原文鏈接:http://tecdat.cn/?p=17748
在資料科學學習之旅中,我經常處理日常作業中的時間序列資料集,并據此做出預測,
我將通過以下步驟:
探索性資料分析(EDA)
- 問題定義(我們要解決什么)
- 變數識別(我們擁有什么資料)
- 單變數分析(了解資料集中的每個欄位)
- 多元分析(了解不同領域和目標之間的相互作用)
- 缺失值處理
- 離群值處理
- 變數轉換
預測建模
- LSTM
- XGBoost
問題定義
我們在兩個不同的表中提供了商店的以下資訊:
- 商店:每個商店的ID
- 銷售:特定日期的營業額(我們的目標變數)
- 客戶:特定日期的客戶數量
- StateHoliday:假日
- SchoolHoliday:學校假期
- StoreType:4個不同的商店:a,b,c,d
- CompetitionDistance:到最近的競爭對手商店的距離(以米為單位)
- CompetitionOpenSince [月/年]:提供最近的競爭對手開放的大致年份和月份
- 促銷:當天促銷與否
- Promo2:Promo2是某些商店的連續和連續促銷:0 =商店不參與,1 =商店正在參與
- PromoInterval:描述促銷啟動的連續區間,并指定重新開始促銷的月份,
利用所有這些資訊,我們預測未來6周的銷售量,
# 讓我們匯入EDA所需的庫:
import numpy as np # 線性代數
import pandas as pd # 資料處理,CSV檔案I / O匯入(例如pd.read_csv)
import matplotlib.pyplot as plt
import seaborn as sns
from datetime import datetime
plt.style.use("ggplot") # 繪圖
#匯入訓練和測驗檔案:
train_df = pd.read_csv("../Data/train.csv")
test_df = pd.read_csv("../Data/test.csv")
#檔案中有多少資料:
print("在訓練集中,我們有", train_df.shape[0], "個觀察值和", train_df.shape[1], 列/變數,")
print("在測驗集中,我們有", test_df.shape[0], "個觀察值和", test_df.shape[1], "列/變數,")
print("在商店集中,我們有", store_df.shape[0], "個觀察值和", store_df.shape[1], "列/變數,")
