有沒有相同的字串物件,如果有的話就回傳對應的地址給變數a,如果沒有的話就把“hello”放入StringTable中,然后再把地址給變數a,我們來看一下是不是這樣:
String s1 = "hello world";
String s2 = "hello world";
String s3 = "hello world";
String s4 = "hello world";
System.out.println(System.identityHashCode(s1));
System.out.println(System.identityHashCode(s2));
System.out.println(System.identityHashCode(s3));
System.out.println(System.identityHashCode(s4));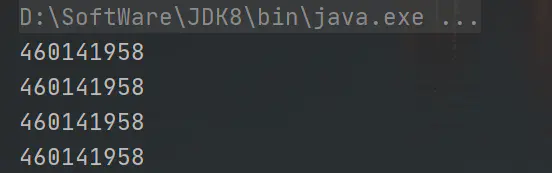
可以看到,四個字串物件的hash值都一樣,說明如果StringTable中已經有了相同的物件就會指向同一個物件而不是指向新的物件,
new String()的時候都干了什么
當我們使用new String()去創建一個字串物件時和直接寫String a = "hello"是不一樣的,前者保存在堆記憶體中,后者保存在StringTable中,
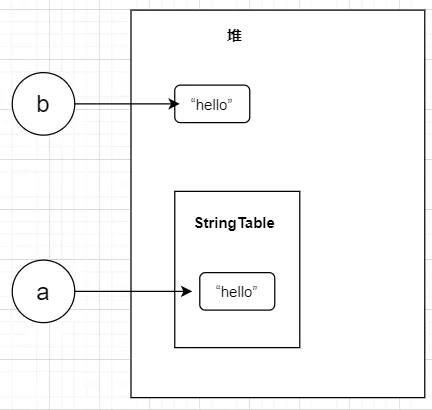
其實StringTable也是在堆中,我后面會詳細說明,我們先來驗證一下上面的說法:
String a = "hello";
String b = new String("hello");
System.out.println(a == b);看一下運行結果:

結果很顯然肯定是false,說明兩者確實不是一個物件,而且上面提到指向字串常量時會先從StringTable中查找,找到就直接回傳找到的字串,但是new String()的時候卻不是這樣,每new 一個String就會在堆里面創建一個新的String物件,即使是相同的內容,比如我創建4個String物件,
String s1 = new String("hello world");
String s2 = new String("hello world");
String s3 = new String("hello world");
String s4 = new String("hello world");這時候在堆里面就會存在4個String物件:
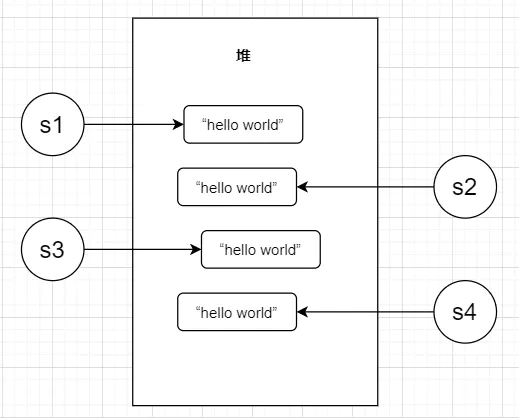
我們再來列印一下hash看看是不是4個物件:
System.out.println(System.identityHashCode(s1));
System.out.println(System.identityHashCode(s2));
System.out.println(System.identityHashCode(s3));
System.out.println(System.identityHashCode(s4));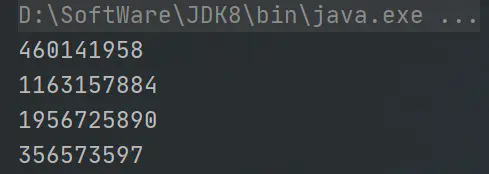
從結果中看出,確實是4個不同的物件,
intern方法是干嗎的
我們先來看一段代碼:
String s1 = new String("hello world");
String s2 = "hello world";
String s3 = s1.intern();
System.out.println(s1 == s2);
System.out.println(s2 == s3);大家看看能不能分析出結果是什么,如果你已經知道結果,說明你已經掌握了intern方法,如果不知道,就看我下面的講解,

結果是false和true,intern方法是干嗎的呢?
