LOL英雄圖片爬取
- 附上url
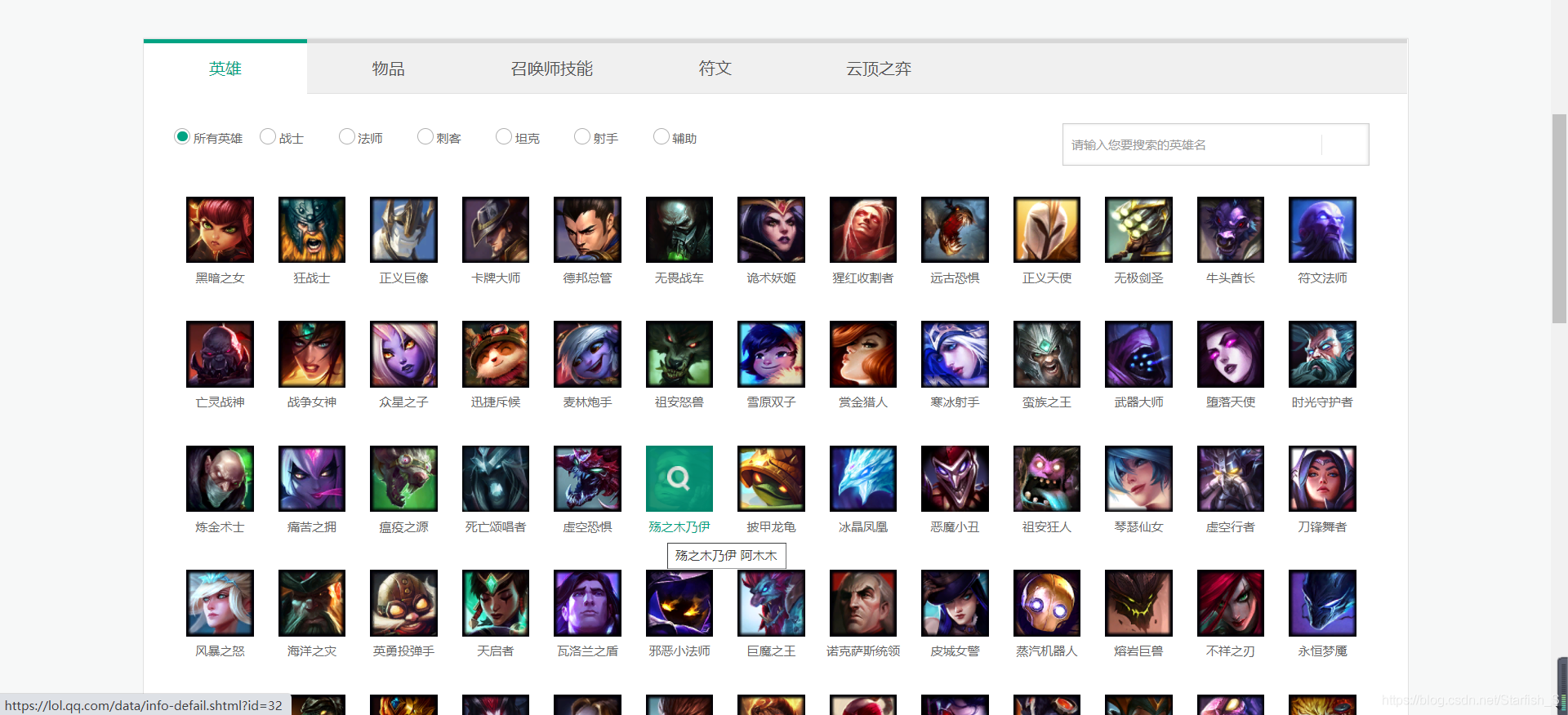
這是我們要爬取的主頁面
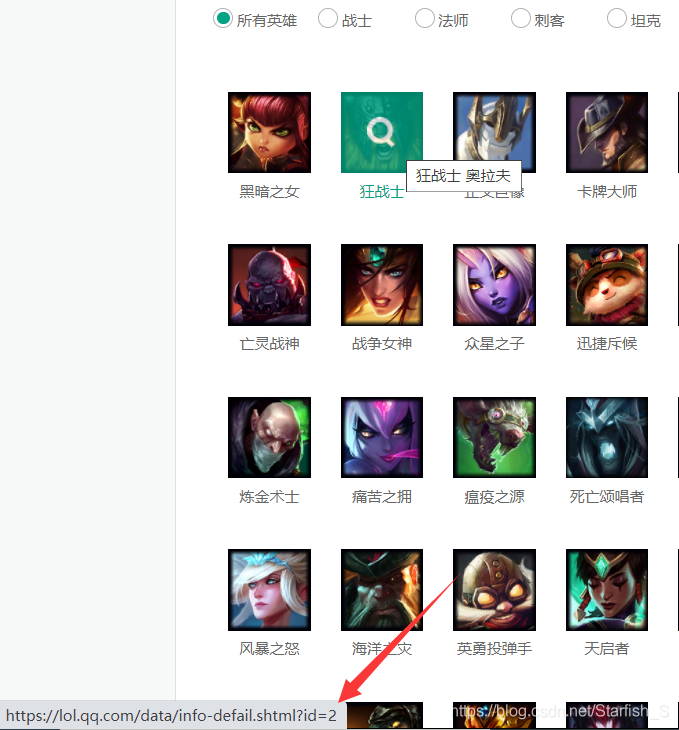
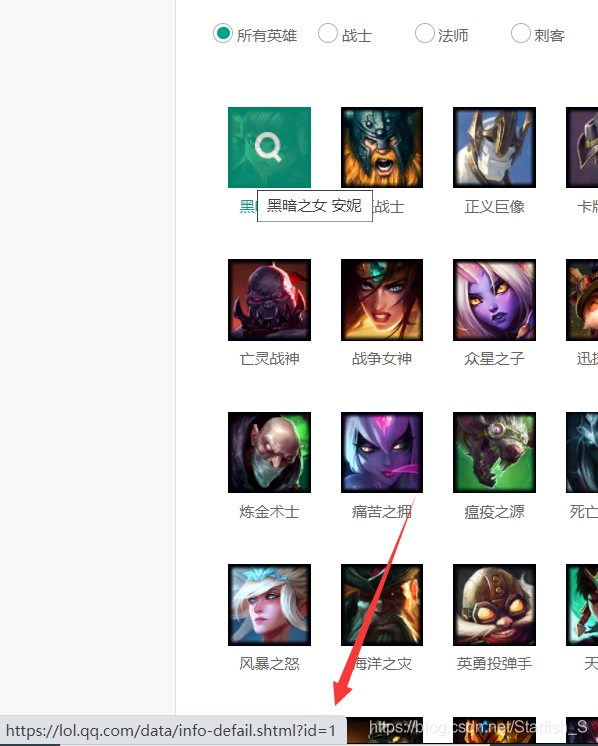
通過上兩個圖可以看出,注意標注出的url, 這是每個英雄的詳情頁面的url地址,而每個英雄的頁面的url不同的地方為id(這個id很重要),所以可以判斷每個英雄都對應著一個自己的id,
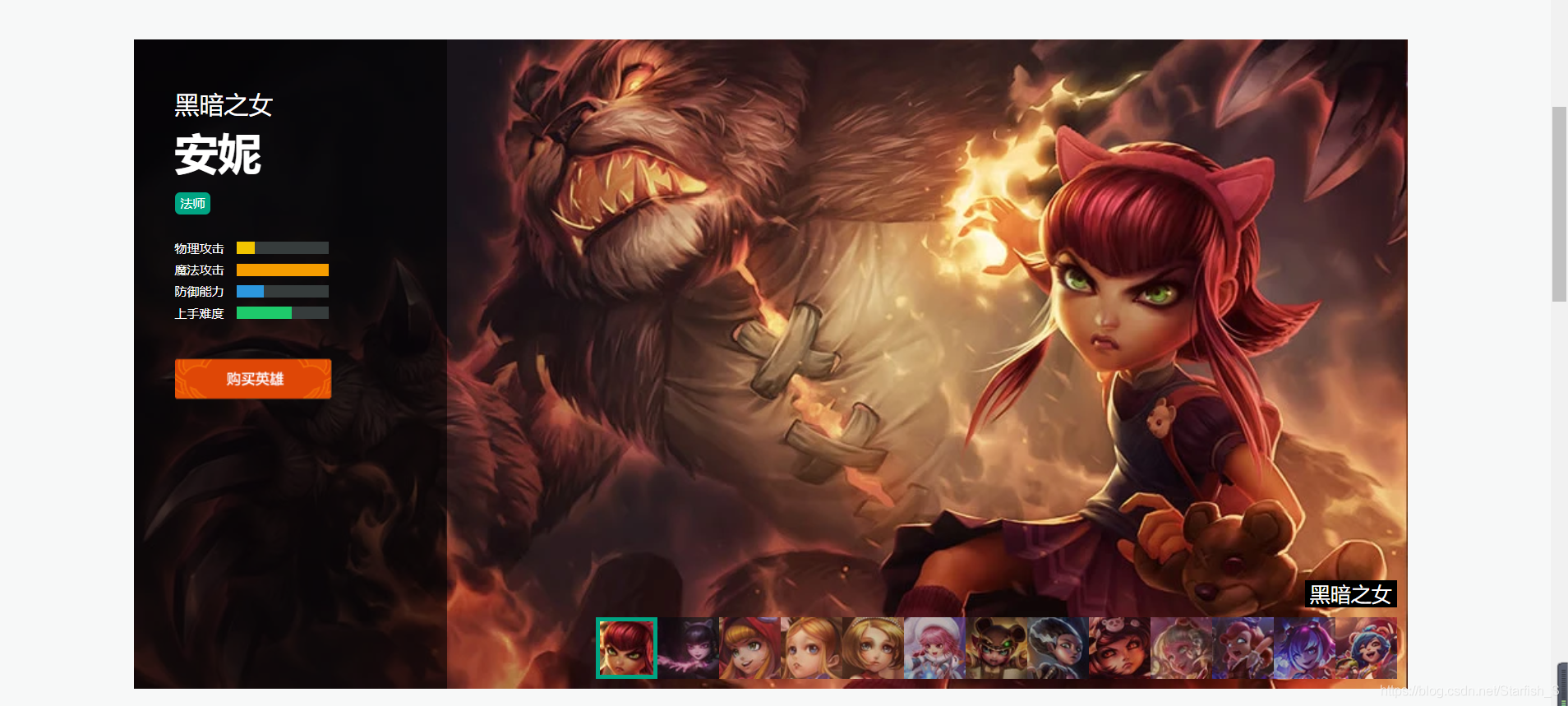
而在每個英雄單獨的頁面中有每個皮膚的大圖,
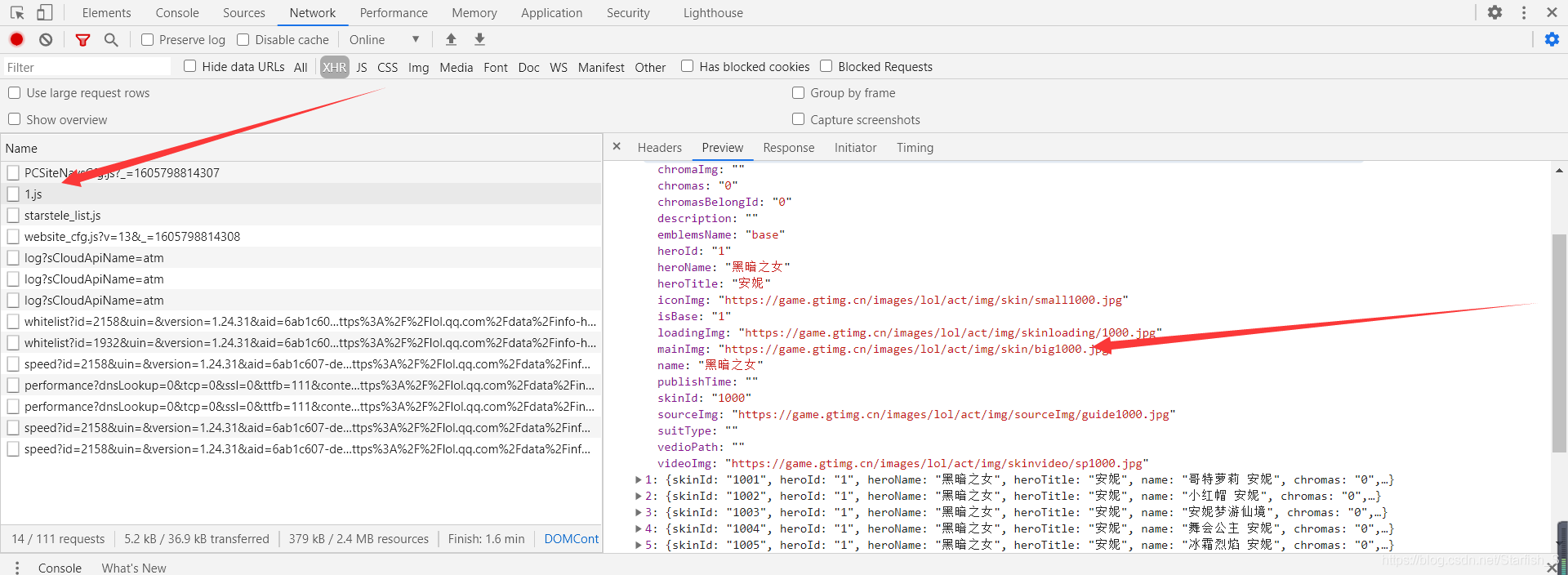
