1:論文資訊
來自IJCAI 2018的一篇論文:《Spatio-Temporal Graph Convolutional Networks: A Deep Learning Framework for Traffic Forecasting 》
- 原始論文地址鏈接
- Pytorch代碼實作
1.1:論文思路
使用Kipf & Welling 2017的近似譜圖卷積得到的圖卷積作為空間上的卷積操作,時間上使用一維卷積TCN對所有頂點進行卷積,兩者交替進行,組成了時空卷積塊,在加州PeMS和北京市的兩個資料集上做了驗證,論文中圖的構建方法并不是基于實際路網,而是通過數學方法構建了一個基于距離關系的網路,
1.2:摘要和引言總結
-
在交通研究中,交通流的基本變數,也就是速度、流量和密度(實際中,還有排隊長度,時間占有率,空間占有率,車頭時距等多個變數),這些變數通常作為監控當前交通狀態以及未來預測的指示指標,根據預測的長度,主要是指預測時間視窗的大小,交通預測大體分為兩個尺度:短期(5~30min),中和長期預測(超過30min),大多數流行的統計方法(比如,線性回歸)可以在短期預測上表現的很好,然而,由于交通流的不確定性和復雜性,這些方法在相對長期的預測上不是很有效,
-
中長期交通預測上的研究可以分為兩類:動態建模和資料驅動的方法,
- 動態建模方法:使用了數學工具(比如微分方程)和物理知識通過計算模擬來形式化交通問題,為了達到一個穩定的狀態,模擬行程不僅需要復雜的系統編程,還需要消耗大量的計算資源,模型中不切實際的假設和化簡也會降低預測的精度,因此,隨著交通資料收集和存盤技術的快速發展,一大群研究者正在將他們的目光投向資料驅動的方法,
- 資料驅動方法:主要是統計學和機器學習模型,在時間序列分析上,自回歸移動平均模型(ARIMA)和它的變形是眾多統一的方法中基于傳統統計學的方法,但是,這種型別的模型受限于時間序列的平穩分布,不能捕捉時空間依賴關系,因此,這些方法限制了高度非線性的交通流的表示能力,相對傳統統計學方法,機器學習可以獲得更高精度的預測結果,對更復雜的資料建模,比如k近鄰(KNN),支持向量機(SVM)和神經網路(NN),
-
