前言
HashMap應該算是Java程式員面試的必問題,因為其中的知識點太多,很適合用來考察面試者的Java基礎,今天小編整理了一份大廠常問的HashMap面試題分享給大家,希望能給大家一點幫助,

一、HashMap的實作原理?
此題可以組成如下連環炮來問
你看過HashMap原始碼嘛,知道原理嘛?
為什么用陣列+鏈表?
hash沖突你還知道哪些解決辦法?
我用LinkedList代替陣列結構可以么?
既然是可以的,為什么HashMap不用LinkedList,而選用陣列?
1.你看過HashMap原始碼嘛,知道原理嘛?
針對這個問題,嗯,當然是必須看過HashMap原始碼,至于原理,下面那張圖很清楚了:
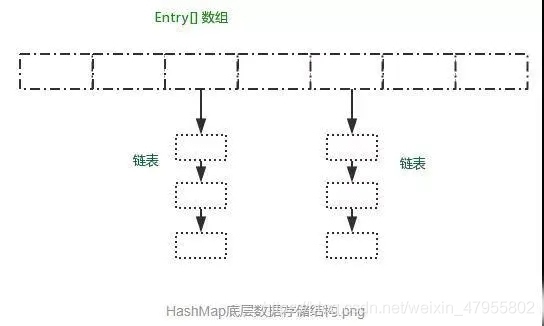
HashMap采用Entry陣列來存盤key-value對,每一個鍵值對組成了一個Entry物體,Entry類實際上是一個單向的鏈表結構,它具有Next指標,可以連接下一個Entry物體,
只是在JDK1.8中,鏈表長度大于8的時候,鏈表會轉成紅黑樹!
2.為什么用陣列+鏈表?
陣列是用來確定桶的位置,利用元素的key的hash值對陣列長度取模得到,
鏈表是用來解決hash沖突問題,當出現hash值一樣的情形,就在陣列上的對應位置形成一條鏈表,ps:這里的hash值并不是指hashcode,而是將hashcode高低十六位異或過的,至于為什么要這么做,繼續往下看,
3.hash沖突你還知道哪些解決辦法?
比較出名的有四種(1)開放定址法(2)鏈地址法(3)再哈希法(4)公共溢位區域法
ps:大家有興趣拓展的,自己去搜一下就懂了,這個就不拓展了!
4.我用LinkedList代替陣列結構可以么?
這里我稍微說明一下,此題的意思是,原始碼中是這樣的
Entry[] table = new Entry[capacity];
ps:Entry就是一個鏈表節點,
那我用下面這樣表示
List table = new LinkedList();
是否可行?
答案很明顯,必須是可以的,
5.既然是可以的,為什么HashMap不用LinkedList,而選用陣列?
因為用陣列效率最高!
在HashMap中,定位桶的位置是利用元素的key的哈希值對陣列長度取模得到,此時,我們已得到桶的位置,顯然陣列的查找效率比LinkedList大,
那ArrayList,底層也是陣列,查找也快啊,為啥不用ArrayList?
(煙哥寫到這里的時候,不禁覺得自己真有想法,自己把自己問死了,還好我靈機一動想出了答案)
因為采用基本陣列結構,擴容機制可以自己定義,HashMap中陣列擴容剛好是2的次冪,在做取模運算的效率高,
而ArrayList的擴容機制是1.5倍擴容,那ArrayList為什么是1.5倍擴容這就不在本文說明了,
二、HashMap在什么條件下擴容?
此題可以組成如下連環炮來問
HashMap在什么條件下擴容?
為什么擴容是2的n次冪?
為什么為什么要先高16位異或低16位再取模運算?
1.HashMap在什么條件下擴容?
如果bucket滿了(超過load factor*current capacity),就要resize,
load factor為0.75,為了最大程度避免哈希沖突
current capacity為當前陣列大小,
2.為什么擴容是2的次冪?
