作者|Billy Fetzner
編譯|VK
來源|Towards Data Science
我認為,既然你點開了這個頁面,你可能有大量的資料需要分析,你可能正在想最好和最有效的方法來解決你資料的一些問題,你問題的答案可以通過Pandas解決,
如何接觸Pandas
由于Pandas的流行,它有自己的傳統縮寫,所以無論何時將Pandas匯入python,請使用以下命名:
import pandas as pd
Pandas包的主要用途是資料框
Pandas API將Pandas資料幀定義為:
二維、大小可變、潛在的異構表格資料,資料結構還包含軸(行和列),算術運算對行標簽和列標簽進行對齊,可以認為是一個類似于dict的容器,用于存盤序列物件,是Pandas主要的資料結構,
基本上,這意味著你有包含在格式中的資料,如下所示,在行和列中找到的資料:
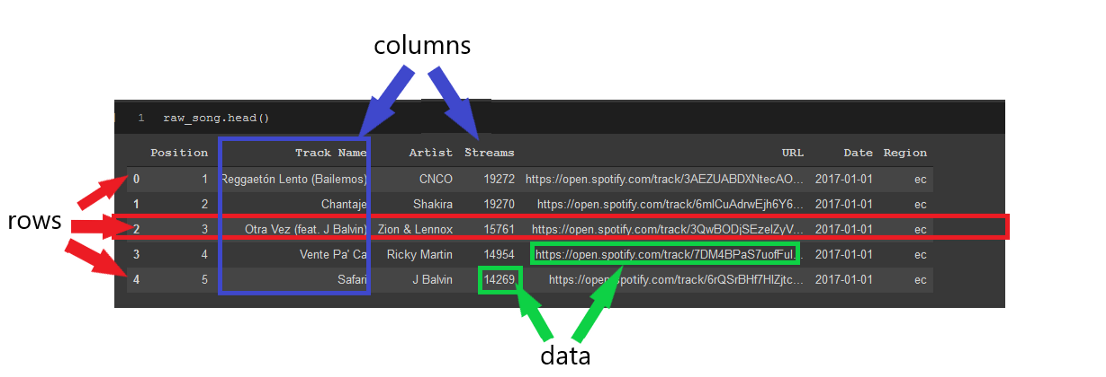
資料幀非常有用,因為它們提供了一種高效的方法來可視化資料,然后按你希望的方式操作資料,
這些行可以很容易地被索引參考,索引是資料幀最左邊的數字,索引將是從零開始的編號,除非你指定每一行的名稱,列也可以很容易地被列名稱(例如“Track name”)或其在資料幀中的位置進行參考,我們將在本文后面詳細討論參考行和列,
創建資料幀

創建Pandas資料幀的方法有幾種:
-
從.csv檔案匯入資料(或其他檔案型別,例如Excel、SQL資料庫)
-
從串列中
-
從字典里
-
從numpy陣列
-
其他
通常,你將主要將.csv檔案或某種型別的資料源的資料放入Pandas資料框架中,而不是從頭開始,因為這將需要非常長的時間來完成,這取決于你擁有的資料量,以下是python字典中的一個快速、簡單的示例:
import pandas as pd
dict1 = {'Exercises': ['Running','Walking','Cycling'],
'Mileage': [250, 1000, 550]}
df = pd.DataFrame(dict1)
df
輸出:
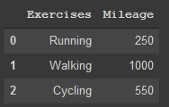
字典鍵(“Exercises”和“Mileage”)成為相應的列標題,字典中的值是本示例中的串列,成為資料幀中的單個資料點,Running是“Exercises”串列中的第一個,250將被列在第二列的第一個,另外,你會注意到,由于我沒有為資料幀的索引指定標簽,因此它會自動標記為0、1和2,
但是,就像我之前所說的,創建Pandas資料幀的最可能方法是從csv或其他型別的檔案中匯入,你將匯入該檔案來分析資料,只需以下內容即可輕松完成:
df = pd.read_csv("file_location.../file_name.csv")