在1.js這個檔案中,我們看到了每個皮膚圖片的對應的url, 多觀察幾個頁面,你會發現每個英雄的皮膚圖片url所在的位置都在id.js中
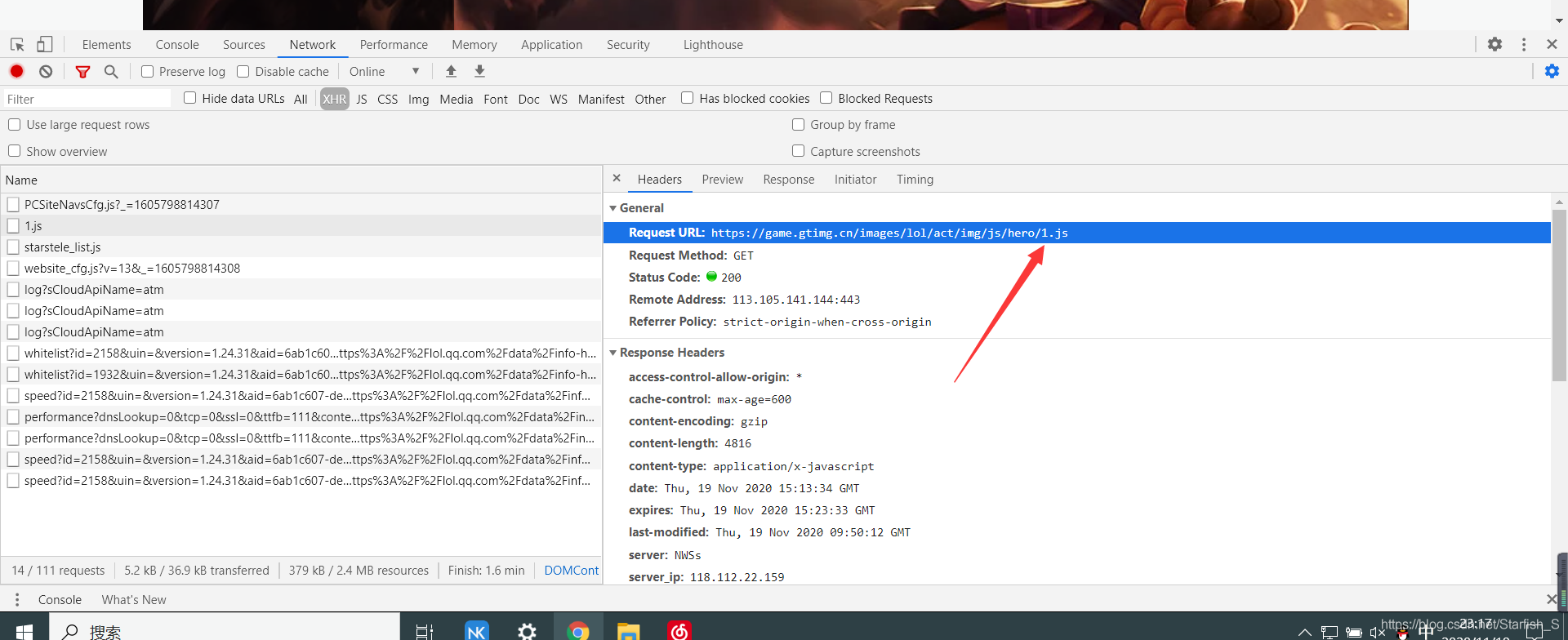
通過上圖,可以看到 - url = ‘https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js’
- 我們在{}中添加英雄的id即可
- OK,現在大概思路已經得到了,
- 首先獲取到每個英雄對應的id
- 然后拼接url
- 對拼接后的url發送請求,得到json檔案,然后取出圖片url,下載每個皮膚的圖片即可
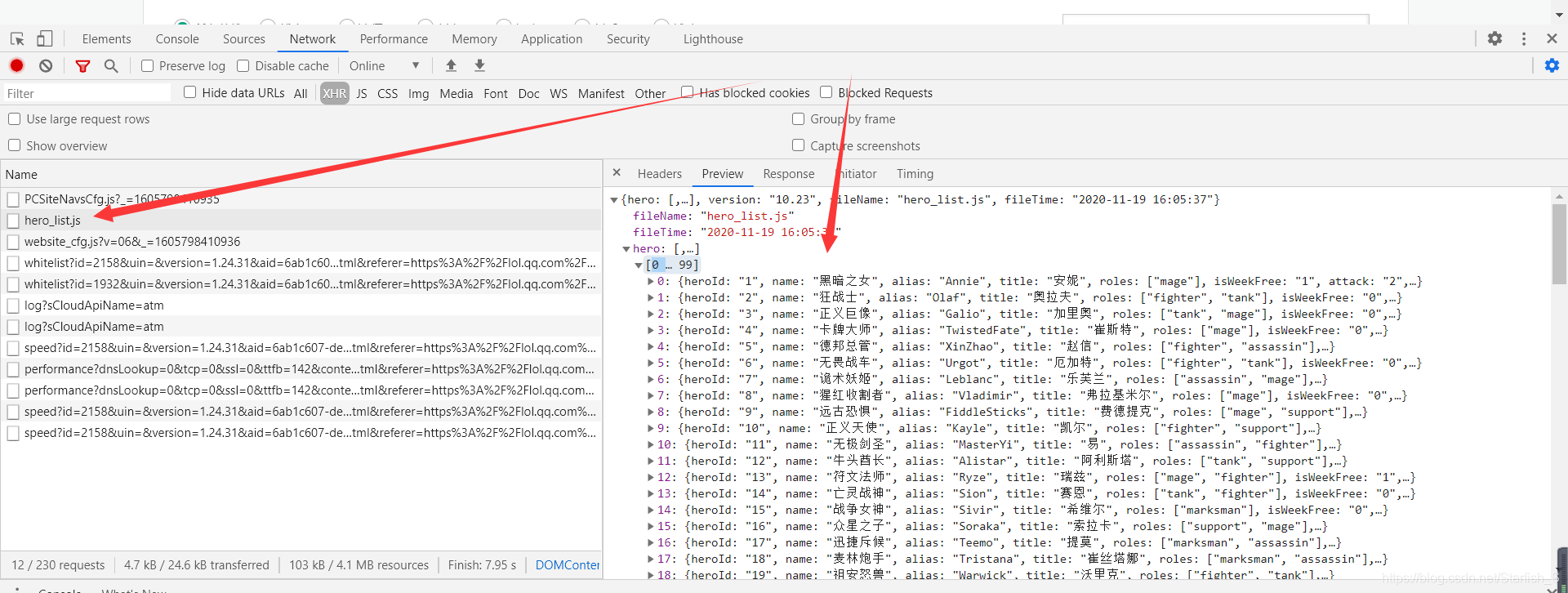
