在前宣告下面有一部分直接參考高翔老師SLAM14講中的內容,因為我實在是看不懂,臨時放在這里,以后有用到再做詳細研究,
在SLAM14講的CP2中第一次引入運動方程以及觀測方程來描述物體帶著傳感器在空間中運動,可以先觀察運動方程以及觀測方程的形式,
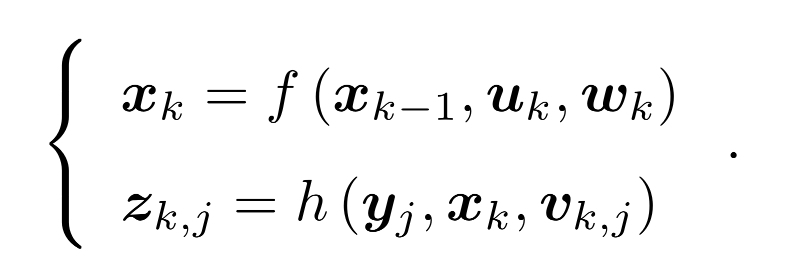
第一個運動方程的輸入包括上一次的位置Xk-1、運動傳感器的讀數(也可稱為輸入)uk、噪聲wk,以及觀測方程根據在xk位置上看到觀測點yj產生一個觀測資料zk,j,vk,j為在此次觀測中的噪聲,不難看出這個方程具有通用性,不管是什么傳感器都可以表示這兩個方程,方程中的位姿可用變換矩陣來表示,再用李代數來優化,在前面的CP4講到,觀測方程由相機成像方程給出,內參是相機固定的,外參是相機的位姿,在前面的CP5講到,但這講的重點不是這個方程而是其中的噪聲,
在SLAM問題中同一個點往往被一個相機在不同的時間內多次觀測,同一個相機在每個時刻中觀測到的點也不止一個,因為這些原因,我們具有了更多的約束,最終能夠較好的從噪聲資料中恢復出我們需要的的東西,
一、狀態估計問題
我們可以討論一下上面兩個方程的具體引數化形式,首先位姿變數xk可以用Tk或者exp(ξ^k)表示,由于運動方程在SLAM沒有特殊性,我們先看觀測方程,可以表示為
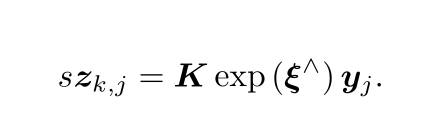
K為相機內參,s為像素點的距離,同時這里的zk,j和yj要用齊次坐標來描述,且中間有一次齊次到非齊次的變換,考慮資料受噪聲的影響后會有什么樣的變化,通常假設兩個噪聲項wk,vk,j滿足高斯分布,
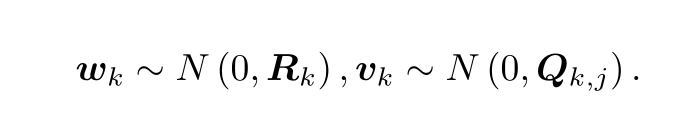
在這些噪聲的影響下,我們希望能夠通過帶噪聲的資料z和u,推斷位姿x和地圖y(以及他們的分布概率),這就構成了一個狀態估計問題,在SLAM程序中,這些資料是通過時間逐漸到來的,使用濾波器來求解是一種早期的方法,其中擴展卡爾曼濾波器(EKF)進行求解是一種方法,但是EKF關心當前時刻的狀態估計xk,不考慮之前的狀態,現在更多普遍使用非線性優化方式,使用所有時刻的采集到的資料進行狀態估計,
在非線性優化中,將所有的待估計變數放入一個"狀態變數"中:x={x1,...,xN,y1,...,yM}.