intern方法的作用就是嘗試將一個字串放入StringTable中,如果不存在就放入StringTable并回傳StringTable中的地址,如果存在的話就直接回傳StringTable中的地址,這是jdk1.8版本中intern方法的作用,jdk1.6版本中有些不同,1.6中intern嘗試將字串物件放入StringTable,如果有則并不會放入,如果沒有會把此物件復制一份,放入StringTable, 再把StringTable中的物件回傳,不過我們在這里不討論1.6版本,
解釋一下上面的代碼:首先我們在堆中創建了一個"hello world"字串物件,s1指向了這個堆中的物件;然后在StringTable中創建了一個值為"hello world"的字串常量物件,s2指向了這個StringTable中的物件;最后我們嘗試將s1指向的堆中物件放入StringTable中,發現已經有了,所以就回傳了StringTable中的字串物件的地址給了s3,所以s1和s2指向了同一個物件,s2和s3是一個物件,就像下圖這樣:
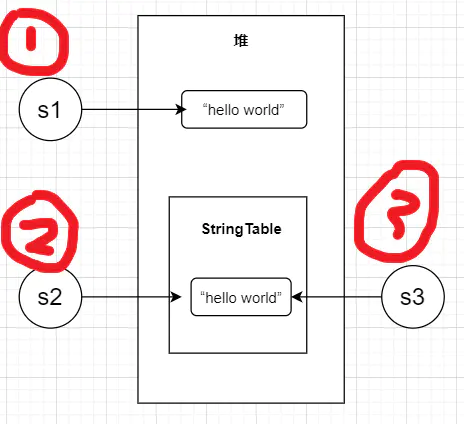
要是把代碼稍微改一下呢:
String s1 = new String("hello world").intern();
String s2 = "hello world";
System.out.println(s1 == s2);這時候結果就是true了,我們來分析一下:首先使用了new String()在堆中創建了字串物件,然后呼叫了其intern()方法,所以就從StringTable中查找有沒有同樣的字串,發現沒有,就將字串放入StringTable中,然后將StringTable中的物件的地址給了s1;到第二行的時候,因為沒有用new String(),所以就直接從StringTable中查找,發現有,就將StringTable中的物件的地址給了s2;所以s1、s2指向了同一個物件,
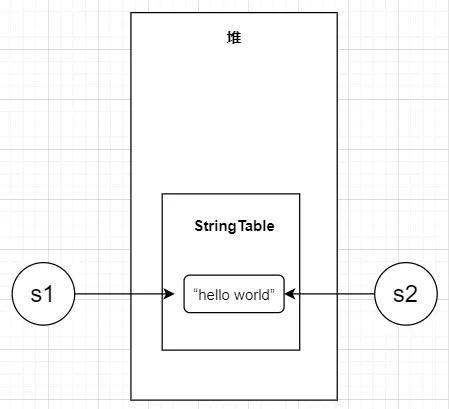
StringTable的位置
前面已經提到了StringTable在堆中,現在來驗證一下,驗證的方式很簡單,我們放入大量的字串導致記憶體溢位,看看是哪個部分記憶體溢位就知道StringTable在哪兒了,