- 然后在主頁面中通過開發者工具我們挨個的尋找發現我們要找的英雄id在hero_list.js這個檔案中
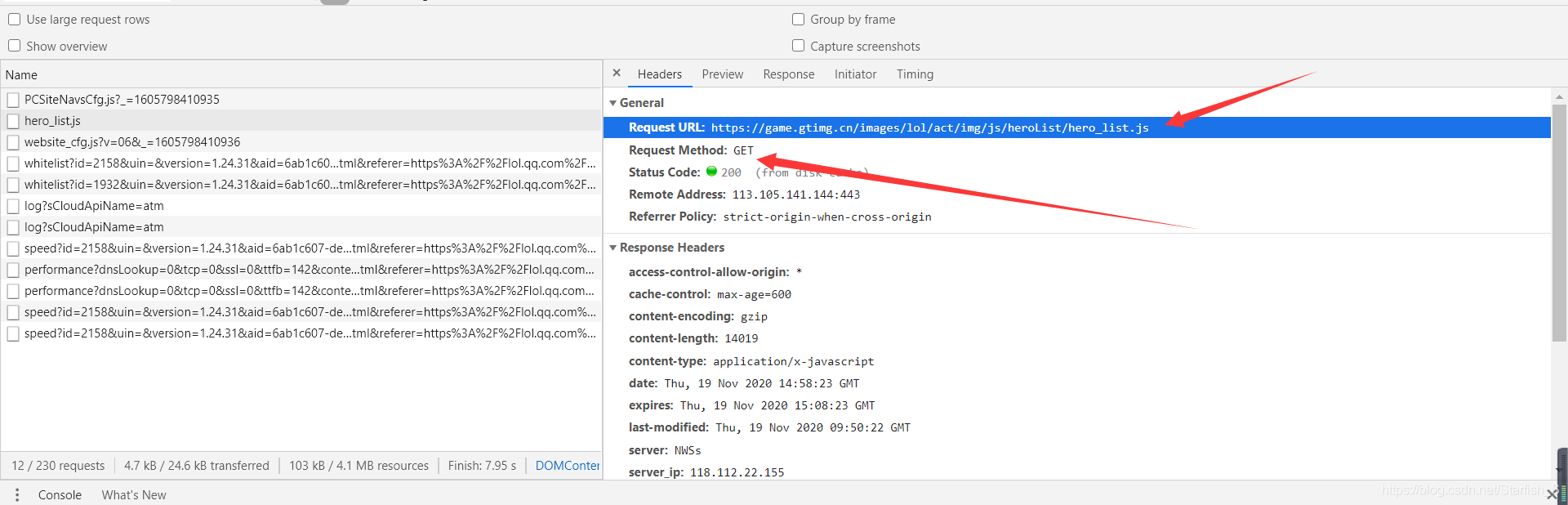
- 一個簡單的get請求即可,那么我們現在就已經獲取到了英雄id了,那么獲取到英雄id后就可以進行下一步,拼接url,得到每個英雄對應的json檔案,然后通過回傳的json檔案中得到圖片的url即可下載,大致思路就是這樣,
- 貼上代碼
import requests
from urllib.request import urlretrieve
from fake_useragent import UserAgent
import json
import os
ua = UserAgent()
headers = {
'user - agent': ua.random
}
def get_id():
url1 = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js'
hero_id_list = requests.get(url1, headers=headers).text
hero_json = json.loads(hero_id_list)['hero']
hero = {}
for h in hero_json:
hero[h['heroId']] = h['name'] + '_' + h['title']
return hero
def get_img_url(url):
res = requests.get(url, headers=headers).text
img_json = json.loads(res)['skins']
img = {}
for i in img_json:
name = i['name'].replace(' ', '_')
img[name] = i['mainImg']
return img
def dowmload_img(url, hero_name, skin_name):
path = 'img//' + hero_name
if not os.path.exists(path):
os.makedirs(path)
try:
urlretrieve(url, path + '//' + skin_name + '.jpg')
except:
pass
print('已下載' + hero_name + skin_name)
if __name__ == '__main__':
hero = get_id()
url2 = 'https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js'
for h in hero:
jsurl = url2.format(h)
hero_name = hero[h]
img_list = get_img_url(jsurl)
for i in img_list:
img_url = img_list[i]
skin_name = i
dowmload_img(img_url, hero_name, skin_name)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/226153.html
標籤:其他