語法分析實作
1. 目標及代碼
- 目標: 實作運算式的語法樹構建(加減乘除的運算式決議)
如: 將1+2*5等運算式決議為語法樹的形式
-
代碼地址: git代碼倉庫
-
注意: 本文章主要目的是記錄個人學習歷程,如有不對的地方歡迎大家評論指出
2. 語法分析階段做什么?
- 語法分析階段主要的功能就是把詞法分析的結果構建一顆語法樹, 此法階段就相當于找到了一個一個的單詞而語法階段要做的就是按照文法規則將這些單詞組織起來
- 此處采用的方法為遞回下降法, 文法部分內容太偏數學如果有興趣可自行搜索
3. 運算式決議理論簡介
3.1 運算式相關產生式
- Eper代表運算式,如果我們想用Eper來表示加法運算
// Eper代表開始符(類似完整運算式 1 + 1)
// Eper可以產生出Eper - Eper | Eper + Eper | digital 中間的豎線代表或者
// digital代表數字
// 完整的看就類似一個遞回運算式,遞回終結條件在于當前的Eper是否為一個digital
// 但是目前這樣的表達是直接寫代碼有問題,因為每一個Exper如果我們先處理左邊那么又是一個Exper,這樣就是一個無限遞回, 所以我們需要消除左遞回(注意:此處的Exper最終就是一個函式,用于決議一個運算式)
Eper -> Eper - Eper | Eper + Eper | digital
// digital 表示數字
digital -> [0-9]+
- 消除左遞回
//也就是說上述存在左遞回的形式直接被以下兩個推導式改為了右遞回
Exper -> digital Exper_
Exper_ -> -Exper Exper_ | +Exper Exper_ | null
// digital 表示數字
digital -> [0-9]+
- 偽代碼實作
- 注意一下代碼沒有做任何校驗僅僅描述主邏輯
func ExperTree Exper() {
// 構造回傳節點
ExperTree node = new ExperTree();
// Exper -> digital Exper_
// digital部分直接從符號流獲取
node.addChildNode(fetchDigitalToken());
// Exper_
node.addChildNode(Exper_());
return node;
}
func ExperTree Exper_() {
// 構造回傳節點
ExperTree node = new ExperTree();
// Exper -> digital Exper_
// digital部分直接從符號流獲取
node.addChildNode(fetchDigitalToken());
// Exper_
exper_Node = Exper_();
// 因為-Exper Exper_ | +Exper Exper_ | null, 中第一位是符號第二位才是一個運算式節點
node.addChildNode(exper_Node.get(1));
//當前運算式的符號(此處也就是+-)
node.setValue(exper_Node.get(0).value())
return node;
}
4. 多優先級運算式
- 如果出現乘除法該怎么處理
- 首先以上運算式如果出現乘除法是不能夠正確的構建一個語法樹的此處只寫出±/*法的運算式
// E運算式只表示加減法
E -> E + Iterm | E - Iterm | Iterm
// Iterm表示乘除法
Iterm -> Iterm * digital | Iterm / digital | digital
// digital 表示數字
digital -> [0-9]+
// 同樣由于左遞回的問題
E -> Iterm E_
E_ -> +Iterm E_ | -Iterm E_ | null
Iterm -> digital Iterm_
Iterm_ -> *digital Iterm_ | /digital Iterm_ | null
// 以上推導式中除了digital所有的都是函式
5. 通用運算式
- 在計算機中不僅僅只有上節中所說的兩種優先級(加減和乘除), 我們常見的優先級如下
1. <、<=、>、>=
2. +、-
3. *、/
4. << >>
5. ()、++、--
- 遇到多優先級改如何表達?一級一級的寫運算式? 在這里實際上我們可以將運算式定義為一個函式但是不同優先級可以傳入數字來表示當前是第幾優先級
- 運算式如下
// 注意Op(k) 代表當前優先級的所有符號集合
// E(k) 實際上在加減乘除中代表的就是E + Iterm | E - Iterm
// E(k + 1)實際上在加減乘除中代表的就是Iterm
E(K) -> E(k) Op(k) E(k + 1) | E(k + 1)
// 同樣因為運算式存在左遞回,消除左遞回如下
E(k) -> E(k + 1) E_(k)
E_(k) -> Op(k) E(k + 1) E_(k) | null
// 目前還有一個問題E(k) 中K到何時結束, 實際上就是到最高優先級就結束這里也就是5, terminal
// E(t) 類似于之前Term
E(t) -> E(t) Op(t) digital | digital
E(t) -> digital E_(t)
E_(t) -> Op(t) digital E_(t) | null
6.具體代碼實作
6.1 基礎語法樹節點
- 基礎結構類如下(具體代碼請查看代碼倉庫)
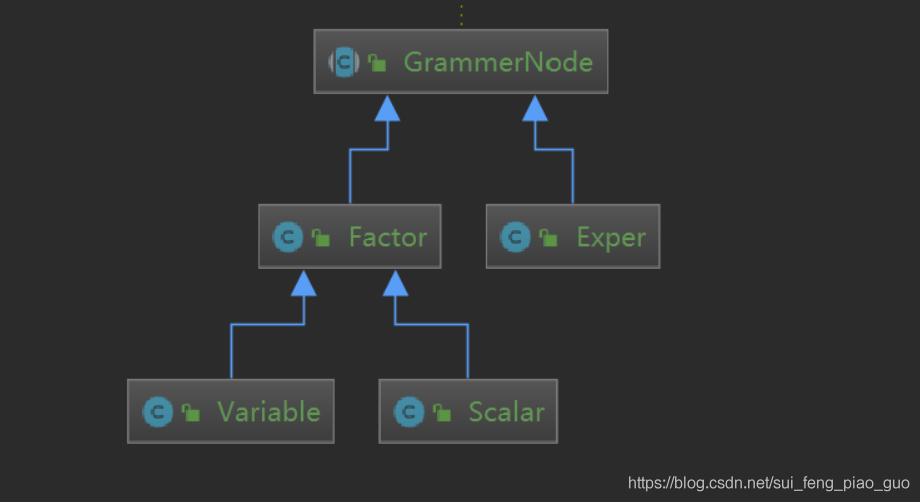
- GrammerNode為抽象語法節點(包含token以及節點型別)
- Factor是因子也是抽象類其主要有Variable和Scalar兩個子類
- Exper代表運算式的意思
- GrammerNode代碼
@Data
public abstract class GrammerNode {
protected Token token; // 詞法單元
protected String label; // 備注(標簽)
protected GrammerNodeTypes type;
//子節點
protected List<GrammerNode> children = new ArrayList<>();
//父節點
protected GrammerNode parent;
public GrammerNode() {
}
