GCN實戰深入淺出圖神經網路第五章:基于Cora資料集的GCN節點分類 代碼分析
文章目錄
- GCN實戰深入淺出圖神經網路第五章:基于Cora資料集的GCN節點分類 代碼分析
- SetUp,庫宣告
- 資料準備
- 圖卷積層定義
- 模型定義
- 模型訓練
SetUp,庫宣告
In [2]:
import itertools
import os
import os.path as osp
import pickle
import urllib
from collections import namedtuple
import numpy as np
import scipy.sparse as sp
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.nn.init as init
import torch.optim as optim
import matplotlib.pyplot as plt
%matplotlib inline
資料準備
Cora資料集說明
├── gcn
│ ├── data //圖資料
│ │ ├── ind.citeseer.allx
│ │ ├── ind.citeseer.ally
│ │ ├── ind.citeseer.graph
│ │ ├── ind.citeseer.test.index
│ │ ├── ind.citeseer.tx # 1
│ │ ├── ind.citeseer.ty # 2
│ │ ├── ind.citeseer.x # 3
│ │ ├── ind.citeseer.y # 4
│ │ ├── ind.cora.allx
│ │ ├── ind.cora.ally
│ │ ├── ind.cora.graph
│ │ ├── ind.cora.test.index
│ │ ├── ind.cora.tx
│ │ ├── ind.cora.ty
│ │ ├── ind.cora.x
│ │ ├── ind.cora.y
│ │ ├── ind.pubmed.allx
│ │ ├── ind.pubmed.ally
│ │ ├── ind.pubmed.graph
│ │ ├── ind.pubmed.test.index
│ │ ├── ind.pubmed.tx
│ │ ├── ind.pubmed.ty
│ │ ├── ind.pubmed.x
│ │ └── ind.pubmed.y
│ ├── __init__.py
│ ├── inits.py //初始化的公用函式
│ ├── layers.py //GCN層定義
│ ├── metrics.py //評測指標的計算
│ ├── models.py //模型結構定義
│ ├── train.py //訓練
│ └── utils.py //工具函式的定義
├── LICENCE
├── README.md
├── requirements.txt
└── setup.py
實驗時可能出現資料集下載出錯的問題,可以自行下載,放行程式預定的檔案夾即可
download_url = https://wwe.lanzous.com/iFiGKib18fi
cora讀取的檔案說明:
ind.cora.x => 訓練實體的特征向量,是scipy.sparse.csr.csr_matrix類物件,shape:(140, 1433),由于ind.cora.x的資料包含于 allx 中,所以實驗中沒有讀取 x
ind.cora.tx => 測驗實體的特征向量,shape:(1000, 1433)
ind.cora.allx => 有標簽的+無無標簽訓練實體的特征向量,是ind.dataset_str.x的超集,shape:(1708, 1433)
# 實驗中的完整的特征向量是有(allx,tx)拼接而成,(2708,1433),在實際訓練是整體訓練,只有當要計算損失值和精確度時才用掩碼從(allx,tx)截取相應的輸出
ind.cora.y => 訓練實體的 標簽,獨熱編碼,numpy.ndarray類的實體,是numpy.ndarray物件,shape:(140, 7)
ind.cora.ty => 測驗實體的標簽,獨熱編碼,numpy.ndarray類的實體,shape:(1000, 7)
ind.cora.ally => 對應于ind.dataset_str.allx的標簽,獨熱編碼,shape:(1708, 7)
# 同樣是(ally,ty)拼接
ind.cora.graph => 圖資料,collections.defaultdict類的實體,格式為 {index:[index_of_neighbor_nodes]}
ind.cora.test.index => 測驗實體的id,(1000,)
In [3]:
Data = namedtuple('Data', ['x', 'y', 'adjacency',
'train_mask', 'val_mask', 'test_mask'])
def tensor_from_numpy(x, device):
return torch.from_numpy(x).to(device)
class CoraData(object):
download_url = "https://github.com/kimiyoung/planetoid/raw/master/data"
filenames = ["ind.cora.{}".format(name) for name in
['x', 'tx', 'allx', 'y', 'ty', 'ally', 'graph', 'test.index']]
def __init__(self, data_root="cora", rebuild=False):
"""Cora資料,包括資料下載,處理,加載等功能
當資料的快取檔案存在時,將使用快取檔案,否則將下載、進行處理,并快取到磁盤
處理之后的資料可以通過屬性 .data 獲得,它將回傳一個資料物件,包括如下幾部分:
* x: 節點的特征,維度為 2708 * 1433,型別為 np.ndarray
* y: 節點的標簽,總共包括7個類別,型別為 np.ndarray
* adjacency: 鄰接矩陣,維度為 2708 * 2708,型別為 scipy.sparse.coo.coo_matrix
