k-均值聚類演算法
- 一.聚類分析概述
- 1.簇的定義
- 2.常用的聚類演算法
- 二.K-均值聚類演算法
- 1.k-均值演算法的python實作
- 1.1 匯入資料集
- 1.2 構建距離計算函式
- 1.3 撰寫自動生成rand質心的函式
- 1.4 K-means聚類函式的實作
一.聚類分析概述
聚類分析是無監督類機器學習演算法中常用的一類,其目的是將資料劃分成有意義或有用的組(也被稱為簇),組
內的物件相互之間是相似的(相關的),而不同組中的物件是不同的(不相關的),組內的相似性 (同質性)越 大,組間差別越大,聚類就越好,
1.簇的定義
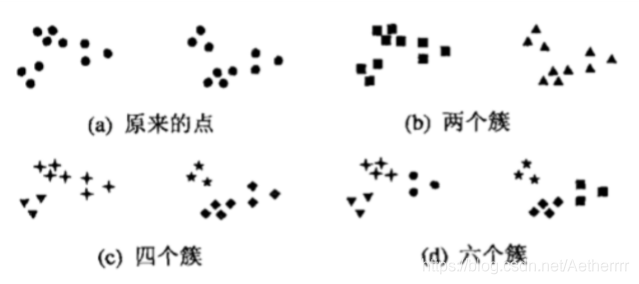
簇就是分類結果中的類,其沒有確切的定義,也沒有客觀的標準,我們可以利用這個我網上找來的圖來理解一下什么是簇:
該圖中顯示了20個點的三種不同的分法,不同的類別用不同的形狀表示,圖a表示還未分類的原始圖,b,c,d三圖分別表示分為兩部分,四部分,六部分的不同分法,其中我們將簇分為兩類可能是最普遍的表示方法,但是分為四個簇仔細一想好像并不是不無道理,而六個簇的分類中,將兩個較大的簇均分為三個小簇可能是人視覺系統造成的假象,這也進一步說明了簇的定義其實是不準確的,而我們如何在問題中更好的定義簇,這依賴于該資料的特性和期望的結果,
2.常用的聚類演算法
常用的聚類演算法有以下三種:
?K-means聚類:也稱為K均值聚類,它試圖發現k(用戶指定個數)個不同的簇 ,并且每個簇的中心采用簇中所含 值的均值計算而成,
?層次聚類:層次聚類(hierarchical clustering)試圖在不同層次對資料集進行劃分,從而形成樹形的聚類結構,
?DBSCAN:這是一種基于密度的聚類演算法,簇的個數由演算法自動地確定,低密度區域中的點被視為噪聲而忽略, 因此DBSCAN不產生完全聚類,
(挖個坑,后續的總結中也會總結這幾個演算法)
二.K-均值聚類演算法
簡要的概述k-均值演算法:我們通過給定的資料集,將其分為K個簇,簇的個數K是用戶給定的,給一個簇通過其質心(centroid)來描述,
大概的流程:1.隨機選取K個質心(大資料數學基礎老師曾講過這個更高級的演算法中會有更具體的初始化質心,現在還并未了解到),k為用戶所指定,
2.將資料中每一個點和這K個質心算距離,并將其歸為最近的質心點,歸為同一個質心點的資料點為一個簇
3.根據歸屬的k個類的資料點,計算該簇的平均值作為新的質心點,并反復2,3操作直至簇不再發生變化或質心不再發生變化為止,
1.k-均值演算法的python實作
偽代碼:
創建k個點作為初始質心(通常是隨機選擇)
當任意一個點的簇分配結果發生改變時:
對資料集中的每個點:
對每個質心:
計算質心與資料點之間的距離
將資料點分配到據其近的簇
對每個簇,計算簇中所有點的均值并將均值作為新的質心
直到簇不再發生變化或者達到大迭代次數
對于距離的計算,我們使用最簡單的歐氏距離,
1.1 匯入資料集
在這里我使用的是之前老師給的鳶尾花資料集(常用的那種,然后把第一行標簽刪掉,蒟蒻不會處理第一行標簽)
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
iris = pd.read_csv('iris.csv', header=None)
(簡單的讀入)
1.2 構建距離計算函式
我們需要定義一個兩個長度相同的陣列,基于此我們來實作歐氏距離的計算函式,而不是直接應用計算距離計算結果,只比距離遠近的情況下,我們可以免去開平方運算以減少運算量,加快運算速度,
這里要注意量綱(單位)的統一!因為這里用的是鳶尾花資料集,所以不需要考慮量綱問題,
def dist(arrA , arrB):
x = arrA - arrB
dist = np.sum(np.power(x,2),axis=1)
return dist
1.3 撰寫自動生成rand質心的函式
選取data中所有行,第n-1列中的最小值和最大值(n-1列為其中一個特征值資料),利用np.random.uniform函式生成隨機質心,三個引數分別為(亂數下界,亂數上界,(k*n-1)的矩陣)