public GrammerNode(GrammerNodeTypes type, String label) {
this.type = type;
this.label = label;
}
public GrammerNode getChild(int index) {
if(index >= this.children.size()) {
return null;
}
return this.children.get(index);
}
public void addChild(GrammerNode node) {
node.parent = this;
children.add(node);
}
}
6.2 添加PeekTokenIterator
- 目的:用于將Token作為流進行操作
- 具體代碼如下:
public class PeekTokenIterator extends PeekIterator<Token> {
public PeekTokenIterator(Stream<Token> stream) {
super(stream);
}
/**
* 判斷下一個token的值是否等于value并回傳token
* @param value
* @return
* @throws ParseException
*/
public Token nextMatch(String value) throws ParseException {
Token token = this.next();
if(!token.getValue().equals(value)) {
throw new ParseException(token);
}
return token;
}
/**
* 判斷下一個token的型別是否等于type并回傳token
* @param type
* @return
* @throws ParseException
*/
public Token nextMatch(TokenType type) throws ParseException {
Token token = this.next();
if(!token.getType().equals(type)) {
throw new ParseException(token);
}
return token;
}
}
6.3 保存優先級符號
- 保存所有的運算子到集合
- 具體代碼
/**
* 運算子優先級存盤
*/
public class PriorityTable {
private List<List<String>> table = new ArrayList<>();
public PriorityTable() {
table.add(Arrays.asList("&", "|", "^"));
table.add(Arrays.asList("==", "!=", ">", "<", ">=", "<="));
table.add(Arrays.asList("+", "-"));
table.add(Arrays.asList("*", "/"));
table.add(Arrays.asList("<<", ">>"));
}
public int size(){
return table.size();
}
public List<String> get(int level) {
return table.get(level);
}
}
6.4 Exper中實作語法分析
- 運算式如下
E(K) -> E(k) Op(k) E(k + 1) | E(k + 1)
// 同樣因為運算式存在左遞回,消除左遞回如下
E(k) -> E(k + 1) E_(k)
E_(k) -> Op(k) E(k + 1) E_(k) | null
// 目前還有一個問題E(k) 中K到何時結束, 實際上就是到最高優先級就結束這里也就是5, terminal
// E(t) 類似于之前Term
E(t) -> E(t) Op(t) digital | digital
E(t) -> digital E_(t)
E_(t) -> Op(t) digital E_(t) | null
-
目標: 輸入一個Token流,將Token流決議為語法樹
-
實作從字符流中決議actor(相當于決議Digital)
public class Factor extends GrammerNode {
public Factor(Token token) {
super();
this.token = token;
this.label = token.getValue();
}
public static GrammerNode parse(PeekTokenIterator it) {
Token token = it.peek();
TokenType type = token.getType();
if(type == TokenType.VARIABLE) {
it.next();
return new Variable(token);
} else if(token.isScalar()){
it.next();
return new Scalar(token);
}
return null;
}
}
- 在Expr中實作完整運算式推導,整體運算式決議入口為pase函式
/**
* 運算式
* 一元運算式
* 二元運算式
*/
public class Expr extends GrammerNode {
//優先級存盤物件
private static PriorityTable priorityTable = new PriorityTable();
public Expr(GrammerNodeTypes type, Token token) {
super();
this.type = type;
this.label = token.getValue();
this.token = token;
}
/**
* 傳入符號流
* @param it 符號流迭代器
* @return 語法樹根節點
* @throws ParseException 語法例外
*/
public static GrammerNode parse(PeekTokenIterator it) throws ParseException {
// 起始符E E(K) -> E(k) Op(k) E(k + 1) | E(k + 1)
return E(0, it);
}
/**
