Redis高可用—主從復制
- 一、為什么需要主從復制?
- 二、配置主從復制
- 三、主從復制實作原理
- 1. 建立連接
- 2. 同步
- 2.1 完整重同步
- 2.2 部分重同步
- 3. 命令傳播
- 四、讀寫分離存在的問題
- 1. 延遲與不一致
- 2. 資料過期
- 五、參考文獻
一、為什么需要主從復制?
前一篇文章講了Redis高可用—持久化,將記憶體資料持久化到硬碟,即使Redis服務器宕機,也能夠根據AOF或者RDB檔案恢復資料庫狀態,但是持久化的資料仍然只在一臺服務器上,當服務器故障無法重啟時,持久化就不能保證資料安全性了,這時候就需要進行主從復制,
主從復制,是將一臺服務器的資料復制到其他服務器上,前者稱為主節點master,后者稱為從節點slave,
主從復制有以下作用:
- 故障恢復:當主節點出現故障時,從節點可以提供服務,實作快速故障恢復;
- 資料冗余:實作了資料備份,是持久化之外的一種資料冗余方式;
- 負載均衡:主從復制+讀寫分離,可以由主節點提供寫服務,從節點提供讀服務,通過多個從節點分擔負載,可以大大提高并發量,
二、配置主從復制
默認每個節點都是主節點,通過slaveof <ip> <port>開啟主從復制關系,slaveof no one 關閉主從復制,
開啟主從復制有3種方式:
- redis.conf:在組態檔中添加
slaveof ip port; - 啟動命令:redis-server啟動命令后加
slaveof ip port; - 客戶端命令:通過在客戶端執行
slaveof ip port使該節點成為從節點,
例如,我們在本機采用多個埠來模擬主從復制:主節點(6379)、從節點1(6380)、從節點2(6381),
- 首先,在redis6380.conf、redis6381.conf中配置6380和6381為6379的從節點:
slaveof 127.0.0.1 6379
- 然后,啟動3個Redis服務節點;
#啟動6379
redis-server /opt/software/redis-3.2/myconf/redis6379.conf
#啟動6380
redis-server /opt/software/redis-3.2/myconf/redis6380.conf
#啟動6381
redis-server /opt/software/redis-3.2/myconf/redis6381.conf
- 分別連接6379、6380、6381,通過
info replication查看主從復制關系:
[root@mq bin]# redis-cli -p 6379
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=2227,lag=1
slave1:ip=127.0.0.1,port=6381,state=online,offset=2227,lag=1
master_repl_offset:2227
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:2226
[root@mq bin]# redis-cli -p 6380
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:8
master_sync_in_progress:0
slave_repl_offset:2367
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
[root@mq bin]# redis-cli -p 6381
127.0.0.1:6381> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:2
master_sync_in_progress:0
