公號:碼農充電站pro
主頁:https://codeshellme.github.io
上篇文章介紹了決策樹演算法的理論篇,本節來介紹如何用決策樹解決實際問題,
決策樹是常用的機器學習演算法之一,決策樹模型的決策程序非常類似人類做判斷的程序,比較好理解,
決策樹可用于很多場景,比如金融風險評估,房屋價格評估,醫療輔助診斷等,
要使用決策樹演算法,我們先來介紹一下 scikit-learn ,
1,scikit-learn
scikit-learn 是基于Python 的一個機器學習庫,簡稱為sklearn,其中實作了很多機器學習演算法,我們可以通過sklearn 官方手冊 來學習如何使用它,
sklearn 自帶資料集
要進行資料挖掘,首先得有資料,sklearn 庫的datasets 模塊中自帶了一些資料集,可以方便我們使用,
sklearn 自帶資料集:
- 鳶尾花資料集:load_iris()
- 乳腺癌資料集:load_breast_cancer()
- 手寫數字資料集:load_digits()
- 糖尿病資料集:load_diabetes()
- 波士頓房價資料集:load_boston()
- 體能訓練資料集:load_linnerud()
- 葡萄酒產地資料集:load_wine()
冒號后邊是每個資料集對應的函式,可以使用相應的函式來匯入資料,
比如我們用如下代碼匯入鳶尾花資料集:
from sklearn.datasets import load_iris
iris = load_iris()
使用dir(iris) 查看iris 中包含哪些屬性:
>>> dir(iris)
['DESCR', 'data', 'feature_names', 'filename', 'frame', 'target', 'target_names']
2,sklearn 中的決策樹
sklearn 庫的tree 模塊實作了兩種決策樹:
sklearn.tree.DecisionTreeClassifier類:分類樹的實作,sklearn.tree.DecisionTreeRegressor類:回歸樹的實作,
分類樹用于預測離散型數值,回歸樹用于預測連續性數值,
sklearn 只實作了預剪枝,沒有實作后剪枝,
DecisionTreeClassifier 類的建構式
def __init__(self, *,
criterion="gini",
splitter="best",
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.,
max_features=None,
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0.,
min_impurity_split=None,
class_weight=None,
ccp_alpha=0.0):
DecisionTreeClassifier 類的建構式中的criterion 引數有2 個取值:
entropy:表示使用 ID3 演算法(資訊增益)構造決策樹,gini:表示使用CART 演算法(基尼系數)構造決策樹,為默認值,
其它引數可使用默認值,
sklearn 庫中的決策分類樹只實作了ID3 演算法和CART 演算法,
DecisionTreeRegressor 類的建構式
def __init__(self, *,
criterion="mse",
splitter="best",
