文章目錄
- 一. Kafka Connect簡介
- 二. 使用Kafka自帶的File連接器
- 圖例
- 配置
- 運行
- 三、 自定義連接器
- 參考
- Task
- SourceTask
- SinkTask
- Connect
一. Kafka Connect簡介
Kafka是一個使用越來越廣的訊息系統,尤其是在大資料開發中(實時資料處理和分析),為何集成其他系統和解耦應用,經常使用Producer來發送訊息到Broker,并使用Consumer來消費Broker中的訊息,Kafka Connect是到0.9版本才提供的并極大的簡化了其他系統與Kafka的集成,Kafka Connect運用用戶快速定義并實作各種Connector(File,Jdbc,Hdfs等),這些功能讓大批量資料匯入/匯出Kafka很方便,
二. 使用Kafka自帶的File連接器
圖例
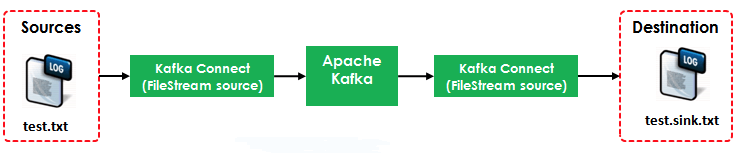
配置
本例使用到了兩個Connector:
FileStreamSource:從test.txt中讀取并發布到Broker中
FileStreamSink:從Broker中讀取資料并寫入到test.sink.txt檔案中 其中的Source使用到的組態檔是$/config/connect-file-source.properties
name=local-file-source
connector.class=FileStreamSource
tasks.max=1
file=test.txt
topic=connect-test
其中的Sink使用到的組態檔是$/config/connect-file-sink.properties
name=local-file-sink
connector.class=FileStreamSink
tasks.max=1
file=test.sink.txt
topics=connect-test
Broker使用到的組態檔是$/config/connect-standalone.properties
bootstrap.servers=localhost:9092
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=trueinternal.key.converter=org.apache.kafka.connect.json.JsonConverter
internal.value.converter=org.apache.kafka.connect.json.JsonConverter
internal.key.converter.schemas.enable=false
internal.value.converter.schemas.enable=false
offset.storage.file.filename=/tmp/connect.offsets
offset.flush.interval.ms=10000
運行
啟動Kafka Broker
先運行zookeeper
[root@localhost kafka_2.11-0.11.0.0]# ./bin/zookeeper-server-start.sh ./config/zookeeper.properties &
再運行kafka
[root@localhost kafka_2.11-0.11.0.0]# ./bin/kafka-server-start.sh ./config/server.properties &
[root@localhost kafka_2.11-0.11.0.0]# ./bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties
消費觀察輸出資料
./kafka-console-consumer.sh --bootstrap-server 192.168.137.121:9092 --topic connect-test --from-beginning
kafka根目錄添加輸入源,觀察輸出資料
[root@Server4 kafka_2.12-0.11.0.0]# echo 'firest line' >> test.txt
[root@Server4 kafka_2.12-0.11.0.0]# echo 'second line' >> test.txt
輸出資料
{"schema":{"type":"string","optional":false},"payload":"firest line"}
{"schema":{"type":"string","optional":false},"payload":"second line"}
查看test.sink.txt
[root@Server4 kafka_2.12-0.11.0.0]# cat test.sink.txt
firest line
second line
三、 自定義連接器
參考
http://kafka.apache.org/documentation/#connect
https://docs.confluent.io/current/connect/index.html
https://www.confluent.io/blog/create-dynamic-kafka-connect-source-connectors/
https://github.com/apache/kafka/tree/trunk/connect
http://www.itrensheng.com/archives/apache-kafka-kafka-connectfileconnector
https://github.com/apache/kafka/tree/trunk/connect/file/src/main/java/org/apache/kafka/connect/file
// 開發自己的connect
https://www.jdon.com/54527
https://www.cnblogs.com/laoqing/p/11927958.html
https://www.orchome.com/345
// debezium 開源實作比較好的
https://github.com/debezium/debezium
maven
<!-- https://mvnrepository.com/artifact/org.apache.kafka/connect-api -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>connect-api</artifactId>
<version>2.6.0</version>
</dependency>
Task
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.kafka.connect.connector;
import java.util.Map;
/**
* <p>
* Tasks contain the code that actually copies data to/from another system. They receive
* a configuration from their parent Connector, assigning them a fraction of a Kafka Connect job's work.