深度學習方法:深度學習已經廣泛且成功地應用于各式各樣的交通任務中,并取得了很顯著的成果,比如層疊自編碼器(SAE),然而,這些全連接神經網路很難從輸入中提取空間和時間特征,而且,空間屬性的嚴格限制甚至完全缺失,這些網路的表示能力被限制的很嚴重,為了充分利用空間特征,一些研究者使用了卷積神經網路來捕獲交通網路中的臨近資訊,同時也在時間軸上部署了回圈神經網路,通過組合LSTM和1維卷積,比如特征層面融合的架構CLTFP來預測短期交通狀況,CLTFP是第一個嘗試對時間和空間規律性對齊的方法,后來,有學者提出帶有嵌入卷積層的全連接網路:ConvLSTM,但是常規卷積操作只適合處理規則化的網路結構,比如影像或者視頻,而大多數領域是非結構化的,比如社交網路,交通路網等,此外,RNN對于序列的學習需要迭代訓練,這會導致誤差的積累,并且還有難以訓練和耗時的缺點,
-
針對以上問題和缺陷:該文引入了一些策略來有效的對交通流的時間動態和空間依賴進行建模,為了完全利用空間資訊,利用廣義圖對交通網路建模,而不是將交通流看成各個離散的部分(比如網格或碎塊),為了處理回圈神經網路的缺陷,我們在時間軸上部署了一個全卷積結構來加速模型的訓練程序,綜上所述,該文提出了一個新的神經網路架構-時空圖卷積網路,來預測交通狀況,這個架構由多個時空圖卷積塊組成,
-
主要貢獻:
- 該文研在交通研究中第一次應用純卷積層(TCN)來同時從圖結構的時間序列中提取時空資訊,
- 該文提出了一個新的由時空塊組成的神經網路結構,由于這個架構中是純卷積操作,它比基于RNN的模型的訓練速度快10倍以上,而且需要的引數更少,這個架構可以讓我們更有效地處理更大的路網,
- 實驗在兩個真實交通資料集上驗證了提出來的網路,這個實驗顯示出我們的框架比已經存在的在多長度預測和網路尺度上的模型表現的更好
1.3:上述總結

2:正文
2.1:資料處理
文章首先將網格資料改為圖資料作為輸入,圖可以用鄰接矩陣來表示,圖中的W就是圖的鄰接矩陣,實驗中使用的資料集PeMSD7(M)共有228個資料點,相當于一個具有228個頂點的圖,因為這個模型主要是對速度進行預測,所以每個頂點只有一個特征就是:速度,
