目錄
ES底層索引原理
IK分詞器
IK中自定義配置擴展詞和停用詞
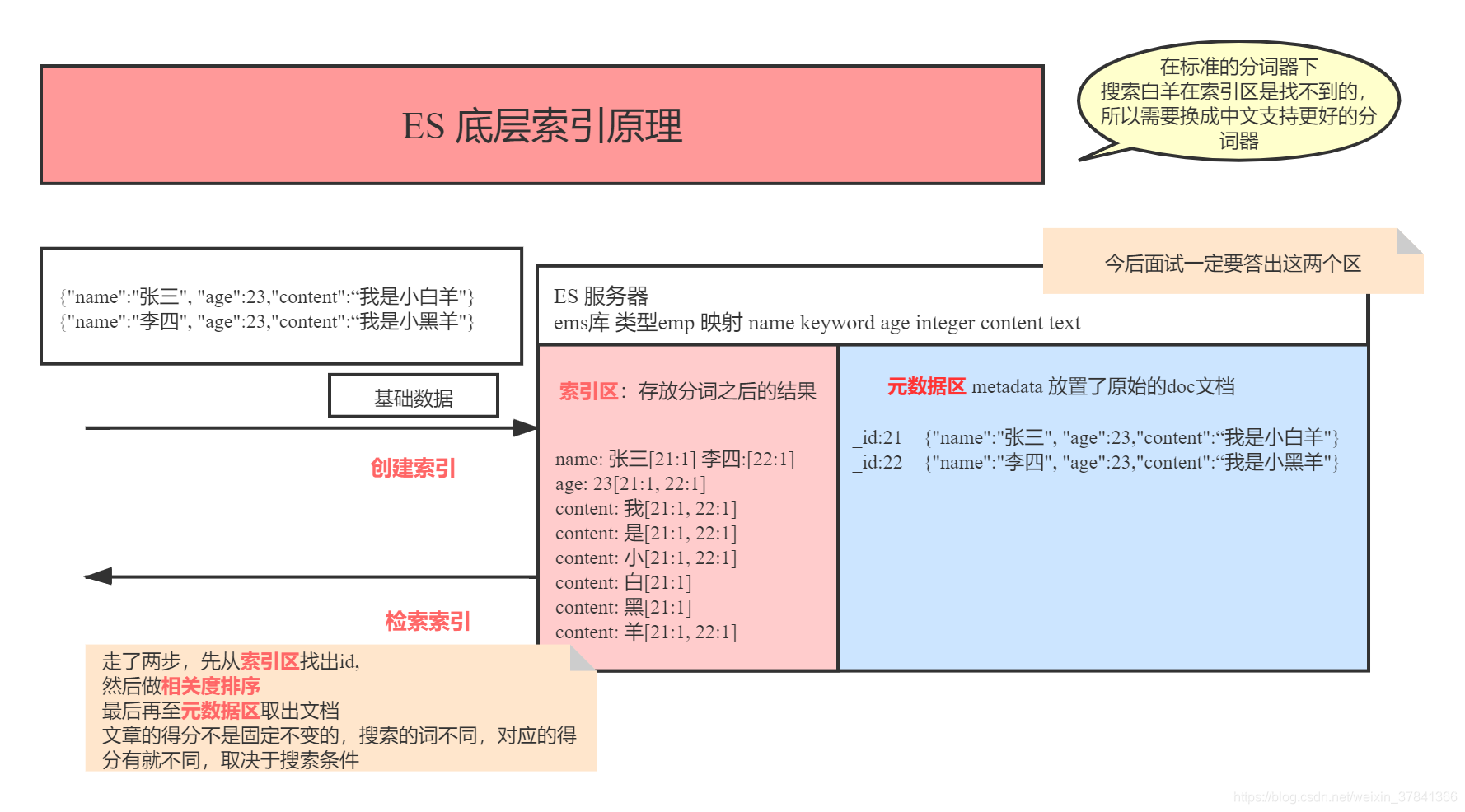
ES底層索引原理
IK分詞器
1. 定義:就是將一本文本中關鍵詞拆分出來
我是小明的同學 分詞器 小明 同學
分詞原理: 拆分關鍵字 去掉停用詞 和 停用詞
2. ES中提供分詞器
1. 默認 標準分詞器 standard analyzer 英文:單詞分詞 中文:單字分詞
2.簡單 simple analyzer 英文:單詞分詞 去掉數字 中文:不分詞
3. 測驗不同的分詞器
GET /_analyzer
{
"analyzer":"simple",
"text":"redis 非常好用 111"
}- standard 分詞結果為 : redis 非 常 好 用 111
- simple 分詞結果為: redis 非常好用
4.github 基于ES分詞器IK分詞器
注意:使用IK分詞器和ES版本必須嚴格一致
5. ik_max_word和ik_smart什么區別?