在訓練集中,我們有1017209個觀察值和9列/變數,
在測驗集中,我們有41088個觀測值和8列/變數,
在商店集中,我們有1115個觀察值和10列/變數,
首先讓我們清理 訓練資料集,
#查看資料
train_df.head().append(train_df.tail()) #顯示前5行,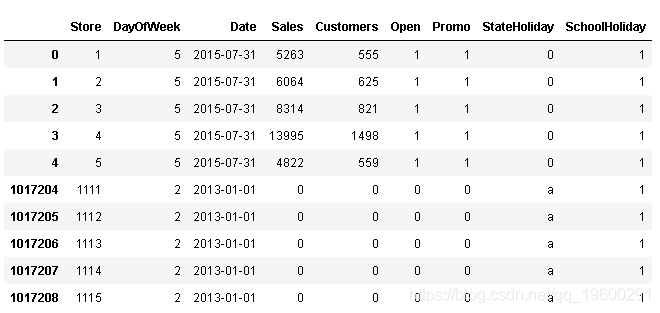
train_df.isnull().all()
Out[5]:
Store False
DayOfWeek False
Date False
Sales False
Customers False
Open False
Promo False
StateHoliday False
SchoolHoliday False
dtype: bool讓我們從第一個變數開始-> 銷售量
opened_sales = (train_df[(train_df.Open == 1) #如果商店開業
opened_sales.Sales.describe()
Out[6]:
count 422307.000000
mean 6951.782199
std 3101.768685
min 133.000000
25% 4853.000000
50% 6367.000000
75% 8355.000000
max 41551.000000
Name: Sales, dtype: float64
<matplotlib.axes._subplots.AxesSubplot at 0x7f7c38fa6588>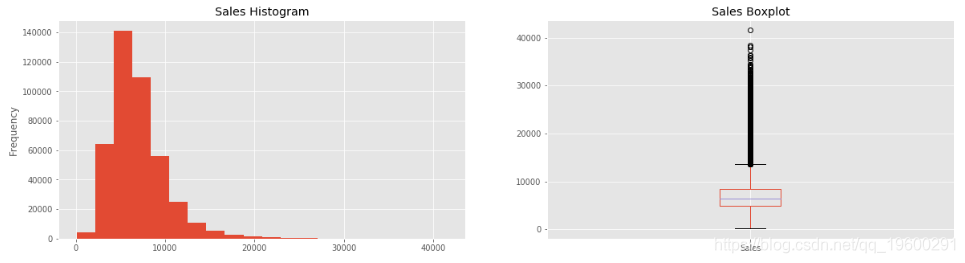
看一下顧客變數
In [9]:
train_df.Customers.describe()
Out[9]:
count 1.017209e+06
mean 6.331459e+02
std 4.644117e+02
min 0.000000e+00
25% 4.050000e+02
50% 6.090000e+02
75% 8.370000e+02
max 7.388000e+03
Name: Customers, dtype: float64
<matplotlib.axes._subplots.AxesSubplot at 0x7f7c3565d240>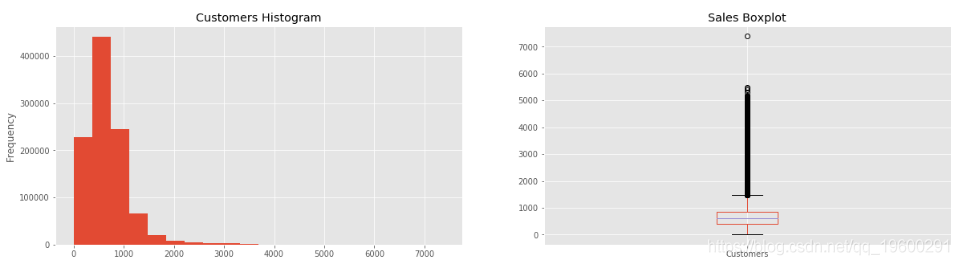
train_df[(train_df.Customers > 6000)]
我們看一下假期 變數,
train_df.StateHoliday.value_counts()
0 855087