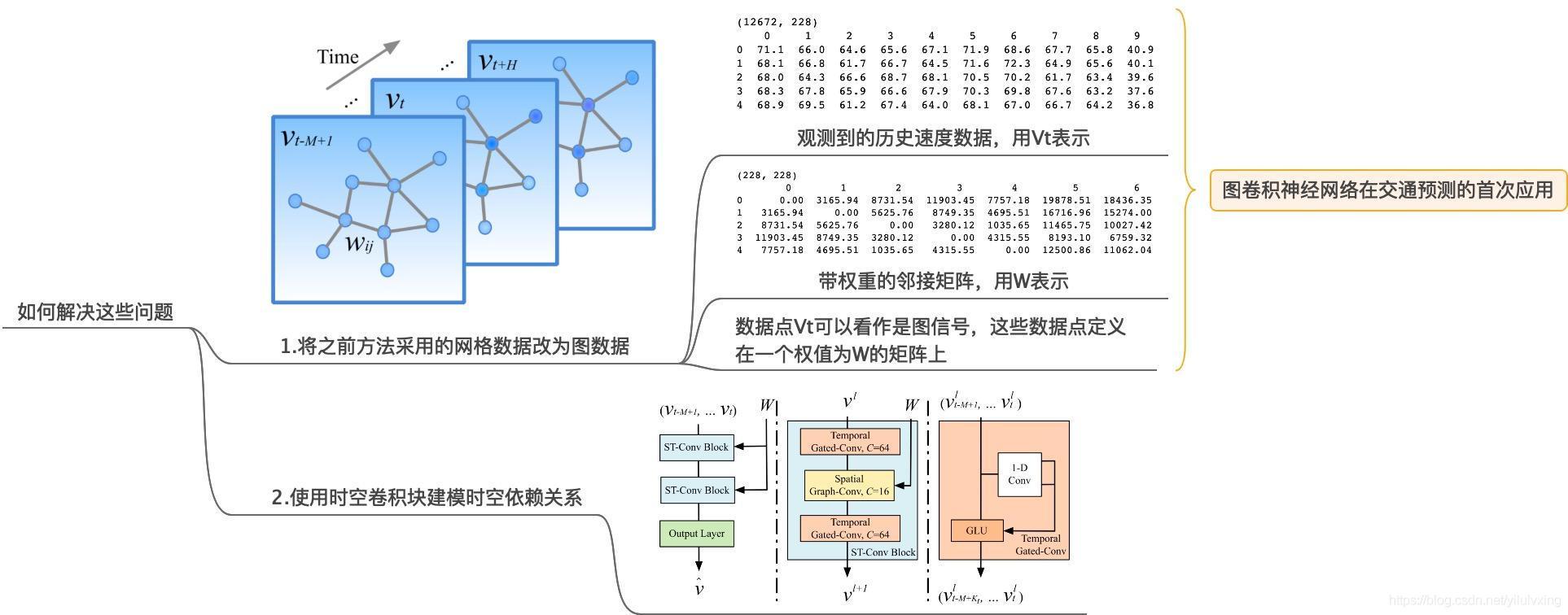
2.2:網路架構
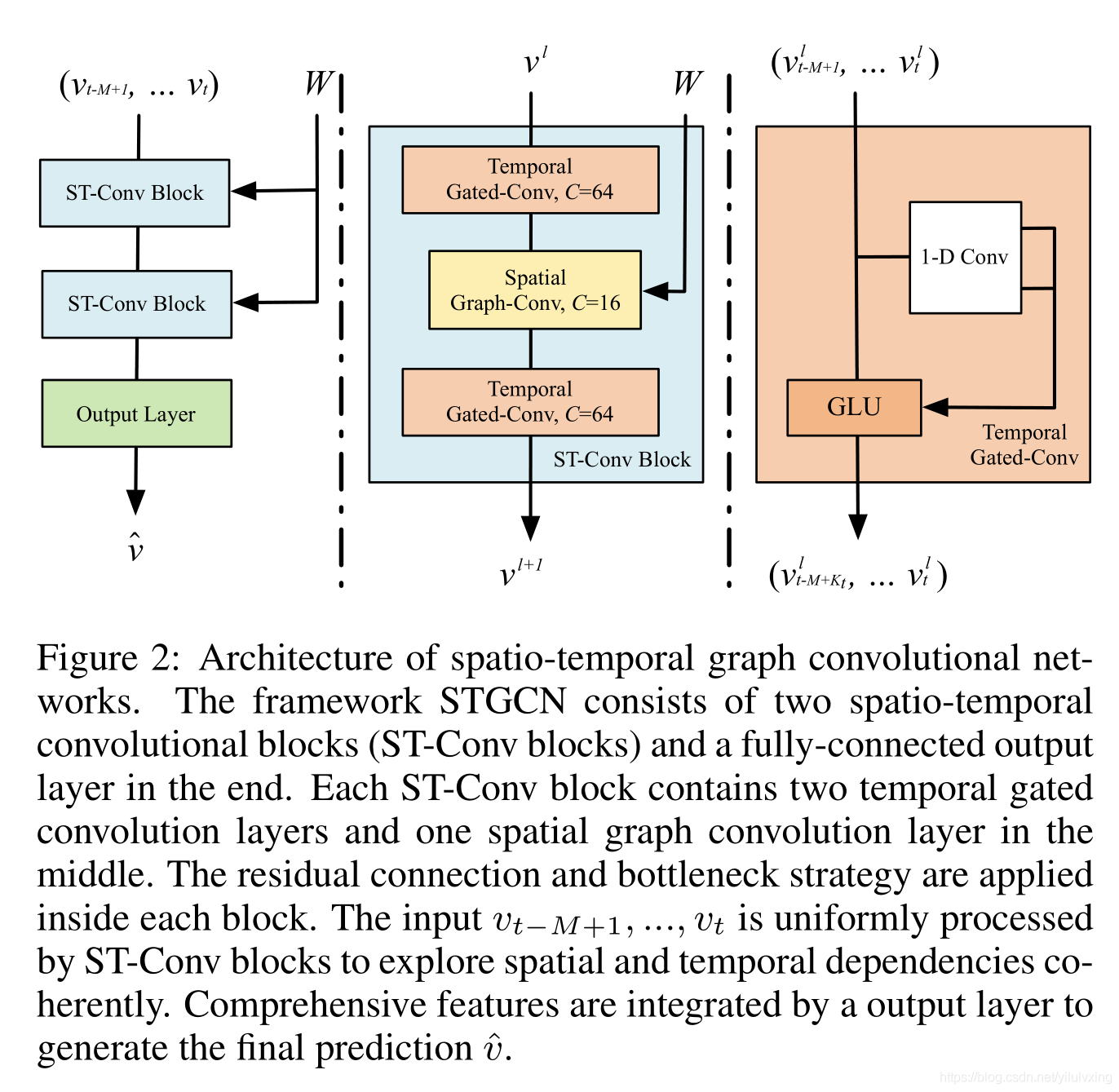
網路架構是本文的重點部分,如下圖所示,STGCN有多個時空卷積塊組成,每一個都是像一個“三明治”結構的組成,有兩個門序列卷積層和一個空間圖卷積層在中間,
組成結構:STGCN 有兩個ST-Conv Block(淡藍色部分)快和一個全連接輸出layer(綠色部分),其中每個ST-Conv Block塊有包括兩個時間卷積塊(橙色部分)和一個空間卷積塊(淺黃色部分)
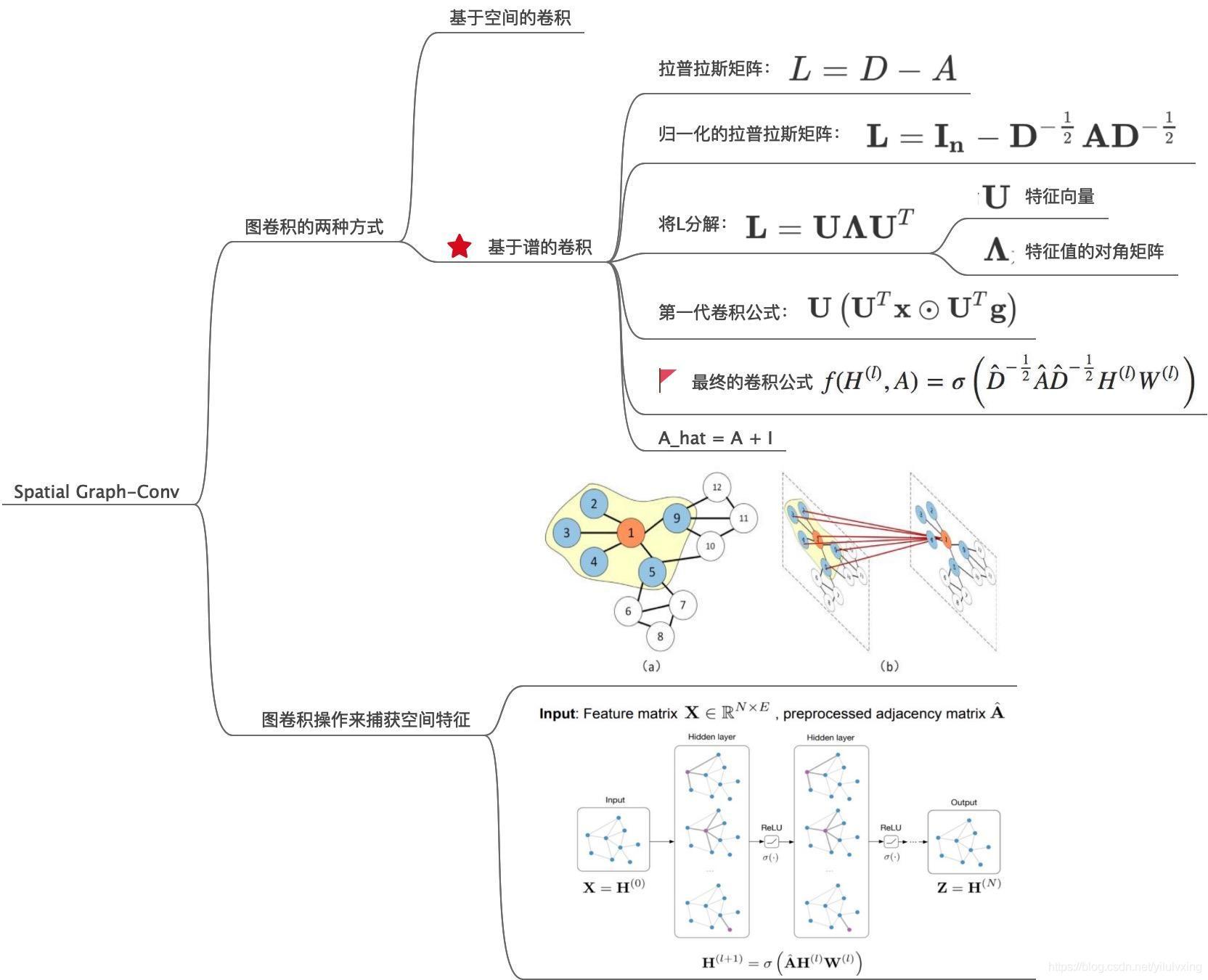
2.3:提取空間特征的圖卷積神經網路
提取時間特征的圖卷積神經網路,即對應網路結構中的Spatial Graph-Conv 模塊,
交通路網是非結構化的影像,為了捕獲空間上的相關性,本篇論文采用的是切比雪夫近似與一階近似后的圖卷積公式,只需要看最終的那個卷積公式,其中D為圖的度矩陣,A_hat為圖的鄰接矩陣+單位矩陣,為的是在卷積程序中不僅考慮鄰居節點的狀態,也考慮自身的狀態,
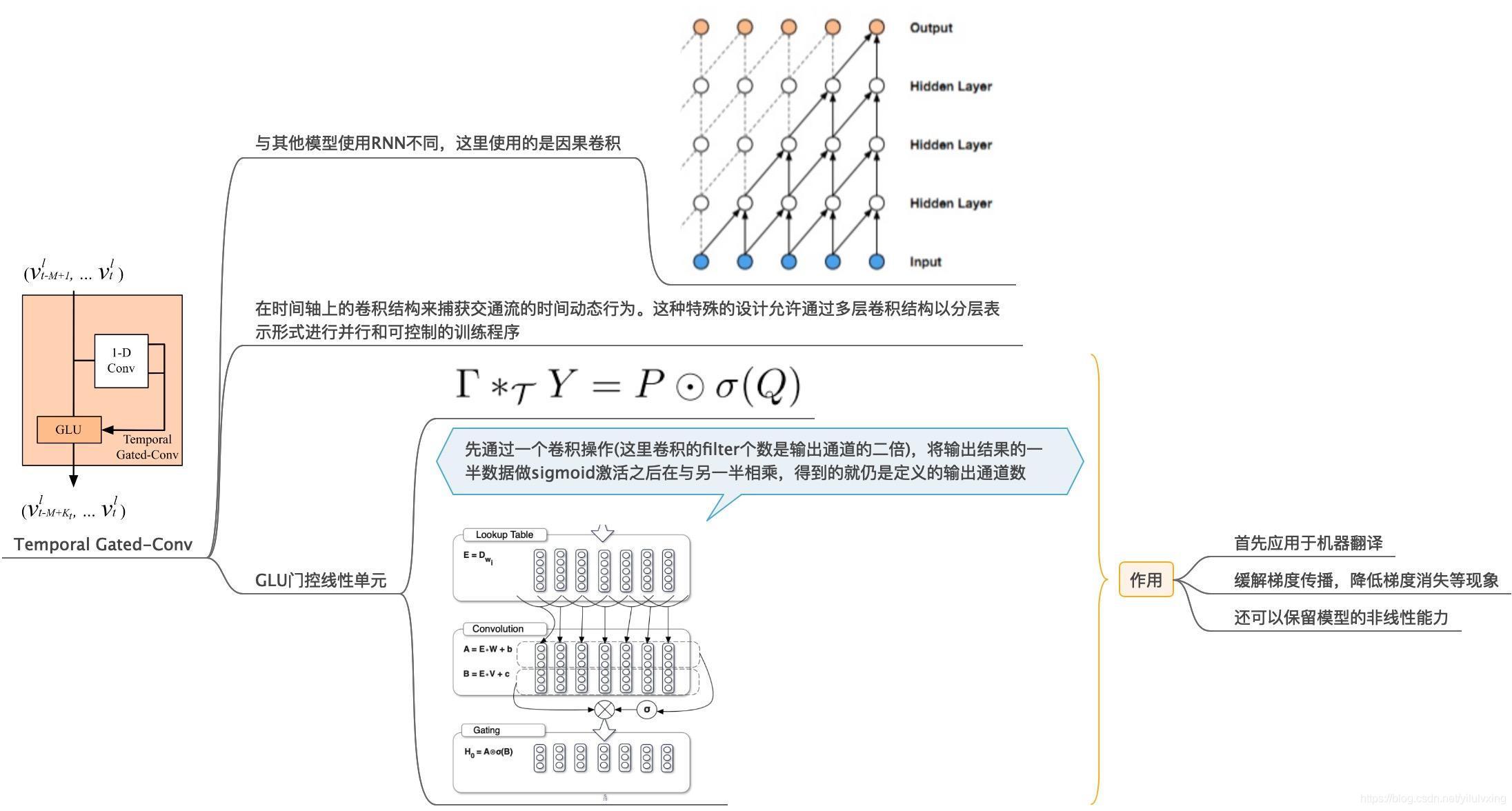
2.4:提取時間特征的門控卷積神經網路
提取空間特征的圖卷積神經網路,即對應網路結構中的Temporal Gated-Conv 模塊,
在時間維度上,本文采用門控卷積來捕獲時間依賴性,而且與傳統的卷積方法不同,由于還要考慮時間序列的問題,所以這里采用的是因果卷積(TCN),使用卷積操作,就不在像采用RNN的方法依賴于之前的輸出,并且還可以對資料進行并行處理,這樣使得模型訓練速度更快,
此外,采用還采用了GLU操作,GLU是在這篇論文中提出的:Language Modeling with Gated Convolutional Networks,在STGCN這篇論文,文章只是簡單提到采用這種操作可以緩解梯度消失等現象還可以保留模型的非線性能力,
2.5:時空卷積塊ST-Conv Block
將以上的圖卷積和門控CNN組合成如圖所示的結構,其中使用了瓶頸策略來實作尺度壓縮和特征壓縮,并在每層之后接歸一化層來防止過擬合,
