作者|Anders Ohrn
編譯|VK
來源|Towards Data Science
利用深度卷積神經網路(DCNN)進行監督影像分類是一個成熟的程序,通過預訓練模板模型加上微調優化,可以在許多有意義的應用中獲得非常高的準確率——比如最近在醫學影像上的這項研究,在日常物體影像上預訓練的模板Inception v3模型對前列腺癌診斷的準確率達到了99.7%,
對于無監督的影像機器學習,目前的研究現狀遠沒有定論,
聚類是無監督機器學習的一種形式,其中資料(本例中的影像)根據資料收集本身的某種結構進行分簇,在同一個簇中結束的影像應該比不同簇中的影像更相似,
影像資料可能是復雜的-變化的背景,視圖中的多個物件-因此一對影像比另一對影像更相似意味著什么并不明顯,如果沒有基本的真實性標簽,通常不清楚是什么使一種聚類方法優于另一種聚類方法,
一方面,無監督的問題因此比有監督的問題更加模糊,沒有現成的正確答案可供優化,另一方面,從模糊的問題、假設的產生、問題的發現和修補中,最有趣的東西出現了,
我將描述一種最新的影像聚類方法的實作(https://arxiv.org/abs/1903.12355),這是近年來發表的許多先進的DCNN聚類技術之一,
我使用PyTorch庫來演示如何實作這個方法,并在整個文本中提供了幾個詳細的代碼片段,倉庫中提供完整的代碼:https://github.com/anderzzz/monkey_caput
在標準庫中沒有無監督版本的聚類方法,這點不像有監督版本,它可以很容易獲得影像聚類方法,但PyTorch仍然能夠平穩地實作實際上非常復雜的方法,因此,我能夠探索、測驗和輕微地探究DCNNs應用于聚類任務時可以做什么,
我的目標是展示如何從一些概念和方程開始,你可以使用PyTorch來得到一些可以在計算機上運行的非常具體的東西,并指導進一步的創新和修改你所擁有的任何任務
我將把這個應用到真菌的影像上,為什么是真菌?你待會兒再看,
但首先…實作VGG自編碼器
在討論聚類方法之前,我將實作一個自動編碼器(AE),AEs有各種各樣的應用,包括降維,并且本身很有趣,它們在影像聚類中的作用將在以后變得更加清楚,
用PyTorch庫實作基本的ae并不是那么困難(請看這兩個例子),我將實作特定的AE架構,它是SegNet方法的一部分,它建立在VGG模板卷積網路上,VGG定義了一種體系結構,最初是為監督影像分類而開發的,
AE的架構如下圖所示,
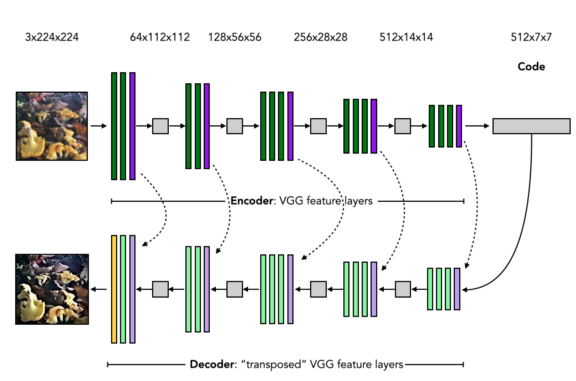
影像自編碼的步驟如下:
-
準備輸入影像(左上角)
-
將影像輸入編碼器,由具有標準CNN和ReLU激活的卷積層(綠色)和最大池層(紫色)組成
-
得到一個低維的編碼
-
將編碼輸入譯碼器,它由轉置的卷積層(帶歸一化和ReLU激活)(淺綠色)和解池化層(淺紫色)加上一個沒有歸一化或激活的最終卷積層(黃色)
-
獲得與輸入尺寸相同的輸出影像,
是時候把這個設計變成代碼了,
我從創建一個編碼器模塊開始,第一行,包括初始化方法,如下所示:
import torch
from torch import nn
from torchvision import models
class EncoderVGG(nn.Module):
'''
基于vgg16體系結構的影像編碼器,具有batch normalization,
Args:
預訓練的params (bool,可選):是否應該用預訓練的vGG引數填充網路,默認值為True
'''
channels_in = 3
channels_code = 512
def __init__(self, pretrained_params=True):
super(EncoderVGG, self).__init__()
vgg = models.vgg16_bn(pretrained=pretrained_params)
del vgg.classifier
del vgg.avgpool
self.encoder = self._encodify_(vgg)
編碼器的結構與VGG-16卷積網路的特征提取層結構相同,因此,PyTorch庫中很容易找到該部分—PyTorch models.vgg16_bn,請參閱代碼片段中的第19行,
與VGG的規范應用程式不同,編碼不會被輸入到分類層中,最后兩層vgg.classifier以及vgg.avgpool被丟棄,
編碼器的層需要一次調整,在解碼器的解池層中,編碼器的最大池層中的池索引必須可用,在前面的影像中虛線箭頭表示,VGG -16的模板版本不生成這些索引,然而,池化層可以重新初始化,這就是EncoderVGG模塊的_encodify方法完成的作業,
def _encodify_(self, encoder):
'''
基于VGG模板的架構創建編碼器模塊串列,在編碼器-解碼器體系結構中,解碼器中的解池操作需要來自編碼器中相應池操作的池索引,在VGG模板中,這些索引不回傳,因此需要使用此方法擴展池操作,
引數:
編碼器:模板VGG模型
回傳:
模塊:定義與VGG模型對應的編碼器的模塊串列
'''
modules = nn.ModuleList()
for module in encoder.features:
if isinstance(module, nn.MaxPool2d):
module_add = nn.MaxPool2d(kernel_size=module.kernel_size,
stride=module.stride,
padding=module.padding,
return_indices=True)
modules.append(module_add)
else:
modules.append(module)
return modules