ArrayList list = new ArrayList();
String str = "hello";
for(int i = 0;i < Integer.MAX_VALUE;i++) {
String s = str + i;
str = s;
list.add(s.intern());
}我們先是呼叫了intern方法將字串放入StringTable,再用一個ArrayList去存放字串,目的是為了避免垃圾回收,因為這樣的話每個字串都會被強參考,就不會被垃圾回收了,垃圾回收了就不會看到我們想要的結果,來看一下結果:

很明顯,是堆記憶體發生了記憶體溢位,這樣就可以確定StringTable是存放在堆中的,不過這是從1.7版本開始的,1.7之前保存在永久代中,
StringTable的垃圾回收
既然前面提到了垃圾回收,我們就來驗證一下StringTable會不會發生垃圾回收,還是上面的代碼,只不過稍微修改一下:
String str = "hello";
for(int i = 0;i < 10000;i++) {
String s = str + i;
s.intern();
}這里沒有再將字串放入ArrayList了,要不然就算是發生了記憶體溢位也不會垃圾回收,為了看到垃圾回收的程序,所以添加幾個虛擬機引數,先不指定堆大小:
運行程式,看看列印情況:
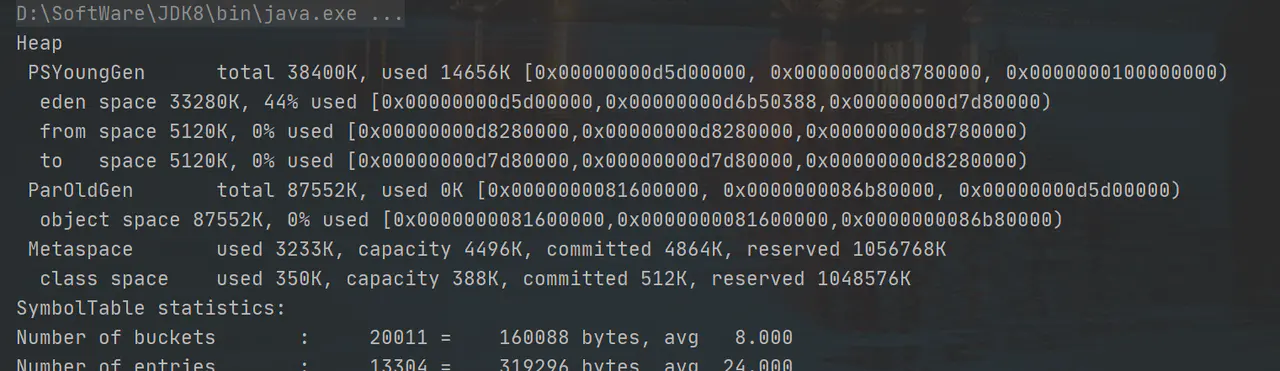
因為堆記憶體足夠大,所以沒有發生垃圾回收,我們現在將堆記憶體設定的小一點,,來個1m:
-Xmx1m再來運行下程式:
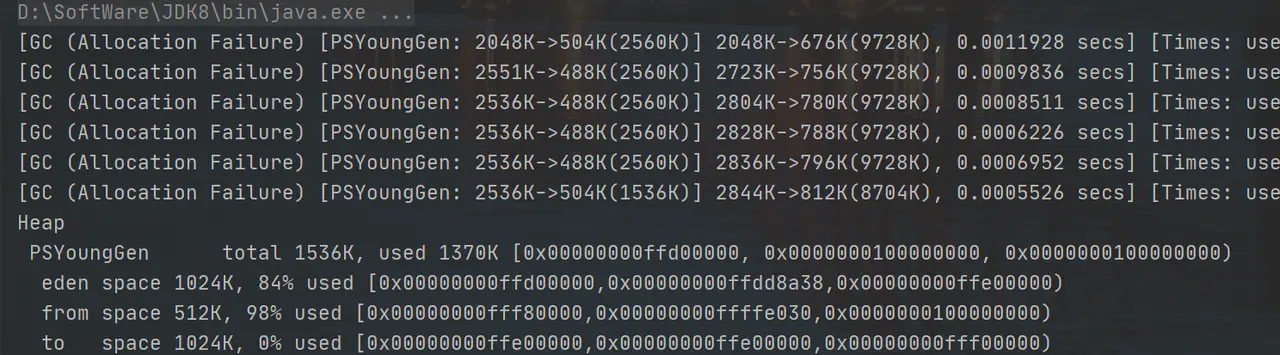
這回因為堆記憶體不夠,發生了多次垃圾回收,所以說,StringTable也會因為記憶體不足導致垃圾回收,
StringTable底層實作以及性能調優
在介紹性能調優之前不得不說一說StringTable的底層實作,前面已經提到了StringTable底層是一個HashTable,HashTable長什么樣呢?其實就是陣列+鏈表,每個元素是一個key-value,當存入一個元素的時候,就會將其key通過hash函式計算得出陣列的下標并存放在對應的位置,
