文章目錄
- 前言
- 一、差分隱私
- 二、問題提出
- 1.什么是隱私?
- 2.什么是差分?
- 3.定義
- 4.如何做到差分隱私?
- 5.差分隱私的性能評估
- 總結
前言
兩年前初識差分隱私,有寫相關理解參考博文:差分隱私 走過的坑
- 近來有好多新同學在學習并咨詢差分隱私相關理論;
- 至此本文補充相關點細節,以填坑,
- 個人理解,差分隱私理論研究或許大概可能較完善,目前要想在此方向前進,研究它的應用點是比較好的 field ,比如:
- 機器學習 - 深度學習- 推薦系統 - 社交網路- 資訊物理系統-
- and the like,哪里需要保護隱私就往哪里用,
一、差分隱私
針對統計資料庫的隱私泄露問題提出的新的隱私定義,
二、問題提出
現有
匿名模型的局限性:
- 特殊的攻擊假設;
- 一定的背景知識;
- 無法對隱私保護強度進行量化分析,
差分隱私優點:
- 無需攻擊假設;
- 不關心攻擊者所擁有的背景知識;
- 定量化分析來表示隱私泄露風險大小,
挑戰:
如何在滿足差分隱私的前提下提高發布統計資料或演算法模型的可用性和演算法效率,
1.什么是隱私?
“單個用戶的某一些屬性”
記得高德地圖發過一張圖,大意是開凱迪拉克的群體喜歡去洗浴中心…很多人說暴露隱私,
其實從學術定義上來說,這個不算隱私泄露,因為沒有牽涉到任何個體,
因此: 從隱私保護的角度來說,隱私的主體是單個用戶,只有牽涉到某個特定用戶的才叫隱私泄露,發布群體用戶的資訊(聚集資訊)不算泄露隱私,
2.什么是差分?
舉例:醫院發布了一系列資訊,說這個月有100個病人,其中10個患HIV,假如,攻擊者知道其中99個人的資訊(即擁有最大背景知識),那么他只需把99人資訊和醫院發布的100人資訊對比,即可知道第100個人是否患HIV,
這種對個人隱私的攻擊行為就是差分攻擊,也即差異化攻擊,
換句話說,攻擊者將自己擁有的背景知識 和 資料發布者發布的聚集資料 進行對比,找之間的差異資訊,從中獲取個體隱私資訊,
差分隱私,即防止差分攻擊,即使攻擊者擁有最大背景知識,即知道發布的100個人中的99個人的資訊,也無法通過查詢獲取第100個人的資訊,
怎么做到的?
加入隨機性,使得查詢100個人記錄和查詢99個人記錄,輸出同樣值的概率接近,
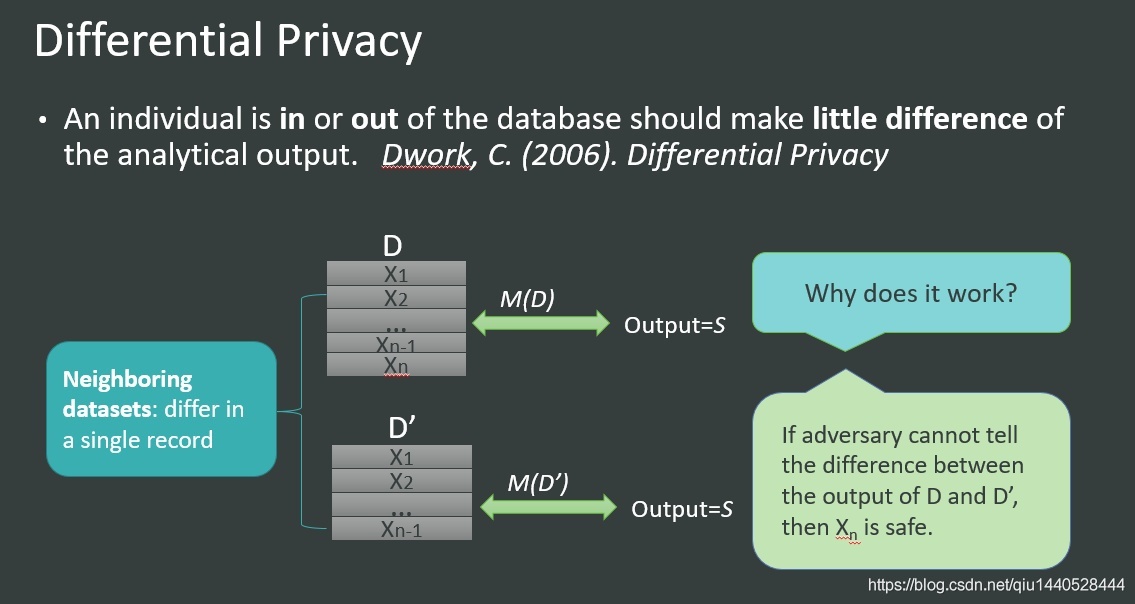
3.定義

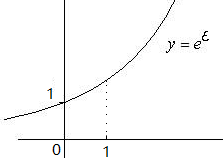
分析:對于指數函式
e
?
