- 貪心演算法:逐步建立一個解決方案,具體地優化一些區域準則,
- 分治:將一個問題分解成獨立的子問題,求解每個子問題,并將子問題的解組合起來形成原問題的解,
- 動態規劃:把一個問題分解成一系列相互重疊的子問題,并為越來越大的子問題建立解決方案,
一、weighted interval scheduling 加權區間調度
- 問題描述:每個job有開始時間、結束時間和權重,找job不overlap的最大權重,
- 解法1:最早結束時間優先,(若權重都一樣,用貪心法是正確的,但在本題不對),
- 以完成時間升序標記jobs,記p(j)=i,表示j>i,在選擇job j后,可選的最大下標為i,
記OPT(j)表示由作業1,2,3…j組成的請求的最優解,
若OPT選擇j,wight包括vj,包括之前的OPT:1,2,…p(j);
若OPT不選擇j,一定包括OPT:1,2…j-1
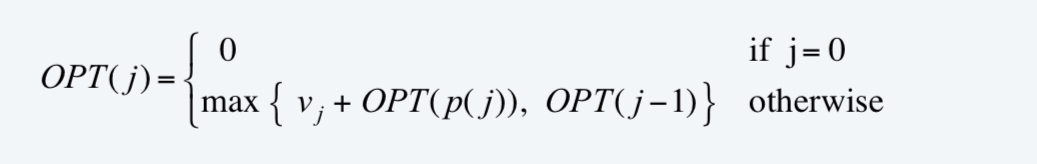
- 解法2:暴力法
//偽代碼
輸入:n,s[n],f[n],v[n]
排序:根據f[n]
計算:p[n]
int computeOpt(int j){
if(j==0)
return 0;
else
return max(v[j]+computeOpt(p[j]),computeOpt(j-1));
}
分析:分層遞回呼叫,時間復雜度指數級增長,
解決:存盤每個子問題的計算結果,以備查找之需,
//偽代碼. O(nlogn) time |
輸入:n,s[n],f[n],v[n];
排序:根據f[n];//O(nlogn)
計算:p[n];
定義:m[n], m[0]=0;
int mComputeOpt(int j){//每次呼叫O(1) time ,總共O(n) time
if(m[j] is empty)
m[j]=max( v[j]+mComputeOpt(p[j]) , mComputeOpt(j-1) );
return m[j];
}
分析:時間復雜度O(nlogn),若已由開始時間、結束時間排序O(n),
- 解法3:用DP演算法計算最優的區間集,
findSolution(int j){
if(j==0)
return {};
else if(v[j]+m[p[j]]>m[j-1])
return {j} ∪ findSolution(p[j]);
else
return findSolution(j-1);
}
分析:由于遞回呼叫次數<=n ,因此時間復雜度為O(n),
- 解法4:自底向上的動態規劃,展開遞回,
//偽代碼
bottomUp(int n,int s[],int f[],int v[]){
sort(f[n]);
compute p[n];
int m[n];m[0]=0;
for(int i=1;i<=n;i++)
m[i]=max( v[i]+m[p[j]] , m[i-1] );
}
- 實作:
#include <iostream>
#include <cmath>
#include <algorithm>
#include <cstring>
using namespace std;
const int maxn = 205;
struct Job
{
int s, e, v, index;
Job(int s=0,int e=0,int v=0,int index=0)//建構式特有語法,比=效率高,有默認引數
:s(s), e(e), v(v), index(index)
{}
}job[maxn];
int p[maxn], m[maxn];//p記錄job j前第一個不沖突的job i;m記錄job 1,2..j的max value
bool cmpE(Job a, Job b)
{
return a.e < b.e;//將job 結束時間從小到大排序
}
int main()
{
//讀入資料&初始化
ios::sync_with_stdio(false); cin.tie(0); cout.tie(0);
memset(p, 0, sizeof(p));
memset(m, 0, sizeof(m));
int n; cin >> n;
for (int i = 1; i <= n; i++)
{
cin >> job[i].s >> job[i].e >> job[i].v;
job[i].index = i;
}
//處理:1.排序 2. 計算p 3.計算 m
//1.
sort(job, job + n, cmpE);
//2.
for (int i = n; i >0 ; i--)
{
for (int j = n - 1; j > 0;j--)
if (job[i].s >= job[j].e)
{
p[i] = job[j].index;
break;
}
}
//3.
for (int i = 1; i <= n; i++)
{
m[i] = max(job[i].v + m[p[i]], m[i - 1]);
}
//輸出:m[n] 即max value of n jobs
cout << m[n] << endl;
return 0;
}
二、segmented least squares 分段最小二乘法
- 最小二乘:統計學基本問題——給定n個點(坐標(xi,yi)),找到一條線y = ax + b使誤差的積分到達最小,
- 問題:有n個點和一個常數c,找到一系例的線,滿足min f(x)=E+cL.