因為這是一個PyTorch模塊(nn.Module),通過EncoderVGG實體實作小批量影像資料的前向傳播需要一個forward方法:
def forward(self, x):
'''將影像輸入encoder
Args:
x (Tensor): 圖片tensor
Returns:
x_code (Tensor): 編碼 tensor
pool_indices (list): 池索引張量
'''
pool_indices = []
x_current = x
for module_encode in self.encoder:
output = module_encode(x_current)
# 如果模塊是池,有兩個輸出,第二個是池索引
if isinstance(output, tuple) and len(output) == 2:
x_current = output[0]
pool_indices.append(output[1])
else:
x_current = output
return x_current, pool_indices
該方法按順序執行編碼器中的每個層,并在創建池索引時收集它們,在執行編碼器模塊之后,代碼與池索引的有序集合一起回傳,
接下來是解碼器,
它是VGG-16網路的“轉置”版本,我使用引號是因為解碼器層看起來很像反向的編碼器,但嚴格地說,它不是反轉或轉置,
譯碼器模塊的初始化:
class DecoderVGG(nn.Module):
'''譯碼器的代碼基于vgg16體系結構與batch normalization,
Args:
encoder: ' EncoderVGG '的編碼器實體,它將被轉換成一個解碼器
'''
channels_in = EncoderVGG.channels_code
channels_out = 3
def __init__(self, encoder):
super(DecoderVGG, self).__init__()
self.decoder = self._invert_(encoder)
def _invert_(self, encoder):
'''將編碼器反轉,以將譯碼器創建為編碼器的鏡像
譯碼器由兩種主要型別組成:二維轉置卷積和二維解池,2D卷積之后是批處理歸一化和激活,
譯碼器是反向的,編碼器中的卷積變成了轉置卷積加上歸一化和激活,編碼器中的maxpooling變成了unpooling,
Args:
encoder (ModuleList): 編碼器
Returns:
decoder (ModuleList): 通過編碼器的“反轉”獲得的譯碼器
'''
modules_transpose = []
for module in reversed(encoder):
if isinstance(module, nn.Conv2d):
kwargs = {'in_channels' : module.out_channels, 'out_channels' : module.in_channels,
'kernel_size' : module.kernel_size, 'stride' : module.stride,
'padding' : module.padding}
module_transpose = nn.ConvTranspose2d(**kwargs)
module_norm = nn.BatchNorm2d(module.in_channels)
module_act = nn.ReLU(inplace=True)
modules_transpose += [module_transpose, module_norm, module_act]
elif isinstance(module, nn.MaxPool2d):
kwargs = {'kernel_size' : module.kernel_size, 'stride' : module.stride,
'padding' : module.padding}
module_transpose = nn.MaxUnpool2d(**kwargs)
modules_transpose += [module_transpose]
# 放棄最后的歸一化和激活函式
modules_transpose = modules_transpose[:-2]
return nn.ModuleList(modules_transpose)
_invert_方法反向遍歷編碼器的各個層,
編碼器中的卷積(影像中為綠色)替換為解碼器中相應的轉置卷積(影像中為淺綠色),這個nn.ConvTranspose2d是PyTorch中的模塊,它對資料進行上采樣,而不是像眾所周知的卷積操作那樣進行下采樣,如需進一步解釋,請參閱此處:https://naokishibuya.medium.com/up-sampling-with-transposed-convolution-9ae4f2df52d0
編碼器中的最大池(紫色)替換為相應的解池層(淺紫色),或nn.MaxUnpool2d,參考PyTorch庫模塊,
解碼器forward為:
def forward(self, x, pool_indices):
'''執行解碼器
Args:
x (Tensor): 從編碼器得到的編碼張量
pool_indices (list): 池索引
Returns:
x (Tensor): 解碼后的影像張量
'''
x_current = x
k_pool = 0
reversed_pool_indices = list(reversed(pool_indices))
for module_decode in self.decoder:
# 如果模塊正在解池,收集適當的池索引
if isinstance(module_decode, nn.MaxUnpool2d):