- ik_max_word:會將文本做最細粒度的拆分,比如會將"我是小明的同學"拆分為"我是小明的同學", "我是","我是小明","小明的同學","同學",會窮盡各種可能的組合我是小明的同學
- ik_smart:會做最粗粒度的拆分,比如會將"我是小明的同學",拆分為"我是小明的同學”
PUT /emp
{
"mappings":{
"emp":{
"properties":{
"name":{
"type":"text",
"analyzer":"ik_max_word"
},
"age":{
"type":"integer"
},
"bir":{
"type":"date"
},
"content":{
"type":"text",
"analyzer":"ik_max_word"
},
"address":{
"type":"keyword"
}
}
}
}
}IK中自定義配置擴展詞和停用詞
1. 擴展詞
定義:現有ik分詞器無法將這個詞切分成一個關鍵詞,但是又希望某個詞成為關鍵詞
ik 分詞器 等都可以被拆分成關鍵詞,比如一些熱門流行的網路詞
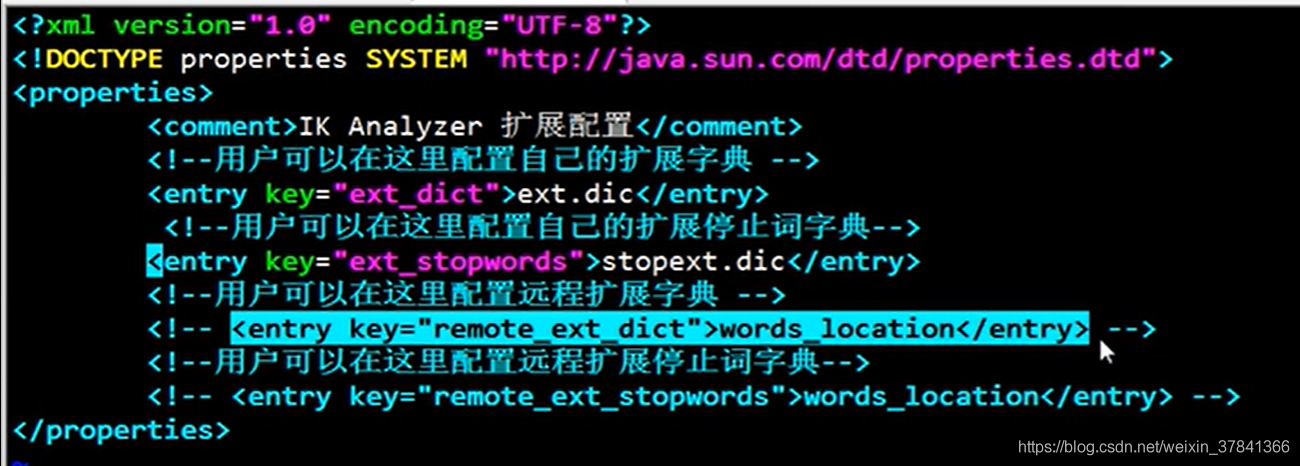
配置IK的組態檔: ES安裝目錄下/plugins/ik/config 目錄中名字 :IKAnalyzer.cfg.xml
修改組態檔加入如下配置:
<!--用戶可以在這里配置自己的擴展字典>
<entry key="ext_dict">ext.dic</entry>
2. 停用詞
定義:現有ik分詞器將一個關鍵詞切分成一個詞,但是出于某種原因這個詞不能作為關鍵詞出現
<entry key="ext_stopwords">stopext.dic</entry>
3.配置遠程擴展詞典
ES中Query
1. Query String ! Query DSL查詢
關鍵詞查詢 -----> 計算得分 排序 等一系列
2. Filter Quey 過濾查詢 效率比較高
篩選出符合條件的資料 --------> 不會計算檔案 得分 排序, 常用Filter 自動常用fiter結果
必須使用bool運算式將兩種query組合在一起
注意:當filterQuery 和query組合使用時先執行fiterQuery中陳述句 然后再去執行query中陳述句
過濾適合在大范圍篩選資料,而查詢則適合精確匹配資料,一般應用時,應先使用過濾資料,然后使用查詢匹配資料,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/223445.html
標籤:其他
上一篇:雙十一背后的技術