E=每個線段的誤差之和;L=線的數量, - 動態規劃解決思路:
記OPT(j)=點p1…pj的最小誤差之和,
e(i,j)=點pi…pj的最小平方和,
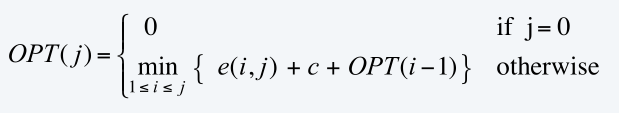
- 演算法:
selectedLeastSquares(int n,int p[n],int c){
for(int j=1;j<=n;j++)
for(int i=1;i<=j;i++)
計算e(i,j);
int m[maxn];m[0]=0;
for(int j=1;j<=n;j++)
m[j]=min{eij+c+m[i-1]} ,1<=i<=j
return m[n]
}
- 分析:O(n3) time | O(n2) space
每次計算e(i,j) O(n2) time ,共計算n次
改進:通過預計算,改善為O(n2) time | O(n) space
三、knapsack problem 背包問題
- 問題描述:給定n個物品和1個背包,每個物品i有重量wi和價值vi;背包可承重W;目標:找背包可放入物品的最大價值,
- 貪心演算法無法解決:①以價值從大到小放×②以重量從小到大放×③以vi/wi從大到小放×
- 動態規劃解法:
定義OPT(i,w)=物品1,2…i的可放入承重w的背包的最大價值
對于第i個物品:
①若i不放入背包:OPT(i,w)=OPT(i-1,w)
②若i放入:OPT(i,w)=OPT(i-1,w-wi)+v[i]
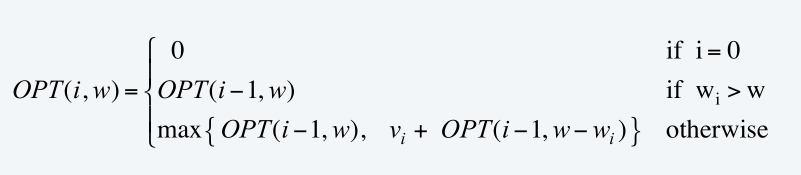
//bottom-up
//O(n*W) time | O(n*W) space
int knapsack(int n,int W,int w[n],int v[n]){
int OPT[maxn][maxn];
//OPT(i,w)=0;if(i==0)
for(int j=0;j<=W;j++)
OPT[0][j]=0;
//OPT(i,w)=OPT(i-1,w);if(w<wi)
//OPT(i,w)=max( v[i]+OPT(i-1,w-wi) , OPT(i-1,w));else
for(int i=1;i<=n;i++){
for(int j=1;j<=W;j++){
if(w[i]>j)
OPT[i][j]=OPT[i-1][j];
else
OPT[i][j]=max( v[i]+OPT[i-1][j-w[i]] , OPT[i-1][j]);
}
}
return OPT[n][W];
}
- 算出最優值后,可以回溯找到解,
四、RNA secondary structure RNA二級結構
- RNA:string b;b由字母{A,C,G,U}組成,
- 二級結構:RNA是單鏈的,有環(每對的末端至少間隔4個字母)、與自身形成堿基對(A-U or G-C),
- 問題描述:給定一個RNA序列,找到一個二級結構,使堿基對的數量最多,
- 記OPT(j)=b1,b2…bj中最多堿基對,
記OPT(i,j)=bi…bj中最多堿基對, - 選擇匹配bt-bn
查找結構(b1,b2…bt-1)=OPT(t-1)和bt+1,bt+2…bn-1,
五、sequence alignment 序列比對
P7-8
- 記gap 為 δ,沒匹配(不一樣)為αpq,
cost=δ+αCG+αTA , - 應用:語音識別、生物學計算、unix diff,
- 序列對比:給定兩個string,找到Min cost,
- 定義:OPT(i,j)=Min cost of string x 1 x 2 … x i and y 1 y 2 … y j .
