問題提出:
給定一段長度為n的文本字串txt和一段長度為m的模式字串pat,在文本字串txt中找到一個和該模式字串pat相同的子字串,找到則回傳匹配的起始位置,沒有回傳-1,
解決方法:
- 樸素字串匹配演算法
- KMP演算法
樸素字串匹配演算法開始
樸素字串匹配演算法:針對pat與txt,使用指標i跟蹤txt,使用指標j跟蹤pat,對于每個i,首先將j重置為0并不斷將他增大,直至找到了一個不匹配的字符或者模式結束(j==m)為止,偽代碼如下:
// search
1 m=pat.length
2 n=txt.length
3 for i=0 to n-m
4 for j=0 to m-1
5 if txt[i+j] != pat[j]
6 break
7 if j==m return i
8 return -1在上述匹配的程序中,當pat的j位置與txt的i+j位置不匹配時,i+j回退到i+1位置,j回退到0位置,因此在最壞的情況下,每次都比較到pat的最后一個位置才發現不匹配,那么時間復雜度就是O(nm),匹配程序簡化如下:
初始:

第1次比較完,未命中:(j從0開始比較到3,i從0開始比較到3)

第2次比較完,未命中:(j從0開始比較到3,i從1開始比較到4)

第3次比較完,未命中:(j從0開始比較到3,i從2開始比較到5)

后續未命中方式都是一致的,直接展示最后一步...
最后1次比較完,命中,回傳9(角標從0計算):(j從0開始比較到3,i從9開始比較到12)

當回退前(j >0)的時,我么知道pat的pat[0...j-1]與txt[i...i+j-1]是匹配的,那么是否可以利用這一點,并通過某個陣列幫助我們計算在這種情況下具體需要回退多少,而不是讓j一下子回退到0,也就是避免“搜索位置移過已經比較過且匹配的位置”,從而保證提高比較的效率,實際上,這種演算法已經被提出和數學證明,它就是KMP演算法,
KMP演算法
由Knuth,Morris和Pratt三人于1977年聯合發表,將時間復雜度降為O(n+m),
演算法思路:
-
構造模式串pat的next[]陣列,記錄最少回退下的回退下標位置,使得匹配串txt在匹配程序中角標不斷后移,避免txt串回退造成低效率;
-
kmp在next[]陣列幫助下完成,具體參見kmp演算法圖解;
-
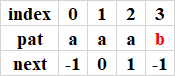
next[]陣列是kmp完成的一大關鍵,其效率也會影響最終演算法的整體效率,使用以下定義(第一張圖片),在實作時使用dp思想,更精確來說是有限狀態機思想,結合跳躍回退建成,時間復雜度為O(m),m時模式串pattern的長度,
pat串next的陣列的定義與建立程序
next陣列的定義:
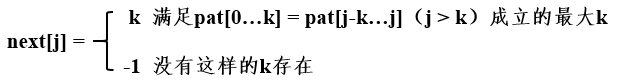
對于上述的pat串,建立next陣列,程序如下:
程序1:index等于1時,沒有這樣的k存在,next[0] = -1;
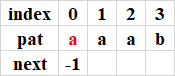
程序2:index等于2時,pat[0...0] = pat[1...1],因此k=0,即next[1] = 0;
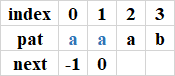
程序3:index等于3時,pat[0...1] = pat[1...2],因此k=1,即next[3] = 1;
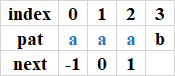
程序4:index等于4時,沒有這樣的k存在,next[3] = -1;
最終:
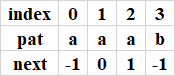
是不是看著挺簡單的,留個難一點的例子pat = "ababbabbabbabab",留作練習(答案如下),

那么如何通過代碼來高效的構建next陣列
1、暴力列舉法構建next陣列
很明顯,如果采用最簡單的暴力列舉方法建立,時間復雜度是O(m^3),如下圖所示
現在假設j處于最后一個位置(黑色箭頭所示),如果每一步都匹配,但是匹配程序是逐步增加的,紅色和藍色箭頭所示,因此對于位置j,需要比較的次數最多是1+2+3+...+j-1=j*(j-1)/2,即O(j^2),而我們的j位置(黑色箭頭的取值范圍0-m), 因此最壞情況大致是1^2+2^2+...+m^2 = m(m+1)(2m+1)/6,即O(m^3),顯然通過暴力列舉方式是非常低效的,

