1.先介紹一些自己會的語言,主要是后端
2.了解跨域嗎?
域:一個網站的網址組成包括協議名,子域名,主域名,埠號,比如https://www.github.com/80,其中https是協議名,www.github.com是子域名,github.com是主域名,埠號是80,當在在頁面中從一個url請求資料時,如果這個url的協議名、子域名、主域名、埠號任意一個有一個不同,就會產生跨域問題,即使是在 http://localhost:80/ 頁面請求 http://127.0.0.1:80/ 也會有跨域問題(因為域名不一樣),這里所有的域是指協議\域名\埠號的合集,同域就是協議域名埠號均相同
跨域問題是瀏覽器同源策略限制,當前域名的js只能讀取同域下的視窗屬性,
同源策略:在前端開發程序中,常見的HTML標簽,如
<a/>,<form/>,<img/>,<script/>,<iframe/>以及ajax操作都可以指向一個資源地址或者說可以發起對一個資源的請求,那么這里所說的請求就存在同域請求和跨域請求,同源策略是瀏覽器的核心基礎安全策略,作用是用來防御非法的攻擊.但是我們不能因為要防御非法的攻擊,就將所有的跨域問題都攔截掉,跨域請求:當發起請求的域,與該請求的資源指向的域,不一致
- 在前端開發當中,經常會用到第三方的服務介面(例如mock server, fake API),隨著專業化分工的出現,有很多專業的資訊服務提供商為前端開發者提供各類介面,這種情況下就需要跨域請求(大部分用cros方式來解決)
- 前端后端屬于不同的服務,在采用前后端分離這種架構的時候就存在跨域問題(大部分用反向代理的方法來解決)
解決辦法:
- 最簡單也最常見:使用jsonp ,即json with padding(內填充),顧名思義,就是把JSON填充到一個盒子里
- 一勞永逸:直接在服務器端設定跨域資源訪問 CORS(Cross-Origin Resource Sharing),設定Request Header頭中Access-Control-Allow-Origin為指定可獲取資料的域名
- 簡單有效:直接請求一張圖片
- 找”爸爸”:通過修改document.domain來跨子域
- 哥倆好:通過window.name來跨域接收資料
- 新石器時代:使用HTML5的window.postMessage方法跨域
3.介紹一下http快取機制?
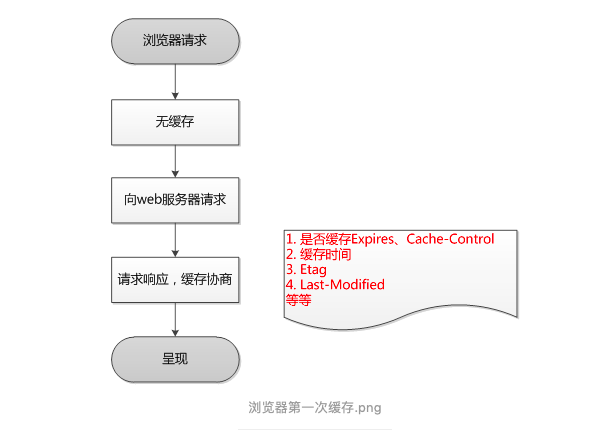
快取發生時機(輸入url到看見頁面):
- 1、首先,在瀏覽器地址欄中輸入url
- 2、瀏覽器先查看瀏覽器快取-系統快取-路由器快取,如果快取中有,會直接在螢屏中顯示頁面內容,若沒有,則跳到第三步操作,
- 3、在發送http請求前,需要域名決議(DNS決議),決議獲取相應的IP地址,
- 4、瀏覽器向服務器發起tcp連接,與瀏覽器建立tcp三次握手,
- 5、握手成功后,瀏覽器向服務器發送http請求,請求資料包,
- 6、服務器處理收到的請求,將資料回傳至瀏覽器
- 7、瀏覽器收到HTTP回應
- 8、讀取頁面內容,瀏覽器渲染,決議html原始碼
- 9、生成Dom樹、決議css樣式、js互動
- 10、客戶端和服務器互動
- 11、ajax查詢
Web 快取:大致可以分為:資料庫快取、服務器端快取(代理服務器快取、CDN 快取)、瀏覽器快取,瀏覽器快取包含很多內容: HTTP 快取、indexDB、cookie、localstorage 等等,
http快取:就是瀏覽器自己給你的一個功能,一個快取資料庫,夾在服務端和客戶端中間,你只需要設定一些引數即可實作:快取/不快取/時效內快取/時效外快取等(默認存在快取),時效內快取:強制快取,重點:cache-Control:max-age=xxx,非時效快取:對比快取,重點:Etag Last-Modified/If-Modified-Since,
兩種快取方式:
- 強制快取(時效快取):服務器通知瀏覽器一個快取時間,在快取時間內,下次請求,直接用快取,不在時間內,執行比較快取策略,使用Cache-Control (低版本瀏覽器用的是Expires,了解即可)