* train_mask: 訓練集掩碼向量,維度為 2708,當節點屬于訓練集時,相應位置為True,否則False
* val_mask: 驗證集掩碼向量,維度為 2708,當節點屬于驗證集時,相應位置為True,否則False
* test_mask: 測驗集掩碼向量,維度為 2708,當節點屬于測驗集時,相應位置為True,否則False
Args:
-------
data_root: string, optional
存放資料的目錄,原始資料路徑: {data_root}/raw
快取資料路徑: {data_root}/processed_cora.pkl
rebuild: boolean, optional
是否需要重新構建資料集,當設為True時,如果存在快取資料也會重建資料
"""
self.data_root = data_root
save_file = osp.join(self.data_root, "processed_cora.pkl")
if osp.exists(save_file) and not rebuild:
print("Using Cached file: {}".format(save_file))
self._data = pickle.load(open(save_file, "rb"))
else:
self.maybe_download()
self._data = self.process_data()
with open(save_file, "wb") as f:
pickle.dump(self.data, f)
print("Cached file: {}".format(save_file))
@property
def data(self):
"""回傳Data資料物件,包括x, y, adjacency, train_mask, val_mask, test_mask"""
return self._data
def process_data(self):
"""
處理資料,得到節點特征和標簽,鄰接矩陣,訓練集、驗證集以及測驗集
參考自:https://github.com/rusty1s/pytorch_geometric
"""
print("Process data ...")
_, tx, allx, y, ty, ally, graph, test_index = [self.read_data(
osp.join(self.data_root, "raw", name)) for name in self.filenames]
# 測驗test_index的形狀(1000,),如果那里不明白可以測驗輸出一下矩陣形狀
print('test_index',test_index.shape)
train_index = np.arange(y.shape[0]) # [0,...139] 140個元素
print('train_index',train_index.shape)
val_index = np.arange(y.shape[0], y.shape[0] + 500) # [140 - 640] 500個元素
print('val_index',val_index.shape)
sorted_test_index = sorted(test_index) # #test_index就是隨機選取的下標,排下序
# print('test_index',sorted_test_index)
x = np.concatenate((allx, tx), axis=0) # 1708 +1000 =2708 特征向量
y = np.concatenate((ally, ty), axis=0).argmax(axis=1) # 把最大值的下標重新作為一個陣列 標簽向量
x[test_index] = x[sorted_test_index] # 打亂順序,單純給test_index 的資料排個序,不清楚具體效果
y[test_index] = y[sorted_test_index]
num_nodes = x.shape[0] #2078
train_mask = np.zeros(num_nodes, dtype=np.bool) # 生成零向量
val_mask = np.zeros(num_nodes, dtype=np.bool)
test_mask = np.zeros(num_nodes, dtype=np.bool)
train_mask[train_index] = True # 前140個元素為訓練集
val_mask[val_index] = True # 140 -639 500個
test_mask[test_index] = True # 1708-2708 1000個元素
#下面兩句是我測驗用的,本來代碼沒有
#是為了知道使用掩碼后,y_train_mask 的形狀,由輸出來說是(140,)
# 這就是后面劃分訓練集的方法
y_train_mask = y[train_mask]
print('y_train_mask',y_train_mask.shape)
#構建鄰接矩陣
adjacency = self.build_adjacency(graph)
print("Node's feature shape: ", x.shape)
print("Node's label shape: ", y.shape)
print("Adjacency's shape: ", adjacency.shape)
print("Number of training nodes: ", train_mask.sum())
print("Number of validation nodes: ", val_mask.sum())
print("Number of test nodes: ", test_mask.sum())
return Data(x=x, y=y, adjacency=adjacency,
train_mask=train_mask, val_mask=val_mask, test_mask=test_mask)
def maybe_download(self):
save_path = os.path.join(self.data_root, "raw")
for name in self.filenames:
