目錄
前言
訊息佇列
搜索引擎
快取
分庫分表
讀寫分離
分布式系統
系統拆分
分布式服務框架
分布式鎖
分布式事務
分布式會話
高可用架構
高可用系統
限流
熔斷
降級
資料庫CRUD操作
1.洗掉表 drop table 表名稱
2.修改表
3.洗掉資料庫
CRUD操作
1、添加資料(create)
2、洗掉資料(delete)
3、修改資料(uodate)
4、查詢資料(10種)
總結一下
前言
crud是指在做計算處理時的增加(Create)、讀取(Retrieve)、更新(Update)和洗掉(Delete)幾個單詞的首字母簡寫,crud主要被用在描述軟體系統中資料庫或者持久層的基本操作功能,你可能有所感悟,零散的資料讀了很多,但是很難有提升,到處是干貨,但是并沒什么用,簡單來說就是缺乏系統化,另外,噪音太多,雷同的框架一大把,我不至于全都要去學了吧,
這里,根據基礎、Java基礎、Java進階給分了下類,挑的也都是最常用最重要的工具,
訊息佇列
-
為什么使用訊息佇列?訊息佇列有什么優點和缺點?Kafka、ActiveMQ、RabbitMQ、RocketMQ 都有什么優點和缺點?
-
如何保證訊息佇列的高可用?
-
如何保證訊息不被重復消費?(如何保證訊息消費時的冪等性)
-
如何保證訊息的可靠性傳輸?(如何處理訊息丟失的問題)
-
如何保證訊息的順序性?
-
如何解決訊息佇列的延時以及過期失效問題?訊息佇列滿了以后該怎么處理?有幾百萬訊息持續積壓幾小時,說說怎么解決?
-
如果讓你寫一個訊息佇列,該如何進行架構設計啊?說一下你的思路,
搜索引擎
-
es 的分布式架構原理能說一下么(es 是如何實作分布式的啊)?
-
es 寫入資料的作業原理是什么啊?es 查詢資料的作業原理是什么啊?底層的 lucene 介紹一下唄?倒排索引了解嗎?
-
es 在資料量很大的情況下(數十億級別)如何提高查詢效率啊?
-
es 生產集群的部署架構是什么?每個索引的資料量大概有多少?每個索引大概有多少個分片?
快取
-
在專案中快取是如何使用的?快取如果使用不當會造成什么后果?
-
Redis 和 Memcached 有什么區別?Redis 的執行緒模型是什么?為什么單執行緒的 Redis 比多執行緒的 Memcached 效率要高得多?
-
Redis 都有哪些資料型別?分別在哪些場景下使用比較合適?
-
Redis 的過期策略都有哪些?手寫一下 LRU 代碼實作?
-
如何保證 Redis 高并發、高可用?Redis 的主從復制原理能介紹一下么?Redis 的哨兵原理能介紹一下么?
-
Redis 的持久化有哪幾種方式?不同的持久化機制都有什么優缺點?持久化機制具體底層是如何實作的?
-
Redis 集群模式的作業原理能說一下么?在集群模式下,Redis 的 key 是如何尋址的?分布式尋址都有哪些演算法?了解一致性 hash 演算法嗎?如何動態增加和洗掉一個節點?
-
了解什么是 Redis 的雪崩和穿透?Redis 崩潰之后會怎么樣?系統該如何應對這種情況?如何處理 Redis 的穿透?
-
如何保證快取與資料庫的雙寫一致性?
-
Redis 的并發競爭問題是什么?如何解決這個問題?了解 Redis 事務的 CAS 方案嗎?
-
生產環境中的 Redis 是怎么部署的?
分庫分表
-
為什么要分庫分表(設計高并發系統的時候,資料庫層面該如何設計)?用過哪些分庫分表中間件?不同的分庫分表中間件都有什么優點和缺點?你們具體是如何對資料庫如何進行垂直拆分或水平拆分的?
-
現在有一個未分庫分表的系統,未來要分庫分表,如何設計才可以讓系統從未分庫分表動態切換到分庫分表上?
-
如何設計可以動態擴容縮容的分庫分表方案?
-
分庫分表之后,id 主鍵如何處理?
讀寫分離
-
如何實作 MySQL 的讀寫分離?MySQL 主從復制原理是啥?如何解決 MySQL 主從同步的延時問題?
高并發系統
-
如何設計一個高并發系統?
-
限流演算法實作
-
系統基本架構
分布式系統
-
什么是分布式系統?
-
分布式系統利弊
-
分布式系統背景
系統拆分
-
為什么要進行系統拆分?如何進行系統拆分?拆分后不用 Dubbo 可以嗎?
分布式服務框架
-
說一下 Dubbo 的作業原理?注冊中心掛了可以繼續通信嗎?
-
Dubbo 支持哪些序列化協議?說一下 Hessian 的資料結構?PB 知道嗎?為什么 PB 的效率是最高的?
-
Dubbo 負載均衡策略和集群容錯策略都有哪些?動態代理策略呢?
-
Dubbo 的 spi 思想是什么?
-
如何基于 Dubbo 進行服務治理、服務降級、失敗重試以及超時重試?
-
分布式服務介面的冪等性如何設計(比如不能重復扣款)?
-
分布式服務介面請求的順序性如何保證?
-
如何自己設計一個類似 Dubbo 的 rpc 框架?
分布式鎖
-
Zookeeper 都有哪些應用場景?
-
使用 Redis 如何設計分布式鎖?使用 Zookeeper 來設計分布式鎖可以嗎?以上兩種分布式鎖的實作方式哪種效率比較高?
分布式事務
-
分布式事務了解嗎?你們如何解決分布式事務問題的?TCC 如果出現網路連不通怎么辦?XA 的一致性如何保證?