x_current = module_decode(x_current, indices=reversed_pool_indices[k_pool])
k_pool += 1
else:
x_current = module_decode(x_current)
return x_current
編碼以及編碼器創建的池索引串列是輸入,每當執行一個解池層時,反向地,每次取一個池索引,這樣,關于編碼器如何執行最大池的資訊被轉移到解碼器,
因此,在鏡像編碼器層的轉置層之后,forward的輸出張量形狀是與輸入到編碼器的影像張量形狀相同,
完整的自編碼器模塊實作為編碼器和解碼器實體的組合:
class AutoEncoderVGG(nn.Module):
'''基于vgg16的batch normalization的自編碼器,該類由編碼器和解碼器組成,
Args:
pretrained_params (bool, optional): 是否應該用先訓練好的VGG引數填充網路,
默認值為True,
'''
channels_in = EncoderVGG.channels_in
channels_code = EncoderVGG.channels_code
channels_out = DecoderVGG.channels_out
def __init__(self, pretrained_params=True):
super(AutoEncoderVGG, self).__init__()
self.encoder = EncoderVGG(pretrained_params=pretrained_params)
self.decoder = DecoderVGG(self.encoder.encoder)
def forward(self, x):
'''自編碼器前向傳播
Args:
x (Tensor): 影像張量
Returns:
x_prime (Tensor): 編碼和解碼后的影像張量
'''
code, pool_indices = self.encoder(x)
x_prime = self.decoder(code, pool_indices)
return x_prime
AE的一組引數可以產生與相應輸入非常相似的輸出,這是一組很好的引數,我使用AE輸入和輸出之間每個像素的均方誤差來作為一個目標函式量化它,也就是PyTorch庫的nn.MSELoss,
通過定義AE模型和一個可微目標函式,利用PyTorch強大的工具進行反向傳播,得到一個梯度,然后進行網路引數優化,我不會詳細介紹訓練是如何實施的(好奇的讀者可以看看在倉庫中的ae_learner.py,https://github.com/anderzzz/monkey_caput),
編碼器通過特征壓縮影像,是聚類的起點
在訓練AE之后,它包含一個編碼器,它可以在較低的維度上近似地表示影像資料集重復出現的高層特征,對于真菌的影像資料集,這些特征可以是形狀、邊界和顏色,這些特征在幾幅蘑菇影像中是共享的,換句話說,編碼器體現了蘑菇樣式加上典型背景的簡潔表示,
因此,兩個與這些高級特征非常相似的影像對應的編碼應該比任何一對隨機編碼更接近——例如通過歐幾里得距離或余弦相似度來衡量,
另一方面,影像的低維壓縮是高度非線性的,因此,如果兩個編碼之間的距離大于某個相當小的閾值,就不能說明是互相對應的影像,這對于創建定義良好、清晰的簇并不理想,
編碼器是一個起點,下一步將對編碼器進行改進,利用已學的蘑菇特征將影像壓縮成編碼,這些編碼也會形成固有的良好簇,
關于區域聚集損失的幾個字和方程
區域聚集(LA)方法定義了一個目標函式來量化一組代碼的聚類效果(https://arxiv.org/abs/1903.12355),目標函式不像有監督的機器學習方法那樣直接參考影像內容的真實標簽,相反,目標函式量化編碼影像資料本質上對定義良好的簇的適應程度,
用這種方法得到的定義是否可以創建有意義的聚類,這一點并不明顯,這就是為什么需要實作和測驗,
首先從LA的幾個定義中說明要實作什么,
LA的簇目標是:
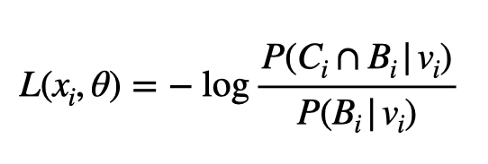
方程中的x?是影像張量,θ表示編碼器的引數,右側的v?是與x?相對應的編碼,這兩個集合C?和B?由集合中其他影像的編碼組成,它們分別被命名為v?的近鄰和背景鄰居,
一組編碼A的概率P定義為:
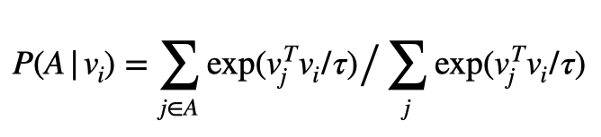
換句話說,指數定義了概率,其中如果概率密度越大,v?與其他成員的點積越大,因此,集合a由與v?相似,v?可能是其簇的成員,
標量τ被稱為溫度,它定義了點積相似性的尺度,
對于給定的真菌影像集合{x?},目標是找到使集合的聚類目標最小化的引數θ,LA論文的作者提出了一個論點,為什么這個目標是有意義的,我在這里不再重復這個論點,簡單地說,分配給一個簇的編碼越清晰,與該簇的補集的編碼相比,簇的目標函式值就越低,
如何將LA目標作為自定義損失函式來實作
在上面關于AE的部分中,描述了定制編碼器模塊,缺少的是LA的目標函式,因為它不是PyTorch中庫損失函式的一部分,
需要實作自定義損失模塊,
loss函式模塊的初始化初始化了許多scikit-learn函式,這些函式是在forward方法中定義背景集和近鄰集中很有用,
import torch
from torch import nn
import torch.nn.functional as F
import numpy as np
from sklearn.neighbors import NearestNeighbors
from sklearn.cluster import KMeans
from sklearn.preprocessing import normalize