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.,
max_features=None,
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0.,
min_impurity_split=None,
ccp_alpha=0.0):
DecisionTreeRegressor 類的建構式中的criterion 引數有4 個取值:
mse:表示均方誤差演算法,為默認值,friedman_mse:表示費爾德曼均方誤差演算法,mae:表示平均誤差演算法,poisson:表示泊松偏差演算法,
其它引數可使用默認值,
3,構造分類樹
我們使用 sklearn.datasets 模塊中自帶的鳶尾花資料集 構造一顆決策樹,
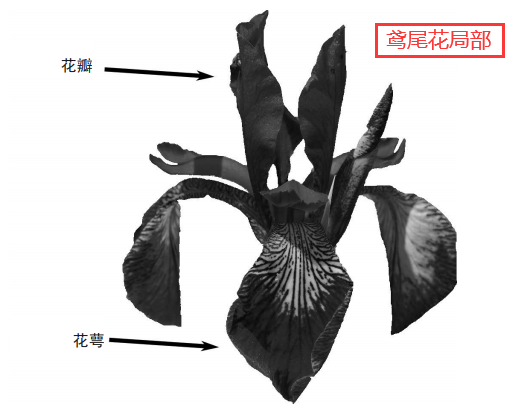
3.1,鳶尾花資料集
鳶尾花資料集目的是通過花瓣的長度和寬度,及花萼的長度和寬度,預測出花的品種,
這個資料集包含150條資料,將鳶尾花分成了三類(每類是50條資料),分別是:
setosa,用數字0表示,versicolor,用數字1表示,virginica,用數字2表示,
我們抽出3 條資料如下:
5.1,3.5,1.4,0.2,0
6.9,3.1,4.9,1.5,1
5.9,3.0,5.1,1.8,2
資料的含義:
- 每條資料包含5 列,列與列之間用逗號隔開,
- 從第1 列到第5 列,每列代表的含義是:花萼長度,花萼寬度,花瓣長度,花瓣寬度,花的品種,
- 在機器學習中,前4列稱為
特征值,最后1列稱為目標值,我們的目的就是用特征值預測出目標值,
將上面3 條資料,用表格表示就是:
| 花萼長度 | 花萼寬度 | 花瓣長度 | 花瓣寬度 | 花的品種 |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | 0 |
| 6.9 | 3.1 | 4.9 | 1.5 | 1 |
| 5.9 | 3.0 | 5.1 | 1.8 | 2 |
3.2,構造分類樹
首先匯入必要的類和函式:
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
其中:
DecisionTreeClassifier類用于構造決策樹,load_iris()函式用于匯入資料,train_test_split()函式用于將資料集拆分成訓練集與測驗集,accuracy_score()函式用于為模型的準確度進行評分,
匯入數據集:
iris = load_iris() # 準備資料集
features = iris.data # 獲取特征集
labels = iris.target # 獲取目標集
將資料分成訓練集和測驗集,訓練集用于訓練模型,測驗集用于測驗模型的準確度,
train_features, test_features, train_labels, test_labels =
train_test_split(features, labels, test_size=0.33, random_state=0)
我們向train_test_split() 函式中傳遞了4 個引數,分別是:
- features:特征集,
- labels:目標集,
- test_size=0.33:測驗集資料所占百分比,剩下的資料分給訓練集,
- random_state=0:亂數種子,
該函式回傳4 個值,分別是:
- train_features:訓練特征集,
- test_features:測驗特征集,
- train_labels:訓練目標集,
- test_labels:測驗目標集,
接下來構造決策樹:
# 用CART 演算法構建分類樹(你也可以使用ID3 演算法構建)
clf = DecisionTreeClassifier(criterion='gini')
# 用訓練集擬合構造CART分類樹
clf = clf.fit(train_features, train_labels)
上面兩句代碼已經在注釋中說明,最終我們得到了決策樹clf(classifier 的縮寫),
用clf 預測測驗集資料,test_predict 為預測結果:
test_predict = clf.predict(test_features)
計算預測結果的準確率:
score = accuracy_score(test_labels, test_predict)
score2 = clf.score(test_features, test_labels)
print(score, score2)
最終得出,sorce 和 score2都為 0.96,意思就是我們訓練出的模型的準確率為96%,
函式accuracy_score() 和 clf.score() 都可以計算模型的準確率,但注意這兩個函式的引數不同,
4,列印決策樹
為了清楚的知道,我們構造出的這個決策樹cfl 到底是什么樣子,可使用 graphviz 模塊將決策樹畫出來,
代碼如下:
from sklearn.tree import export_graphviz
import graphviz
# clf 為決策樹物件
dot_data = https://www.cnblogs.com/codeshell/p/export_graphviz(clf)
graph = graphviz.Source(dot_data)
# 生成 Source.gv.pdf 檔案,并打開
graph.view()
為了畫出決策樹,除了需要安裝相應的 Python 模塊外,還需要安裝Graphviz 軟體,
由上面的代碼,我們得到的決策樹圖如下:

我們以根節點為例,來解釋一下每個方框里的四行資料(葉子節點是三行資料)都是什么意思,

四行資料所代表的含義:
- 第一行
X[3]<=0.75:鳶尾花資料集的特征集有4 個屬性,所以對于X[n]中的n的取值范圍為0<=n<=3,X[0]表示第1個屬性,X[3]表示第4 個屬性,X[3]<=0.75的意思就是當X[3]屬性的值小于等于0.75 的時候,走左子樹,否則走右子樹,- X[0] 表示花萼長度,
- X[1] 表示花萼寬度,
- X[2] 表示花瓣長度,
- X[3] 表示花瓣寬度,
- 第二行
gini=0.666,表示當前的gini系數值, - 第三行
samples=100,samples表示當前的樣本數,我們知道整個資料集有150 條資料,我們選擇了0.33 百分比作為測驗集,那么訓練集的資料就占0.67,也就是100 條資料,根節點包含所有樣本集,所以根節點的samples值為100, - 第四行
value:value表示屬于該節點的每個類別的樣本個數,value是一個陣列,陣列中的元素之和為samples值,我們知道該資料集的目標集中共有3 個類別,分別為:setosa,versicolor和virginica,所以:value[0]表示該節點中setosa種類的資料量,即34,value[1]表示該節點中versicolor種類的資料量,即31,value[2]表示該節點中virginica種類的資料量,即35,