0 131072
a 20260
b 6690
c 4100
Name: StateHoliday, dtype: int64
train_df.StateHoliday_cat.count()
1017209
train_df.tail()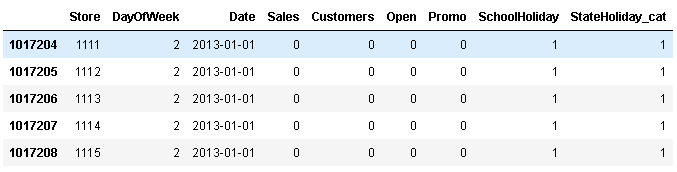
train_df.isnull().all() #檢查缺失
Out[18]:
Store False
DayOfWeek False
Date False
Sales False
Customers False
Open False
Promo False
SchoolHoliday False
StateHoliday_cat False
dtype: bool讓我們繼續進行商店分析
store_df.head().append(store_df.tail())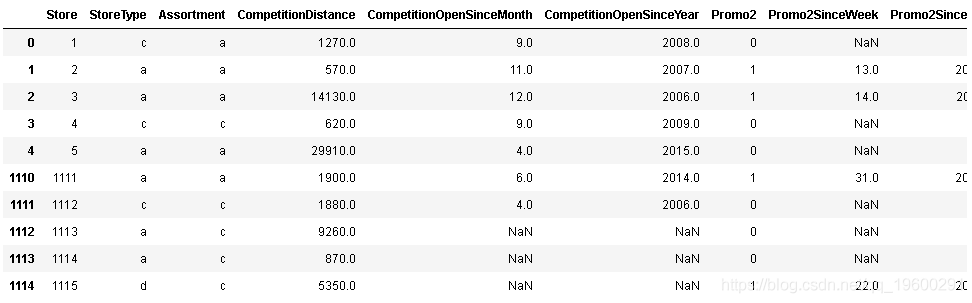
#缺失資料:
Store 0.000000
StoreType 0.000000
Assortment 0.000000
CompetitionDistance 0.269058
CompetitionOpenSinceMonth 31.748879
CompetitionOpenSinceYear 31.748879
Promo2 0.000000
Promo2SinceWeek 48.789238
Promo2SinceYear 48.789238
PromoInterval 48.789238
dtype: float64
In [21]:
讓我們從缺失的資料開始,第一個是 CompetitionDistance
store_df.CompetitionDistance.plot.box() 讓我看看例外值,因此我們可以在均值和中位數之間進行選擇來填充NaN
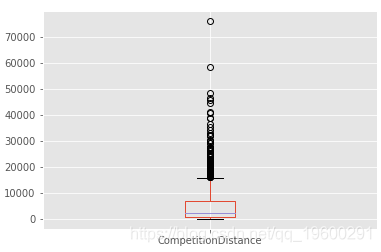
缺少資料,因為商店沒有競爭, 因此,我建議用零填充缺失的值,
store_df["CompetitionOpenSinceMonth"].fillna(0, inplace = True)
讓我們看一下促銷活動,
store_df.groupby(by = "Promo2", axis = 0).count() 
如果未進行促銷,則應將“促銷”中的NaN替換為零
我們合并商店資料和訓練集資料,然后繼續進行分析,
第一,讓我們按銷售量、客戶等比較商店,
f, ax = plt.subplots(2, 3, figsize = (20,10))