pd.read_csv是一種非常強大和通用的方法,根據你希望如何匯入資料,它將非常有用,如果csv檔案已經附帶了頭或索引,則可以在匯入時指定,為了充分了解pd.read_csv,我建議你看看這里的PandasAPI:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html?highlight=read_csv
第一件事
現在你已經準備好了這個巨大的資料集,你必須查看它,看看它的外觀,作為一個分析這些資料的人,首先必須對資料集熟悉,并真正了解資料集中發生了什么,我喜歡用四種方法來了解我的資料,
- .head() & .tail()
- .info()
- .describe()
- .sample()
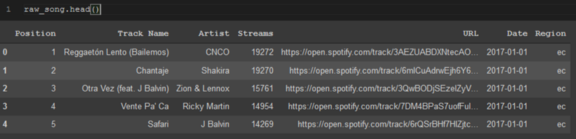
raw_song.head()
它顯示資料幀的前5行和每個列,以便你輕松地總結資料的外觀,你還可以在方法中指定一定數量的行,以顯示更多行,
.tail僅顯示最后5行,
raw_song.tail()
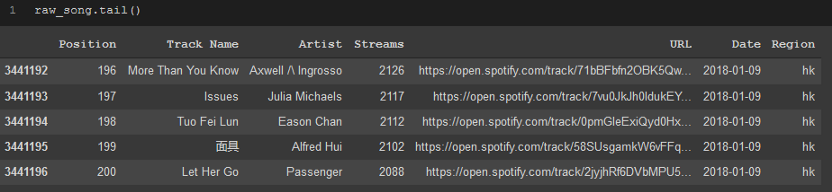
從這兩個快速方法中,我對列名和資料的外觀有了一個大致的了解,這只是從資料集的一個小樣本中得到的,這些方法也非常有用,尤其是對于Spotify資料集這樣的資料集,處理超過300萬行的資料時,你可以輕松地顯示資料集并快速了解資料,而且你的計算機也不會花很長時間來顯示資料,
.info也很有用,它向我顯示了所有列、它們的資料型別以及是否有null資料點,
raw_song.info(verbose=True, null_counts=True)
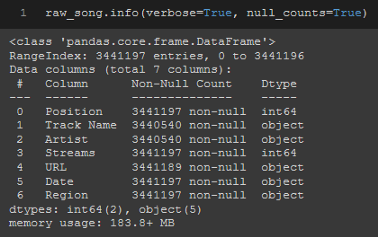
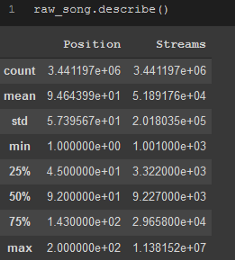
如果你有完整的整型或浮點型列(即'Position'、'Streams'),那么.describe是一個有用的方法,可以幫助你更好地了解資料集,因為它將顯示關于這些列的許多描述性統計資訊,
raw_song.describe()
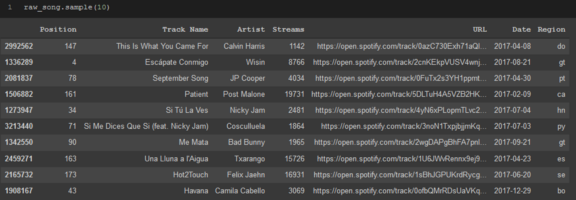
最后,.sample將允許你隨機對資料幀進行采樣,并查看你所做的任何操作是否錯誤地更改了資料集中的某些內容,而且當你第一次探索資料集時,也可以很好地了解資料集包含哪些內容
raw_song.sample(10)
在探索和準備資料集進行分析時,我始終使用這些方法,每當我更改列中的資料、更改列名或添加/洗掉行/列時,我都會通過至少快速運行前面5個方法中的一些來確保所有更改都按我希望的方式進行,
選擇行或列
太棒了,現在你知道如何將資料集作為一個整體來看待,但實際上你只想查看幾列或幾行,然后將其余部分排除在外,