if not osp.exists(osp.join(save_path, name)):
self.download_data(
"{}/{}".format(self.download_url, name), save_path)
@staticmethod
def build_adjacency(adj_dict):
"""根據鄰接表創建鄰接矩陣"""
edge_index = []
num_nodes = len(adj_dict)
print('num_nodesaaaaaaaaaaaa',num_nodes)
for src, dst in adj_dict.items(): # 格式為 {index:[index_of_neighbor_nodes]}
edge_index.extend([src, v] for v in dst) #
edge_index.extend([v, src] for v in dst)
# 去除重復的邊
edge_index = list(k for k, _ in itertools.groupby(sorted(edge_index))) # 以輪到的元素為k,每個k對應一個陣列,和k相同放進陣列,不
# 同再生成一個k,sorted()是以第一個元素大小排序
edge_index = np.asarray(edge_index)
#稀疏矩陣 存盤非0值 節省空間
adjacency = sp.coo_matrix((np.ones(len(edge_index)),
(edge_index[:, 0], edge_index[:, 1])),
shape=(num_nodes, num_nodes), dtype="float32")
return adjacency
@staticmethod
def read_data(path):
"""使用不同的方式讀取原始資料以進一步處理"""
name = osp.basename(path)
if name == "ind.cora.test.index":
out = np.genfromtxt(path, dtype="int64")
return out
else:
out = pickle.load(open(path, "rb"), encoding="latin1")
out = out.toarray() if hasattr(out, "toarray") else out
return out
@staticmethod
def download_data(url, save_path):
"""資料下載工具,當原始資料不存在時將會進行下載"""
if not os.path.exists(save_path):
os.makedirs(save_path)
data = urllib.request.urlopen(url)
filename = os.path.split(url)[-1]
with open(os.path.join(save_path, filename), 'wb') as f:
f.write(data.read())
return True
@staticmethod
def normalization(adjacency):
"""計算 L=D^-0.5 * (A+I) * D^-0.5"""
adjacency += sp.eye(adjacency.shape[0]) # 增加自連接
degree = np.array(adjacency.sum(1))
d_hat = sp.diags(np.power(degree, -0.5).flatten())
return d_hat.dot(adjacency).dot(d_hat).tocoo() #回傳稀疏矩陣的coo_matrix形式
# 這樣可以單獨測驗Process_data函式
a = CoraData()
a.process_data()
Out[3]:
Using Cached file: cora\processed_cora.pkl
Process data ...
test_index (1000,)
train_index (140,)
val_index (500,)
y_train_mask (140,)
num_nodesaaaaaaaaaaaa 2708
Node's feature shape: (2708, 1433)
Node's label shape: (2708,)
Adjacency's shape: (2708, 2708)
Number of training nodes: 140
Number of validation nodes: 500
Number of test nodes: 1000
Data(x=array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]], dtype=float32), y=array([3, 4, 4, ..., 3, 3, 3], dtype=int64), adjacency=<2708x2708 sparse matrix of type '<class 'numpy.float32'>'
with 10556 stored elements in COOrdinate format>, train_mask=array([ True, True, True, ..., False, False, False]), val_mask=array([False, False, False, ..., False, False, False]), test_mask=array([False, False, False, ..., True, True, True]))
圖卷積層定義
In [13]:
class GraphConvolution(nn.Module):
def __init__(self, input_dim, output_dim, use_bias=True):
"""圖卷積:L*X*\theta
完整GCN函式
f = sigma(D^-1/2 A D^-1/2 * H * W)
卷積是D^-1/2 A D^-1/2 * H * W
adjacency = D^-1/2 A D^-1/2 已經經過歸一化,標準化的拉普拉斯矩陣
這樣就把傅里葉變化和拉普拉斯矩陣結合起來了.