from scipy.spatial.distance import cosine as cosine_distance
class LocalAggregationLoss(nn.Module):
'''Local Aggregation Loss module from "Local Aggregation for Unsupervised Learning of Visual Embeddings" by
Zhuang, Zhai and Yamins (2019), arXiv:1903.12355v2
'''
def __init__(self, temperature,
k_nearest_neighbours, clustering_repeats, number_of_centroids,
memory_bank,
kmeans_n_init=1, nn_metric=cosine_distance, nn_metric_params={}):
super(LocalAggregationLoss, self).__init__()
self.temperature = temperature
self.memory_bank = memory_bank
self.neighbour_finder = NearestNeighbors(n_neighbors=k_nearest_neighbours + 1,
algorithm='ball_tree',
metric=nn_metric, metric_params=nn_metric_params)
self.clusterer = []
for k_clusterer in range(clustering_repeats):
self.clusterer.append(KMeans(n_clusters=number_of_centroids,
init='random', n_init=kmeans_n_init))
NearestNeighbors實體提供了一種有效的方法來計算資料點的最近鄰,這將用于定義集合B,KMeans實體提供了一種有效的方法來計算資料點的簇,這些將用于定義集合C,
其中:LocalAggregationLoss所需的forward方法為
def forward(self, codes, indices):
'''local aggregation loss 模塊的forward方法'''
assert codes.shape[0] == len(indices)
codes = codes.type(torch.DoubleTensor)
code_data = https://www.cnblogs.com/panchuangai/p/normalize(codes.detach().numpy(), axis=1)
# 計算和收集定義損失函式中的常量的索引陣列,請注意,這些資料值在反向傳播時不計算梯度
self.memory_bank.update_memory(code_data, indices)
background_neighbours = self._nearest_neighbours(code_data, indices)
close_neighbours = self._close_grouper(indices)
neighbour_intersect = self._intersecter(background_neighbours, close_neighbours)
# 計算給定記憶庫常數的編碼的概率密度
v = F.normalize(codes, p=2, dim=1)
d1 = self._prob_density(v, background_neighbours)
d2 = self._prob_density(v, neighbour_intersect)
return torch.sum(torch.log(d1) - torch.log(d2)) / codes.shape[0]
forward方法接受當前版本的編碼器生成的一小批編碼,以及完整資料集中所述編碼的索引,由于在創建小批量時通常會對資料進行無序處理,因此索引可以是一個非連續整數的串列,
forward有兩個主要部分,首先計算相鄰集B,C及其交集,其次,對給定的一批編碼和集合計算概率密度,然后將其計算LA目標函式,
“記憶庫”是什么?
LA的創造者采用了一種記憶庫的技巧,他們將其歸因于吳等人的另一篇論文(https://arxiv.org/pdf/1808.04699.pdf),這是一種處理LA目標函式的梯度依賴于資料集所有編碼的梯度的方法,
所述函式的適當梯度必須計算如下所示:
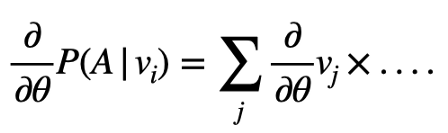
右邊所有編碼的和意味著需要計算大量的張量并且在反向傳播時一直保留下來,在小批影像上迭代不會提高效率,因為必須計算與解碼器引數有關編碼的梯度,
因為聚類的質量將一個影像與資料集的所有其他影像相關聯,而不是一個固定的真實標簽,這種糾纏是可以理解的,
記憶庫技巧相當于將當前小批量中的編碼以外的其他編碼視為常量,因此,與其他編碼的導數的糾纏就消失了,只要近似的梯度足夠好地引導優化朝最小值方向發展,這是一個有用的方法,
記憶庫類實作為:
class MemoryBank(object):
'''Memory bank
Args:
n_vectors (int): 記憶庫應該持有的向量數量
dim_vector (int): 記憶庫應該持有的向量的維度
memory_mixing_rate (float, optional): 要添加到當前存盤向量的新向量的一部分,值應該在0.0到1.0之間,值越大更新越快,混合速率可以在呼叫' update_memory '時設定,.
