作者|Soner Y?ld?r?m
編譯|VK
來源|Towards Data Science

資料結構是任何編程語言的關鍵部分,為了創建健壯且性能良好的產品,必須非常了解資料結構,
在這篇文章中,我們將研究Python編程語言的一個重要資料結構,即字典,
字典是鍵值對的無序集合,每個項都有一個鍵和值,字典可以看作是一個有特殊索引的串列,
鍵必須是唯一的和不可變的,我們可以使用字串、數字(int或float)或元組作為鍵,值可以是任何型別,
考慮一個我們需要存盤學生成績的案例,我們可以把它們存盤在字典或串列中,
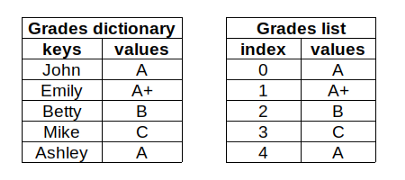
使用字典可以讓我們通過提供學生姓名(key)來獲取每個學生的成績,另一方面,為了能夠獲得某個學生的成績,我們需要一個額外的串列,
新的串列包含學生的姓名,并且與成績串列的順序完全相同,
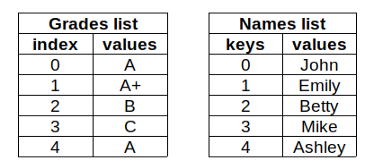
因此,對于這種情況,字典比串列更好,
在簡短的介紹之后,讓我們從示例開始深入研究字典,這些例子將涵蓋字典的特性,以及對它們進行操作的函式和方法,
1.創建字典
我們可以通過在大括號之間提供0個或多個鍵值對來創建字典,
empty_dict = {}
grades = {'John':'A', 'Emily':'A+', 'Betty':'B', 'Mike':'C', 'Ashley':'A'}
grades
{'Ashley': 'A', 'Betty': 'B', 'Emily': 'A+', 'John': 'A', 'Mike': 'C'}
2.訪問值
我們通過提供索引來訪問串列中的值,類似地,在字典中,通過使用鍵來訪問值,
grades['John']
'A'
grades.get('Betty')
'B'
3.訪問所有值或所有鍵
keys方法用于獲取所有鍵,
grades.keys()
dict_keys(['John', 'Emily', 'Betty', 'Mike', 'Ashley'])
回傳物件是dict_keys物件,它是iterable型別,因此,我們可以在for回圈中迭代它,
類似地,values方法回傳所有值,
grades.values()
dict_values(['A', 'A+', 'B', 'C', 'A'])
我們不能對dict_keys 或dict_values進行索引操作,但我們可以將它們轉換為一個串列,然后使用索引,
list(grades.values())[0]
'A'
items方法回傳鍵值對,
grades.items()
dict_items([('John', 'A'), ('Emily', 'A+'), ('Betty', 'B'), ('Mike', 'C'), ('Ashley', 'A')])
4.更新或添加項
字典是可變的,所以我們可以更新、添加或洗掉條目,更新或添加項的語法是相同的,如果字典中存在給定的鍵,則更新現有項的值,否則,將創建一個新項(即鍵值對),
grades['Edward'] = 'B+'
grades['John'] = 'B'
grades
{'Ashley': 'A',
'Betty': 'B',
'Edward': 'B+',
'Emily': 'A+',
'John': 'B',
'Mike': 'C'}
5.使用新字典更新
我們也可以將字典傳遞給update函式,字典將根據新字典中的項進行更新,舉個例子會更清楚,
考慮以下字典:
grades = {'John':'A', 'Emily':'A+', 'Betty':'B', 'Mike':'C'}
grades_new = {'John':'B', 'Sam':'A', 'Betty':'A'}
如果我們根據grades_new更新grades ,John和Betty的值也會更新,此外,還將添加新項('Sam':'a'),
grades.update(grades_new)
grades
{'Betty': 'A', 'Emily': 'A+', 'John': 'B', 'Mike': 'C', 'Sam': 'A'}
6.洗掉項
我們可以使用del或pop函式洗掉項,我們只傳遞要洗掉的項的鍵,
del(grades['Edward'])
grades.pop('Ashley')
'A'
grades
'Betty': 'B', 'Emily': 'A+', 'John': 'B', 'Mike': 'C'}
與del函式不同,pop函式回傳已洗掉項的值,因此,我們可以選擇將其分配給一個變數,
7.字典作為iterable
我們可以迭代字典,默認情況下,迭代基于鍵,
for i in grades:
print(i)
John
Emily
Betty
Mike
我們也可以對值進行迭代(grades.values()或grades.items()).