slave_repl_offset:2479
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
- 在6379節點執行命令:
127.0.0.1:6381> set k1 v1
127.0.0.1:6379> keys *
1) "k1"
- 查看6380、6381節點的資料,能夠看到從節點同步了主節點的資料:
127.0.0.1:6380> keys *
1) "k1"
127.0.0.1:6380> keys *
1) "k1"
- 如果主節點6379出現故障,我們可以將6380設定為主節點,讓6381成為6380的從節點,新的主從關系建立,可以通過info replication 查看,
127.0.0.1:6380> slaveof no one
127.0.0.1:6381> slaveof 127.0.0.1 6380
注意:Redis非集群模式下的主從復制支持樹狀結構(中間的節點既是其主節點的從節點,也是其從節點的主節點),這種拓撲結構可以減少主節點的直接從節點,降低主節點的負擔;但多層從節點的延遲增大,資料一致性變差,結構復雜,維護比較困難,
三、主從復制實作原理
通過向從服務器發送SLAVEOF命令,可以讓從服務器去復制主服務器,Redis的復制功能分為:建立連接、同步、命令傳播,
1. 建立連接
這個階段會進行以下操作:保存主節點資訊、主從節點建立socket連接、從節點向主節點發送ping命令、從節點向主節點進行身份驗證、發送從節點埠資訊等,這里暫不詳細展開說明,
2. 同步
同步程序分為:完整重同步和部分重同步,
2.1 完整重同步
完整重同步:用于處理初次復制情況(從服務器以前沒有復制過任何服務器,或從服務器當前要復制的主服務器和上次復制的主服務器不同),
當客戶端向從服務器發送slaveof ip port命令,要求從服務器復制主服務器時,從服務器首先需要執行完整重同步操作,該程序需要從服務器向主服務器發送PSYNC命令實作(Redis2.8以前是SYNC命令),
完整重同步的執行步驟如下:
- 從服務器向主服務器發送 PSYNC 命令;
- 主服務器收到 PSYNC 命令,執行BGSAVE 命令在后臺生成一個RDB檔案,并使用一個緩沖區記錄從現在開始執行的所有寫操作;
- 當BGSAVE命令執行完畢時,主服務器會將RDB檔案發送給從服務器,從服務器接收RDB檔案,清空老資料,載入RDB檔案,從服務器載入RDB檔案的程序是阻塞的,無法回應客戶端請求,
- 主服務器將記錄在緩沖區里的所有寫命令發送給從服務器,從服務器執行這些寫命令,將自己的資料庫狀態更新至和主服務器一致,
完整重同步缺點:消耗CPU、記憶體、磁盤IO、網路帶寬等,
2.2 部分重同步
部分重同步:用于斷線后重復制情況(當從服務器在斷線后重新連接主服務器時,如果條件允許,主服務器將從服務器斷開期間的寫命令發送給從服務器,從服務器接收并執行這些寫命令,將資料庫狀態更新至和主服務器一致),
redis2.8之前沒有部分重同步,斷線后仍然采用完整重同步,通過從服務器向主服務器發送SYNC命令實作,
部分重同步實作是基于:復制偏移量、復制積壓緩沖區、服務器運行ID,
(1)復制偏移量
主從服務器都維護一個復制偏移量,主服務器每次向從服務器傳播N個位元組的資料,就將自己的復制偏移量加N;從服務器每次接收到主服務器的N個位元組的資料,就將自己的復制偏移量加N,因此可以根據主從服務器的復制偏移量是否相等判斷主從服務器是否處于一致狀態,
(2)復制積壓緩沖區
復制積壓快取區是主服務器維護的一個固定長度先進先出的佇列,默認大小1M,主服務器進行命令傳播時,不僅會將寫命令發送給所有從服務器,還會將寫命令寫入復制積壓緩沖區,復制積壓緩沖區記錄了寫命令和每個位元組對應的偏移量,