ST-Conv Block的公式就是圖的另一個解釋,輸入資料先做時間維度卷積,輸出結果再做圖卷積,圖卷積的輸出結果經過一個RELU,在進行一個時間維度卷積,就是整個ST-Conv Block的輸出,

2.6:模型輸出
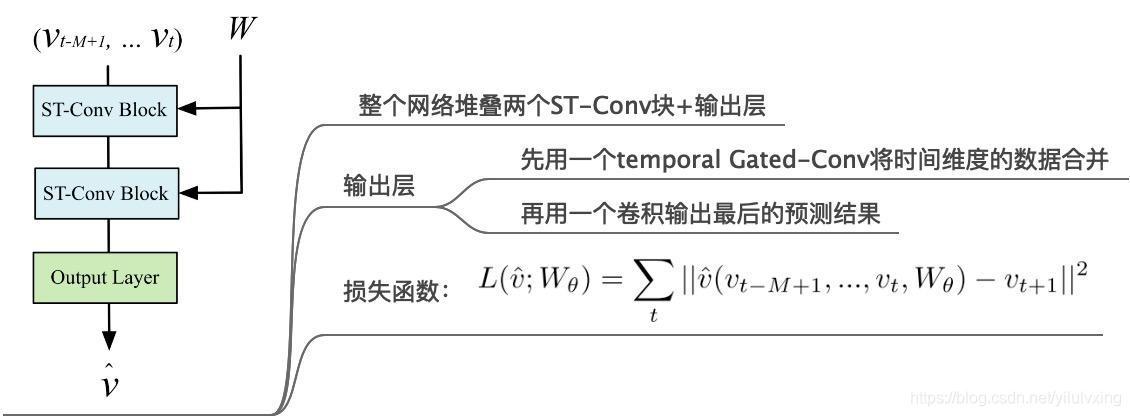
最后的模型是堆疊兩個St-Conv Block之后接一個輸出層,其中輸出層首先用時間維度的卷積將之前的輸出資料的時間維度進行合并,合并之后在經過一個卷積輸出最終的預測資料,預測資料就是下一個時間維度的一張圖[1,228,1],模型采用的是L2損失,
2.7:模型總結
- STGCN 是處理結構化時間序列的通用框架,它不僅能夠解決交通網路建模和預測問題,而且可以應用于更一般的時空序列學習任務,
- 時空卷積塊結合了圖卷積和門控時間卷積,能夠提取出最有用的空間特征,并連貫地捕捉到最基本的時間特征,
- 該模型完全由卷積結構組成,在輸入端實作并行化,引數更少,訓練速度更 快,更重要的是,這種經濟架構允許模型以更高的效率處理大規模網路,
3:原始碼解讀
原始碼以Pytorch為例
3.1:讀取資料
原始資料時間視窗長度是5min一個資料片,即:每5分鐘記錄該時間視窗內,各個路網節點的資料資訊,每條資料資訊包含2個維度資訊,
utlis.load_metr_la_data函式
讀取資料,并且利用 Z-score method進行歸一化:
X = X - means.reshape(1, -1, 1)和 X = X / stds.reshape(1, -1, 1),最侄訓傳資料格式為:X:[207, 2, 34272],表示有圖中有207個節點,34272個時間片,每個時間片對應的節點資料維度是2
def load_metr_la_data():
if (not os.path.isfile("data/adj_mat.npy")
or not os.path.isfile("data/node_values.npy")):
with zipfile.ZipFile("data/METR-LA.zip", 'r') as zip_ref:
zip_ref.extractall("data/")
