前言
愉悅的一周又要開始了,本周菌哥打算用幾期文章為大家分享一個之前在B站自學的一個專案——基于flink的電商用戶行為資料分析,本期我們先對專案整體功能和模塊做一個介紹,

正式介紹專案整體之前,我們來探討一下批處理和流處理技術,
批處理 VS 流處理
批處理和流處理代表了現在大資料處理領域兩種完全不同的資料處理方式,
下面兩組分別列出的分別是批處理和流處理的"代表作",

左邊Hadoop和Spark是“批處理”的代表作,其中Spark可以被認為是批處理的“巔峰之作”,已經非常成熟,并且社區也非常廣泛,應用的領域也很多,
右邊Storm和Flink是“流處理”的代表作,其中Storm是流處理的“先鋒”,但它本身有很多問題,Storm是首次真正意義上實作“流處理”,來一個資料就處理一個,但它隨之帶來的一個問題就是,在大資料應用場景下,吞吐量不夠,另外如果資料出現亂序,Storm也處理不了,而Flink的引入,在Storm的基礎上,完美的解決了著這兩個問題,Flink可以說,是目前“流處理”的一個高峰!
那具體“批處理”和“流處理”有哪些特點,我們來做一個對比:
批處理
- 批處理主要操作大容量靜態資料集,并在計算程序完成后回傳結果,可以認為,處理的是用一個固定時間間隔分組的資料點集合,批處理模式中使用的資料集通常符合下列特征:
– 有界:批處理資料集代表資料的有限集合
– 持久:資料通常始終存盤在某種型別的持久存盤位置中
– 大量:批處理操作通常是處理極為海量資料集的唯一方法
流處理
- 流處理可以對隨時進入系統的資料進行計算,流處理方式無需針對整個資料集執行操作,而是對通過系統傳輸的每個資料項執行操作,流處理中的資料集是“無邊界”的,這就產生了幾個重要的影響:
– 可以處理幾乎無限量的資料,但同一時間只能處理一條資料,不同記錄間只維持最少量的狀態,
– 處理作業是基于事件的,除非明確停止否則沒有“盡頭”,
– 處理結果立刻可用,并會隨著新資料的抵達繼續更新,

很好,回顧了批處理和流處理的區別之后,我們直接進入專案的整體介紹!
專案整體介紹
電商平臺中的用戶行為頻繁且較復雜,系統上線運行一段時間后,可以收集到大量的用戶行為資料,進而利用大資料技術進行深入挖掘和分析,得到感興趣的商業指標并增強對風險的控制,
電商用戶行為資料多樣,整體可以分為用戶行為習慣資料和業務行為資料兩大類,用戶的行為習慣資料包括了用戶的登錄方式、上線的時間點及時長、點擊和瀏覽頁面、頁面停留時間以及頁面跳轉等等,我們可以從中進行流量統計和熱門商品的統計,也可以深入挖掘用戶的特征;這些資料往往可以從web服務器日志中直接讀取到,而業務行為資料就是用戶在電商平臺中針對每個業務(通常是某個具體商品)所作的操作,我們一般會在業務系統中相應的位置埋點,然后收集日志進行分析,業務行為資料又可以簡單分為兩類:一類是能夠明顯地表現出用戶興趣的行為,比如對商品的收藏、喜歡、評分和評價,我們可以從中對資料進行深入分析,得到用戶畫像,進而對用戶給出個性化的推薦商品串列,這個程序往往會用到機器學習相關的演算法;另一類則是常規的業務操作,但需要著重關注一些例外狀況以做好風控,比如登錄和訂單支付,
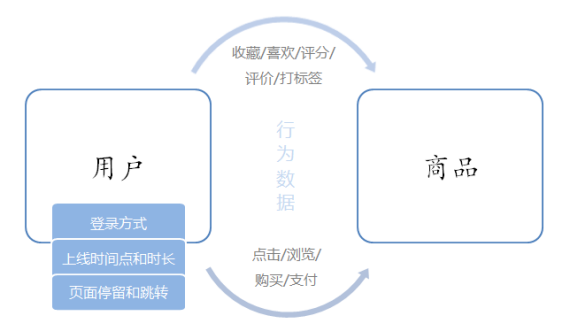
專案主要模塊
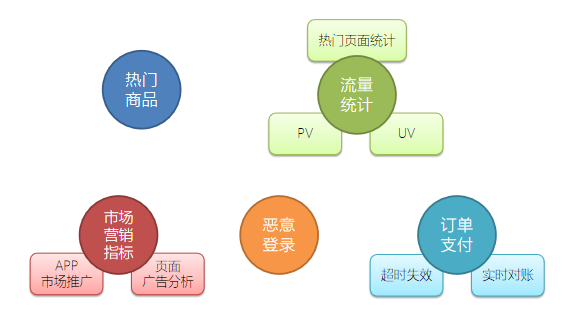
基于對電商用戶行為資料的基本分類,我們可以發現主要有以下三個分析方向:
1、熱門統計
利用用戶的點擊瀏覽行為,進行流量統計、近期熱門商品統計等,
2、偏好統計
利用用戶的偏好行為,比如收藏、喜歡、評分等,進行用戶畫像分析,給出個性化的商品推薦串列,
3、風險控制
利用用戶的常規業務行為,比如登錄、下單、支付等,分析資料,對例外情況進行報警提示,
總結:
- 統計分析
– 點擊、瀏覽
– 熱門商品、近期熱門商品、分類熱門商品、流量統計- 統計分析
– 收藏、喜歡、評分、打標簽
– 用戶畫像,推薦串列(結合特征工程和機器學習演算法)- 風險控制
– 下訂單、支付、登錄
– 刷單監控,訂單失效監控,惡意登錄(短時間內頻繁登錄失敗)監控
大的方面,我們可以將其分為實時統計分析和業務流程及風險控制領域