Args:
----------
input_dim: int
節點輸入特征的維度
output_dim: int
輸出特征維度
use_bias : bool, optional
是否使用偏置
"""
super(GraphConvolution, self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.use_bias = use_bias
# 定義GCN層的 W 權重形狀
self.weight = nn.Parameter(torch.Tensor(input_dim, output_dim))
#定義GCN層的 b 權重矩陣
if self.use_bias:
self.bias = nn.Parameter(torch.Tensor(output_dim))
else:
self.register_parameter('bias', None)
self.reset_parameters()
# 這里才是宣告初始化 nn.Module 類里面的W,b引數
def reset_parameters(self):
init.kaiming_uniform_(self.weight)
if self.use_bias:
init.zeros_(self.bias)
def forward(self, adjacency, input_feature):
"""鄰接矩陣是稀疏矩陣,因此在計算時使用稀疏矩陣乘法
Args:
-------
adjacency: torch.sparse.FloatTensor
鄰接矩陣
input_feature: torch.Tensor
輸入特征
"""
support = torch.mm(input_feature, self.weight) # 矩陣相乘 m由matrix縮寫
output = torch.sparse.mm(adjacency, support) # sparse 稀疏的
if self.use_bias:
output += self.bias # bias 偏置,偏見
return output
# 一般是為了列印類實體的資訊而重寫的內置函式
def __repr__(self):
return self.__class__.__name__ + ' (' \
+ str(self.input_dim) + ' -> ' \
+ str(self.output_dim) + ')'
模型定義
讀者可以自己對GCN模型結構進行修改和實驗
In [14]:
class GcnNet(nn.Module):
"""
定義一個包含兩層GraphConvolution的模型
"""
def __init__(self, input_dim=1433):
super(GcnNet, self).__init__()
self.gcn1 = GraphConvolution(input_dim, 16) #(N,1433)->(N,16)
self.gcn2 = GraphConvolution(16, 7) #(N,16)->(N,7)
def forward(self, adjacency, feature):
h = F.relu(self.gcn1(adjacency, feature)) #(N,1433)->(N,16),經過relu函式
logits = self.gcn2(adjacency, h) #(N,16)->(N,7)
return logits
模型訓練
In [16]:
# 超引數定義
LEARNING_RATE = 0.1 #學習率
WEIGHT_DACAY = 5e-4 #正則化系數 weight_dacay
EPOCHS = 200 #完整遍歷訓練集的次數
DEVICE = "cuda" if torch.cuda.is_available() else "cpu" #設備
# 如果當前顯卡忙于其他作業,可以設定為 DEVICE = "cpu",使用cpu運行
In [17]:
# 加載資料,并轉換為torch.Tensor
dataset = CoraData().data
node_feature = dataset.x / dataset.x.sum(1, keepdims=True) # 歸一化資料,使得每一行和為1
tensor_x = tensor_from_numpy(node_feature, DEVICE) # (2708,1433)
tensor_y = tensor_from_numpy(dataset.y, DEVICE) #(2708,)
tensor_train_mask = tensor_from_numpy(dataset.train_mask, DEVICE) #前140個為True
tensor_val_mask = tensor_from_numpy(dataset.val_mask, DEVICE) # 140 - 639 500個
tensor_test_mask = tensor_from_numpy(dataset.test_mask, DEVICE) # 1708 - 2707 1000個
normalize_adjacency = CoraData.normalization(dataset.adjacency) # 規范化鄰接矩陣 計算 L=D^-0.5 * (A+I) * D^-0.5
num_nodes, input_dim = node_feature.shape # 2708,1433
# 原始創建coo_matrix((data, (row, col)), shape=(4, 4)) indices為index復數 https://blog.csdn.net/chao2016/article/details/80344828?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522160509865819724838529777%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=160509865819724838529777&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_v2~rank_v28-2-80344828.pc_first_rank_v2_rank_v28&utm_term=%E7%A8%80%E7%96%8F%E7%9F%A9%E9%98%B5%E7%9A%84coo_matrix&spm=1018.2118.3001.4449
indices = torch.from_numpy(np.asarray([normalize_adjacency.row,