Expires :是HTTP 1.0的東西,現在默認瀏覽器均默認使用HTTP 1.1,所以它的作用基本忽略,
Cache-Control:與Expires的作用一致,都是指明當前資源的有效期,控制瀏覽器是否直接從瀏覽器快取取資料還是重新發請求到服務器取資料,只不過Cache-Control的選擇更多,設定更細致,如果同時設定的話,其優先級高于Expires, 它的值有一下6種:
Cache-Control 是最重要的規則,常見的取值有private、public、no-cache、max-age,no-store,默認為private, private 客戶端可以快取 public 客戶端和代理服務器都可快取(前端的同學,可以認為public和private是一樣的) max-age=xxx 快取的內容將在 xxx 秒后失效 no-cache 需要使用對比快取來驗證快取資料(后面介紹) no-store: 所有內容都不會快取,強制快取,對比快取都不會觸發(對于前端開發來說,快取越多越好,so...基本上和它說886)
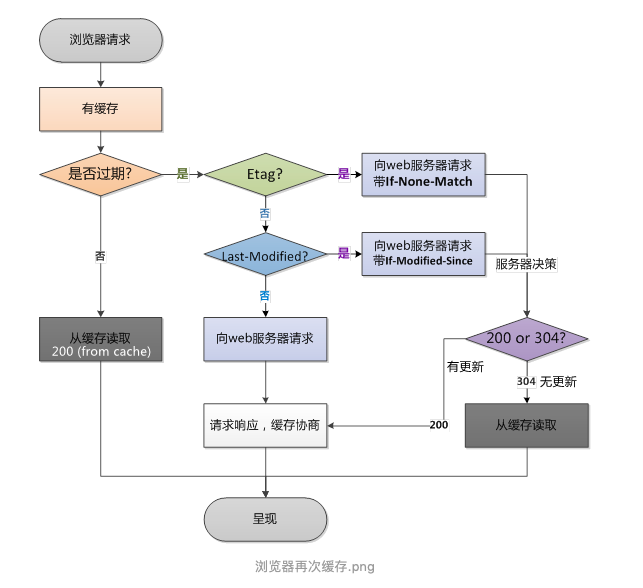
- 比較快取(非時效快取):用的不是時效時間max-age,第一次請求的時候,回傳給客戶端資料和快取的資訊,也就是一個特定的快取標識,客戶端把這個快取標識放到快取資料庫,再次請求時,客戶端先把快取標識也一起發給服務端,進行對比,客戶端將備份的快取標識Etag和Last-Modified發送給服務器,服務器根據快取標識進行判斷,判斷成功后,回傳304狀態碼,通知客戶端比較成功,可以使用快取資料,分為兩種快取標識:Etag 、Last-Modified/If-Modified-Since,對比快取標識生效不生效時,狀態碼200,服務端回傳body和header;在對比快取標識生效時,狀態碼為304,并且報文大小和請求時間大大減少,原因是,服務端在進行標識比較后,只回傳header部分,通過狀態碼通知客戶端使用快取,不再需要將報文主體部分回傳給客戶端,
- Etag(唯一標識,優先級高于Last-Modified / If-Modified-Since):服務器回應請求時,告訴瀏覽器當前資源在服務器的唯一標識(生成規則由服務器決定),
- Last-Modified: 服務器在回應請求時,告訴瀏覽器資源的最后修改時間,優先級沒有Etag高,
- If-Modified-Since: 回傳給客戶端最后這個資源的修改時間,優先級沒有Etag高,再次請求服務器時,通過此欄位通知服務器上次請求時,服務器回傳的資源最后修改時間, 服務器收到請求后發現有頭If-Modified-Since 則與被請求資源的最后修改時間進行比對, 若資源的最后修改時間大于If-Modified-Since,說明資源有被改動過,則回應整片資源內容,回傳狀態碼200; 若資源的最后修改時間小于或等于If-Modified-Since,說明資源無新修改,則回應HTTP 304,告知瀏覽器繼續使用所保存的cache,
- If-None-Match: 再次請求服務器時,通過此欄位通知服務器客戶段快取資料的唯一標識, 服務器收到請求后發現有頭If-None-Match 則與被請求資源的唯一標識進行比對, 不同,說明資源又被改動過,則回應整片資源內容,回傳狀態碼200; 相同,說明資源無新修改,則回應HTTP 304,告知瀏覽器繼續使用所保存的cache,
總結:
強制快取的優先級更高,如果沒失效,就直接用快取資料庫里的東西,如果時間已經失效了,就看用的是哪種標識(Etag服務端生成的唯一標識,還是last-modified資源最后修改時間標識)回傳304就用快取里的,回傳200就回傳body和新的header,一般來說,無論如何都會協商快取,瀏覽器必備的快取不可能沒有
補充:
HTTP報文:瀏覽器和服務器間通信時發送及回應的資料塊,
瀏覽器向服務器請求資料,發送請求(request)報文;服務器向瀏覽器回傳資料,回傳回應(response)報文,
報文資訊主要分為兩部分