分布式會話
-
集群部署時的分布式 Session 如何實作?
高可用架構
-
Hystrix 介紹
-
電商網站詳情頁系統架構
高可用系統
-
如何設計一個高可用系統?
限流
-
如何限流?在作業中是怎么做的?說一下具體的實作?
熔斷
-
如何進行熔斷?
-
熔斷框架都有哪些?具體實作原理知道嗎?
降級
-
如何進行降級?
資料庫CRUD操作
1.洗掉表 drop table 表名稱
2.修改表
alter table 表名稱 add 列名 資料型別 (add表示添加一列)
alter table 表名稱 drop column 列名稱( column表示列 drop表示洗掉)
3.洗掉資料庫
drop database 資料庫
CRUD操作
(create 添加資料read讀取資料 update 修改資料delete洗掉資料)
1、添加資料(create)
a: insert into + nation values('n002 ','回族 ')--加單引號是轉為字串,英文的
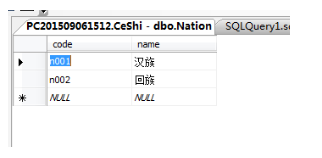
b: insert into nation values('n003',' ') 只添加一列 后面的是空 給所有的添加可以用
c: insert into nation(code,) values('n004') 給某一列添加可以用
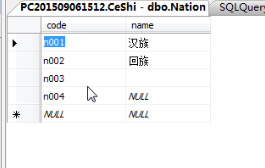
d:給多列添加 insert into nation(code,name) values('n004','維吾爾族')
e: 專門添加自增長列的 insert into 表名 values('p001','p006') 自增長列不用管,直接寫第二列
2、洗掉資料(delete)
delete from +表名稱--洗掉表中所有內容
delete from +表名稱 where ids=5 (洗掉此行)---where后面跟一個條件
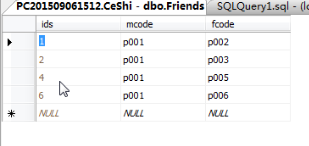
3、修改資料(uodate)
update +表名稱 set +列名稱=' ' set(設定)---修改所有的內容這一列的
update +表名稱 set +列名稱='p006 ' where ids=6
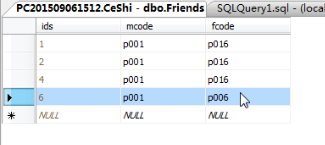
update +表名稱 set +列名稱='p006 ',列名稱='p002' where ids=6-----用逗號隔開可以修改多列
整數型(int)的不需要加單引號 0 (false)1(true)
4、查詢資料(10種)
a1:簡單查詢
select * from 表名稱 ——查詢表中所有資料 *代表所有列
select code,name from 表名稱——查詢指定列資料
select code,name from 表名稱——查指定列的資料
select code as'代號',name as'姓名' from 表名稱——給列指定別名
a2:條件查詢
select * from 表名 where code=' ' 查這一行
select * from 表名 where sex='true' and nation=' ' 表示并列,--多條件并的關系
select * from 表名 where sex='true' or nation=' ' --多條件或的關系
a3:范圍查詢
select * from 表名 where 列名>40 and 列名<50
select * from 表名 where 列名 between 40 and 50 --專用于范圍查詢
a4:離散查詢
select * from 表名 where 列名 in (' ',' ',' ')
select * from 表名 where 列名 not in (' ',' ',' ') 反選,不在里面的
a5:模糊查詢
select * from 表名 where 列名 like '%寶馬%'——查包含寶馬的
select * from 表名 where 列名 like '寶馬%'——查以寶馬開頭的
select * from 表名 where 列名 like '%寶馬'——查以寶馬結尾的
select * from 表名 where 列名 like '寶馬'——查等于寶馬的
select * from 表名 where 列名 like '--E'——查第三個是E的
% 代表是任意多個字符
- 下劃線 代表是一個字符
a6:排序查詢
select * from 表名 order by 列名——默認升序排序
select * from 表名 order by 列名 desc——降序排列
select * from 表名 order by 列名 desc, 列名 asc——多個條件排序 , 前面是主條件 后面是次要條件
desc 降序 ,asc 升序, order by 排序 根據哪一列排序
a7:分頁查詢
select top 5 * from 表名——查詢前5條資料
select top 5 * from 表名 where code not in (select top 5 code from car)
a8:去重查詢(去掉重復的)
select distinct 列名 from
a9:分組查詢
select Brand from 表名 group by Brand having count(*)>2
group by having ——表示根據一列分組 ,count(*)>2——每一組的數量
a10:聚合函式(統計查詢)
select count (*) from 表名——查詢所有資料條數(每一列的)
select count (列名主鍵) from 表名——查詢這列的所有資料條數(執行快)
select sum (列名) from 表名——求和
select avg (列名) from 表名——求平均值
select max (列名) from 表名——求最大值
select min (列名) from 表名——求最小值
總結一下
Java后端做三件事,向前一件事,向后兩件事,向前負責API互動,也就是Web,向后集成第三方服務,不同型別的資料庫是一類,其他第三方技術是另一類,在這三件事之上都是架構范疇的事情,例如微服務等等,CRUD也見水平,有些人代碼寫的很漂亮,閱讀性很高,看著很舒服;有些代碼寫完,可能自己都不想看第二遍了,所以有一定CRUD經驗后,設計模式是繞不開的,
最后來自小編的福利

以下的面試題及答案是小編整理許久整理成的合集,需要領取的小伙伴可以 點我 免費領取 ,在這里小編祝福想去大廠面試的同學,旗開得勝,offer拿到手抽筋,
部分資料圖片:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/227504.html
標籤:其他
上一篇:從Hadoop1.0到Hadoop2.0架構的優化和發展探索詳解
下一篇:漫畫:什么是 “千年蟲” 問題?