現在對機器人狀態的估計,就是求已知輸入資料u和觀測資料z的情況下,計算狀態x的條件概率分布P(x|z,u).類似于x這里的z,u同樣是所有資料的統稱,特別的,當我們沒有檢測運動的傳感器,只有一張張影像時,即只考慮觀測方程的資料,相當于估計P(x|x)的條件概率分布,如果忽略影像在時間上的聯系,把他們看作一堆彼此沒有關系的圖片,該問題為SfM,即如何通過從許多影像中重建三維空間結構,而SLAM問題可以把影像看作有時間先后順序,需要實時求解的SfM問題,我們需要利用貝葉斯公式來估計狀態變數的條件分布,
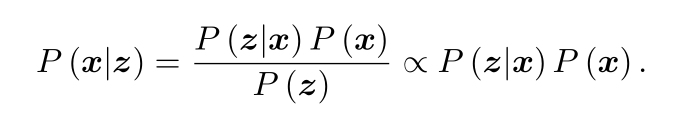
貝葉斯法則的左側通常稱為后驗概率,右側P(z|x)稱為似然,P(x)為先驗,直接求后驗概率是困難的,但求一個狀態最優估計使得在該狀態下后驗概率最大化(MAP),則是可行的,
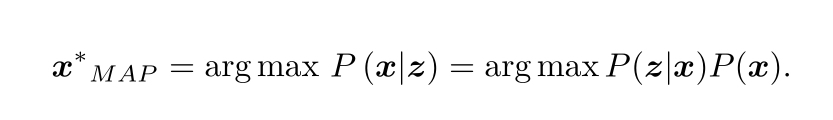
因為分母與x無關所以直接忽略,貝葉斯法則告訴我們,求最大后驗概率,相當于最大似然和先驗的乘積,接著當我們不知道機器人的位姿大概在什么地方,此時就沒有了先驗,那么就能求解x的最大似然估計,
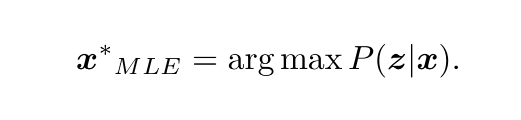
似然指的是"在當前的位姿下,可能產生怎樣的觀測資料",由于我們知道觀測資料,所以最大似然估計,相當于"在什么樣的狀態下,最可能產生現在觀測到的資料",
二、最小二乘
如何求最大似然估計?在高斯分布的情況之下,最大似然有比較簡單的形式,我們假設噪聲項vk~N(0,Qk,j)所以觀測資料的條件分布為
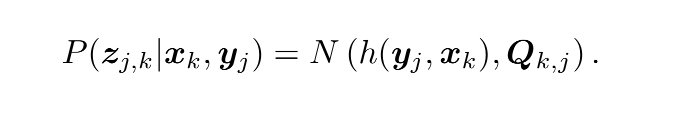
它依舊是一個高斯分布,為了計算它最大化的xk,yj,使用最小化負對數,求高斯分布的最大似然,


三、非線性最小二乘
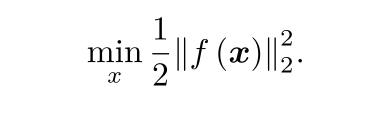
上式是一最小二乘問題,這里的x屬于Rn f是一個任意非線性函式,我們設它為m維;f(x)屬于Rm 如果f是一個數學形式簡單的函式,那么問題可以用決議形式來求,讓目標函式的導數等于零,然后求解x的最優解,得到函式在導數為零的極值,只需要比較極大值、極小值、鞍部的函式值大小就行,那這個函式是否容易求解呢?取決于f導函式的形式,在SLAM中我們采用李代數來表示旋轉與位移,但依舊不能夠十分容易的求解一個非線性方程,
對于不方便直接求解的最小二乘問題,可以用迭代的方法,從一個初始值開始不斷更新變數,使其函式值下降,具體步驟如下:
1.給定某個初始值x
2.對于第k次迭代,尋找一個增量Δxk,使得||f(xk+Δx1)||2 達到極小值,
3.若Δxk足夠小,就停止
4.否則,另xk+1=xk+Δxk,回傳2
這樣讓求解導函式為零的程序,變成一個不斷尋找梯度并下降的程序,直到無法再減小,此時函式收斂,這個程序只要尋到迭代點的梯度方向即可,無需尋找全域導函式為零的情況,(?多個極小值)
四、一階和二階梯度法
求解增量最直接的方法就是把目標函式在x附近進行泰勒展開:||f(x+Δx)||2≈||f(x)||2+J(x)Δx+1/2ΔxTHΔx
這里的J是關于||f(x)||2關于x的導數(雅可比矩陣),而H則是二次導數(海塞矩陣),我們可以保留泰勒展開的一階和二階項,對應求解方法就是一階梯度和二階梯度法,
如果保留一階梯度,那么增量的方向就是 Δx*=-JT(x).