- 包含屬性的首部(header)————————–附加資訊(cookie,快取資訊等)與快取相關的規則資訊,均包含在header中
- 包含資料的主體部分(body)———————–HTTP請求真正想要傳輸的部分
我做的專案:
//啟動檔案里
res.setHeader("Cache-Control", "no-store");//用于防止重要的資訊被無意的發布,在請求訊息中發送將使得請求和回應訊息都不使用快取,
//log in配置里
res.set('Cache-Control', 'no-cache, private, no-store, must-revalidate, max-stale=0, post-check=0, pre-check=0');//使用比較快取
4.介紹一些IO模型?
阻塞IO、非阻塞IO、多路復用IO、信號驅動IO以及異步IO,
- 阻塞IO:最傳統的一種IO模型,即在讀寫資料程序中會發生阻塞現象,當用戶執行緒發出IO請求之后,作業系統內核會去查看資料是否就緒,如果沒有就緒就會等待資料就緒,而用戶執行緒就會處于阻塞狀態,用戶執行緒交出CPU,當資料就緒之后,內核會將資料拷貝到用戶執行緒,并回傳結果給用戶執行緒,用戶執行緒才解除block狀態,
- 非阻塞IO:當用戶執行緒發起一個read操作后,并不需要等待,而是馬上就得到了一個結果,如果結果是一個error時,它就知道資料還沒有準備好,于是它可以再次發送read操作,一旦內核中的資料準備好了,并且又再次收到了用戶執行緒的請求,那么它馬上就將資料拷貝到了用戶執行緒,然后回傳,所以事實上,在非阻塞IO模型中,用戶執行緒需要不斷地詢問內核資料是否就緒,也就說非阻塞IO不會交出CPU,而會一直占用CPU,但是對于非阻塞IO就有一個非常嚴重的問題,在while回圈中需要不斷地去輪詢內核資料是否就緒,這樣會導致CPU占用率非常高,因此一般情況下很少使用while回圈這種方式來讀取資料,
//偽代碼 while(true){ new MyThread(socket) } class MyThread{ data = socket.read(); if(data!= error){ //處理資料 break; }- 多路復用IO:多路復用IO模型是目前使用得比較多的模型,在多路復用IO模型中,會有一個執行緒不斷去輪詢多個socket的狀態,只有當socket真正有讀寫事件時,才真正呼叫實際的IO讀寫操作,因為在多路復用IO模型中,只需要使用一個執行緒就可以管理多個socket,系統不需要建立新的行程或者執行緒,也不必維護這些執行緒和行程,并且只有在真正有socket讀寫事件進行時,才會使用IO資源,所以它大大減少了資源占用,在Java NIO中,是通過selector.select()去查詢每個通道是否有到達事件,如果沒有事件,則一直阻塞在那里,因此這種方式會導致用戶執行緒的阻塞,也許有朋友會說,我可以采用 多執行緒+ 阻塞IO 達到類似的效果,但是由于在多執行緒 + 阻塞IO 中,每個socket對應一個執行緒,這樣會造成很大的資源占用,并且尤其是對于長連接來說,執行緒的資源一直不會釋放,如果后面陸續有很多連接的話,就會造成性能上的瓶頸,而多路復用IO模式,通過一個執行緒就可以管理多個socket,只有當socket真正有讀寫事件發生才會占用資源來進行實際的讀寫操作,因此,多路復用IO比較適合連接數比較多的情況,另外多路復用IO為何比非阻塞IO模型的效率高是因為在非阻塞IO中,不斷地詢問socket狀態時通過用戶執行緒去進行的,而在多路復用IO中,輪詢每個socket狀態是內核在進行的,這個效率要比用戶執行緒要高的多,不過要注意的是,多路復用IO模型是通過輪詢的方式來檢測是否有事件到達,并且對到達的事件逐一進行回應,因此對于多路復用IO模型來說,一旦事件回應體很大,那么就會導致后續的事件遲遲得不到處理,并且會影響新的事件輪詢,
- 信號驅動IO:當用戶執行緒發起一個IO請求操作,會給對應的socket注冊一個信號函式,然后用戶執行緒會繼續執行,當內核資料就緒時會發送一個信號給用戶執行緒,用戶執行緒接收到信號之后,便在信號函式中呼叫IO讀寫操作來進行實際的IO請求操作,
