作者|Marco Santos
編譯|Flin
來源|towardsdatascience

在無休止地瀏覽成百上千個交友檔案,卻沒有一個與之匹配之后,人們可能會開始懷疑這些檔案是如何在手機上出現的,所有這些組態檔都不是他們要找的型別,他們已經刷了好幾個小時甚至幾天,都沒有發現任何成功,他們可能會問:
“為什么這些約會應用程式會向我展示那些我知道我不適合的人呢?”
在很多人看來,用來顯示約會檔案的約會演算法可能已經失效,他們厭倦了在應該匹配的時候向左滑動,每個交友網站和應用程式都可能利用自己的秘密交友演算法來優化用戶之間的匹配,但有時它會讓人覺得它只是在向其他人展示隨機用戶,而沒有任何解釋,我們如何才能更多地了解這個問題,并與之作斗爭?可以用一種叫做機器學習的方法,
我們可以使用機器學習來加速約會應用程式中用戶之間的配對程序,使用機器學習,組態檔可以潛在地與其他類似的組態檔聚集在一起,這將減少互不兼容的組態檔的數量,從這些集群中,用戶可以找到更像他們的其他用戶,
集群組態檔資料
使用上面文章中的資料,我們能夠成功地獲得convenient panda DataFrame中的集群約會組態檔,
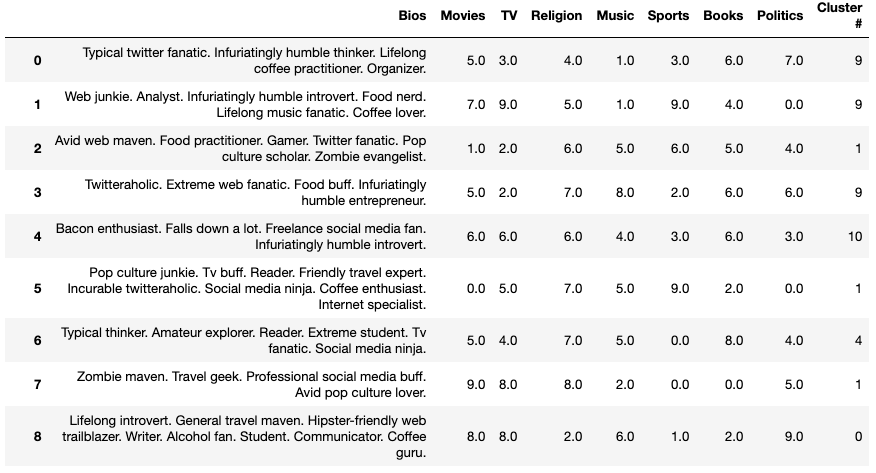
在此DataFrame中,每一行都有一個組態檔,最后,在將Hierarchical Agglomerative Clustering(https://www.datanovia.com/en/lessons/agglomerative-hierarchical-clustering/) 應用于資料集后,我們可以看到它們所屬的集群組,每個組態檔都屬于一個特定的集群編號或組,
不過,這些小組可以進行一些改進,
對集群組態檔進行排序
使用集群檔案資料,我們可以根據每個檔案之間的相似程度對結果進行排序,從而進一步細化結果,這個程序可能比你想象的更快更容易,
import random
# 隨機選擇一個集群
rand_cluster = random.choice(df['Cluster #'].unique())
# 將集群組態檔分配為新的DF
group = df[df['Cluster #']==rand_cluster].drop('Cluster #', axis=1)
## 矢量化所選集群中的BIOS
# 將Vectorizer適配到BIOS
cluster_x = vectorizer.fit_transform(group['Bios'])
# 創建一個包含矢量化單詞的新DF
cluster_v = pd.DataFrame(cluster_x.toarray(), index=group.index, columns=vectorizer.get_feature_names())
# 連接向量DF和原始DF
group = group.join(cluster_v)
# 洗掉BIOS,因為不再需要它來代替矢量化
group.drop('Bios', axis=1, inplace=True)
## 在用戶之間尋找關聯
# 定位DF,以便我們與索引(用戶)關聯
corr_group = group.T.corr()
## 尋找排名前10位的類似用戶
# 隨機選擇一個用戶
random_user = random.choice(corr_group.index)
print("Top 10 most similar users to User #", random_user, '\n')
# 創建與所選用戶最相似的前10名用戶的DF
top_10_sim = corr_group[[random_user]].sort_values(by=[random_user],axis=0, ascending=False)[1:11]
# 列印結果
print(top_10_sim)
print("\nThe most similar user to User #", random_user, "is User #", top_10_sim.index[0])
代碼分解
讓我們將代碼分解為從random開始的簡單步驟,在整個代碼中使用random來簡單地選擇集群和用戶,這樣做是為了使我們的代碼可以適用于資料集中的任何用戶,一旦我們有了隨機選擇的集群,我們就可以縮小整個資料集的范圍,使之只包含那些帶有所選集群的行,
矢量化
在縮小選定集群組的范圍后,下一步涉及對該組中的bios進行矢量化,