* The Kafka Connect framework then pushes/pulls data from the Task. The Task must also be able to
* respond to reconfiguration requests.
* </p>
* <p>
* Task only contains the minimal shared functionality between
* {@link org.apache.kafka.connect.source.SourceTask} and
* {@link org.apache.kafka.connect.sink.SinkTask}.
* </p>
*/
public interface Task {
/**
* Get the version of this task. Usually this should be the same as the corresponding {@link Connector} class's version.
*
* @return the version, formatted as a String
*/
String version();
/**
* Start the Task
* @param props initial configuration
*/
void start(Map<String, String> props);
/**
* Stop this task.
*/
void stop();
}
SourceTask
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.kafka.connect.source;
import org.apache.kafka.connect.connector.Task;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.List;
import java.util.Map;
/**
* SourceTask is a Task that pulls records from another system for storage in Kafka.
*/
public abstract class SourceTask implements Task {
protected SourceTaskContext context;
/**
* Initialize this SourceTask with the specified context object.
*/
public void initialize(SourceTaskContext context) {
this.context = context;
}
/**
* Start the Task. This should handle any configuration parsing and one-time setup of the task.
* @param props initial configuration
*/
@Override
public abstract void start(Map<String, String> props);
/**
* <p>
* Poll this source task for new records. If no data is currently available, this method
* should block but return control to the caller regularly (by returning {@code null}) in
* order for the task to transition to the {@code PAUSED} state if requested to do so.
* </p>
* <p>
* The task will be {@link #stop() stopped} on a separate thread, and when that happens
* this method is expected to unblock, quickly finish up any remaining processing, and
* return.
* </p>
*
* @return a list of source records
*/
public abstract List<SourceRecord> poll() throws InterruptedException;
/**
* <p>
* Commit the offsets, up to the offsets that have been returned by {@link #poll()}. This
* method should block until the commit is complete.
* </p>
* <p>
* SourceTasks are not required to implement this functionality; Kafka Connect will record offsets
* automatically. This hook is provided for systems that also need to store offsets internally
* in their own system.
* </p>
*/
public void commit() throws InterruptedException {
// This space intentionally left blank.
}
/**
* Signal this SourceTask to stop. In SourceTasks, this method only needs to signal to the task that it should stop
* trying to poll for new data and interrupt any outstanding poll() requests. It is not required that the task has
* fully stopped. Note that this method necessarily may be invoked from a different thread than {@link #poll()} and
* {@link #commit()}.
*
* For example, if a task uses a {@link java.nio.channels.Selector} to receive data over the network, this method
* could set a flag that will force {@link #poll()} to exit immediately and invoke
* {@link java.nio.channels.Selector#wakeup() wakeup()} to interrupt any ongoing requests.
*/
@Override
public abstract void stop();
/**
* <p>
* Commit an individual {@link SourceRecord} when the callback from the producer client is received. This method is
* also called when a record is filtered by a transformation, and thus will never be ACK'd by a broker.
* </p>
* <p>
* This is an alias for {@link #commitRecord(SourceRecord, RecordMetadata)} for backwards compatibility. The default
* implementation of {@link #commitRecord(SourceRecord, RecordMetadata)} just calls this method. It is not necessary
* to override both methods.
* </p>
* <p>
* SourceTasks are not required to implement this functionality; Kafka Connect will record offsets
* automatically. This hook is provided for systems that also need to store offsets internally
* in their own system.
* </p>
*
* @param record {@link SourceRecord} that was successfully sent via the producer or filtered by a transformation
* @throws InterruptedException
* @deprecated Use {@link #commitRecord(SourceRecord, RecordMetadata)} instead.