* E(K)函式,其右遞回運算式如下
* E(k) -> E(k + 1) E_(k) 注意當 k 為最高優先級時為結束條件
* 注意:此處默認運算式一定是一元或二元運算式
* @param k 當前第幾優先級
* @param it 符號流
* @return 語法根節點
*/
private static GrammerNode E(int k, PeekTokenIterator it) throws ParseException {
//當還未達到最高優先級時E(k) -> E(k + 1) E_(k)
// 當前情況Expr.left = E(k + 1) Exper.right = E_(k)中的運算式部分 Expr.label為E_(k)的符號部分
if (k < priorityTable.size() - 1) {
GrammerNode expr = combine(it, () -> E(k + 1, it), () -> E_(k , it));
return expr;
} else {
// 達到最高優先級
//E(t) -> digital E_(t)
//E(t) -> F E_(t) | U E_(t) 此處F相當于digital,但還有一種特俗情況一元運算式
return race(
it,
() -> combine( it, () -> F(it), () -> E_( k, it)),
() -> combine( it, () -> U(it), () -> E_( k, it))
);
}
}
/**
* E(t) -> U E_(t)
* @param it
* @return
*/
private static GrammerNode U(PeekTokenIterator it) throws ParseException {
Token token = it.peek();
String value = token.getValue();
if(value.equals("(")) {
it.nextMatch("(");
GrammerNode expr = E(0, it);
it.nextMatch(")");
return expr;
}
else if (value.equals("++") || value.equals("--") || value.equals("!")) {
Token t = it.peek();
it.nextMatch(value);
Expr unaryExpr = new Expr(GrammerNodeTypes.UNARY_EXPR, t);
unaryExpr.addChild(E(0, it));
return unaryExpr;
}
return null;
}
/**
* E(t) -> F E_(t)
* @param it
* @return
*/
private static GrammerNode F(PeekTokenIterator it) {
GrammerNode node = Factor.parse(it);
if (null == node) {
return null;
}
return node;
}
/**
* E_(k) -> Op(k) E(k + 1) E_(k) | null
* @param k 當前級
* @param it 迭代器
* @return 節點
*/
private static GrammerNode E_(int k, PeekTokenIterator it) throws ParseException {
// lookhead查看當前第一位是否為運算子
Token token = it.peek();
String value = token.getValue();
//存在當前運算子不存在直接回傳空
if(priorityTable.get(k).indexOf(value) != -1) {
Expr expr = new Expr(GrammerNodeTypes.BINARY_EXPR, it.nextMatch(value));
expr.addChild(combine(it,
() -> E(k+1, it),
() -> E_(k, it)
));
return expr;
}
return null;
}
/**
* 結合時只看結果
* @param a E(k + 1)
* E(t) -> digital E_(t)
* @param b E_(k) E_(k) -> Op(k) E(k + 1) E_(k) | null
* @return 結合后的節點
*/
private static GrammerNode combine(PeekTokenIterator it, ExprFunc a, ExprFunc b) throws ParseException {
//如果a執行結果為空則時一元運算式
GrammerNode aNode = a.exec();
if(aNode == null) {
return it.hasNext() ? b.exec() : null;
}
GrammerNode bNode = it.hasNext() ? b.exec() : null;
if(bNode == null) {
return aNode;
}
//E_(k) -> Op(k) E(k + 1) E_(k) 此處相當于Op(k) 是根節點
Expr expr = new Expr(GrammerNodeTypes.BINARY_EXPR, bNode.token);
expr.addChild(aNode);
//E(k + 1)
expr.addChild(bNode.getChild(0));
//指定父節點
return expr;
}
private static GrammerNode race(PeekTokenIterator it, ExprFunc aFunc, ExprFunc bFunc) throws ParseException {
if(!it.hasNext()) {
return null;
}
GrammerNode a = aFunc.exec();
if(a != null) {
return a;
}
return bFunc.exec();
}
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/225341.html
標籤:其他
上一篇:我的第一篇博客