4.1,列印特征重要性
我們構造出來的決策樹物件clf 中,有一個feature_importances_ 屬性,如下:
>>> clf.feature_importances_
array([0, 0.02252929, 0.88894654, 0.08852417])
clf.feature_importances_ 是一個陣列型別,里邊的元素分別代表對應特征的重要性,所有元素之和為1,元素的值越大,則對應的特征越重要,
所以,從這個陣列,我們可以知道,四個特征的重要性排序為:
- 花瓣長度 > 花瓣寬度 > 花萼寬度 > 花萼長度
我們可以使用下面這個函式,將該陣列畫成柱狀圖:
import matplotlib.pyplot as plt
import numpy as np
# mode 是我們訓練出的模型,即決策樹物件
# data 是原始資料集
def plot_feature_importances(model, data):
n_features = data.data.shape[1]
plt.barh(range(n_features), model.feature_importances_, align='center')
plt.yticks(np.arange(n_features), data.feature_names)
plt.xlabel("Feature importance")
plt.ylabel("Feature")
plt.show()
plot_feature_importances(clf, iris)
下圖是用plot_feature_importances() 函式生成的柱狀圖(紅字是我添加的),從圖中可以清楚的看出每個特種的重要性,
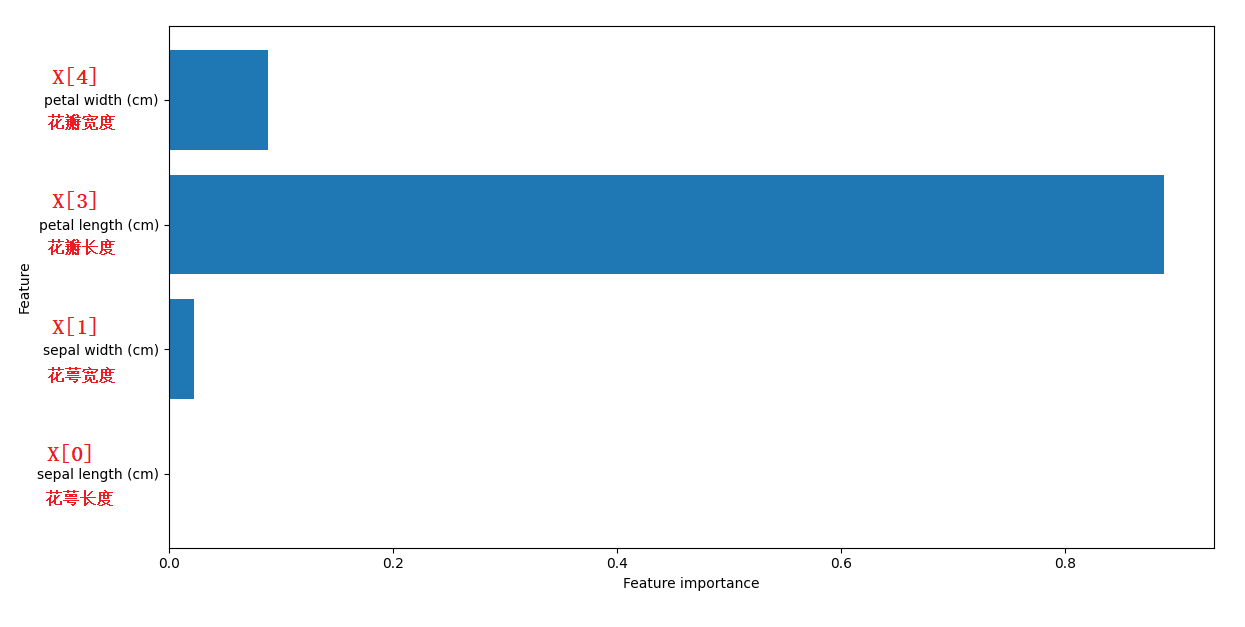
從該圖中也可以看出,為什么決策樹的根節點的特征是X[3],
5,構造回歸樹
我們已經用鳶尾花資料集構造了一棵分類樹,下面我們用波士頓房價資料集構造一顆回歸樹,
來看幾條資料:

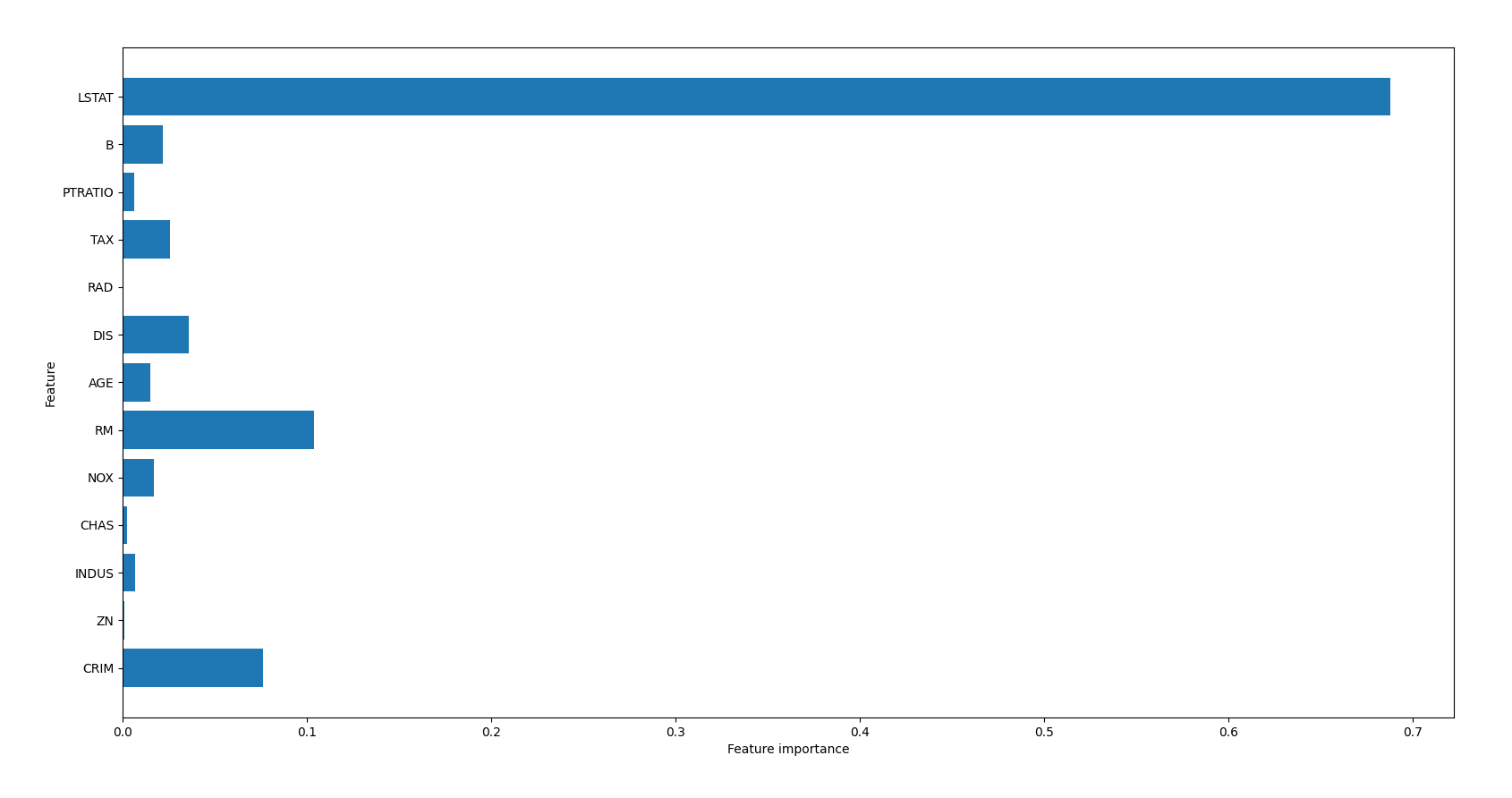
首先,我們認為房價是有很多因素影響的,在這個資料集中,影響房價的因素有13 個:
- "CRIM",人均犯罪率,
- "ZN",住宅用地占比,
- "INDUS",非商業用地占比,
- "CHAS",查爾斯河虛擬變數,用于回歸分析,
- "NOX",環保指數,
- "RM",每個住宅的房間數,
- "AGE",1940 年之前建成的房屋比例,
- "DIS",距離五個波士頓就業中心的加權距離,
- "RAD",距離高速公路的便利指數,
- "TAX",每一萬美元的不動產稅率,
- "PTRATIO",城鎮中教師學生比例,
- "B",城鎮中黑人比例,
- "LSTAT",地區有多少百分比的房東屬于是低收入階層,
資料中的最后一列的資料是房價:
- "MEDV" ,自住房屋房價的中位數,
因為房價是一個連續值,而不是離散值,所以需要構建一棵回歸樹,
下面對資料進行建模,構造回歸樹使用DecisionTreeRegressor 類:
from sklearn.tree import DecisionTreeRegressor
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_error