*/
@Deprecated
public void commitRecord(SourceRecord record) throws InterruptedException {
// This space intentionally left blank.
}
/**
* <p>
* Commit an individual {@link SourceRecord} when the callback from the producer client is received. This method is
* also called when a record is filtered by a transformation, and thus will never be ACK'd by a broker. In this case
* {@code metadata} will be null.
* </p>
* <p>
* SourceTasks are not required to implement this functionality; Kafka Connect will record offsets
* automatically. This hook is provided for systems that also need to store offsets internally
* in their own system.
* </p>
* <p>
* The default implementation just calls {@link #commitRecord(SourceRecord)}, which is a nop by default. It is
* not necessary to implement both methods.
* </p>
*
* @param record {@link SourceRecord} that was successfully sent via the producer or filtered by a transformation
* @param metadata {@link RecordMetadata} record metadata returned from the broker, or null if the record was filtered
* @throws InterruptedException
*/
public void commitRecord(SourceRecord record, RecordMetadata metadata)
throws InterruptedException {
// by default, just call other method for backwards compatibility
commitRecord(record);
}
}
SinkTask
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.kafka.connect.sink;
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.connect.connector.Task;
import java.util.Collection;
import java.util.Map;
/**
* SinkTask is a Task that takes records loaded from Kafka and sends them to another system. Each task
* instance is assigned a set of partitions by the Connect framework and will handle all records received
* from those partitions. As records are fetched from Kafka, they will be passed to the sink task using the
* {@link #put(Collection)} API, which should either write them to the downstream system or batch them for
* later writing. Periodically, Connect will call {@link #flush(Map)} to ensure that batched records are
* actually pushed to the downstream system..
*
* Below we describe the lifecycle of a SinkTask.
*
* <ol>
* <li><b>Initialization:</b> SinkTasks are first initialized using {@link #initialize(SinkTaskContext)}
* to prepare the task's context and {@link #start(Map)} to accept configuration and start any services
* needed for processing.</li>
* <li><b>Partition Assignment:</b> After initialization, Connect will assign the task a set of partitions
* using {@link #open(Collection)}. These partitions are owned exclusively by this task until they
* have been closed with {@link #close(Collection)}.</li>
* <li><b>Record Processing:</b> Once partitions have been opened for writing, Connect will begin forwarding
* records from Kafka using the {@link #put(Collection)} API. Periodically, Connect will ask the task
* to flush records using {@link #flush(Map)} as described above.</li>
* <li><b>Partition Rebalancing:</b> Occasionally, Connect will need to change the assignment of this task.
* When this happens, the currently assigned partitions will be closed with {@link #close(Collection)} and
* the new assignment will be opened using {@link #open(Collection)}.</li>
* <li><b>Shutdown:</b> When the task needs to be shutdown, Connect will close active partitions (if there
* are any) and stop the task using {@link #stop()}</li>
* </ol>
*
*/
public abstract class SinkTask implements Task {
/**
* <p>
* The configuration key that provides the list of topics that are inputs for this
* SinkTask.
* </p>
*/
public static final String TOPICS_CONFIG = "topics";
/**
* <p>
* The configuration key that provides a regex specifying which topics to include as inputs
* for this SinkTask.
* </p>
*/
public static final String TOPICS_REGEX_CONFIG = "topics.regex";
protected SinkTaskContext context;
/**
* Initialize the context of this task. Note that the partition assignment will be empty until
* Connect has opened the partitions for writing with {@link #open(Collection)}.
* @param context The sink task's context
*/
public void initialize(SinkTaskContext context) {
this.context = context;
}
/**
* Start the Task. This should handle any configuration parsing and one-time setup of the task.
* @param props initial configuration
*/
@Override
public abstract void start(Map<String, String> props);
/**
* Put the records in the sink. Usually this should send the records to the sink asynchronously
* and immediately return.