他的意義非常簡單,只要我們沿著反向梯度的方向前進,我們還需要該方向取一個步長λ,求最快的下降方式,這種就是最速下降法,
如果保留二階梯度那么增量函式
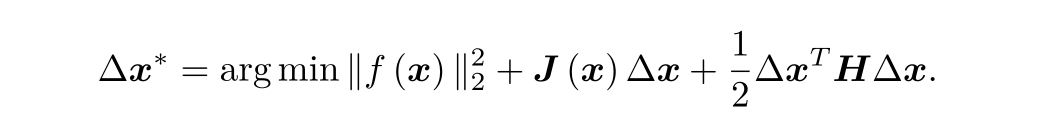
求右側等式關于Δx的導數并令它等于零,就得到增量的解 HΔx=-JT
這種方法又稱牛頓法,我們看到一階和二階梯度法都非常直觀,只要把函式在迭代點附近進行泰勒展開,并且更新量最小化,由于泰勒展開之后函式形成多項式,于是求解增量只需求解線性方程即可,
五、Gauss-Newton
這個方法是最優化演算法中最簡單的方法之一,它的思想就是將f(x)進行一階泰勒展開(注意不是目標函式f(x)2)
f(x+Δx)≈f(x)+J(x)Δx
這里的J(x)是f(x)關于x的導數實際上是一個m*n的矩陣,也是一個雅可比矩陣,為了求解Δx,我們需要求解一個線性最小二乘問題,
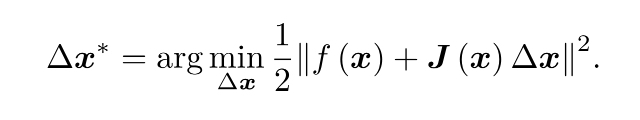

注意,我們要求解的變數是Δx,因此這是一個線性方程組,我們稱之為增量方程,也是高斯牛頓方程,或是正規方程,我們把左式定義為H,右邊定義為g,上式變成HΔx=g,
這里把左側記作H是有意義的,對比牛頓法,Gauss-Newton用JTJ作為牛頓法中二階海塞矩陣,從而忽略了H的程序,求解增量方程是整個優化問題的核心所在,如果我們能解出方程,那么演算法步驟如下:
1.給定初始值x0
2.對于第k次迭代,求出當前的雅可比矩陣J(xk)和誤差f(xk),
3.求解增量方程
4.若Δxk足夠小,則停止,否則xk+1=xk-Δxk,回傳2
原則上,增量方程要求我們所用的近似H矩陣是可逆的(而且是正定的),但實際的JTJ只有半正定性(?),也就是,在使用該方法,可能出現H為奇異矩陣或病態的情況,此時增量穩定性差,演算法不收斂,更嚴重,就算我們的H非病態和非奇異,如果我們的步長太大,導致我們區域不夠精確,這樣我們不但不能保證它迭代收斂,甚至可能會讓目標函式更大,
盡管Gauss-Newton法有這些確定,但依舊值得學習,因為有相當多的演算法都是它的變種,
六、Levenberg-Marquadt
L-M方法比G-N方法更加魯棒,盡管它的收斂比G-N慢,被稱為阻尼牛頓法,
由于G-N方法采用近似二階泰勒展開只能在展開點附近有比較好的近似效果,所以我們可以給Δx添加一個信賴區域,非線性優化具有一系列這種方法,可被稱為信賴區域方法,在信賴區域里面我們認為近似是有效的,反之則可能出現問題,
那么怎么確定信賴區域的范圍呢?一個比較好的方法就是根據我們近似模型跟實際函式直接的差距來確定這個范圍,如果差異小,就讓范圍盡可能大,反之則縮小這個范圍,
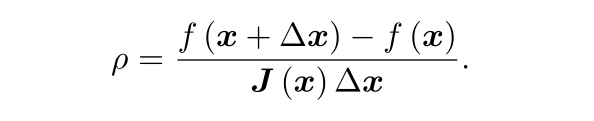
使用上式來判斷近似是不是夠好,ρ的分子是函式下降的值,如果接近1,則近似是好的,如果太小,說明實際減小的值遠少于近似減小的值,則認為近似比較差,需要縮小范圍,反之則擴大,
下面是一個改良版非線性優化框架:
1,給定初始值x0,以及初始優化半徑μ
2.對于第k次迭代求

3.計算ρ
4.若ρ>3/4 則μ=2μ
4.若ρ<1/4 則μ=0.5μ
5.如果ρ大于某閾值,認為近似可行,令xk+1=xk+Δxk
6.判斷演算法是否收斂,不收斂回傳2.