normalize_adjacency.col]).astype('int64')).long()
values = torch.from_numpy(normalize_adjacency.data.astype(np.float32))
tensor_adjacency = torch.sparse.FloatTensor(indices, values,
(num_nodes, num_nodes)).to(DEVICE)
#根據三元組 構造 稀疏矩陣向量,構造出來的張量是 (2708,2708)
In [18]:
# 模型定義:Model, Loss, Optimizer
model = GcnNet(input_dim).to(DEVICE)
criterion = nn.CrossEntropyLoss().to(DEVICE) # criterion評判標準
optimizer = optim.Adam(model.parameters(), # optimizer 優化程式 ,使用Adam 優化方法,權重衰減https://blog.csdn.net/program_developer/article/details/80867468
lr=LEARNING_RATE,
weight_decay=WEIGHT_DACAY)
In [8]:
# 訓練主體函式
def train():
loss_history = []
val_acc_history = []
model.train()
train_y = tensor_y[tensor_train_mask] # shape=(140,)不是(2708,)了
# 共進行200次訓練
for epoch in range(EPOCHS):
logits = model(tensor_adjacency, tensor_x) # 前向傳播,認為因為宣告了 model.train(),不用forward了
train_mask_logits = logits[tensor_train_mask] # 只選擇訓練節點進行監督 (140,)
loss = criterion(train_mask_logits, train_y) # 計算損失值
optimizer.zero_grad() # 梯度歸零
loss.backward() # 反向傳播計算引數的梯度
optimizer.step() # 使用優化方法進行梯度更新
train_acc, _, _ = test(tensor_train_mask) # 計算當前模型訓練集上的準確率 呼叫test函式
val_acc, _, _ = test(tensor_val_mask) # 計算當前模型在驗證集上的準確率
# 記錄訓練程序中損失值和準確率的變化,用于畫圖
loss_history.append(loss.item())
val_acc_history.append(val_acc.item())
print("Epoch {:03d}: Loss {:.4f}, TrainAcc {:.4}, ValAcc {:.4f}".format(
epoch, loss.item(), train_acc.item(), val_acc.item()))
return loss_history, val_acc_history
In [9]:
# 測驗函式
def test(mask):
model.eval() # 表示將模型轉變為evaluation(測驗)模式,這樣就可以排除BN和Dropout對測驗的干擾
with torch.no_grad(): # 顯著減少顯存占用
logits = model(tensor_adjacency, tensor_x) #(N,16)->(N,7) N節點數
test_mask_logits = logits[mask] # 矩陣形狀和mask一樣
predict_y = test_mask_logits.max(1)[1] # 回傳每一行的最大值中索引(回傳最大元素在各行的列索引)
accuarcy = torch.eq(predict_y, tensor_y[mask]).float().mean()
return accuarcy, test_mask_logits.cpu().numpy(), tensor_y[mask].cpu().numpy()
In [13]:
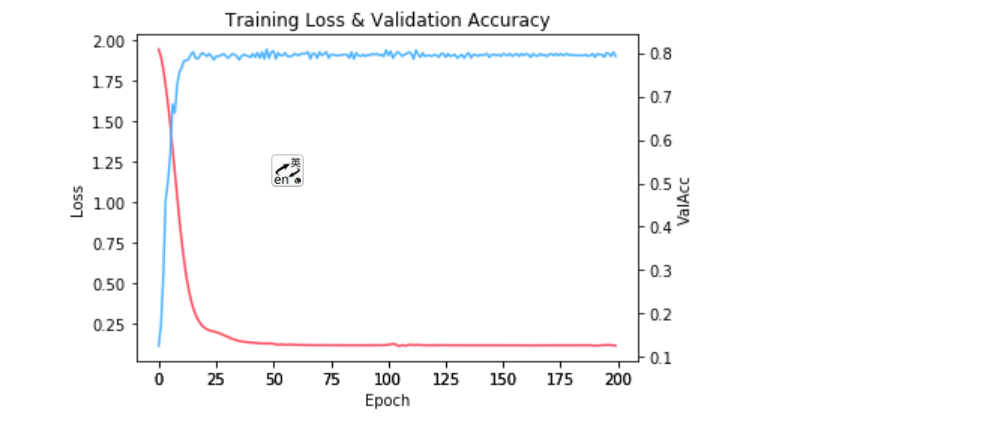
def plot_loss_with_acc(loss_history, val_acc_history):
fig = plt.figure()
# 坐標系ax1畫曲線1
ax1 = fig.add_subplot(111) # 指的是將plot界面分成1行1列,此子圖占據從左到右從上到下的1位置
ax1.plot(range(len(loss_history)), loss_history,
c=np.array([255, 71, 90]) / 255.) # c為顏色
plt.ylabel('Loss')
# 坐標系ax2畫曲線2
ax2 = fig.add_subplot(111, sharex=ax1, frameon=False) # 其本質就是添加坐標系,設定共享ax1的x軸,ax2背景透明
ax2.plot(range(len(val_acc_history)), val_acc_history,
c=np.array([79, 179, 255]) / 255.)
ax2.yaxis.tick_right() # 開啟右邊的y坐標
ax2.yaxis.set_label_position("right")
plt.ylabel('ValAcc')
plt.xlabel('Epoch')
plt.title('Training Loss & Validation Accuracy')
plt.show()
In [ ]:
loss, val_acc = train()
test_acc, test_logits, test_label = test(tensor_test_mask)
print("Test accuarcy: ", test_acc.item())
In [14]:
plot_loss_with_acc(loss, val_acc)
,
,
,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/216455.html
標籤:其他