def randCent(D , k):
n = D.shape[1]
D_min = D.iloc[ : , :n-1].min()
D_max = D.iloc[ : , :n-1].max()
centers = np.random.uniform(D_min , D_max , (k,n-1))
return centers
1.4 K-means聚類函式的實作
因為在k-means實作的時候我們需要不斷地迭代質心,因此我們需要兩個可以迭代的容器來完成這個目標:
第一個容器是用來存放質心的,用list來存放,因為,list不僅是可迭代物件,同時list內不同元素索引位置也可用于標記和區分各質心,即各簇的編號;命名為center
第二個容器是三列,第一列存放與最近質心點的距離,第二列存放本次迭代的類別,第三列存放上次迭代的類別,(通過比較第二列和第三列來選擇是否終止迭代) 命名為res_mid,之后與元資料合并為resultlist
其中 dist代表回傳的歐氏距離值
def Kmeans(D , k):
m,n = D.shape
center = randCent(D , 3)
res_mid = np.zeros((m,3))
res_mid[: , 0] = np.inf
res_mid[: , 1:3] = -1
resultlist = pd.concat([D , pd.DataFrame(res_mid)] , axis = 1 , ignore_index = True)
changed = True
while changed:
changed = False
for i in range(m):
dist1 = dist(D.iloc[i,:n - 1].values, center)
resultlist.iloc[i, n] = dist1.min()
resultlist.iloc[i, n+1] = np.where(dist1 == dist1.min())[0]
changed = not (resultlist.iloc[:, n+1] == resultlist.iloc[ : , n +2]).all()
if changed:
cent_df = resultlist.groupby(n+1).mean()
center = cent_df.iloc[: , :n-1].values
resultlist.iloc[: , n+2] = resultlist.iloc[: , n+1]
return center , resultlist
有以下幾點需要特別注意:
1.設定統一的操作物件resultlist
為了呼叫和使用的方便,此處將res_mid容易轉換為了DataFrame并與輸入DataFrame合并,組成的 物件可作為后續呼叫的統一物件,該物件內即保存了原始資料,也保存了迭代運算的中間結果,包括資料所 屬簇標記和資料質心距離等,該物件同時也作為終函式的回傳結果;
2. 判斷質心發生是否發生改變條件
注意,在K-Means中判斷質心是否發生改變,即判斷是否繼續進行下一步迭代的依據并不是某點距離新的質 心距離變短,而是某點新的距離向量(到各質心的距離)中短的分量位置是否發生變化,即質心變化后某 點是否應歸屬另外的簇,在質心變化導致各點所屬簇發生變化的程序中,點到質心的距離不一定會變短,即 判斷條件不能用下述陳述句表示
if not (resultlist.iloc[:, -1] == resultlist.iloc[:, -2]).all()
3.合并DataFrame后索引值為n的列
這里有個小技巧,能夠幫助迅速定位DataFrame合并后列的索引,即兩個DF合并后后者的第一列在合并后的 DF索引值為n,第二列索引值為n+1
4.質心和類別一一對應
即在后生成的結果中,center的行標即為resultlist中各點所屬類別
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/226621.html
標籤:AI
下一篇:DGCF代碼解讀之重新出發