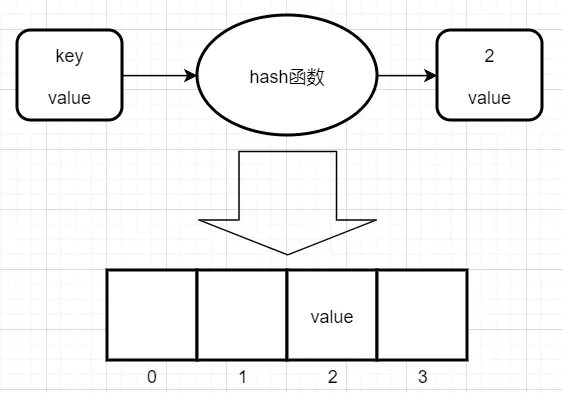
比如現在有一個key-value,這個key通過hash函式計算結果為2,那么就把value存放在陣列下標為2的位置,但是如果現在又有一個key通過hash函式計算出了相同的結果,比如也是2,但2的位置已經有值了,這種現象就叫做哈希沖突,怎么解決呢?這里采用了鏈表法:
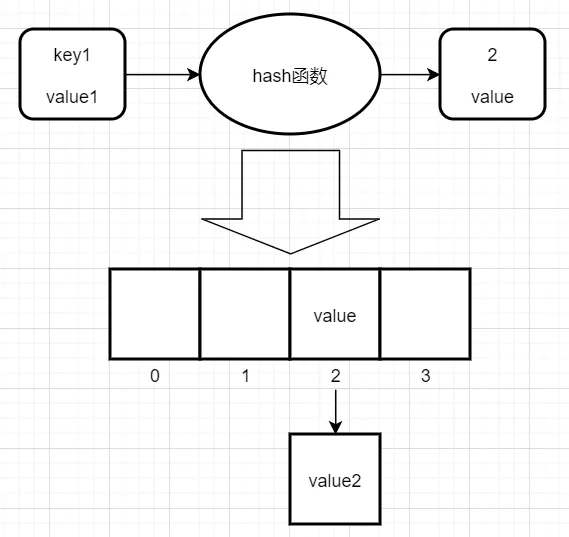
鏈表法就是將下標一樣的元素通過鏈表的形式串起來,如果陣列容量很小但是元素很多,那么發生哈希沖突的概率就會提高,大家都知道,鏈表的效率遠沒有陣列那么高,哈希沖突過多會影響性能,所以為了減少哈希沖突的概率,所以可以適當的增加陣列的大小,陣列的每一格在StringTable中叫做bucket,我們可以增加bucket的數量來提高性能,默認的數量為60013個,來看一個對比:
long startTime = System.nanoTime();
String str = "hello";
for(int i = 0;i < 500000;i++) {
String s = str + i;
s.intern();
}
long endTime = System.nanoTime();
System.out.println("花費的時間為:"+(endTime-startTime)/1000000 + "毫秒");先通過一個虛擬機引數將bucket指定的小一點,來個2000吧:
-XX:StringTableSize=2000運行一下:

一共花費了1.2秒,再來將bucket的數量增加一點,來個20000個:
-XX:StringTableSize=20000運行一下:

可以看到,這次只花了0.19秒,性能有了明顯的提升,說明這樣確實可以優化StringTable,這里只介紹了一種提升性能的方法,篇幅有限,就不再多說了,我以后可能會專門寫一篇文章來專門講講StringTable性能優化的問題,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/213029.html
標籤:其他