# 準備資料集
boston = load_boston()
# 獲取特征集和房價
features = boston.data
prices = boston.target
# 隨機抽取33% 的資料作為測驗集,其余為訓練集
train_features, test_features, train_price, test_price =
train_test_split(features, prices, test_size=0.33)
# 創建CART回歸樹
dtr = DecisionTreeRegressor()
# 擬合構造CART回歸樹
dtr.fit(train_features, train_price)
# 預測測驗集中的房價
predict_price = dtr.predict(test_features)
# 測驗集的結果評價
print('回歸樹準確率:', dtr.score(test_features, test_price))
print('回歸樹r2_score:', r2_score(test_price, predict_price))
print('回歸樹二乘偏差均值:', mean_squared_error(test_price, predict_price))
print('回歸樹絕對值偏差均值:', mean_absolute_error(test_price, predict_price))
最后四行代碼是計算模型的準確度,這里用了4 種方法,輸出如下:
回歸樹準確率: 0.7030833400349499
回歸樹r2_score: 0.7030833400349499
回歸樹二乘偏差均值: 28.40730538922156
回歸樹絕對值偏差均值: 3.6275449101796404
需要注意,回歸樹與分類樹預測準確度的方法不一樣:
dtr.score():與分類樹類似,不多說,r2_score():表示R 方誤差,結果與dtr.score() 一樣,取值范圍是0 到1,mean_squared_error():表示均方誤差,數值越小,代表準確度越高,mean_absolute_error():表示平均絕對誤差,數值越小,代表準確度越高,
可以用下面代碼,將構建好的決策樹畫成圖:
from sklearn.tree import export_graphviz
import graphviz
# dtr 為決策樹物件
dot_data = https://www.cnblogs.com/codeshell/p/export_graphviz(dtr)
graph = graphviz.Source(dot_data)
# 生成 Source.gv.pdf 檔案,并打開
graph.view()
這棵二叉樹比較大,你可以自己生成看一下,
再來執行下面代碼,看下特征重要性:
import matplotlib.pyplot as plt
import numpy as np
# mode 是我們訓練出的模型,即決策樹物件
# data 是原始資料集
def plot_feature_importances(model, data):
n_features = data.data.shape[1]
plt.barh(range(n_features), model.feature_importances_, align='center')