'''
def __init__(self, n_vectors, dim_vector, memory_mixing_rate):
self.dim_vector = dim_vector
self.vectors = np.array([marsaglia(dim_vector) for _ in range(n_vectors)])
self.memory_mixing_rate = memory_mixing_rate
self.mask_init = np.array([False] * n_vectors)
def update_memory(self, vectors, index):
'''用新的向量更新'''
if isinstance(index, int):
self.vectors[index] = self._update_(vectors, self.vectors[index])
elif isinstance(index, np.ndarray):
for ind, vector in zip(index, vectors):
self.vectors[ind] = self._update_(vector, self.vectors[ind])
def mask(self, inds_int):
'''給定整數索引構造一個布爾掩碼'''
ret_mask = []
for row in inds_int:
row_mask = np.full(self.vectors.shape[0], False)
row_mask[row.astype(int)] = True
ret_mask.append(row_mask)
return np.array(ret_mask)
def _update_(self, vector_new, vector_recall):
return vector_new * self.memory_mixing_rate + vector_recall * (1.0 - self.memory_mixing_rate)
它由與待聚類資料集維數相同、個數相同的單位資料向量組成(在超球面上用Marsaglia的方法統一初始化),
因此,一個用編碼生成尺寸為512的1000幅影像的編碼器任務,意味著在尺寸為512的真實坐標向量空間中有1000個單位向量的記憶庫,一旦向記憶庫提供了一組新的向量以及相應的索引,記憶就會用某種混合速率memory_mixing_rate更新,該類還包含一個方便的方法,用于將整數索引集合轉換為整個資料集的布爾掩碼,
注意,記憶庫只處理數字,記憶庫無法連接到PyTorch張量的反向傳播機制,記憶庫是更新的,而不是直接作為反向傳播的一部分,
它是MemoryBank的一個實體,存盤在LocalAggregationLoss的memory_bank屬性中,
如何創建背景鄰居集和近鄰集
再次回到LocalAggregationLoss的forward方法,我使用先前初始化的scikit-learn實作鄰居集的創建,
def _nearest_neighbours(self, codes_data, indices):
'''確定記憶庫中給定編碼的k個最近鄰的索引
Returns:
indices_nearest (numpy.ndarray): 這批編碼的k個最近鄰的布爾陣列
'''
self.neighbour_finder.fit(self.memory_bank.vectors)
indices_nearest = self.neighbour_finder.kneighbors(codes_data, return_distance=False)
return self.memory_bank.mask(indices_nearest)
def _close_grouper(self, indices):
'''確定與給定索引的向量在同一簇中的向量在記憶庫中的索引
Returns:
indices_close (numpy.ndarray): 批代碼相鄰的布爾陣列
'''
memberships = [[]] * len(indices)
for clusterer in self.clusterer:
clusterer.fit(self.memory_bank.vectors)
for k_index, cluster_index in enumerate(clusterer.labels_[indices]):
other_members = np.where(clusterer.labels_ == cluster_index)[0]
other_members_union = np.union1d(memberships[k_index], other_members)
memberships[k_index] = other_members_union.astype(int)
return self.memory_bank.mask(np.array(memberships, dtype=object))
def _intersecter(self, n1, n2):
'''兩個布爾陣列的交集計算'''
return np.array([[v1 and v2 for v1, v2 in zip(n1_x, n2_x)] for n1_x, n2_x in zip(n1, n2)])
_nearest_neighbours和_intersecter都很簡單,前者依賴于尋找最近鄰居的方法,它考慮記憶庫中的所有資料點,
_close_grouper在記憶庫中執行多個資料點聚類,與關注點v?屬于同一簇的那些資料點定義了這個近鄰集C?,LA論文的作者鼓勵使用多個聚類運行,因為聚類包含一個隨機成分,所以通過執行多個聚類,可以消除噪聲,
為了說明這一點,下圖中的紅點是其他編碼海洋中感興趣的編碼,記憶庫當前狀態的聚類將感興趣的點放在其他點的簇中(中間影像中的綠色),最近鄰定義了另一組相關資料點(右側影像中為紫色),“_nearest_neighbours”和“_close_grouper為小批量中的每個編碼創建這兩個集合,并將這些集合表示為布爾掩碼,
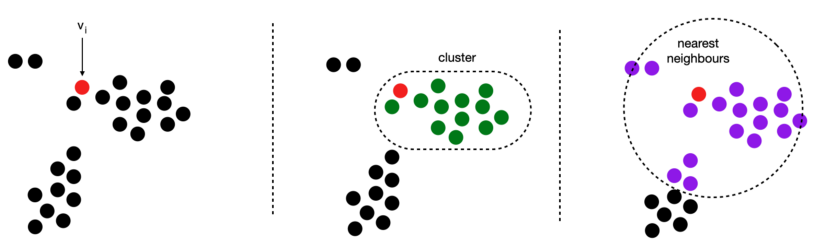