但本專案限于資料,我們只實作熱門統計和風險控制中的部分內容,將包括以下四大模塊:實時熱門商品統計、實時流量統計、惡意登錄監控和訂單支付失效監控,

專案模塊設計,可以參考這張圖:
由于對實時性要求較高,我們會用flink作為資料處理的框架,在專案中,我們將綜合運用flink的各種API,基于EventTime去處理基本的業務需求,并且靈活地使用底層的processFunction,基于狀態編程和CEP去處理更加復雜的情形,
資料源決議
我們準備了一份淘寶用戶行為資料集,保存為csv檔案,本資料集包含了淘寶上某一天隨機一百萬用戶的所有行為(包括點擊、購買、收藏、喜歡),資料集的每一行表示一條用戶行為,由用戶ID、商品ID、商品類目ID、行為型別和時間戳組成,并以逗號分隔,關于資料集中每一列的詳細描述如下:
| 欄位名 | 資料型別 | 說明 |
|---|---|---|
| userId | Long | 加密后的用戶ID |
| itemId | Long | 加密后的商品ID |
| categoryId | Int | 加密后的商品所屬類別ID |
| behavior | String | 用戶行為型別,包括(‘pv’, ‘’buy, ‘cart’, ‘fav’) |
| timestamp | Long | 行為發生的時間戳,單位秒 |
另外,我們還可以拿到web服務器的日志資料,這里以apache服務器的一份log為例,每一行日志記錄了訪問者的IP、userId、訪問時間、訪問方法以及訪問的url,具體描述如下:
| 欄位名 | 資料型別 | 說明 |
|---|---|---|
| ip | String | 訪問的 IP |
| userId | Long | 訪問的 user ID |
| eventTime | Long | 訪問時間 |
| method | String | 訪問方法 GET/POST/PUT/DELETE |
| url | String | 訪問的 url |
由于行為資料有限,在實時熱門商品統計模塊中可以使用UserBehavior資料集,而對于惡意登錄監控和訂單支付失效監控,我們只以示例資料來做演示,
小結
本期內容為大家回顧了關于批處理和流處理的特性及“代表作”分析,然后對于專案整體和主要模塊做了一個說明,至此,基于flink的電商用戶行為資料分析【1】| 專案整體介紹的內容就到這里,從下一期開始,我們就要正式步入實際需求,去完成功能模塊的開發,
你知道的越多,你不知道的也越多,我是Alice,我們下一期見!受益的朋友記得三連支持小菌!
文章持續更新,可以微信搜一搜「 猿人菌 」第一時間閱讀,思維導圖,大資料書籍,大資料高頻面試題,海量一線大廠面經…期待您的關注!
 CSDN認證博客專家
CSDN博客專家
大資料學者
追夢人
CSDN認證博客專家
CSDN博客專家
大資料學者
追夢人
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/226806.html
標籤:其他