這里近似范圍擴大倍數和閾值都是經驗值,可以替換,在上式中我們把增量限定于一個半徑為μ的球中,認為在球中是有效的,帶上D后這個球可以看成一個橢球,在L提出的優化方法中,把D取成單位陣I,相當于直接把Δx約束在一個球里,隨后M提出將D取為為負數對角陣,實際中通常用JTJ的對角元素平方根,使得在梯度小的維度約束范圍更大,

(H+λI)Δx=g
當引數λ比較小,H占主要地位,說明二次近似模型在該范圍內比較好,L-M近似于G-N,如果λ比較大,L-M更接近于一階梯度下降法,說明二次近似模型不夠好,這樣L-M可以一定程度上避免線性方程組的系數矩陣的非奇異和病態問題,
---小結
總之非線性優化問題的框架分為LineSearch和TrustRegion,前者先固定搜索方向,然后再方向尋找步長,以最速下降法和G-N法,后者先固定搜索區域,然后找到最優點,以L-M為代表,
無論是G-N還是L-M,在做最優計算的時候,都需要提供變數的初始值,實際上非線性優化的所有迭代求解方案,都需要用戶提供一個較好的初始值,由于目標函式太復雜,導致求解空間上難以琢磨,對于問題提供給不同的初始值往往得到不同的計算程序,這種情況是非線性優化的通病:大多數演算法都容易陷入區域極小值,因此,無論是哪類問題,我們提供初始值都需要有科學依據,
如何求解線性增量方程?存在著許多針對線性方程組的數值求解方法,不同領域采用不同的方法,但幾乎沒有之中直接求系數矩陣的逆,我們采用矩陣分解的方法來求解,比如QR、Cholesky等分解方法,
接下來就是代碼部分,書中的代碼我會實驗并且增加一些知識點來理解它,當然書中的講解也是非常充分的,但可能需要一些基礎,
實踐一、Ceres
Ceres庫主要是面對通用的最小二乘的問題,我們需要定義優化問題,設定選項輸入求解即可,Ceres求解的問題最一般的形式如下(帶邊界的核函式最小二乘):
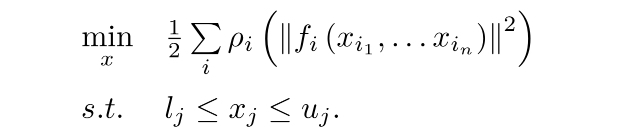
目標函式有許多平方項,經過一個核函式ρ()之后,求和組成,最簡單的情況ρ取恒等函式,這個問題中,優化變數x1……xn,fi稱為代價函式,在SLAM中亦可理解成誤差項,lj uj為第j個優化變數的上下限,最簡單的情況下上下限取無窮,并且核函式取恒等函式,就得到無約束的最小二乘,
下面的演示,假設有一條滿足y=exp(ax2+bx+c)+w方程的曲線,
abc為曲線的引數,w為高斯噪聲,我們假設有N點x,y觀測資料點,想根據這些點來求出曲線的引數,那么,可以求解以下最小二乘的問題以估計曲線引數:
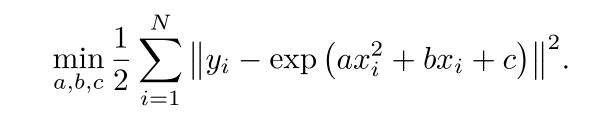
不得不說,寫這個實踐的程序還是十分痛苦的,因為一些版本問題,導致之前的代碼不能直接使用,包括CMakeLists的撰寫也是有點困難,


cmake_minimum_required(VERSION 2.8) project(ceres_curve_fitting) set(CMAKE_CXX_FLAGS "-std=c++14 -O3") find_package(OpenCV REQUIRED) include_directories(${OpenCV_INCLUDE_DIRS}) find_package(Ceres REQUIRED) include_directories(${CERE_INCLUDE_DIRS}) add_executable(ceres_curve_fitting main.cpp) target_link_libraries(ceres_curve_fitting ${OpenCV_LIBS} ${CERES_LIBRARIES})View Code
實踐一的主要是安裝Ceres然后倒入包就行了,
#include<iostream> #include<opencv2/core/core.hpp> #include<ceres/ceres.h> #include<chrono> using namespace std; struct CURVE_FITTING_COST{ CURVE_FITTING_COST(double x, double y): _x(x), _y(y){} template<typename T> bool operator() (const T* const abc, T* residual) const{ residual[0]= T(_y) - ceres::exp(abc[0]*T(_x) *T(_x) + abc[1]*T(_x) + abc[2]); return true; } const