計算概率密度,以便PyTorch反向傳播能夠計算梯度
對于批處理中每個代碼v?的兩個集合(B?和B?與C?相交),是時候計算概率密度了,這個密度也可以用PyTorch方法來區分,
其實作方式為:
def _prob_density(self, codes, indices):
'''計算由指標定義的集合中編碼的非歸一化概率密度
Returns:
prob_dens (Tensor): 給定編碼的向量的非歸一化概率密度
'''
ragged = len(set([np.count_nonzero(ind) for ind in indices])) != 1
# 在該情況下,所有的向量子集都是相同的大小,可以簡潔地使用廣播和批處理,
if not ragged:
vals = torch.tensor([np.compress(ind, self.memory_bank.vectors, axis=0) for ind in indices],
requires_grad=False)
v_dots = torch.matmul(vals, codes.unsqueeze(-1))
exp_values = torch.exp(torch.div(v_dots, self.temperature))
pdensity = torch.sum(exp_values, dim=1).squeeze(-1)
#如果向量子集是不同的大小, 廣播是不可能的,所以手動回圈
else:
xx_container = []
for k_item in range(codes.size(0)):
vals = torch.tensor(np.compress(indices[k_item], self.memory_bank.vectors, axis=0),
requires_grad=False)
v_dots_prime = torch.mv(vals, codes[k_item])
exp_values_prime = torch.exp(torch.div(v_dots_prime, self.temperature))
xx_prime = torch.sum(exp_values_prime, dim=0)
xx_container.append(xx_prime)
pdensity = torch.stack(xx_container, dim=0)
return pdensity
在第14-16行中,所有不同的點積都是在小批量編碼和記憶庫子集之間計算的,這個np.compress將掩碼應用于記憶庫向量,
這個torch.matmul計算所有點積,還請注意,張量codes包含編碼器的數學運算記錄,因此,當這使PyTorch的反向傳播機制autograd能夠評估關于編碼器所有引數的損耗準則的梯度,
概念上相同的操作發生在第25-27行,但是在這個子句中,mini-batch維度被顯式地迭代,當numpy陣列不能被廣播時,這是必需的,對于參差不齊的陣列(至少目前是這樣),
把模型和損失放在一起
總而言之,下面的代碼可以為特定的資料集VGG編碼器和LA提供訓練,
from torch.optim import SGD
from torch.utils.data import DataLoader
from sklearn.preprocessing import normalize
import fungidata
from ae_deep import EncoderVGGMerged
from cluster_utils import MemoryBank, LocalAggregationLoss
# 創建真菌資料集
dataset = fungidata.factory.create('grid basic idx', ...)
dataloader = DataLoader(dataset, ...)
# 實體化定制的模型和初始預訓練的vgg編碼器
model = EncoderVGGMerged(merger_type='mean')
memory_bank = MemoryBank(n_vectors=5400, dim_vector=model.channels_code, memory_mixing_rate=0.5)
memory_bank.vectors = normalize(model.eval_codes_for_(dataloader), axis=1)
criterion = LocalAggregationLoss(memory_bank=memory_bank,
temperature=0.07, k_nearest_neighbours=500, clustering_repeats=6, number_of_centroids=100)
# 實體化一個隨機梯度下降優化器
optimizer = SGD(model.parameters())
# 基本訓練回圈
for epoch in range(20):
for inputs in dataloader:
optimizer.zero_grad()
output = model(inputs['image'])
loss = criterion(output, inputs['idx'])
loss.backward()
optimizer.step()
我在討論中省略了資料是如何準備的(我放在fungidata檔案中的操作),詳細資訊可以在倉庫中找(https://github.com/anderzzz/monkey_caput)
對于這個討論,將dataloader看作它可以回傳真菌影像的小批量資料,inputs['image'],以及它們在更大資料集中的相應索引,inputs['idx'],
訓練回圈是函式式的,雖然很簡短,但詳細資訊請參閱la_learner檔案,不過沒有使用任何不同尋常的東西,
我使用稍微修改過的編碼器EncoderVGGMerged版本,它是EncoderVGG的子類,
class EncoderVGGMerged(EncoderVGG):
'''VGG編碼器的特殊情況,其中代碼是沿著高度/寬度維度合并的,這是' EncoderVGG '的一個瘦子類,
Args:
merger_type (str, optional): 定義如何合并代碼.