HashMap為了存取高效,要盡量較少碰撞,就是要盡量把資料分配均勻,每個鏈表長度大致相同,這個實作就在把資料存到哪個鏈表中的演算法;這個演算法實際就是取模,hash%length,
但是,大家都知道這種運算不如位移運算快,
因此,原始碼中做了優化hash&(length-1),
也就是說hash%length==hash&(length-1)
那為什么是2的n次方呢?
因為2的n次方實際就是1后面n個0,2的n次方-1,實際就是n個1,
例如長度為8時候,3&(8-1)=3 2&(8-1)=2 ,不同位置上,不碰撞,
而長度為5的時候,3&(5-1)=0 2&(5-1)=0,都在0上,出現碰撞了,
所以,保證容積是2的n次方,是為了保證在做(length-1)的時候,每一位都能&1 ,也就是和1111……1111111進行與運算,
3.為什么為什么要先高16位異或低16位再取模運算?
我先曬一下,jdk1.8里的hash方法,1.7的比較復雜,咱就不看了,

hashmap這么做,只是為了降低hash沖突的幾率,
打個比方,當我們的length為16的時候,哈希碼(字串“abcabcabcabcabc”的key對應的哈希碼)對(16-1)與操作,對于多個key生成的hashCode,只要哈希碼的后4位為0,不論不論高位怎么變化,最終的結果均為0,
如下圖所示

而加上高16位異或低16位的“擾動函式”后,結果如下
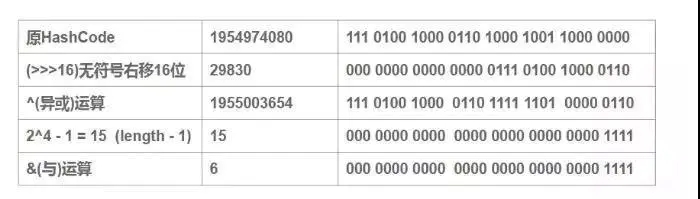
可以看到:擾動函式優化前:1954974080 % 16 = 1954974080 & (16 - 1) = 0 擾動函式優化后:1955003654 % 16 = 1955003654 & (16 - 1) = 6 很顯然,減少了碰撞的幾率,
三、講講hashmap的get/put的程序?
此題可以組成如下連環炮來問
知道hashmap中put元素的程序是什么樣么?
知道hashmap中get元素的程序是什么樣么?
你還知道哪些hash演算法?
說說String中hashcode的實作?(此題很多大廠問過)
1.知道hashmap中put元素的程序是什么樣么?
對key的hashCode()做hash運算,計算index;
如果沒碰撞直接放到bucket里;
如果碰撞了,以鏈表的形式存在buckets后;
如果碰撞導致鏈表過長(大于等于TREEIFY_THRESHOLD),就把鏈表轉換成紅黑樹(JDK1.8中的改動);
如果節點已經存在就替換old value(保證key的唯一性)
如果bucket滿了(超過load factor*current capacity),就要resize,
2.知道hashmap中get元素的程序是什么樣么?
對key的hashCode()做hash運算,計算index;
如果在bucket里的第一個節點里直接命中,則直接回傳;
如果有沖突,則通過key.equals(k)去查找對應的Entry;
若為樹,則在樹中通過key.equals(k)查找,O(logn);
若為鏈表,則在鏈表中通過key.equals(k)查找,O(n),
3.你還知道哪些hash演算法?
先說一下hash演算法干嘛的,Hash函式是指把一個大范圍映射到一個小范圍,把大范圍映射到一個小范圍的目的往往是為了節省空間,使得資料容易保存,
比較出名的有MurmurHash、MD4、MD5等等
4.說說String中hashcode的實作?(此題頻率很高)
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
String類中的hashCode計算方法還是比較簡單的,就是以31為權,每一位為字符的ASCII值進行運算,用自然溢位來等效取模,
哈希計算公式可以計為s[0]31^(n-1) + s[1]31^(n-2) + … + s[n-1]
那為什么以31為質數呢?