- 異步IO:是最理想的IO模型,在異步IO模型中,當用戶執行緒發起read操作之后,立刻就可以開始去做其它的事,而另一方面,從內核的角度,當它受到一個asynchronous read之后,它會立刻回傳,說明read請求已經成功發起了,因此不會對用戶執行緒產生任何block,然后,內核會等待資料準備完成,然后將資料拷貝到用戶執行緒,當這一切都完成之后,內核會給用戶執行緒發送一個信號,告訴它read操作完成了,也就說用戶執行緒完全不需要實際的整個IO操作是如何進行的,只需要先發起一個請求,當接收內核回傳的成功信號時表示IO操作已經完成,可以直接去使用資料了,也就說在異步IO模型中,IO操作的兩個階段都不會阻塞用戶執行緒,這兩個階段都是由內核自動完成,然后發送一個信號告知用戶執行緒操作已完成,用戶執行緒中不需要再次呼叫IO函式進行具體的讀寫,這點是和信號驅動模型有所不同的在信號驅動模型中,當用戶執行緒接收到信號表示資料已經就緒,然后需要用戶執行緒呼叫IO函式進行實際的讀寫操作;而在異步IO模型中,收到信號表示IO操作已經完成,不需要再在用戶執行緒中呼叫iO函式進行實際的讀寫操作,注意,異步IO是需要作業系統的底層支持,因為無論是多路復用IO還是信號驅動模型,IO操作的第2個階段都會引起用戶執行緒阻塞,也就是內核進行資料拷貝的程序都會讓用戶執行緒阻塞,
5.了解Node模型嗎?
Node.js 采用事件驅動和異步 I/O 的方式,實作了一個單執行緒、高并發的 JavaScript 運行時環境,
6.了解mysql嗎?了解sql索引嗎?資料庫里資料量很大,如何快速搜索,
查詢效率慢的原因:
1:沒有加索引或者索引失效
where條件使用如下陳述句會索引失效:null、!=、<>、or連接、in(非要使用,可用關鍵字exist替代)和not in、'%abc%';
使用引數:num=@num、運算式操作:where num/2=100、函式操作:where substring(name,1,3)=‘abc’-name;
2:查詢的資料量過大,回傳不必要的行和列
只查詢有用的欄位,不要用*查詢出所有欄位,用具體的欄位串列代替“*”,不要回傳用不到的任何欄位,
采用多執行緒多次查詢,如果查詢條件是某段時間之類的范圍條件,可以把時間條件切分,多次查詢結果合并,
3:鎖或者死鎖
4: I/O吞吐量小,形成瓶頸效應,
5:記憶體不足,
少造物件,物件只在需要使用時創建,不要在整個背景關系傳遞,
及時清理jvm記憶體,
6:網路速度慢,
SQL優化方法
1:如果索引是復合索引,必須使用該索引的第一個欄位作為條件才能保證系統使用該索引,否則索引不會被參考,并且應盡可能的讓欄位順序與索引順序一致,
2:索引并不是越多越好,一個表索引最好不要超過6個,索引固然可以提高select效率,但是也降低了insert效率和update效率,因為insert和update會使索引重建,所以怎么建索引需要慎重考慮,
3:建表的一些優化:
盡量使用數字型欄位,若資料只含有數值資訊盡量不要設計成字符型,這會降低查詢和連接的性能,并會增加存盤開銷,因為引擎在處理查詢和連接時會逐個比較字串中每個字符,而對于數字型而言只需比較一次就夠了,
盡量使用varchar/nvarchar代替char/nchar,因為首先變長欄位存盤空間小,可以節省存盤空間,其次對于查詢來說,在一個相對較小的欄位內搜索效率顯然要高一些,
4:盡量避免使用游標,因為游標的效率較差,如果游標操作的資料超過1萬行,那么就應該考慮改寫,(游標是很老的功能了,幾乎廢棄了,)5:并不是所有索引對查詢都有效,SQL是根據表中資料來進行查詢優化的,當索引列有大量資料重復時,SQL查詢可能不會去利用索引,如一表中有欄位 sex,male、female幾乎各一半,那么即使在sex上建了索引也對查詢效率起不了作用,
6:盡量避免大事務操作,提高系統并發能力,
注意事項:
1:使用like時,一定要記得判空
... where name like ‘%’.變數名.'%'; (變數值是從外面傳進來的)
如果:變數是空,就變成如下sql