'''
def __init__(self, merger_type='mean', pretrained_params=True):
super(EncoderVGGMerged, self).__init__(pretrained_params=pretrained_params)
if merger_type is None:
self.code_post_process = lambda x: x
self.code_post_process_kwargs = {}
elif merger_type == 'mean':
self.code_post_process = torch.mean
self.code_post_process_kwargs = {'dim' : (-2, -1)}
elif merger_type == 'flatten':
self.code_post_process = torch.flatten
self.code_post_process_kwargs = {'start_dim' : 1, 'end_dim' : -1}
else:
raise ValueError('Unknown merger type for the encoder code: {}'.format(merger_type))
def forward(self, x):
'''影像輸入到編碼器
Args:
x (Tensor): 圖片張量
Returns:
x_code (Tensor): 合并
'''
x_current, _ = super().forward(x)
x_code = self.code_post_process(x_current, **self.code_post_process_kwargs)
return x_code
這個類在編碼器的結果中附加一個應用于代碼的合并層,因此它是一個一維的向量,
我將演示用于聚類的編碼器模型,該模型應用于一個RGB 64x64影像作為輸入,
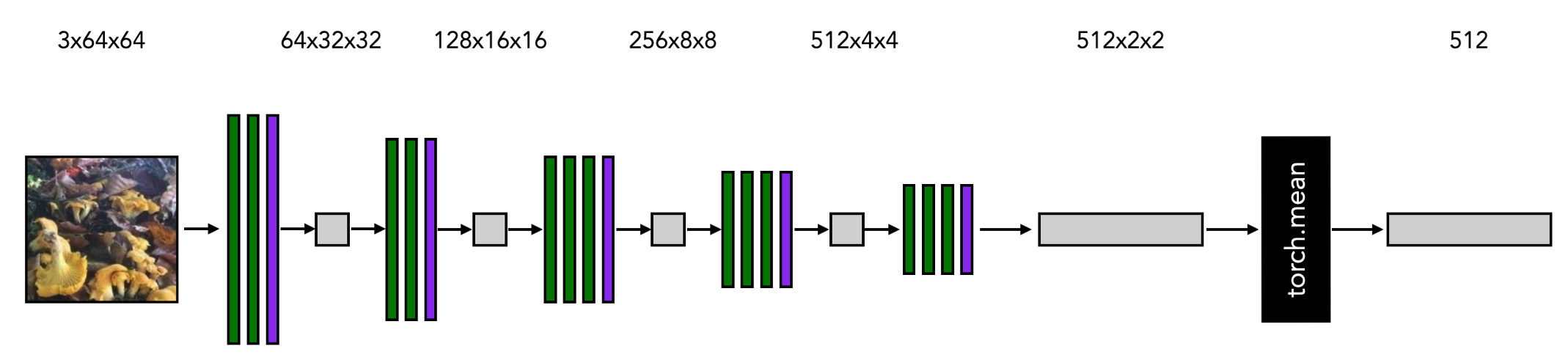
接下來,我將演示創建輸出和損失變數的模型的一小批影像的前向程序,
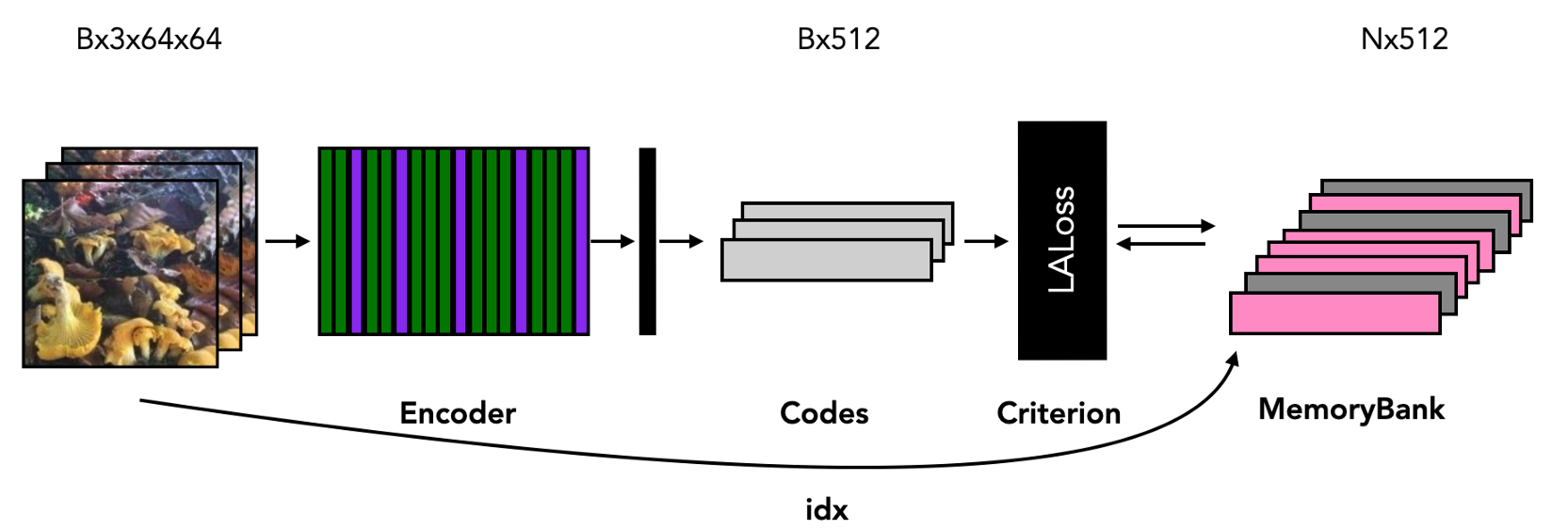
圖中的LALoss模塊與記憶庫互動,考慮到大小為N的總資料集中的小批量影像的索引,它構建記憶庫當前狀態的簇和最近鄰,并將小批量代碼與這些子集關聯起來,
backward執行反向傳播,從LA準則的損失輸出開始,然后遵循涉及代碼的數學運算,并通過鏈式規則獲得LA目標函式相對于編碼器引數的近似梯度,
關于真菌影像
我將把這個方法應用到真菌影像中,我的理由:
-
我使用的軟體庫不是為這個特定任務開發或預先訓練的,我希望測驗使用通用庫工具處理特殊影像任務的場景,
-
真菌的外觀在形狀、顏色、大小、光澤、結構細節以及它們典型的背景(秋葉、青苔、土壤、采摘者的手)等方面各不相同,信號和噪聲都是不同的,
-
真菌影像位于人類憑直覺識別的明顯物體(例如狗、貓和汽車)與需要深層專業知識才能掌握的影像之間的最佳位置,我相信這有助于理解方法,
-
丹麥真菌學協會(2016)提供了非常好的注釋眾包公開資料,(https://svampe.databasen.org/).
