OceanBase 的特性
OceanBase的優勢
分布式事務
OceanBase是通過對原有2PC的改良,來實作分布式事務
2PC的問題
- 單點問題,過度依賴協調者,一旦協調者出現問題,系統將無法正常運轉,會有可能造成資料不一致
- 參與者在等待其他參與者回應的同時,無法進行任何操作,處于阻塞狀態,一旦參與者出現故障,協調者只能通過自己的超時機制發現
- 效率比較低,用戶感知到的提交時延是4次寫日志耗時以及2次 RPC 的往返耗時
OceanBase的改良
OceanBase通過多副本(Multi-Paxos),解決了2PC單點,阻塞和資料不一致的問題
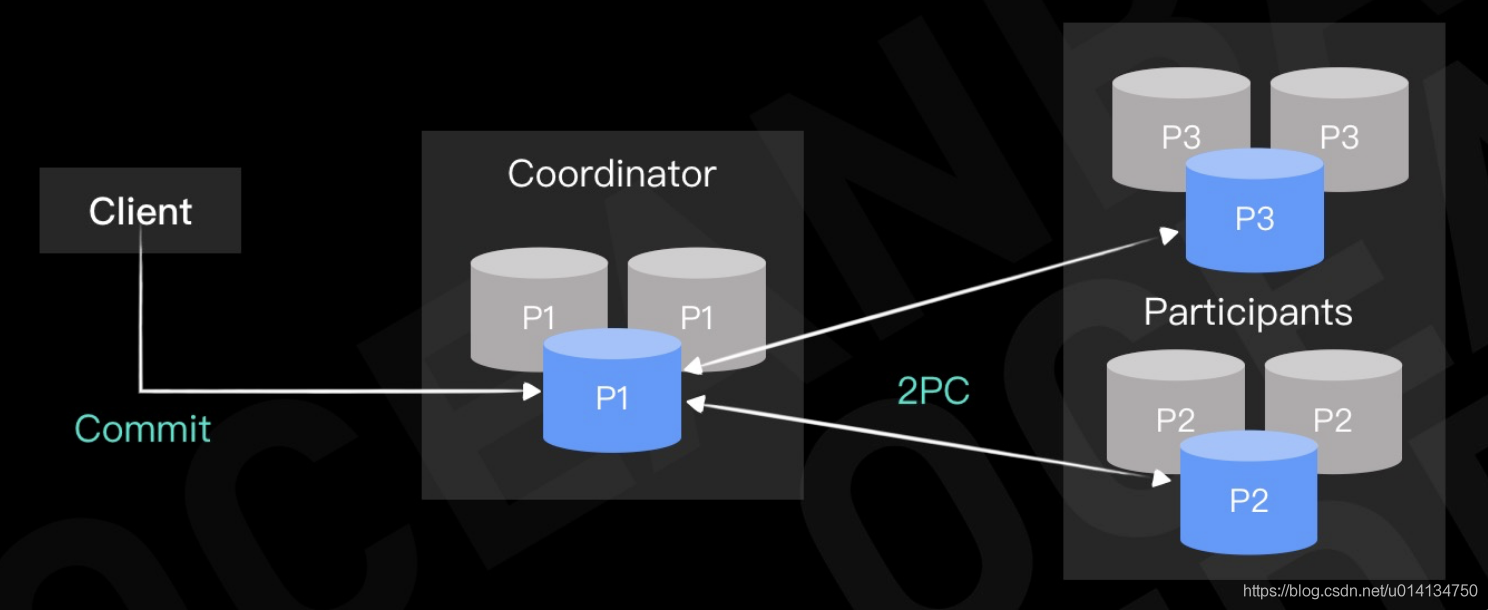
如上圖所示,當分布式事務提交時,會選擇其中的一個資料分片作為協調者在所有資料分片上執行兩階段提交協議,還記得前文提到過的協調者宕機問題么?在 OceanBase 中,由于所有資料分片都是通過 Paxos 復制日志實作多副本高可用的,當主副本發生宕機后,會由同一資料分片的備副本轉換為新的主副本繼續提供服務,所以可以認為在 OceanBase 中,參與者和協調者都是保證高可用不宕機的(多數派存活),繞開了協調者宕機的問題,
在參與者高可用的實作前提下,OceanBase 對協調者進行了“無狀態”的優化,在標準的兩階段提交中,協調者要通過記錄日志的方法持久化自己的狀態,否則如果協調者和參與者同時宕機,協調者恢復后可能會導致事務提交狀態不一致,但是如果我們認為參與者不會宕機,那么協調者并不需要寫日志記錄自己的狀態,
OceanBase在第一階段所有參與者都回復prepare完成以后,即反饋事務提交成功,提升了2PC的效率
由于存在多副本,只要保證在prepare階段,驗證事務執行沒有錯誤,協調者發出commit指令后,就可以樂觀的認為,事務執行成功并反饋給事務發起者,OceanBase相信commit訊息會被多數副本收到,多數副本收到訊息以后,剩下的就交給他們自己同步
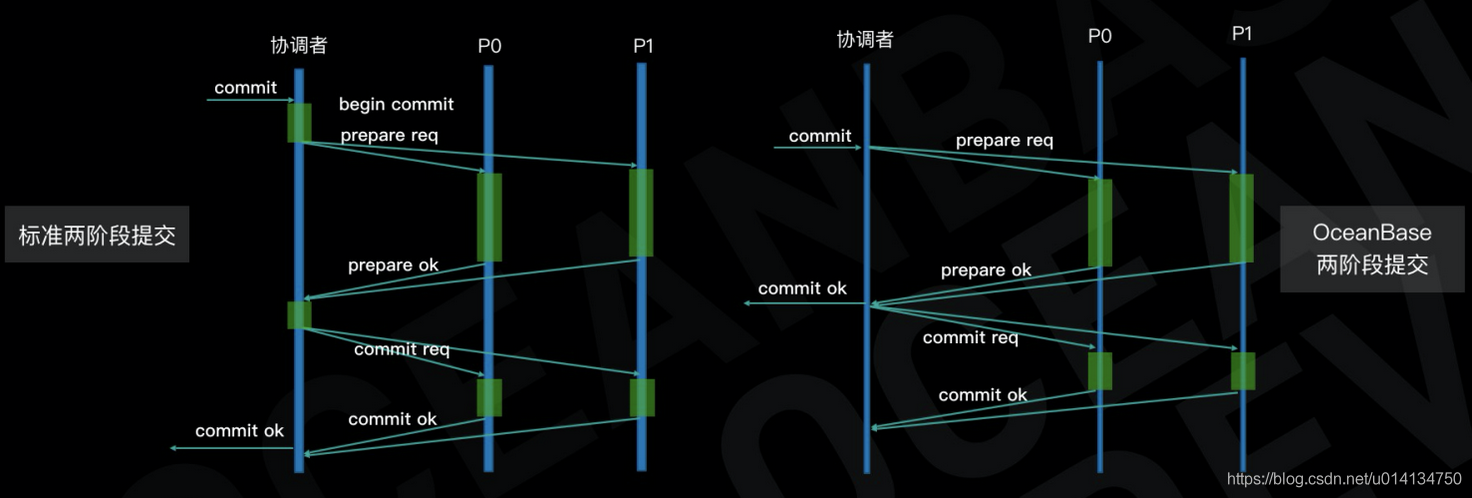