...where name like '%%'; -- 這個條件造成的后果就是 ‘選出全部資料 or 更新全部資料 or 洗掉全部資料’ 相當于沒有寫條件,出現后是相當嚴重的問題,
2:like 配合 通配符:%和_ 的使用
通配符的分類:
%百分號通配符: 表示任何字符出現任意次數**(可以是0次)**.
_下劃線通配符:表示只能匹配單個字符,不能多也不能少,就是一個字符.like運算子:
LIKE作用是指示mysql后面的搜索模式是利用通配符而不是直接相等匹配進行比較.
注意: 如果在使用like運算子時,后面的沒有使用通用匹配符效果是和=一致的,SELECT * FROM products WHERE products.prod_name like '1000';只能匹配的結果為1000,而不能匹配像JetPack 1000這樣的結果.1)%通配符使用:
匹配以"yves"開頭的記錄:(包括記錄"yves")
SELECT * FROM products WHERE products.prod_name like 'yves%';匹配包含"yves"的記錄(包括記錄"yves")
SELECT * FROM products WHERE products.prod_name like '%yves%';匹配以"yves"結尾的記錄(包括記錄"yves",不包括記錄"yves ",也就是yves后面有空格的記錄,這里需要注意)
SELECT * FROM products WHERE products.prod_name like '%yves';2)_通配符使用:
SELECT * FROM products WHERE products.prod_name like '_yves';
匹配結果為: 像"yyves"這樣記錄.SELECT * FROM products WHERE products.prod_name like 'yves__';
匹配結果為: 像"yvesHe"這樣的記錄.(一個下劃線只能匹配一個字符,不能多也不能少)其他操作:
insert into tb (...) values(...),(...)...; 要比 insert into tb (...) values (...);insert into tb (...) values (...);...方式批量插入效率高 【原因】:這里第二種SQL執行效率高的主要原因是合并后日志量(MySQL的binlog和innodb的事務讓日志) 減少了,降低日志刷盤的資料量和頻率,從而提高效率,通過合并SQL陳述句,同時也能減少SQL陳述句決議的次數,減少網路傳輸的IO,
7.了解行程和執行緒嗎?CPU處理的基本單位是什么?
行程:程式的一次執行程序,是一個動態概念,是程式在執行程序中分配和管理資源的基本單位,每一個行程都有一個自己的地址空間,至少有 5 種基本狀態,它們是:初始態,執行態,等待狀態,就緒狀態,終止狀態,
執行緒:CPU調度和分派的基本單位,它可與同屬一個行程的其他的執行緒共享行程所擁有的全部資源,
聯系:行程是執行緒的容器,執行緒是行程的一部分,一個執行緒只能屬于一個行程,而一個行程可以有多個執行緒,但至少有一個執行緒,
區別:根本區別:行程是作業系統資源分配的基本單位,而執行緒是任務調度和執行的基本單位,在開銷方面:每個行程都有獨立的代碼和資料空間(程式背景關系),程式之間的切換會有較大的開銷;執行緒可以看做輕量級的行程,同一類執行緒共享代碼和資料空間,每個執行緒都有自己獨立的運行堆疊和程式計數器(PC),執行緒之間切換的開銷小,所處環境:在作業系統中能同時運行多個行程(程式);而在同一個行程(程式)中有多個執行緒同時執行(通過CPU調度,在每個時間片中只有一個執行緒執行),記憶體分配方面:系統在運行的時候會為每個行程分配不同的記憶體空間;而對執行緒而言,除了CPU外,系統不會為執行緒分配記憶體(執行緒所使用的資源來自其所屬行程的資源),執行緒組之間只能共享資源,包含關系:沒有執行緒的行程可以看做是單執行緒的,如果一個行程內有多個執行緒,則執行程序不是一條線的,而是多條線(執行緒)共同完成的;執行緒是行程的一部分,所以執行緒也被稱為輕權行程或者輕量級行程,
8.介紹一下CPU處理的演算法?