A = np.load("data/adj_mat.npy")
X = np.load("data/node_values.npy").transpose((1, 2, 0))
X = X.astype(np.float32)
# Normalization using Z-score method
means = np.mean(X, axis=(0, 2))
X = X - means.reshape(1, -1, 1)
stds = np.std(X, axis=(0, 2))
X = X / stds.reshape(1, -1, 1)
return A, X, means, stds
utlis.get_normalized_adj函式
讀取鄰接矩陣,并回傳度資訊
def get_normalized_adj(A):
"""
Returns the degree normalized adjacency matrix.
"""
A = A + np.diag(np.ones(A.shape[0], dtype=np.float32))
D = np.array(np.sum(A, axis=1)).reshape((-1,))
D[D <= 10e-5] = 10e-5 # Prevent infs
diag = np.reciprocal(np.sqrt(D))
A_wave = np.multiply(np.multiply(diag.reshape((-1, 1)), A),
diag.reshape((1, -1)))
return A_wave
utlis.generate_dataset函式
- 歷史時間視窗長度:num_timesteps_input = 12,預測未來時間視窗長度:num_timesteps_output = 3,即用過去12個時間片資訊,來預測接下來3個時間片的數值,
- 在main函式中,訓練資料集為60%,即訓練數量共34272*0.6=20563,main函式呼叫generate_dataseth函式,其原始輸入為 (num_vertices, num_features,num_timesteps),即 (207, 2, 20563),207是節點數量,2表示每個時間片對應的特征數量,訓練時間片數量為20563,
- 最后generate_dataseth回傳X的結果為:(num_samples, num_vertices, num_features, num_timesteps_input),即[20549, 207, 12, 2],20549表示處理后的時間片數量,207表示節點數量,12表示特征數量也就是過去12個時間片,2表示特征的通道數量,generate_dataseth回傳Y的結果為:(num_samples, num_vertices, num_features, num_timesteps_output),即[20549, 207, 3],其中的第一個通道的數值表示預測數值對應的通道,
def generate_dataset(X, num_timesteps_input, num_timesteps_output):
"""
Takes node features for the graph and divides them into multiple samples
along the time-axis by sliding a window of size (num_timesteps_input+
num_timesteps_output) across it in steps of 1.
:param X: Node features of shape (num_vertices, num_features,
num_timesteps)
:return:
- Node features divided into multiple samples. Shape is
(num_samples, num_vertices, num_features, num_timesteps_input).
- Node targets for the samples. Shape is
(num_samples, num_vertices, num_features, num_timesteps_output).