用于此操作的矢量器與用于創建初始集群資料幀的矢量器相同-CountVectorizer(),(向量器變數是在我們對第一個資料集進行向量化時預先實體化的,這可以在上面的文章中看到),
# 使向量化器適合Bios
cluster_x = vectorizer.fit_transform(group['Bios'])
# 創建一個新的DF,其中包含向量化的詞
cluster_v = pd.DataFrame(cluster_x.toarray(),
index=group.index,
columns=vectorizer.get_feature_names())
通過對Bios進行矢量化處理,我們創建了一個二進制矩陣,其中包含每個bio中的單詞,
然后,我們會將這個向量化的DataFrame加入到選定的組/集群DataFrame中,
# 將向量DF和原始DF連接起來
group = group.join(cluster_v)
# 洗掉Bios,因為不再需要它
group.drop('Bios', axis=1, inplace=True)
將兩個DataFrame結合在一起之后,剩下的是矢量化的bios和分類列:
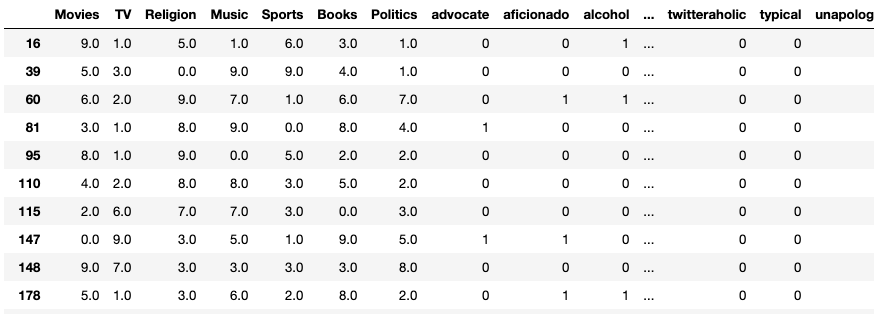
從這里我們可以開始找到彼此最相似的用戶,
尋找約會檔案之間的相關性
創建填充了二進制值和數字的DataFrame之后,我們就可以開始查找約會組態檔之間的相關性,每個約會檔案都有一個唯一的索引號,我們可以將其用作參考,
一開始,我們一共有6600個約會檔案,在聚類并縮小資料幀到所選聚類之后,約會組態檔的數量可以從100到1000不等,在整個程序中,約會組態檔的索引號保持不變,現在,我們可以使用每個索引號來參考每個約會組態檔,
每個索引號代表一個唯一的約會個人資料,我們可以為每個個人資料找到相似或相關的用戶,這可以通過運行一行代碼來創建相關矩陣來實作,
corr_group = group.T.corr()
我們需要做的第一件事是轉置 DataFrame以便切換列和索引,這樣做是為了使我們使用的相關方法應用于索引而不是列,一旦我們轉換了DF,我們就可以應用.corr()方法,它將在索引之間創建一個相關矩陣,
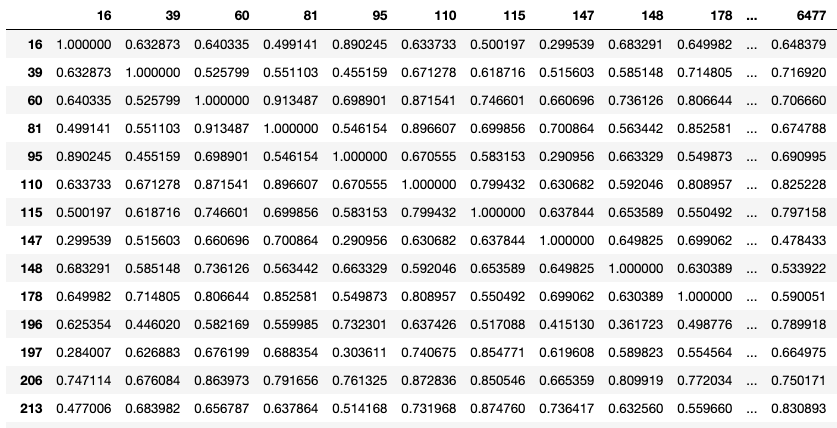
該相關矩陣包含使用Pearson相關方法計算的數值,接近1的值彼此正相關,這就是為什么您將看到與自己的索引相關的索引為1.0000的原因,
查找排名前10的相似約會資料
現在,我們有了一個包含每個索引/約會檔案的相關性得分的相關矩陣,我們可以開始根據它們的相似性對檔案進行排序,
random_user = random.choice(corr_group.index)
print("Top 10 most similar users to User #", random_user, '\n')
top_10_sim = corr_group[[random_user]].sort_values(by=
[random_user],axis=0, ascending=False)[1:11]
print(top_10_sim)
print("\nThe most similar user to User #", random_user, "is User #", top_10_sim.index[0])
上面代碼塊中的第一行從相關矩陣中選擇隨機的約會組態檔或用戶,從那里,我們可以選擇具有所選用戶的列,并對列中的用戶進行排序,以便它只回傳前10個最相關的用戶(不包括所選索引本身),

成功!—— 當我們運行上面的代碼時,我們會得到一個用戶串列,按照他們各自的相關得分進行排序,我們可以看到與隨機選擇的用戶最相似的前10個用戶,這可以與另一個集群組和另一個組態檔或用戶一起再次運行,
結束語
如果這是一個約會應用程式,用戶將能夠看到前10名與自己最相似的用戶,這將有望減少刷屏的時間,減少挫敗感,并增加我們假設的約會應用程式用戶之間的匹配度,假設的約會應用程式的演算法將實作無監督機器學習聚類,以創建一組約會組態檔,在這些組中,演算法將根據相關得分對組態檔進行排序,最后,它將能夠向用戶展示與自己最相似的約會檔案,
原文鏈接:https://towardsdatascience.com/sorting-dating-profiles-with-machine-learning-and-python-51db7a074a25
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/215881.html
標籤:其他