一、 RNN概述
人工神經網路和卷積神經網路的假設前提都是:元素之間是相互獨立的 ,但是在生活中很多情況下這種假設并不成立,比如你寫一段有意義的話 “遇見一個人只需1秒,喜歡一個人只需3,秒,愛上一個人只需1分鐘,而我卻用我的[?]在愛你,” ,作為正常人我們知道這里應該填 “一生”,但之所以我們會這樣填是因為我們讀取了背景關系,而普通的神經網路輸入之間是相互獨立的,網路沒有記憶能力,擴展一下:訓練樣本是連續的序列且其長短不一,如一段連續的語音、一段連續的文本等,這些序列前面的輸入與后面的輸入有有一定的相關性,很難將其拆解為一個個單獨的樣本來進行DNN/CNN訓練,
回圈神經網路(Recurrent Neural Networks,簡稱RNN)廣泛應用于:
- 語意分析(Semantic Analysis):按照語法分析器識別語法范疇進行語意檢查和處理,產生相應的中間代碼或者目標代碼
- 情感分析(Sentiment Classification)
- 影像標注(Image Captioning):對圖片進行文本描述
- 語言翻譯(Language Translation)
二、RNN網路結構及原理
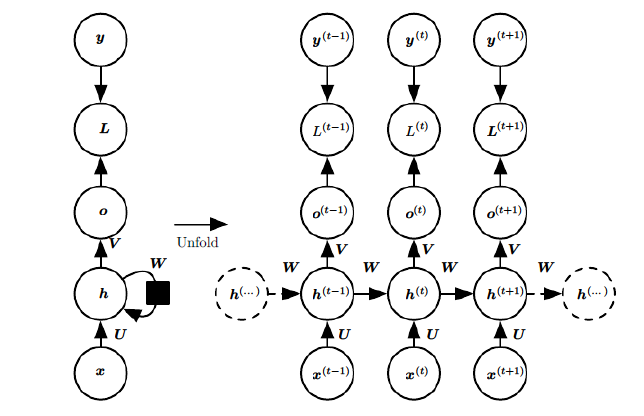
圖中各個引數意義:
1)x(t)代表在序列索引號t時訓練樣本的輸入,同樣的,x(t?1)和x(t+1)代表在序列索引號t?1和t+1時訓練樣本的輸入,
2)h(t)代表在序列索引號t時模型的隱藏狀態,h(t)由x(t)和h(t?1)共同決定,
3)o(t)代表在序列索引號t時模型的輸出,o(t)只由模型當前的隱藏狀態h(t)決定,
4)L(t)代表在序列索引號t時模型的損失函式,
5)y(t)代表在序列索引號t時訓練樣本序列的真實輸出,
6)U,W,V這三個矩陣是我們的模型的線性關系引數,它在整個RNN網路中是共享的,這點和DNN很不相同, 也正因為是共享了,它體現了RNN的模型的“回圈反饋”的思想, [1]
三、RNN前向傳播原理
對于任何一個序列索引號t,隱藏狀態\(h{(t)}\)由\(h^{(t-1)}\)和\(x^{(t)}\)得到:
其中σ為RNN的激活函式,b為偏置值(bias)
序列索引號為t的時候模型的輸出\(o^{(t)}\)的運算式比較簡單:
此時預測輸出為:
\[\hat{y}^{(t)} = \sigma(o^{(t)}) \]在上面這一程序中使用了兩次激活函式(第一次獲得隱藏狀態\(h^{(t)}\),第二次獲得預測輸出\(\hat{y}^{(t)}\))通常在第一次使用tanh激活函式,第二次使用softmax激活函式
四、RNN反向傳播推導
RNN的法向傳播通過梯度下降一次次迭代得到合適的引數U、W、V、b、c,在RNN中U、W、V、b、c引數在序列的各個位置都是相同的,反向傳播我們更新的是同樣的引數,
對于RNN,我們在序列的每一個位置上都有損失,所以最終的損失L為:
損失函式對更新的引數進行求偏導(注意我們這里使用的兩個激活函式分別為softmax和tanh,使用的誤差計算公式為交叉熵):
- 首先考慮與損失函式直接相關的兩個變數
c和V(即預測輸出時的權值和偏置值),利用損失函式可以對這兩個變數進行直接求偏導(即對softmax函式求導):
- 而損失函式對
W、U、b的偏導數計算就比較復雜了:在反向傳播時,某一序列位置t的梯度損失由當前位置的輸出對應的梯度損失和序列索引位置t+1時的梯度損失兩部分共同決定,
從正向傳播來看:
對于W、U、b在某一序列位置t的梯度損失需要反向傳播一步步的計算,我們定義序列索引t位置的隱藏狀態的梯度為:
從\(\delta^{(\tau+1)}\)遞推\(\delta^{(t)}\)
\[\delta^{(t)} = (\frac{\partial{\delta^{(t)}}}{\partial{h^{(t)}}})^T \frac{\partial{L}}{\partial{o^{(t)}}} + (\frac{\partial{h^{(t+1)}}}{\partial{h^{(t)}}})^T \frac{\partial{L}}{\partial{h^{(t+1)}}} = V^T(\hat{y}^{(t)}-y^{(t)}) +W^Tdiag(1-(h^{(t+1)})^2)\delta^{(t+1)} \]對于\(\delta{(\tau)}\),其后面沒有其他的索引(最后一個輸入),因此:
\[\delta^{(\tau)} = (\frac{\partial{\delta^{(\tau)}}}{\partial{h^{(\tau)}}})^T \frac{\partial{L}}{\partial{o^{(\tau)}}} = V^T(\hat{y}^{(\tau)}-y^{(t)}) \]根據\(\delta{(t)}\),我們就可以計算W、U、b了:
五、RNN梯度消失問題
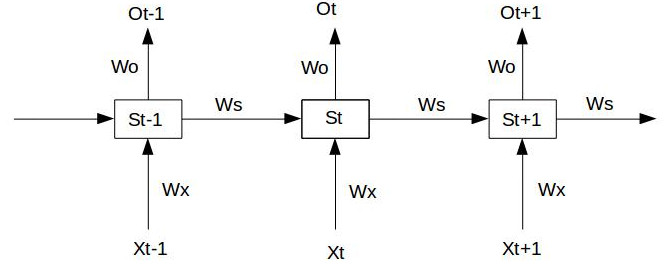
假設時間序列只有三段,\(S_0\)為給定值,神經元沒有激活函式,而RNN按照最簡單的前向傳播:
假設在t=3時刻,損失函式為$$L_3 = \frac{1}{2}(Y_3-O_3)^2$$
對于一次訓練,其損失函式值是累加的:$$L = \sum_{t = 0}{T}L_t$$
此處利用反向傳播公式僅對Wx、Ws、W0求偏導數(Wx、Ws與輸出Output相關,并非直接求損失函式Loss的偏導,在第四部分也已經說明了:
從這冗長的公式中可以看見用梯度下降法對損失函式求W0的偏導數其沒有很長的依賴(就是公式很短、求解簡單)但是對于Wx和Ws的公式就非常長了,上面僅僅推到了三層網路結構就已經如此繁雜了,推導任意時刻損失函式關于Wx和Ws的偏導數公式:
如果再加上激活函式:$$S_j = tanh(W_xX_j + W_sS_{j-1}+b_1)$$
則$$\prod_{j=k+1}^{t}\frac{\partial{S}j}{\partial{S}{j-1}} = \prod_{j=k+1}^{t}W_s tanh^{'}$$
激活函式tanh[2]:
\[f(x) = tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} \]tanh函式導數:
\[f(x)^{'} = 1 - (tanh(x))^2 \]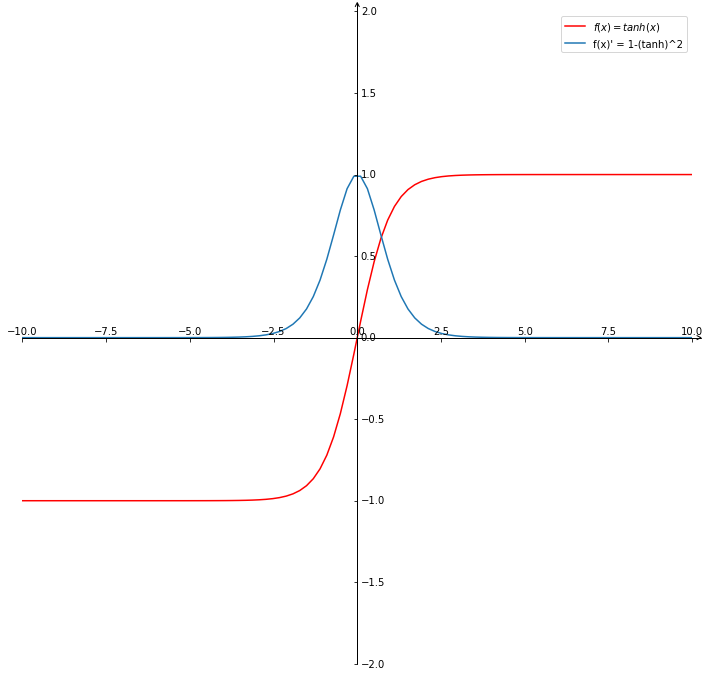
根據激活函式及其導數的影像可見 [3]
- \[tanh^{'}(x) ≤ 1 \]
- 絕大部分情況下,tanh的導數都是小于1的,很少情況出現:
- 如果
Ws是一個大于0小于1的值,當t很大的時候
- 如果
Ws是一個很大的值,當t很大的時候
六、消除梯度爆炸和梯度消失
在公式:
\[\frac{\partial{L}_t}{\partial{W}_x} = \sum_{k=0}^{t}\frac{\partial{L}_t}{\partial{O}_t}\frac{\partial{O}_t}{\partial{S}_t}(\prod_{j=k+1}^{t}\frac{\partial{S}_j}{\partial{S}_{j-1}})\frac{\partial{S}_k}{\partial{W}_x} \]\[\frac{\partial{L}_t}{\partial{W}_s} = \sum_{k=0}^{t}\frac{\partial{L}_t}{\partial{O}_t}\frac{\partial{O}_t}{\partial{S}_t}(\prod_{j=k+1}^{t}\frac{\partial{S}_j}{\partial{S}_{j-1}})\frac{\partial{S}_k}{\partial{W}_s} \]導致梯度消失和梯度爆炸的原因在于:
\[\prod_{j=k+1}^{t}\frac{\partial{S}_j}{\partial{S}_{j-1}} \]消除這個部分的影響一個考慮是使得
\[\frac{\partial{S}_j}{\partial{S}_{j-1}} ≈ 1 \]另一種是使得:
\[\frac{\partial{S}_j}{\partial{S}_{j-1}} ≈ 0 \]回圈神經網路(RNN)模型與前向反向傳播演算法 ??
Tanh激活函式及求導程序 ??
RNN梯度消失和爆炸的原因 ??
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/225574.html
標籤:其他