.loc[]和.iloc[]
這兩個方法將以不同的方式來實作這一點,這取決于你能夠參考特定行或列的方式,
如果知道行或列的標簽,請使用.loc[],
如果知道行或列的索引,請使用.iloc[],
如果你兩者都知道,就選你最喜歡的,
因此,回到Spotify資料集,你可以使用.loc[]或.iloc[]查看列“Track Name”,如果知道列的標簽可以使用.loc[],所以我將使用以下內容:
raw_song.loc[:,'Track Name']
第一個括號后面的冒號指定我參考的行,由于我希望所有行都位于“Track Name”列中,所以我使用“:”,
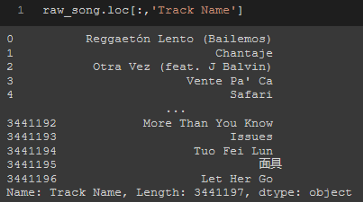
我將收到與.iloc[]相同的輸出,但這次需要指定“Track Name”列的索引:
raw_song.iloc[:,1]
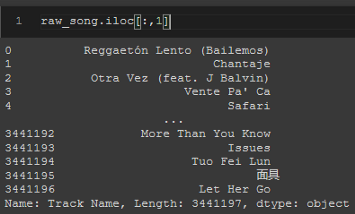
.loc[]和.iloc[]對行的作用相同,但在本例中,因為行的標簽和索引都是相同的,所以它們看起來完全相同,
切片

另一種獲取DataFrame部分的簡單方法是使用[]并在方括號內指定列名,
raw_song[['Artist','Streams']].head()
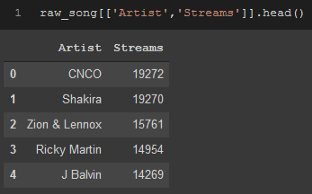
如果你只使用一列和一組括號,你將得到Pandas Series,
raw_song['Streams']
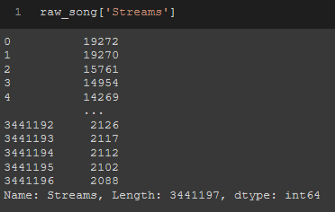
從資料幀添加行、列
利用我們已經從.loc[]獲得的資訊,我們可以使用this或.insert將行或列添加到資料幀中,
添加行
如果決定使用.loc[]將行添加到dataframe,則只能將其添加到dataframe的底部,指定dataframe中的任何其他索引,洗掉當前在該行中的資料,并用要插入的資料替換它,
raw_song.loc[3441197] = [0,'hello','bluemen',1,"https://open.spotify.com/track/notarealtrack", '2017-02-05','ec']
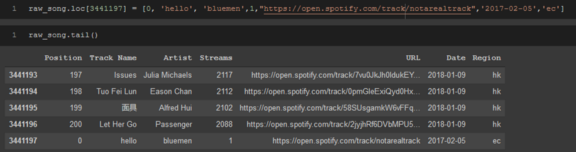
你也可以使用.loc[]將列添加到資料幀中,
raw_song.loc[:,'new_col'] = 0
raw_song.tail()
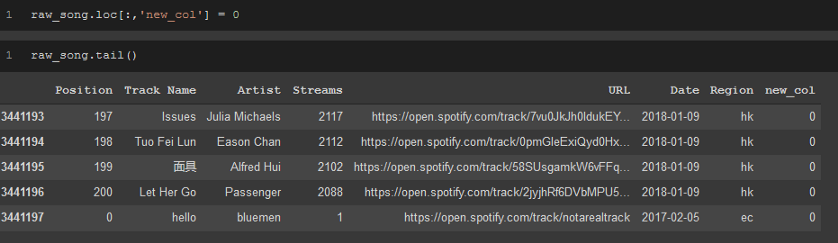
除了在末尾之外,還有兩種方法可以將新列插入資料幀中,
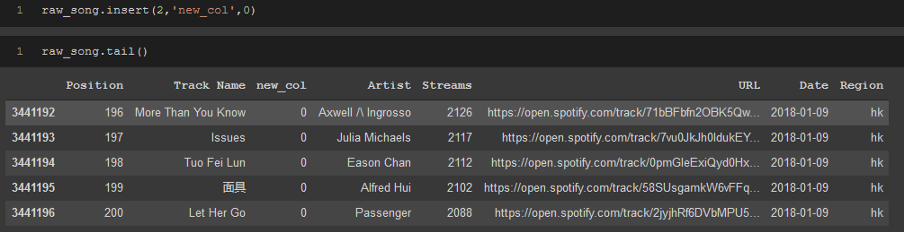
insert方法允許你指定要將列放入資料幀的位置,它接受3個引數、要放置它的索引、新列的名稱以及要作為列資料放置的值,