double _x,_y; }; int main(int argc, char** argv){ double a=1.0, b=2.0, c=1.0; int N=100; double w_sigma=1.0; cv::RNG rng; double abc[3]={0,0,0}; vector<double> x_data, y_data; cout<<"generating data:"<<endl; for(int i=0; i<N; i++){ double x=i/100.0; x_data.push_back(x); y_data.push_back(exp(a*x*x+b*x+c) + rng.gaussian(w_sigma)); cout<<x_data[i]<<" "<<y_data[i]<<endl; } ceres::Problem problem; for(int i=0; i<N;i++){ problem.AddResidualBlock(new ceres::AutoDiffCostFunction<CURVE_FITTING_COST, 1, 3>(new CURVE_FITTING_COST(x_data[i], y_data[i])), nullptr, abc); } ceres::Solver::Options options; options.linear_solver_type=ceres::DENSE_QR; options.minimizer_progress_to_stdout=true; ceres::Solver::Summary summary; chrono::steady_clock::time_point t1=chrono::steady_clock::now(); ceres::Solve( options, &problem, &summary); chrono::steady_clock::time_point t2=chrono::steady_clock::now(); chrono::duration<double> time_used=chrono::duration_cast<chrono::duration<double>>(t2-t1); cout<<"solve time const="<<time_used.count()<<"seconds."<<endl; cout<<summary.BriefReport()<<endl; cout<<"estimate a,b,c="; for(auto a:abc) cout<<a<<" "; cout<<endl; return 0; }View Code
代碼部分的話主要說一些我不太知道的,以及關鍵的,經過查閱的內容,
首先就是
struct CURVE_FITTING_COST{ CURVE_FITTING_COST(double x, double y): _x(x), _y(y){} template<typename T> bool operator() (const T* const abc, T* residual) const{ residual[0]= T(_y) - ceres::exp(abc[0]*T(_x) *T(_x) + abc[1]*T(_x) + abc[2]); return true; } const double _x,_y; }; problem.AddResidualBlock(new ceres::AutoDiffCostFunction<CURVE_FITTING_COST, 1, 3>(new CURVE_FITTING_COST(x_data[i], y_data[i])), nullptr, abc);
這個是代碼中定義CURVE_FITTING_COST的以及使用的程序,首先這里是一個擬函式Functor,有什么用呢,就是我們可以看到AutoDiffCostFunction函式只接受一個引數,但是我們這個結構體同時需要x,y才能構建它,于是就用到擬函式,通過這個模板類的構建方法,我認為是先將它實體化輸入x,y初始值,然后再帶到對應的函式中,相當于是需要多載()運算子,
然后就是AddResidualBlock這個函式,將誤差項添加到目標函式,因為優化需要梯度,所以有幾種選項1.自動求導,就是我們用的這種 2.使用數值求導 3.自行推倒決議導數形式,而自動求導AutoDiffCostFunction需要指定誤差項以及優化變數,這里的誤差項是一維的,所以就是1,優化量就是abc,所以就是3.