plt.yticks(np.arange(n_features), data.feature_names)
plt.xlabel("Feature importance")
plt.ylabel("Feature")
plt.show()
plot_feature_importances(dtr, boston)
從生成的柱狀圖,可以看到LSTAT 對房價的影響最大:
6,關于資料準備
本文中用到的資料是sklearn 中自帶的資料,資料完整性比較好,所以我們沒有對資料進行預處理,實際專案中,可能資料比較雜亂,所以在構建模型之前,先要對資料進行預處理,
-
要對資料有個清楚的認識,每個特征的含義,如果有特別明顯的特征對我們要預測的目標集沒有影響,則要將這些資料從訓練集中洗掉,
-
如果某些特征有資料缺失,需要對資料進行補全,可以使用著名的 Pandas 模塊對資料進行預處理,如果某特征的資料缺失嚴重,則應該將其從訓練集中洗掉,對于需要補全的值:
- 如果缺失的值是離散型資料,可以用出現次數最多的值去補全缺失值,
- 如果缺失的值是連續型資料,可以用該特征的平均值去補全缺失值,
-
如果某些特征的值是字串型別資料,則需要將這些資料轉為數值型資料,
- 可以使用
sklearn.feature_extraction模塊中的DictVectorizer類來處理(轉換成數字0/1),
- 可以使用
-
在測驗模型的準確率時,如果測驗集中只有特征值沒有目標值,就不好對測驗結果進行驗證,此時有兩種方法來測驗模型準確率:
- 在構造模型之前,用
train_test_split() 函式將原始資料集(含有目標集)拆分成訓練集和測驗集, - 使用
sklearn.model_selection模塊中的cross_val_score函式進行K 折交叉驗證來計算準確率,
- 在構造模型之前,用
K 折交叉驗證原理很簡單:
- 將資料集平均分成K 個等份,
K一般取10,- 使用K 份中的1 份作為測驗資料,其余為訓練資料,然后進行準確率計算,
- 進行多次以上步驟,求平均值,
7,總結
本篇文章介紹了如何用決策樹來處理實際問題,主要介紹了以下知識點:
sklearn是基于Python的一個機器學習庫,sklearn.datasets模塊中有一些自帶資料集供我們使用,- 用
sklearn.tree中的兩個類來構建分類樹和回歸樹:DecisionTreeClassifier類:構造決策分類樹,用于預測離散值,DecisionTreeRegressor類:構造決策回歸樹,用于預測連續值,
- 分別介紹了兩個類的建構式中的
criterion引數的含義, - 介紹了幾個重要函式的用途:
train_test_split() 函式用于拆分資料集,o.fit() 用于擬合決策樹,(o表示決策樹物件)o.predict() 用于預測資料,o.score() 用于給模型的準確度評分,accuracy_score() 函式用于給分類樹模型評分,r2_score() 函式用于給回歸樹模型評分,mean_squared_error() 函式用于給回歸樹模型評分,mean_absolute_error() 函式用于給回歸樹模型評分,
- 介紹了如何給決策樹畫圖,
- 介紹了如何給特征重要性畫圖,
(本節完,)
推薦閱讀:
決策樹演算法-理論篇
歡迎關注作者公眾號,獲取更多技術干貨,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/227324.html
標籤:其他