e^{\epsilon}
e?,一般取值為ε∈(0,1)
當ε→0時,e^ε→1,則Pr[·] \ Pr[·] ≈1,即兩個查詢結果概率相近;
因此:
ε→0 時,隱私性越高;
ε→∞ 時,越沒隱私,但查詢結果更精確,
通俗的講,該機制保證了一個資料集的每個個體不被泄露,但資料集的統計學資訊(如均值、方差)可被外界了解,
因此,一個醫療機構要公布患者疾病資料給外界以供研究,就可以先對該資料集做一個滿足DP的擾動,再公布出去,
4.如何做到差分隱私?
其實,就是在查詢結果里面加入隨機性,
任何一種方法,只要用在資料集上能滿足差分隱私的核心思想,那么這個方法就是滿足差分隱私的,所以最常用的方法是在結果上加滿足某種分布的噪聲,使結果隨機化,
Laplace機制
差分隱私資料發布在互動式模式下,通過向真實值添加滿足Laplace分布的噪聲來實作差分隱私保護,
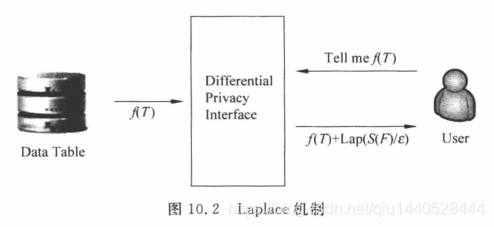
Laplace機制中通常向查詢請求結果
f
(
T
)
f(T)
f(T) 中添加噪聲
η
\eta
η,得到
f
(
T
)
+
η
f(T) +\eta
f(T)+η,其中
η
\eta
η是一個滿足Laplace分布的連續隨機變數,Laplace分布如下圖:
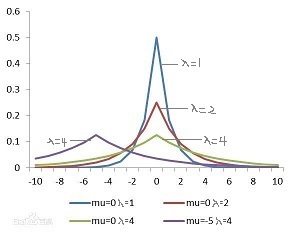
其概率密度函式為:
P ( η ) = 1 2 λ e ? η λ P(\eta) = \dfrac{1}{2\lambda}e^{-\dfrac{\eta}{\lambda}} P(η)=2λ1?e?λη?