①若xi有對應yj,OPT(i,j)=( xi-yj ) +OPT(i-1,j-1)
②若xi無對應,OPT(i,j)=δi +OPT(i-1,j)
③若yj無對應,OPT(i,j)=δji +OPT(i,j-1)
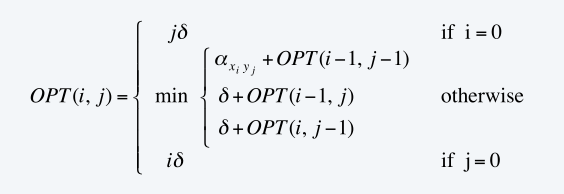
- 演算法:
//偽代碼
int sequenceAlignment(int m,int n,int x[m],int y[n],int δ[],int α[][]){
//if j=0
for(int i=0;i<m;i++)
OPT[i,0]=δ[xi];
//if i=0
for(int j=0;j<n;j++)
OPT[0,j]=δ[yj];
//otherwise
for(int i=1;i<m;i++){
for(int j=1;j<n;j++){
OPT[i][j]=min(α[xi][yi]+OPT[i-1][j-1],δ[xi]+OPT[i-1][j],δ[yj]+OPT[i][j+1]);
}
}
return OPT[m][n];
}
- 分析: Θ(mn) time | Θ(mn) space.
- 練習:C:Human Gene Functions
#include<iostream>
#include<cstring>
#include<cstdio>
#include<cstdlib>
#include<algorithm>
using namespace std;
#define maxn 105
int dp[maxn][maxn];
int M[maxn][maxn];
//題目中的 scoring matrix
void matrix(){
M['A']['A'] = M['C']['C'] = M['G']['G'] = M['T']['T'] = 5;
M['A']['C'] = M['C']['A'] = M['A']['T'] = M['T']['A'] = -1;
M['-']['T'] = M['T']['-'] = -1;
M['A']['G'] = M['G']['A'] = M['C']['T'] = M['T']['C'] = -2;
M['T']['G'] = M['G']['T'] = M['-']['G'] = M['G']['-'] = -2;
M['C']['G'] = M['G']['C'] = M['-']['A'] = M['A']['-'] = -3;
M['-']['C'] = M['C']['-'] = -4;
}
int main()
{
ios::sync_with_stdio(false); cin.tie(0); cout.tie(0);
matrix();
int t; cin >> t;
while (t--){
//初始化&讀入
char s1[maxn], s2[maxn];
int len1, len2;
cin >> len1 >> s1+1; cin >> len2 >> s2+1;//將字串輸入到s1中,且從s1[1]開始輸入
//scanf("%d %s", &len2, s2 + 1);
//處理
dp[0][0] = 0;
for (int i = 1; i <= len1; i++)
dp[i][0] = dp[i - 1][0] + M[s1[i]]['-'];
for (int j = 1; j <= len2; j++)
dp[0][j] = dp[0][j - 1] + M['-'][s2[j]];
for (int i = 1; i <= len1; i++){
for (int j = 1; j <= len2; j++){
dp[i][j] = max(dp[i - 1][j - 1] + M[s1[i]][s2[j]],
max(dp[i - 1][j] + M[s1[i]]['-'],
dp[i][j - 1] + M['-'][s2[j]]));
}
}
//輸出
cout << dp[len1][len2] << endl;
}
return 0;
}
- 總結:1.C++陣列下標可以是字符(ASCII碼:a-97,A-65, - 45)
2.陣列及賦值,可以放在一個函式中,main中再呼叫一次即可,
3.char c[5];
scanf("%s",c+1);//用指標的方式,傳入一個字串,直到遇到空格,
4.max對比多個數:max(a,max(b,c));
六、Hirschberg’s algorithm 赫施伯格演算法
七、Bellman-Ford algorithm 貝爾曼-福特演算法
八、distance vector protocols 距離向量協議
九、negative cycles in a digraph 有向圖中的負圈
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/216271.html
標籤:其他
上一篇:滑鼠拓展性
下一篇:失業日記 11月11日