*
* If this operation fails, the SinkTask may throw a {@link org.apache.kafka.connect.errors.RetriableException} to
* indicate that the framework should attempt to retry the same call again. Other exceptions will cause the task to
* be stopped immediately. {@link SinkTaskContext#timeout(long)} can be used to set the maximum time before the
* batch will be retried.
*
* @param records the set of records to send
*/
public abstract void put(Collection<SinkRecord> records);
/**
* Flush all records that have been {@link #put(Collection)} for the specified topic-partitions.
*
* @param currentOffsets the current offset state as of the last call to {@link #put(Collection)}},
* provided for convenience but could also be determined by tracking all offsets included in the {@link SinkRecord}s
* passed to {@link #put}.
*/
public void flush(Map<TopicPartition, OffsetAndMetadata> currentOffsets) {
}
/**
* Pre-commit hook invoked prior to an offset commit.
*
* The default implementation simply invokes {@link #flush(Map)} and is thus able to assume all {@code currentOffsets} are safe to commit.
*
* @param currentOffsets the current offset state as of the last call to {@link #put(Collection)}},
* provided for convenience but could also be determined by tracking all offsets included in the {@link SinkRecord}s
* passed to {@link #put}.
*
* @return an empty map if Connect-managed offset commit is not desired, otherwise a map of offsets by topic-partition that are safe to commit.
*/
public Map<TopicPartition, OffsetAndMetadata> preCommit(Map<TopicPartition, OffsetAndMetadata> currentOffsets) {
flush(currentOffsets);
return currentOffsets;
}
/**
* The SinkTask use this method to create writers for newly assigned partitions in case of partition
* rebalance. This method will be called after partition re-assignment completes and before the SinkTask starts
* fetching data. Note that any errors raised from this method will cause the task to stop.
* @param partitions The list of partitions that are now assigned to the task (may include
* partitions previously assigned to the task)
*/
public void open(Collection<TopicPartition> partitions) {
this.onPartitionsAssigned(partitions);
}
/**
* @deprecated Use {@link #open(Collection)} for partition initialization.
*/
@Deprecated
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
}
/**
* The SinkTask use this method to close writers for partitions that are no
* longer assigned to the SinkTask. This method will be called before a rebalance operation starts
* and after the SinkTask stops fetching data. After being closed, Connect will not write
* any records to the task until a new set of partitions has been opened. Note that any errors raised
* from this method will cause the task to stop.
* @param partitions The list of partitions that should be closed
*/
public void close(Collection<TopicPartition> partitions) {
this.onPartitionsRevoked(partitions);
}
/**
* @deprecated Use {@link #close(Collection)} instead for partition cleanup.
*/
@Deprecated
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
}
/**
* Perform any cleanup to stop this task. In SinkTasks, this method is invoked only once outstanding calls to other
* methods have completed (e.g., {@link #put(Collection)} has returned) and a final {@link #flush(Map)} and offset
* commit has completed. Implementations of this method should only need to perform final cleanup operations, such
* as closing network connections to the sink system.
*/
@Override
public abstract void stop();
}
Connect
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.kafka.connect.connector;
import org.apache.kafka.common.config.Config;
import org.apache.kafka.common.config.ConfigDef;
import org.apache.kafka.common.config.ConfigValue;
import org.apache.kafka.connect.errors.ConnectException;
import org.apache.kafka.connect.components.Versioned;
import java.util.List;
import java.util.Map;
/**
* <p>
* Connectors manage integration of Kafka Connect with another system, either as an input that ingests
* data into Kafka or an output that passes data to an external system. Implementations should
* not use this class directly; they should inherit from {@link org.apache.kafka.connect.source.SourceConnector SourceConnector}
* or {@link org.apache.kafka.connect.sink.SinkConnector SinkConnector}.
* </p>
* <p>
* Connectors have two primary tasks. First, given some configuration, they are responsible for
* creating configurations for a set of {@link Task}s that split up the data processing. For
* example, a database Connector might create Tasks by dividing the set of tables evenly among
* tasks. Second, they are responsible for monitoring inputs for changes that require
* reconfiguration and notifying the Kafka Connect runtime via the {@link ConnectorContext}. Continuing the
* previous example, the connector might periodically check for new tables and notify Kafka Connect of
* additions and deletions. Kafka Connect will then request new configurations and update the running
* Tasks.