待更
9.行程死鎖是什么?
死鎖定義:死鎖就是一個行程集合中的多個行程因為競爭資源,而造成的互相等待現象,如:A和B吃餃子,A拿著醬油,B拿著醋,A想要醋,B想要醬油,結果二者死等吃不上餃子,
死鎖原因:系統資源不足;多個行程的推進順序不合理;資源分配不當
死鎖的必要條件:
(1)互斥條件(Mutual exclusion):資源不能被共享,只能由一個行程使用,
(2)請求與保持條件(Holdand wait):已經得到資源的行程可以再次申請新的資源,
(3)非剝奪條件(Nopre-emption):已經分配的資源不能從相應的行程中被強制地剝奪,
(4)回圈等待條件(Circular wait):系統中若干行程組成環路,該環路中每個行程都在等待相鄰行程正占用的資源,
處理死鎖的方法有四種:1) 預防死鎖 2) 避免死鎖 3)檢測和解除死鎖
預防死鎖:破壞四個必要條件之一即可
①破壞互斥條件:讓資源允許共享,如SPOOLing技術就可以允許若干個行程同時產生列印資料,
缺點: SPOOLing的技術并不適用于所有的資源,如行程表等,所以破懷澩的互斥性是比較困難的,該方法并不是很好
②破壞請求和保持條件:資源一次性分配,
缺點:采取這種機制,那么行程在執行程序中就不再申請資源了,但這種方法的效率極低,資源無法得到充分的利用,
③破壞不可剝奪條件:有兩種方法,一種是當其申請的資源得不到滿足時,也必須放棄其原先占有的資源;另一種方法是只適用于申請資源的行程優先級比占有該資源的行程優先級高時,如果一個行程申請的資源被其它行程占用,而申請行程的優先級較高,那么它可以強迫占有資源的行程放棄,這種方法一般適用于處理機和存盤資源,
④破壞回圈等待條件:系統給每類資源賦予一個編號,每一個行程按編號遞增的順序請求資源,釋放則相反(如:哲學家進餐問題)
避免死鎖的方法有兩種:1) 資源按序分配 2) 銀行家演算法,
解除死鎖的方法有兩種:1) 資源剝奪法 2) 撤消行程法 3)行程回退法
10.給你一個網站的url,請寫出這個url內所有url以及通過這些url之后跳轉的所有url中不重復的結果?
當時答的用一個樹結構,但是還是不會做
11.上傳檔案和點擊一個按鈕的content type的區別?http傳輸協議的區別?
content-type:
一般是指網頁中存在的 Content-Type,用于定義網路檔案的型別和網頁的編碼,決定瀏覽器將以什么形式、什么編碼讀取這個檔案,這就是經常看到一些 PHP 網頁點擊的結果卻是下載一個檔案或一張圖片的原因,標頭告訴客戶端實際回傳的內容的內容型別,是Http的物體首部欄位,用于說明請求或回傳的訊息主體是用何種方式編碼,在request header和response header里都存在,
常見的型別:
text/(plain、 css、html、xml) (文本、、 css、html、xml)型別
application/(x-javascript、json、xml、octet-stream) (js、json、xml、二進制流資料)型別
image/png jpg gif image/*上傳excel檔案:
.xls application/vnd.ms-excel
12.演算法題:輸出一個 int 型陣列{1,2,5,-7,8,-10}使得和最大的連續子陣列
待更
總結:
這次準備的主要是js知識,沒想到位元組的面試很偏底層的基礎,都沒復習到,,,演算法題也沒刷題,做了半小時,沒能做出來,,,感覺比前段時間面試的螞蟻金服難多了,,,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/221073.html
標籤:其他
上一篇:資料結構--線段樹