"""
# Generate the beginning index and the ending index of a sample, which
# contains (num_points_for_training + num_points_for_predicting) points
indices = [(i, i + (num_timesteps_input + num_timesteps_output)) for i
in range(X.shape[2] - (
num_timesteps_input + num_timesteps_output) + 1)]
# Save samples
features, target = [], []
for i, j in indices:
features.append(
X[:, :, i: i + num_timesteps_input].transpose(
(0, 2, 1)))
target.append(X[:, 0, i + num_timesteps_input: j])
return torch.from_numpy(np.array(features)), \
torch.from_numpy(np.array(target))
3.2:模型輸入
這里batch_size設定為50,同時為了比較快速清晰的查看各個模塊的輸出,我們就以一個batch為例,即:輸入的總時間片長度為50
STGCN包含三個模型,其中兩個時空STGCNBlock模塊和一個TimeBlock模塊和最后一個全連接層,而一個STGCNBlock又包含兩個temporal(temporal)模塊,(也就是TimeBlock模塊模塊)和 一個Theta(spatial)模塊,一個TimeBlock模塊包含因果卷積操作目的就是為了提取時間資訊(主要是W維度上的)TimeBlock模塊主要是為了提取時間資訊,利用的是一維卷積,kernel_size=3,卷積核大小為(1,kernel_size=3,分別對應H,W),
- GLU操作:Theta(spatial)模塊中的切比雪夫近似與一階近似后的圖卷積與上一個TimeBlock進行矩陣相乘計算,GLU單元來緩解梯度消失等現象還可以保留模型的非線性能力,
- TimeBlock模塊的原始輸入為:[50, 207, 12, 2]即[B,H,W,C],經過尺度變換轉換為pytorch最終的輸入為[50, 2, 207, 12],即[B,C,H,W],尺度變換的原因在于要與卷積核對應,因為
卷積核大小為(1,kernel_size=3,分別對應H,W),呼叫一次TimeBlock模塊H不變也就是207數值不變,W減小2,也就是12-2,即提取一個時間切片下的時間資訊, - STGCN包含三個模型,其中兩個時空STGCNBlock模塊(分別為block1和block2)和一個TimeBlock模塊(last_temporal),block1和block2均包含2個TimeBlock,每個TimeBlock計算后,W要減少2,因此,兩個block1和block2后,W共減少8,因此block2的輸出結果為[50, 207, 4, 64],
- 再利用切比雪夫近似與一階近似后的圖卷積公式進行計算,從而提取空間資訊,STGCN中最后包含的TimeBlock模塊主要是為了維度資訊的縮放,輸出通道統一為64,這樣保證后面全連接的時候,
- 引數一致,如原始batch輸入為[50, 207, 12, 2],在經過整個STGCN的前兩個時空STGCNBlock模塊后,其輸出大小為out3:[50, 207, 2, 64],在經過最后一層的全連接之前,要進行維度調整,(out3.shape[0], out3.shape[1], -1)回傳的是[50, 207, 3],
- 最后再經過一個全連接層:self.fully = nn.Linear((num_timesteps_input - 2 * 5) *64,num_timesteps_output)回傳預測的3個時間片結果
3.3:模型總結
- 資料匯入和劃分:
資料匯入后的格式為X:[207, 2, 34272],60%用作訓練集,數量共34272*0.6=20563,num_timesteps_input = 12,num_timesteps_output = 3,資料集生成函式回傳的X結果為[20549, 207, 12, 2],Y結果為[20549, 207, 3],batch設定的數值為50,也就是每50個時間片資料進行訓練,因此TimeBlock模塊的輸入為[50, 207, 12, 2]即[B,H,W,C], - 維度變換:
STGCN = block1+block2+last_temporal:
第一個Block中的第一個TimeBlock模塊的定義為self.temporal1TimeBlock(in_channels=in_channels,out_channels=out_channels),TimeBlock輸入為[50, 207, 12, 2]即[B,H,W,C],但需要進一步轉換,轉換后的結果為[50, 2, 207, 12],即[B,C,H,W],因為一般情況下,圖網路資料轉換為網格資料時,H一般表示網格節點數量,W表示特征數量(時空資料下的同一時間片的歷史資料量),另一個尺度變換的原因在于要與卷積核對應,因為卷積核大小為(1,kernel_size=3,分別對應H,W),C表示通道,B表示batch的大小,如果保持原始的[B,H,W,C],則一維卷積則對W,C進行卷積,顯然是不合理的, - TimeBlock計算的結果是[50, 64, 207, 10],即[B,C,H,W](以呼叫一次TimeBlock為例,W減少2),再進行一次維度變換,回傳的結果是[50, 207, 10, 64],即[B,H,W,C],因為后面還會呼叫TimeBlock,所以與上一次輸入格式保持一致,
- GLU的定義為:self.Theta1 = nn.Parameter(torch.FloatTensor(out_channels,spatial_channels) — spatial_channels=16
經過矩陣相乘,GLU的操作轉換輸出結果為[50, 207, 10, 16],作為下一個TimeBlock的輸入, - 第一個block1中的第二個TimeBlock模塊的定義為self.temporal2=self.temporal2 = TimeBlock(in_channels=spatial_channels,out_channels=out_channels)與第一個TimeBlock模塊輸出結果類似,self.tempora2的輸出結果為[50, 207, 8, 64],即self.temporal => self.Theta1 => self.tempora2 ,通道數量從64 => 16 => 64,也就是說self.Theta1模塊經過一次非線性變換,只需要將輸入,輸出通道數量對齊即可,最后經過一層BN:self.tempora2的輸出結果為[50, 207, 8, 64],經過BN其輸出維度保持不變:[50, 207, 8, 64]同理,再經過第二個block2后,BN層的輸出結果為[50, 207, 4, 64],最后一個last_temporal(TimeBlock):其輸入為[50, 207, 4, 64],輸出為[50, 207, 2, 64]
- 最后全連接層:self.fully = nn.Linear((num_timesteps_input - 2 * 5) *64,num_timesteps_output),out4 = self.fully(out3.reshape((out3.shape[0], out3.shape[1], -1))),輸出結果為[50, 207, 3]
TimeBlock模塊:
class TimeBlock(nn.Module):
"""
Neural network block that applies a temporal convolution to each node of
a graph in isolation.