* </p>
*/
public abstract class Connector implements Versioned {
protected ConnectorContext context;
/**
* Initialize this connector, using the provided ConnectorContext to notify the runtime of
* input configuration changes.
* @param ctx context object used to interact with the Kafka Connect runtime
*/
public void initialize(ConnectorContext ctx) {
context = ctx;
}
/**
* <p>
* Initialize this connector, using the provided ConnectorContext to notify the runtime of
* input configuration changes and using the provided set of Task configurations.
* This version is only used to recover from failures.
* </p>
* <p>
* The default implementation ignores the provided Task configurations. During recovery, Kafka Connect will request
* an updated set of configurations and update the running Tasks appropriately. However, Connectors should
* implement special handling of this case if it will avoid unnecessary changes to running Tasks.
* </p>
*
* @param ctx context object used to interact with the Kafka Connect runtime
* @param taskConfigs existing task configurations, which may be used when generating new task configs to avoid
* churn in partition to task assignments
*/
public void initialize(ConnectorContext ctx, List<Map<String, String>> taskConfigs) {
context = ctx;
// Ignore taskConfigs. May result in more churn of tasks during recovery if updated configs
// are very different, but reduces the difficulty of implementing a Connector
}
/**
* Returns the context object used to interact with the Kafka Connect runtime.
*
* @return the context for this Connector.
*/
protected ConnectorContext context() {
return context;
}
/**
* Start this Connector. This method will only be called on a clean Connector, i.e. it has
* either just been instantiated and initialized or {@link #stop()} has been invoked.
*
* @param props configuration settings
*/
public abstract void start(Map<String, String> props);
/**
* Reconfigure this Connector. Most implementations will not override this, using the default
* implementation that calls {@link #stop()} followed by {@link #start(Map)}.
* Implementations only need to override this if they want to handle this process more
* efficiently, e.g. without shutting down network connections to the external system.
*
* @param props new configuration settings
*/
public void reconfigure(Map<String, String> props) {
stop();
start(props);
}
/**
* Returns the Task implementation for this Connector.
*/
public abstract Class<? extends Task> taskClass();
/**
* Returns a set of configurations for Tasks based on the current configuration,
* producing at most count configurations.
*
* @param maxTasks maximum number of configurations to generate
* @return configurations for Tasks
*/
public abstract List<Map<String, String>> taskConfigs(int maxTasks);
/**
* Stop this connector.
*/
public abstract void stop();
/**
* Validate the connector configuration values against configuration definitions.
* @param connectorConfigs the provided configuration values
* @return List of Config, each Config contains the updated configuration information given
* the current configuration values.
*/
public Config validate(Map<String, String> connectorConfigs) {
ConfigDef configDef = config();
if (null == configDef) {
throw new ConnectException(
String.format("%s.config() must return a ConfigDef that is not null.", this.getClass().getName())
);
}
List<ConfigValue> configValues = configDef.validate(connectorConfigs);
return new Config(configValues);
}
/**
* Define the configuration for the connector.
* @return The ConfigDef for this connector; may not be null.
*/
public abstract ConfigDef config();
}
瑞 新
 CSDN認證博客專家
分布式
Java
架構
CSDN認證博客專家
分布式
Java
架構
CSDN認證博客專家
分布式
Java
架構
求職中 ? Java全堆疊養成計劃公眾號 ? 讓我遇見相似的靈魂回復領取:競賽 書籍 專案 面試左手代碼,右手吉他,這就是天下:如果有一天我遇見相似的靈魂 那它肯定是步履艱難 不被理解 喜黑怕光的,如果可以的話 讓我觸摸一下吧 它也一樣孤獨得太久, 不一樣的文藝青年,不一樣的程式猿,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/225826.html
標籤:其他