主要是因為31是一個奇質數,所以31i=32i-i=(i<<5)-i,這種位移與減法結合的計算相比一般的運算快很多,
四、為什么hashmap的在鏈表元素數量超過8時改為紅黑樹?
此題可以組成如下連環炮來問
知道jdk1.8中hashmap改了啥么?
為什么在解決hash沖突的時候,不直接用紅黑樹?而選擇先用鏈表,再轉紅黑樹?
我不用紅黑樹,用二叉查找樹可以么?
那為什么閥值是8呢?
當鏈表轉為紅黑樹后,什么時候退化為鏈表?
1.知道jdk1.8中hashmap改了啥么?
由陣列+鏈表的結構改為陣列+鏈表+紅黑樹,
優化了高位運算的hash演算法:h^(h>>>16)
擴容后,元素要么是在原位置,要么是在原位置再移動2次冪的位置,且鏈表順序不變,
最后一條是重點,因為最后一條的變動,hashmap在1.8中,不會在出現死回圈問題,
2.為什么在解決hash沖突的時候,不直接用紅黑樹?而選擇先用鏈表,再轉紅黑樹?
因為紅黑樹需要進行左旋,右旋,變色這些操作來保持平衡,而單鏈表不需要,
當元素小于8個當時候,此時做查詢操作,鏈表結構已經能保證查詢性能,當元素大于8個的時候,此時需要紅黑樹來加快查詢速度,但是新增節點的效率變慢了,
因此,如果一開始就用紅黑樹結構,元素太少,新增效率又比較慢,無疑這是浪費性能的,
3.我不用紅黑樹,用二叉查找樹可以么?
可以,但是二叉查找樹在特殊情況下會變成一條線性結構(這就跟原來使用鏈表結構一樣了,造成很深的問題),遍歷查找會非常慢,
4.那為什么閥值是8呢?
不知道,等jdk作者來回答,
這道題,網上能找到的答案都是扯淡,
我隨便貼一個牛客網的答案,如下圖所示

看出bug沒?交點是6.64?交點分明是4,好么,
log4=2,4/2=2,
jdk作者選擇8,一定經過了嚴格的運算,覺得在長度為8的時候,與其保證鏈表結構的查找開銷,不如轉換為紅黑樹,改為維持其平衡開銷,
5.當鏈表轉為紅黑樹后,什么時候退化為鏈表?
為6的時候退轉為鏈表,中間有個差值7可以防止鏈表和樹之間頻繁的轉換,假設一下,如果設計成鏈表個數超過8則鏈表轉換成樹結構,鏈表個數小于8則樹結構轉換成鏈表,如果一個HashMap不停的插入、洗掉元素,鏈表個數在8左右徘徊,就會頻繁的發生樹轉鏈表、鏈表轉樹,效率會很低,
五、HashMap的并發問題?
此題可以組成如下連環炮來問
HashMap在并發編程環境下有什么問題啊?
在jdk1.8中還有這些問題么?
你一般怎么解決這些問題的?
HashMap在并發編程環境下有什么問題啊?
(1)多執行緒擴容,引起的死回圈問題
(2)多執行緒put的時候可能導致元素丟失
(3)put非null元素后get出來的卻是null
在jdk1.8中還有這些問題么?
在jdk1.8中,死回圈問題已經解決,其他兩個問題還是存在,
你一般怎么解決這些問題的?
比如ConcurrentHashmap,Hashtable等執行緒安全等集合類,
六、你一般用什么作為HashMap的key?
此題可以組成如下連環炮來問
健可以為Null值么?
你一般用什么作為HashMap的key?
我用可變類當HashMap的key有什么問題?
如果讓你實作一個自定義的class作為HashMap的key該如何實作?
1.健可以為Null值么?