plt.subplots_adjust(hspace = 0.3)
plt.show()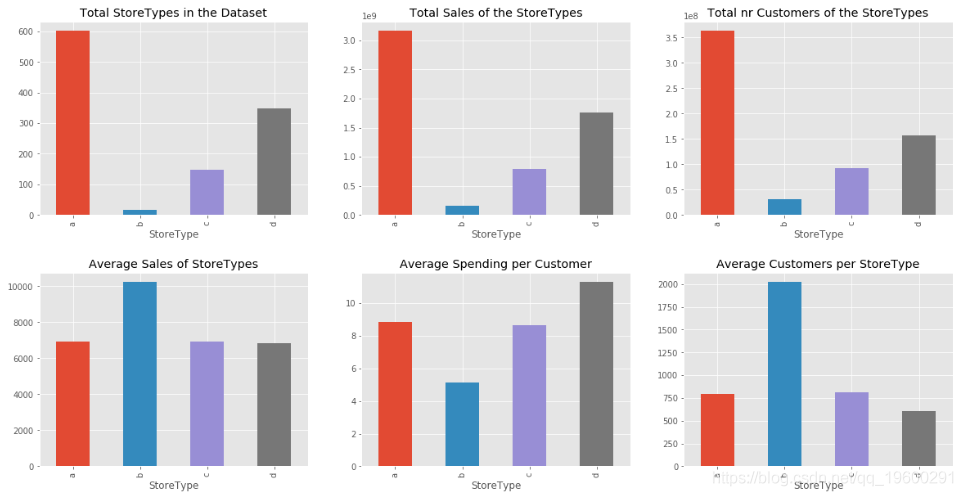
從圖中可以看出,StoreType A擁有最多的商店,銷售和客戶,但是,StoreType D的平均每位客戶平均支出最高,只有17家商店的StoreType B擁有最多的平均顧客,
我們逐年查看趨勢,
sns.factorplot(data = train_store_df,
# 我們可以看到季節性,但看不到趨勢, 該銷售額每年保持不變
<seaborn.axisgrid.FacetGrid at 0x7f7c350e0c50>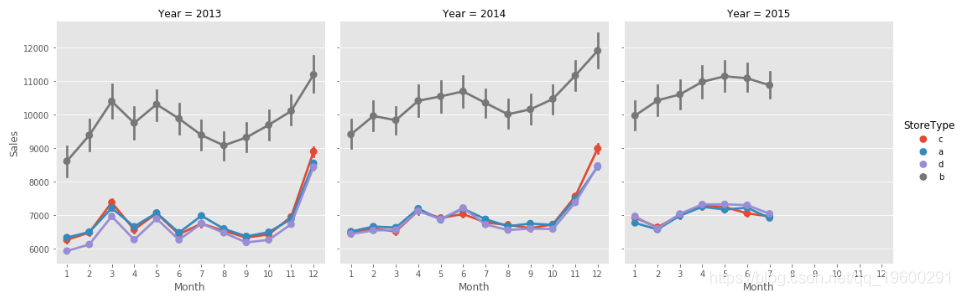
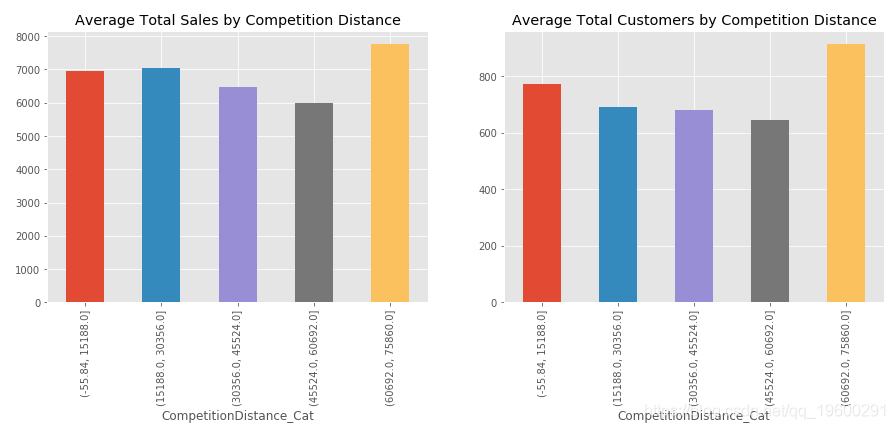
我們看一下相關圖,
"CompetitionOpenSinceMonth", "CompetitionOpenSinceYear", "Promo2
<matplotlib.axes._subplots.AxesSubplot at 0x7f7c33d79c18>
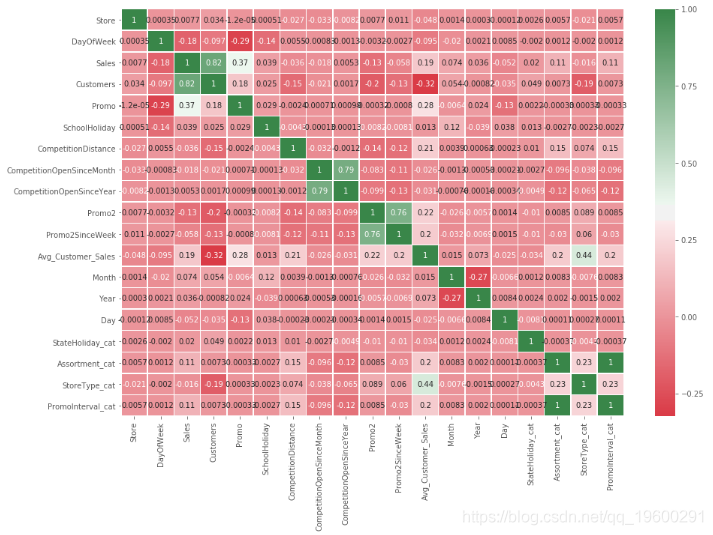
我們可以得到相關性:
- 客戶與銷售(0.82)
- 促銷與銷售(0,82)
- 平均顧客銷量 vs促銷(0,28)
- 商店類別 vs 平均顧客銷量 (0,44)
我的分析結論:
- 商店類別 A擁有最多的銷售和顧客,
- 商店類別 B的每位客戶平均銷售額最低,因此,我認為客戶只為小商品而來,
- 商店類別 D的購物車數量最多,
- 促銷僅在作業日進行,
- 客戶傾向于在星期一(促銷)和星期日(沒有促銷)購買更多商品,
- 我看不到任何年度趨勢,僅季節性模式,

最受歡迎的見解
1.在python中使用lstm和pytorch進行時間序列預測
2.python中利用長短期記憶模型lstm進行時間序列預測分析
3.使用r語言進行時間序列(arima,指數平滑)分析
4.r語言多元copula-garch-模型時間序列預測
5.r語言copulas和金融時間序列案例
6.使用r語言隨機波動模型sv處理時間序列中的隨機波動
7.r語言時間序列tar閾值自回歸模型
8.r語言k-shape時間序列聚類方法對股票價格時間序列聚類
9.python3用arima模型進行時間序列預測
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/220988.html
標籤:其他