其中,Laplace分布的期望值 μ \mu μ=0,方差為 2 λ 2 2\lambda^{2} 2λ2,
分析:
引數μ \mu μ,在Laplace分布圖中表示:位置引數
但實際意義是固定生成的Laplace分布噪聲的期望值,使保護的資料集的期望盡可能不變,保證了添加噪聲的穩定性,不至于破壞資料的可用性,
引數λ \lambda λ,在Laplace分布圖中表示:尺度引數、幅度大小,即噪聲樣本的集中程度
λ
\lambda
λ↑,
→
\rightarrow
→幅度越大
→
\rightarrow
→噪聲越分散
→
\rightarrow
→擾動越大
→
\rightarrow
→隱私越好;
λ
\lambda
λ↓,
→
\rightarrow
→幅度越小
→
\rightarrow
→噪聲越集中
→
\rightarrow
→隱私越差,
-
此外,若尺度引數λ \lambda λ取值為Δ f ? \dfrac{\Delta f}{\epsilon} ?Δf?,即 λ = Δ f ? \lambda=\dfrac{\Delta f}{\epsilon} λ=?Δf?時,則 L a p ( Δ f ? ) Lap(\dfrac{\Delta f}{\epsilon}) Lap(?Δf?)中,噪聲的大小由 Δ f \Delta f Δf和 ? \epsilon ?共同決定,要降低噪聲量則: -
Δ f \Delta f Δf,敏感度與查詢函式有關,那么盡量讓敏感度最小;
-
? \epsilon ?,隱私預算一般取值為(0,1),那么盡量讓隱私預算分配越多;
-
或者,兩者同時都考慮, Δ f \Delta f Δf↓ and ? \epsilon ?↑,
定義:Laplace機制敏感度,給定一個函式集 F F F,若 f ( D ) ∈ R f(D)\in R f(D)∈R,則 F F F的敏感度定義為: Δ f = m a x D 1 , D 2 , ( ∑ f ∈ F ∣ f ( D 1 ) ? f ( D 2 ) ∣ ) \Delta f=max_{D_1,D_2},(\sum_{f\in F}|f(D_1)-f(D_2)|) Δf=maxD1?,D2??,(f∈F∑?∣f(D1?)?f(D2?)∣)
敏感度:對相鄰資料集同一查詢結果的最大變化程度(最大差值);
注意:敏感度只與查詢函式有關,許多型別的查詢下,Laplace敏感度值很小,
指數機制:
Laplace局限于輸出是實數,方可加噪,
指數機制采用滿足特定分布的隨機抽樣來實作差分隱私,取代了添加噪聲的方法,
原理:
定義一個實用性估價函式 q q q,對每一種輸出方案計算出一個實用性分值,分值高的輸出方案具有更大的概率被發布,從而保證發布資料的質量,估價函式 q q q選擇必須擁有盡可能低的敏感度,
定義:給定一估價函式 q q q,輸出為一物體物件 r r r,若查詢函式 F ( D , q ) F(D,q) F(D,q)滿足以下等式,則F滿足 ? \epsilon ?-差分隱私,
F ( D , q ) = { r : P r [ r ∈ O ] } ∈ e x p ( ? q ( D , q ) 2 Δ q ) F(D,q)=\{r:Pr[r\in O]\}\in exp({\dfrac{\epsilon q(D,q)}{2\Delta q}}) F(D,q)={r:Pr[r∈O]}∈exp(2Δq?q(D,q)?)
即函式 F ( D , q ) F(D,q) F(D,q)選擇并輸出 r r r的概率與 e x p ( ? q ( D , q ) 2 Δ q ) exp({\dfrac{\epsilon q(D,q)}{2\Delta q}}) exp(2Δq?q(D,q)?)成正比即可,
定義:指數機制敏感度,給定一實用性估價函式 q q q,則 q q q敏感度為:
Δ q = m a x D 1 , D 2 , r ∣ ∣ q ( D 1 , r ) ? q ( D 2 , r ) ∣ ∣ \Delta q=max_{D_1,D_2,r}||q(D_1,r)-q(D_2,r)|| Δq=maxD1?,D2?,r?∣∣q(D1?,r)?q(D2?,r)∣∣
即,對相鄰資料集同一輸出物件的估值的最大變化程度,即物件的實用性估值的最大差值,
5.差分隱私的性能評估
- 隱私保護強度: ? \epsilon ?用來衡量隱私保護強度,取值為 ? ∈ ( 0 , 1 ) \epsilon \in(0,1) ?∈(0,1),此外 ? \epsilon ?的分配方案對演算法誤差影響交大,
- 演算法誤差:常用誤差度量方法有相對誤差、絕對誤差、誤差的方差,
- 演算法性能:一般采用時間復雜度對演算法性能進行度量,
總結
個人理解難說準確與深刻不足或有誤之處務必提出一起探討修正,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/226139.html
標籤:AI
上一篇:Java實作HHO演算法
下一篇:邏輯回歸詳細推導(保證能看懂)