當從服務器斷線后重新連上主服務器,從服務器會發送PSYNC命令將自己的復制偏移量offset發送給主服務器,主服務器根據這個復制偏移量決定執行完整重同步還是部分重同步,如果offset之后的資料還在復制積壓緩沖區中,則執行部分重同步;否則執行完整重同步,
(3)服務器運行ID
每個Redis服務器都有自己的運行ID,從服務器對主服務器進行初次復制時,主服務器會將自己的運行ID發送給從服務器,從服務器將這個ID保存起來,當從服務器斷線后重連上一個主服務器時,從服務器會向當前連接的主服務器發送之前保存的主服務器運行ID,
如果從服務器保存的運行ID和當前連接的主服務器ID相同,說明主服務器斷線前連接的主服務器就是這個主服務器,可以嘗試進行部分重同步;如果不相同,則進行完整重同步,
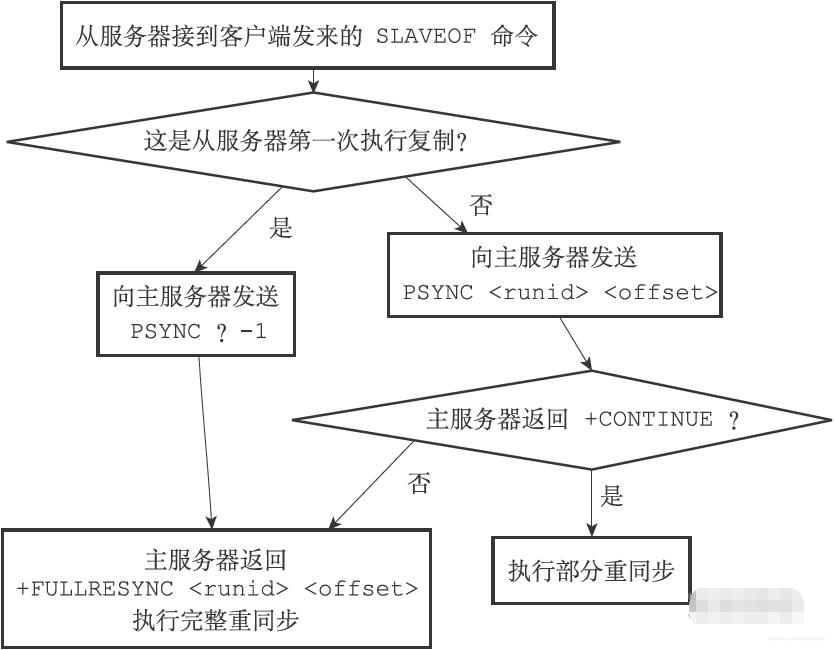
綜上,一個PSYNC命令執行完整重同步和部分重同步的程序如下圖:
3. 命令傳播
完成同步之后,主從服務器就會進入命令傳播階段,主服務器一直將自己執行的寫命令發送給從服務器,從服務器接收并執行主服務器發來的寫命令,保證主從服務器資料庫狀態一致,
心跳檢測
命令傳播期間,從服務器默認會以每秒一次的頻率,向主服務發送命令:REPLCONF ACK <replication_offset>,其中replication_offset是從服務器的復制偏移量,
發送這個命令有以下3個作用:
- 檢測主從服務器的網路連接狀態,
如果主服務器超過一秒鐘沒有收到從服務器發來的REPLCONF ACK命令,主服務器就知道主從之間發生了連接問題, 在主服務器上執行info replication 命令,可以看到 lag=1,表示1秒之前發過REPLCONF ACK命令,
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=2227,lag=1 #1秒之前發過REPLCONF ACK命令
slave1:ip=127.0.0.1,port=6381,state=online,offset=2227,lag=1
- 輔助實作min-slaves選項,
Redis的min-slaves-to-write和min-slaves-max-lag兩個選項可以 防止主服務器在不安全的情況下執行寫命令,
min-slaves-to-write 3 #從服務器數量不少于3個
min-slaves-max-lag 10 #從服務器發送REPLCONF ACK命令的延遲時間不超過10秒
當以上2個條件中任意一個條件不滿足時,主服務器將拒絕執行寫命令,
- 檢測命令丟失,
如果因網路故障,主服務器發送給從服務器的命令在半路丟失,那么當從服務器向主服務器發送REPLCONF ACK命令時,主服務器會發現從服務器的復制偏移量少于自己的復制偏移量,主服務器會從復制積壓緩沖區里找到從服務器缺少的資料,將這些資料重新發送給從服務器,
四、讀寫分離存在的問題
1. 延遲與不一致
主從復制的命令傳播是異步的,讀寫分離時很可能會發生資料的不一致,可能的優化方案有:
(1)優化主從節點之間的網路環境;
(2)如果主從節點延遲過大,不再讀從;
(3)使用集群同時擴展寫負載和讀負載,
2. 資料過期
單機版Redis的資料過期策略包括:惰性洗掉、定期洗掉,
主從復制時,為了主從節點資料的一致性,從節點不會主動洗掉快取,而是由主節點控制從節點中過期資料的洗掉,由于主節點的惰性洗掉和定期洗掉都不能保證主節點及時對過期資料進行洗掉,因此當客戶端通過從節點讀取資料時,很可能會讀到過期的資料,Redis3.2中,從節點讀取資料時,增加了資料是否過期的判斷,如果資料過期,不再返給客戶端,升級到Redis3.2可以解決資料過期問題,
五、參考文獻
- 《Redis設計與實作》
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/225318.html
標籤:其他