必須可以,key為null的時候,hash演算法最后的值以0來計算,也就是放在陣列的第一個位置,

2.你一般用什么作為HashMap的key?
一般用Integer、String這種不可變類當HashMap當key,而且String最為常用,
(1)因為字串是不可變的,所以在它創建的時候hashcode就被快取了,不需要重新計算,這就使得字串很適合作為Map中的鍵,字串的處理速度要快過其它的鍵物件,這就是HashMap中的鍵往往都使用字串,
(2)因為獲取物件的時候要用到equals()和hashCode()方法,那么鍵物件正確的重寫這兩個方法是非常重要的,這些類已經很規范的覆寫了hashCode()以及equals()方法,
3.我用可變類當HashMap的key有什么問題?
hashcode可能發生改變,導致put進去的值,無法get出,如下所示
HashMap<List, Object> changeMap = new HashMap<>();
List list = new ArrayList<>();
list.add(“hello”);
Object objectValue = new Object();
changeMap.put(list, objectValue);
System.out.println(changeMap.get(list));
list.add(“hello world”);//hashcode發生了改變
System.out.println(changeMap.get(list));
輸出值如下
java.lang.Object@74a14482
null
4.如果讓你實作一個自定義的class作為HashMap的key該如何實作?
此題考察兩個知識點
重寫hashcode和equals方法注意什么?
如何設計一個不變類
針對問題一,記住下面四個原則即可
(1)兩個物件相等,hashcode一定相等
(2)兩個物件不等,hashcode不一定不等
(3)hashcode相等,兩個物件不一定相等
(4)hashcode不等,兩個物件一定不等
針對問題二,記住如何寫一個不可變類
(1)類添加final修飾符,保證類不被繼承,
如果類可以被繼承會破壞類的不可變性機制,只要繼承類覆寫父類的方法并且繼承類可以改變成員變數值,那么一旦子類以父類的形式出現時,不能保證當前類是否可變,
(2)保證所有成員變數必須私有,并且加上final修飾
通過這種方式保證成員變數不可改變,但只做到這一步還不夠,因為如果是物件成員變數有可能再外部改變其值,所以第4點彌補這個不足,
(3)不提供改變成員變數的方法,包括setter
避免通過其他介面改變成員變數的值,破壞不可變特性,
(4)通過構造器初始化所有成員,進行深拷貝(deep copy)
如果構造器傳入的物件直接賦值給成員變數,還是可以通過對傳入物件的修改進而導致改變內部變數的值,例如:
public final class ImmutableDemo {
private final int[] myArray;
public ImmutableDemo(int[] array) {
this.myArray = array; // wrong
}
}
這種方式不能保證不可變性,myArray和array指向同一塊記憶體地址,用戶可以在ImmutableDemo之外通過修改array物件的值來改變myArray內部的值,
為了保證內部的值不被修改,可以采用深度copy來創建一個新記憶體保存傳入的值,正確做法:
public final class MyImmutableDemo {
private final int[] myArray;
public MyImmutableDemo(int[] array) {
this.myArray = array.clone();
}
}
(5)在getter方法中,不要直接回傳物件本身,而是克隆物件,并回傳物件的拷貝
這種做法也是防止物件外泄,防止通過getter獲得內部可變成員物件后對成員變數直接操作,導致成員變數發生改變,
總結
十月馬上就要過去了,還在找作業的小伙伴要抓緊時間了哦,
小編整理了大廠java程式員面試涉及到的絕大部分面試題及答案免費分享給大家,希望能幫助到大家,有需要的朋友可以看下面的免費領取方式!
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
領資料點這里:暗號CSDN
領資料點這里:暗號CSDN
↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑
最后感謝大家的支持,希望小編整理的資料能夠幫助到大家!也祝愿大家都能夠升職加薪!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/218821.html
標籤:其他
上一篇:溫度測量與pwm調解沖突