2、利用狀態轉移機制高效建立next陣列
正如我們前面所說,我們要利用前面匹配的串的狀態記錄來推導計算后面位置的值,狀態求解從j=0開始,現在給出一般情況,要求的位置j狀態處于較后的位置,如下圖所示:
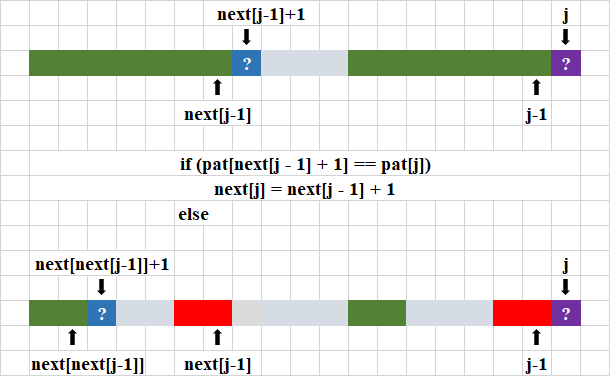
這就一種有限狀態轉移機制,求解當前狀態,利用上一個狀態,上一個狀態能確定本次狀態,完成狀態計算,否則,利用上一個狀態的前一個狀態,看能否確定本次狀態,直到沒有前一個狀態可是使用,
偽代碼如下:
// buildNext
1 m=pat.size()
2 let next[0...m] be a new array and be initialized to -1
3 k=0
4 for j=1 to m-1
5 k=next[j-1]
6 while k>=0 and pat[k+1]≠pat[j]
7 k=next[k]
8 if pat[k+1]==pat[j]
9 next[j]=k+1
10 return next注意:以上偽代碼有個for回圈和一個while回圈,理論上時間復雜度是O(m^2),但不完全準確,大歐表示法是上界表示法,只能說正確,但不夠精確,分析下,這里是回退,對于每一個回退,k的回退次數不會高于k的增長次數,k的最大增長次數不會大于m,因為這里是有限狀態機制,本次k影響下一次的回退次數,這里說個極端最差情況,最后k為0,針對增加m次減小m次,一增一減,那么最侄訓圈次數是2*m,在演算法導論中使用攤還分析的聚合方法進行分析得出時間復雜度Θ(m),
kmp演算法search演算法
當前訪問的txt串和pat串對應位置txt[i]與pat[j]匹配,i和j均向前移1位,進行下一輪比較;
當前訪問的txt串和pat串對應位置txt[i]與pat[j]不匹配且j大于0(即j可以回退),利用next陣列確定j的回退位置,然后進行下一輪比較;
當上述兩者均不滿足,說明txt[i] != pat[0],直接將i向前移動1位,進行下一輪比較,
示意圖如下:

偽代碼如下:
// search
// txt pat
1 n=txt.size, m=pat.txt, i=0, j=0
2 while i<n and j<m
3 if txt[i]==pat[j]
4 i++, j++
5 else if j>0
6 j=next[j-1]+1
7 else i++
8 return j==m ? i-m : -1時間復雜度的分析同樣采用攤還分析的聚合方法,為Θ(m),
案例模擬:
接下來使用上述kmp演算法的search函式和next陣列模擬下開頭的例子
初始狀態:

第1次比較完,未命中:(j從0開始比較到3,i從0開始比較到3)
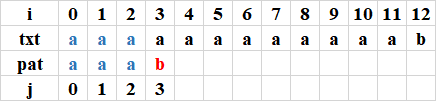
利用next陣列進行回退,下一個j = next[3 - 1] + 1 = 2
第2次比較完,未命中:(j從2開始比較到3,i從3開始比較到4)
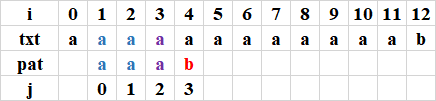
利用next陣列進行回退,下一個j = next[3 - 1] + 1 = 2
第3次比較完,未命中:(j從2開始比較到3,i從4開始比較到5)
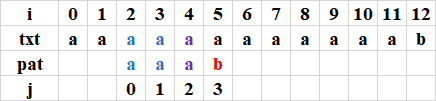
利用next陣列進行回退,下一個j = next[3 - 1] + 1 = 2
...
最后1次比較完,命中,回傳9:(j從2開始比較到3,i從11開始比較到12)
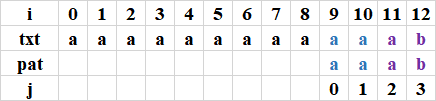
完整的代碼C++版本
#include <iostream>
#include <vector>
using namespace std;
// liyang 2019-12-12
// update: 2020-09-14
class KMP {
public:
// 在文本字串txt中尋找模式字串pat
// 找到:回傳第一次匹配時pat在txt中的角標位置
// 沒找到:回傳-1
static int indexOf(const string txt, const string pat) {
int n = txt.size(); int m = pat.size();
if (m <= 0) {
cout << "模式字串pat輸入不合法!" << endl;
return -1;
}
if (n < m) {
cout << "文本字串txt的長度小于模式字串的長度,不合法!" << endl;
return -1;
}
vector<int> next = buildNext(pat, m);
return search(txt, pat, next);
}
private:
// 創建pat字串的next陣列
static vector<int> buildNext(const string& pat, const int& m) {
vector<int> next(m, -1);
for (int j = 1, k; j < m; j++) {
k = next[j - 1];
while (k >= 0 && pat[k + 1] != pat[j]) {
k = next[k];
}
if (pat[k + 1] == pat[j]) {
next[j] = k + 1;
}
}
return next;
}
// 利用next陣列進行真正的查找操作
static int search(const string& txt, const string& pat, const vector<int>& next) {
int n = txt.size(); int m = pat.size();
int i = 0, j = 0;
while (i < n && j < m) {
if (txt[i] == pat[j]) { // 匹配
i++; j++;
}
else if (j > 0) { // 不匹配,j可以回退
j = next[j - 1] + 1;
}
else { // 不匹配,j不可以回退(j==0),只能i前進
i++;
}
}
return j == m ? i - m : -1;
}
};
int main(int argc, const char* argv[]) {
string txt = "aaaaaaaaaaab";
string pat = "aab";
int index = KMP::indexOf(txt, pat);
int n = txt.size();
cout << index << ": " << (n - 3 == index ? "correct" : "wrong") << endl;
system("pause");
return 0;
}9: correct
請按任意鍵繼續. . .
完整版的Java代碼
package com.ly.kmp;
/**
* @author Young 2020-09-14
* update:2020-09-15
*/
public class KMP {
public static int indexOf(String txt, String pat) {
int n = txt.length(); int m = pat.length();
if (n < m || m == 0) {
System.out.println("字串輸入有問題,請核對后重新輸入!");
return -1;
}
int[] next = buildNext(pat);
return search(txt, pat, next);
}
private static int[] buildNext(String pat) {
int m = pat.length();
int[] next = new int[m];
next[0] = -1;
int k;
for (int j = 1; j < m; j++) {
k = next[j - 1];
while (k >= 0 && pat.charAt(k + 1) != pat.charAt(j)) {
k = next[k];
}
if (pat.charAt(k + 1) == pat.charAt(j)) {
next[j] = k + 1;
} else {
next[j] = -1;
}
}
return next;
}
private static int search(String txt, String pat, int[] next) {
int n = txt.length(); int m = pat.length();
int i = 0; int j = 0;
while (i < n && j < m) {
if (txt.charAt(i) == pat.charAt(j)) {
i++; j++;
} else if (j > 0) {
j = next[j - 1] + 1;
} else {
i++;
}
}
return j == m ? i - m : -1;
}
public static void main(String[] args) {
String txt = "aaaaaaaaaaaab";
String pat = "aaab";
int index = KMP.indexOf(txt, pat);
int n = txt.length();
System.out.println(index + ": " + ((n - 4) == index ? "correct" : "wrong"));
}
}9: correct
Process finished with exit code 0參考資料:
浙大資料結構
演算法導論
演算法4
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/223264.html
標籤:其他