8.字典生成式
它類似于串列生成式,字典生成式是一種基于iterables的字典創建方法,
{x: x**2 for x in range(5)}
{0: 0, 1: 1, 2: 4, 3: 9, 4: 16}
{word: len(word) for word in ['data','science','is','awesome']}
{'awesome': 7, 'data': 4, 'is': 2, 'science': 7}
iterable中的元素成為字典的鍵,這些值是根據字典生成式中的賦值確定的,
9.從串列創建字典
我們可以使用串列或元組串列創建字典,
a = [['A',4], ['B',5], ['C',11]]
dict(a)
{'A': 4, 'B': 5, 'C': 11}
b = [('A',4), ('B',5), ('C',11)]
dict(b)
{'A': 4, 'B': 5, 'C': 11}
10.從字典到資料幀
Pandas的dataframe函式可用于使用字典創建資料幀,鍵變成列名,值變成行,
到目前為止,我們已經用值為字串的字典做了一些示例,但是,字典中的值可以是任何型別,例如串列、numpy陣列、其他字典等等,
在從字典創建資料幀的情況下,值由陣列組成(例如list、numpy array),
import numpy as np
import pandas as pd
dict_a = {'names':['Amber','John','Edward','Emily'],
'points':np.random.randint(100, size=4)}
df = pd.DataFrame(dict_a)
df

11.len和clear
len函式回傳字典中的項數(即長度),clear方法用于洗掉字典中的所有項,因此我們將得到一個空字典,
len(grades)
4
grades.clear()
len(grades)
0
12.復制字典
grades = {'John':'A', 'Emily':'A+', 'Betty':'B'}
dict1 = grades
dict2 = grades.copy()
dict3 = dict(grades)
所有dict1、dict2和dict3都包含與分數完全相同的鍵值對,然而,dict1只是一個指向grades的指標,因此,grades的任何變化也會改變dict1,
dict2和dict3是記憶體中獨立的物件,因此它們不會受到grades變化的影響,
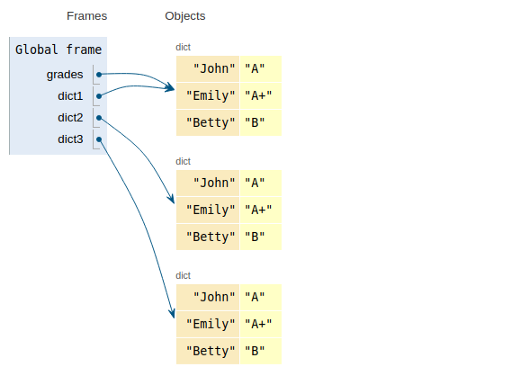
我們需要特別注意我們如何復制字典,
好處:使用python3.9合并和更新運算子
Python3.9為字典提供了merge(“|”)和update(“|=”)運算子,我還沒有安裝Python 3.9,所以我將使用Python檔案中的示例:
>>> x = {"key1": "value1 from x", "key2": "value2 from x"}
>>> y = {"key2": "value2 from y", "key3": "value3 from y"}
>>> x | y
{'key1': 'value1 from x', 'key2': 'value2 from y', 'key3': 'value3 from y'}
>>> y | x
{'key2': 'value2 from x', 'key3': 'value3 from y', 'key1': 'value1 from x'}
字典是Python中非常重要的資料結構,在許多情況下都會用到,我們在這篇文章中所做的例子將涵蓋你需要了解的字典的大部分內容,
然而,當然還有更多技巧,和其他技能一樣,熟能生巧,你會在不斷練習中掌握,
原文鏈接:https://towardsdatascience.com/12-examples-to-master-python-dictionaries-5a8bcd688c6d
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/218283.html
標籤:其他