在上圖中(綠色部分表示寫日志的動作),左側為標準兩階段提交協議,用戶感知到的提交時延是4次寫日志耗時以及2次 RPC 的往返耗時;右側圖中 OceanBase 的兩階段提交實作,由于少了協調者的寫日志耗時以及提前了應答客戶端的時機,用戶感知到的提交時延是1次寫日志耗時以及1次 RPC 的往返耗時,
OceanBase的問題
復雜查詢的效率問題
OceanBase資料庫在磁區以后,在處理一些復雜的查詢,比如跨磁區鍵的多表join,不包含的磁區鍵的查詢,這些查詢需要分發到每一個磁區,甚至產生笛卡爾乘積,
問題
OceanBase 有沒有提供類似于Mysql Binlog監聽的功能,這樣可以把一些復雜查詢,放到ES上去處理
對于資料結構設計的要求非常高
正如上面討論的OceanBase在沒有使用到磁區鍵的時候,查詢效率非常低,這也是目前分布式資料庫普遍的問題,
設計難點:
- 就是在設計上要結合業務,充分發揮磁區鍵的作用
- 跨庫關聯的處理:欄位冗余,系結表(以某一維度為索引的資料,都放在一張表里),全域表(變更不頻繁的,資料量不大)
- 分頁: 為了在跨磁區的分頁查詢中,掃描更少的行數,需要在分庫中查詢出來以后,進行二次組裝,并且查詢第二頁以后時,需要帶上前一頁排序欄位最后的值
- 簡單的關聯查詢,可以通過多維度分庫來實作(比如訂單表通過userId的hash值分片,如果需要以商戶維度來查詢某一個店家的訂單詳情,為了避免全磁區掃描,就需要創建一個訂單id和商戶的索引映射表,該表通過商戶id分片,查詢時,先通過商戶id查出映射表里對應的訂單,最后去訂單表里帶出訂單詳情),效率有所降低
- 將OceanBase定位于事務性資料庫(OLTP),專注于事務流水操作,把復雜的查詢放到ES上去做
總結
OceanBase 特別適合于寫多讀少,對事務有比較高要求,高并發,大資料量的業務場景(例如金融領域)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/214152.html
標籤:其他
上一篇:重磅!騰訊年度星級“kafka骨灰級筆記”,分布式有它就夠了
下一篇:加快腦動脈瘤檢測,AI來了