raw_song.insert(2,'new_col',0)
raw_song.tail()
將列添加到dataframe的第二種方法是通過使用[]命名新列并使其與新資料相等,從而使其成為dataframe的一部分,
raw_song['new_col'] = 0
raw_song.tail()
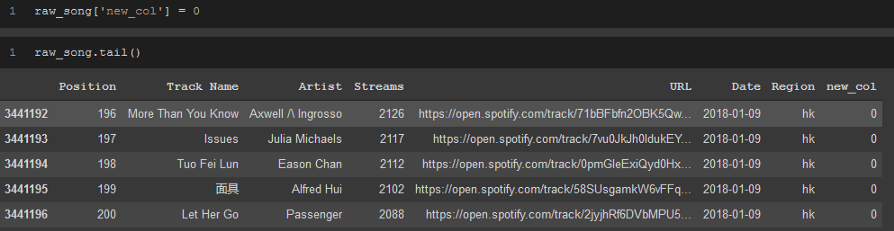
通過這種方式,我無法指定新列的位置,但這是執行該操作的另一種有用方法,
從資料幀中洗掉行、列

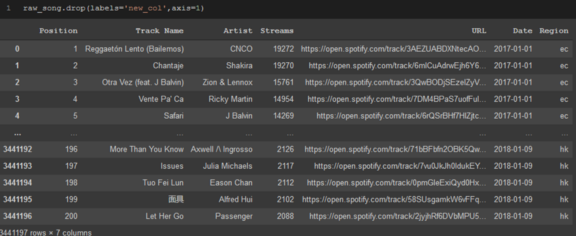
如果你想洗掉一些行或列,這很簡單,只需洗掉它們,
只需指定要洗掉的軸(行為0,列為1)和要洗掉的行或列的名稱,就可以開始了!
raw_song.drop(labels='new_col',axis=1)
重命名索引或列
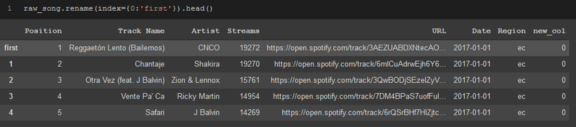
如果要將dataframe的索引更改為dataframe中的其他列,請使用.set_index并在括號中指定列的名稱,但是,如果你確切知道要為索引命名的內容,請使用.rename方法,
raw_song.rename(index={0:'first'}).head()
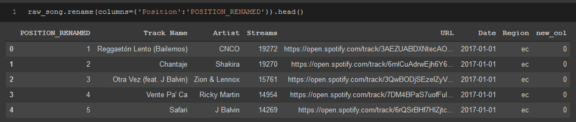
要重命名列,請在.rename方法中指定要重命名的列以及在{}中要為其命名的名稱,類似于重命名索引,
raw_song.rename(columns={'Position':'POSITION_RENAMED'}).head()
如何迭代資料幀
很多時候,當你處理資料幀中的資料時,你需要以某種方式更改資料并迭代資料幀中的所有值,最簡單的方法是在pandas中內置for回圈:
for index, col in raw_song.iterrows():
# 在此處操作資料
如何將資料幀寫入檔案
在完成對資料幀的所有操作之后,現在是匯出資料幀的時候了,以便可以將其發送到其他地方,與從檔案匯入資料集類似,現在正好相反,Pandas有多種不同的檔案型別,你可以將資料幀寫入其中,但最常見的是將其寫入csv檔案,
pd.to_csv('file_name.csv')
現在你知道Pandas和資料幀的基本知識了,這些是資料分析工具箱中非常強大的工具,
原文鏈接:https://towardsdatascience.com/an-introduction-to-pandas-29d15a7da6d
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/220972.html
標籤:其他
上一篇:散列沖突解決的方式
下一篇:四、功能測驗--邊界值分析法