以下是由真菌照片創建的影像資料,資料庫中的三幅影像如下所示,

說明性測驗運行和探索
LA的一個缺點是它涉及多個超引數,可悲的是,我沒有足夠的gpu來支持,所以我必須限制自己在超引數和真菌影像選擇的許多可能變化中的很少一部分,
我在這篇文章中的重點是從概念和方程實作(外加一個真菌影像資料的插件),因此,我在這里尋求說明和啟發,并將繼續對高層次的觀察得出進一步的結論,
我訓練AE的香腸菌和木耳蘑菇壓縮到224x224,在隨機梯度下降優化器下,AE最終收斂,但對于某些優化引數,訓練陷入次優,下面顯示了一個經過訓練的AE的輸入和輸出示例,
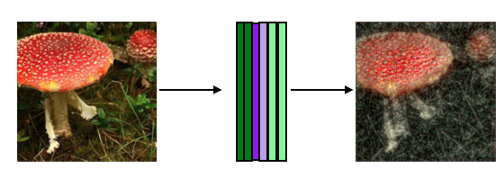
這是一個明顯的損失保真度,特別是在周圍的草地,
以AE的編碼器為起始點,進一步對編碼器進行LA目標優化,使用相同的一組蘑菇影像,溫度為0.07,混合速率為0.5(如原始論文中所述),聚類的數量約為待聚類影像數量的十分之一,由于我的影像資料集比較小,所以我設定了背景鄰居,將所有的影像都包含在資料集中,
一組影像說明如下:

很明顯,蒼蠅瓊脂簇有明顯的白色斑點,然而,在簇中所包含的影像也是相當不同的,觀察其他簇,在其他簇中偶爾會出現白點蒼耳帽,
另一個說明性簇如下所示,

這些影像有一些共同點,使它們與典型的影像有所不同:顏色較深,大部分來自背景中的褐色葉子,
但是,同樣的,滿足這個粗略標準的影像也出現在其他的聚類中,說明編碼中還有額外的非線性關系,這使得上面的影像對應的編碼相對緊密和不同,而其他的則不是,較難解釋,
我還注意到許多簇只包含一個影像,改變進入k-means聚類的簇質心的數量會影響到這一點,但是隨后會出現非常大的影像簇,因此很難提供對共享特征的直觀解釋,
這些是其他運行所生成的結果的說明,我在這里進行的有限的幾次運行中最小化了LA的場景,創造出了一組影像,至少在我看來是一組自然的影像,
考慮到深度神經網路的靈活性,我希望有很多方法可以將影像壓縮成清晰的簇,但就我所知,這些方法并不一定包含有用的含義,與實際情況標簽不同的是,神經網路的靈活性被引導到一個我們在優化之前定義為有用的目標,優化器在這里可以自由地尋找特征來利用,以提高簇質量,
也許需要一個不同的歸納偏差來更好地限制靈活性的部署,以最小化LA目標函式?就我的視覺認知而言,也許LA目標函式應該與一個附加目標相結合,以防止它偏離某個合理的范圍?也許我應該使用標準化的影像,例如某些醫學影像、護照照片或固定透視相機,將影像的變化限制為較少的高級特征,而這些特征可以在聚類中使用?或者,我擔心的真正答案是在這個問題上投入更多的gpu,然后找出超引數的完美組合?
當然都是猜測,多虧了PyTorch,從概念和方程式到原型設計和創建模板解決方案的障礙降低了,
結尾
常規警告:我對LA的實作與最初的論文一樣,所以有出現誤解或bug的可能性,
我沒有花任何精力來優化實作,很可能我忽略了PyTorch和/或NumPy技巧,它們可以加快CPU或GPU的速度,
原文鏈接:https://towardsdatascience.com/image-clustering-implementation-with-pytorch-587af1d14123
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/223026.html
標籤:其他
上一篇:Python 爬蟲進階必備 | 關于新聞平臺請求頭加密引數邏輯分析
下一篇:用PyTorch實作影像聚類