"""
def __init__(self, in_channels, out_channels, kernel_size=3):
"""
:param in_channels: Number of input features at each node in each time
step.
:param out_channels: Desired number of output channels at each node in
each time step.
:param kernel_size: Size of the 1D temporal kernel.
"""
super(TimeBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, (1, kernel_size))
self.conv2 = nn.Conv2d(in_channels, out_channels, (1, kernel_size))
self.conv3 = nn.Conv2d(in_channels, out_channels, (1, kernel_size))
def forward(self, X):
"""
:param X: Input data of shape (batch_size, num_nodes, num_timesteps,
num_features=in_channels)
:return: Output data of shape (batch_size, num_nodes,
num_timesteps_out, num_features_out=out_channels)
"""
# Convert into NCHW format for pytorch to perform convolutions.
X = X.permute(0, 3, 1, 2)
temp = self.conv1(X) + torch.sigmoid(self.conv2(X))
out = F.relu(temp + self.conv3(X))
# Convert back from NCHW to NHWC
out = out.permute(0, 2, 3, 1)
return out
STGCNBlock模塊
class STGCNBlock(nn.Module):
"""
Neural network block that applies a temporal convolution on each node in
isolation, followed by a graph convolution, followed by another temporal
convolution on each node.
"""
def __init__(self, in_channels, spatial_channels, out_channels,
num_nodes):
"""
:param in_channels: Number of input features at each node in each time
step.
:param spatial_channels: Number of output channels of the graph
convolutional, spatial sub-block.
:param out_channels: Desired number of output features at each node in
each time step.
:param num_nodes: Number of nodes in the graph.
"""
super(STGCNBlock, self).__init__()
self.temporal1 = TimeBlock(in_channels=in_channels,
out_channels=out_channels)
self.Theta1 = nn.Parameter(torch.FloatTensor(out_channels,
spatial_channels))
self.temporal2 = TimeBlock(in_channels=spatial_channels,
out_channels=out_channels)
self.batch_norm = nn.BatchNorm2d(num_nodes)
self.reset_parameters()
def reset_parameters(self):
stdv = 1. / math.sqrt(self.Theta1.shape[1])
self.Theta1.data.uniform_(-stdv, stdv)
def forward(self, X, A_hat):
"""
:param X: Input data of shape (batch_size, num_nodes, num_timesteps,
num_features=in_channels).
:param A_hat: Normalized adjacency matrix.
:return: Output data of shape (batch_size, num_nodes,
num_timesteps_out, num_features=out_channels).
"""
t = self.temporal1(X)
lfs = torch.einsum("ij,jklm->kilm", [A_hat, t.permute(1, 0, 2, 3)])
# t2 = F.relu(torch.einsum("ijkl,lp->ijkp", [lfs, self.Theta1]))
t2 = F.relu(torch.matmul(lfs, self.Theta1))
t3 = self.temporal2(t2)
return self.batch_norm(t3)
# return t3
STGCN模塊:
class STGCN(nn.Module):
"""
Spatio-temporal graph convolutional network as described in
https://arxiv.org/abs/1709.04875v3 by Yu et al.
Input should have shape (batch_size, num_nodes, num_input_time_steps,
num_features).
"""
def __init__(self, num_nodes, num_features, num_timesteps_input,
num_timesteps_output):
"""
:param num_nodes: Number of nodes in the graph.
:param num_features: Number of features at each node in each time step.
:param num_timesteps_input: Number of past time steps fed into the
network.
:param num_timesteps_output: Desired number of future time steps
output by the network.
"""
super(STGCN, self).__init__()
self.block1 = STGCNBlock(in_channels=num_features, out_channels=64,
spatial_channels=16, num_nodes=num_nodes)
self.block2 = STGCNBlock(in_channels=64, out_channels=64,
spatial_channels=16, num_nodes=num_nodes)
self.last_temporal = TimeBlock(in_channels=64, out_channels=64)
self.fully = nn.Linear((num_timesteps_input - 2 * 5) * 64,
num_timesteps_output)
def forward(self, A_hat, X):
"""
:param X: Input data of shape (batch_size, num_nodes, num_timesteps,
num_features=in_channels).
:param A_hat: Normalized adjacency matrix.
"""
out1 = self.block1(X, A_hat)
out2 = self.block2(out1, A_hat)
out3 = self.last_temporal(out2)
out4 = self.fully(out3.reshape((out3.shape[0], out3.shape[1], -1)))
return out4
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/213244.html
標籤:其他
上一篇:加快腦動脈瘤檢測,AI來了