資料處理完之后就可以用Solve進行求解,通過Option進行設定使用linearSearch還是TrustRegion,
以下是對應的結構還是很接近我們設定的abc的,a=1,b=2,c=1
estimate model=0.890912 2.1719 0.943629
實踐二、g2o
它是基于圖優化的庫,圖優化是一種把非線性優化和圖論結合起來的理論,我們先需要知道一些圖優化理論,
我門已經介紹了非線性最小二乘的求解方法,他們是由許多個誤差項之和組成的,然而僅有一組優化變數和有許多個誤差項,我們不清楚他們之間的關聯,我們希望能夠看到優化問題長什么樣,
圖優化,是把優化問題表現成圖的一種方式,這里的圖是圖論意義上的圖,由多個頂點以及連接著頂點的邊組成,用點來表示優化變數,用邊來表示誤差項,
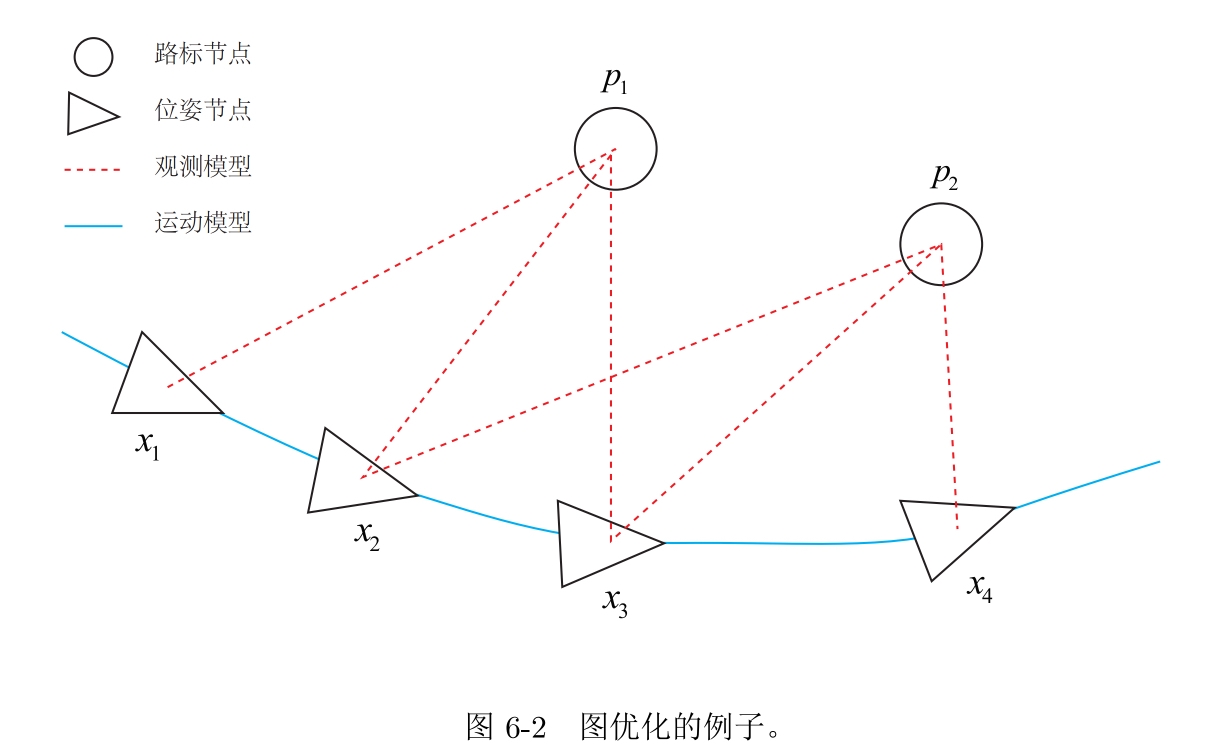
我們用三角形表示相機位姿節點,圓形表示路標點,他們就是圖優化的頂點,同時藍色的的線表示運動模型,紅色的虛線表示觀測模型,構成了圖優化的邊,雖然還是我們之前說的觀測方程以及運動方程,但我們更夠看到問題的結構,我們可以去掉孤立的點活優先優化邊數較多(度數較大,圖論中的術語)的頂點這樣的優化,
在上面實踐一的內容語境下,我們這里的優化變數abc就可以作為圖優化的頂點,而帶噪聲的資料點,就構成了一個個誤差項也就是對應的邊,
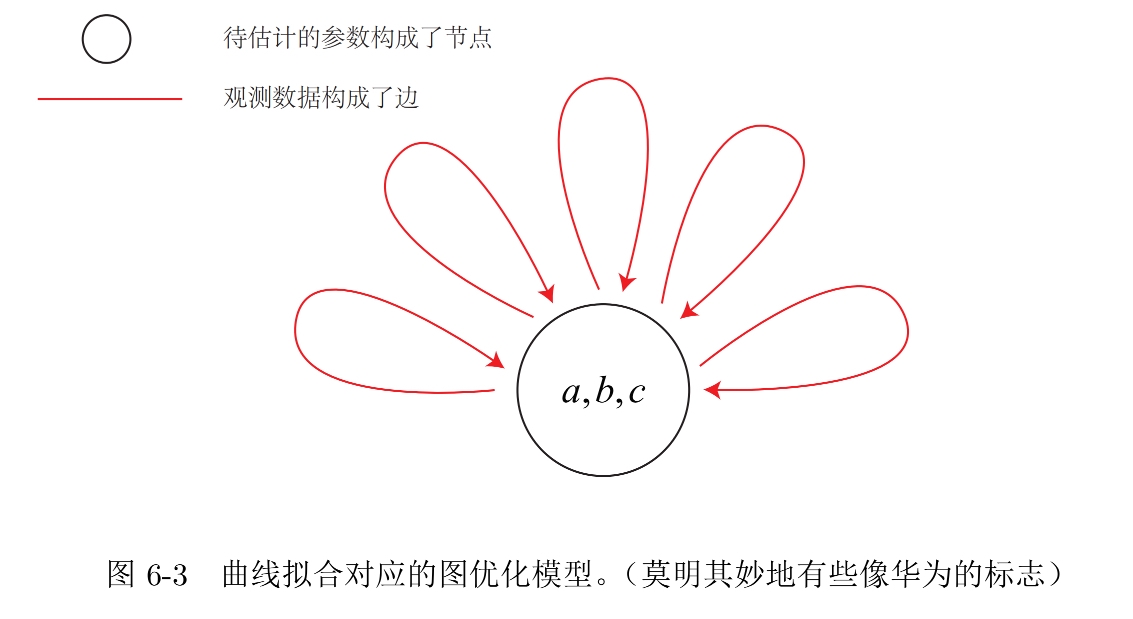
但是這里的邊是一元邊,即指鏈接一個頂點的,因為我們的圖只有一個頂點,實際上圖優化一條邊可以連接多個頂點也可以是一個,主要反映在每個誤差與多少個優化變數有關,我們把它叫做超邊,整個圖叫做超圖,
我們主要做的事情分為以下幾步:
1.定義頂點和邊的型別
2.構建圖
3.選擇優化演算法
4.呼叫g2o進行優化,回傳結果,
一樣先把對應的原始碼和配置放在這里,和原書上的不太一樣,因為版本問題,都可以百度得到,說不定以后又不適用了,淚目,
cmake_minimum_required(VERSION 2.8) project(g2o_curve_fitting) set(CMAKE_BUILD_TYPE Release) set(CMAKE_CXX_FLAGS "-std=c++14 -O3") list( APPEND CMAKE_MODULE_PATH ${PROJECT_SOURCE_DIR}/cmake_modules ) find_package(OpenCV REQUIRED) include_directories(${OpenCV_INCLUDE_DIRS}) find_package(G2O REQUIRED) include_directories(${G2O_INCLUDE_DIRS}) add_executable(g2o_curve_fitting main.cpp) target_link_libraries(g2o_curve_fitting ${OpenCV_LIBS} g2o_core g2o_stuff)View Code
這里使用的CMakeLists的方法需要將g2o檔案夾下面的cmake_modules檔案夾放到與build檔案夾同一目錄下,
#include<iostream> #include<g2o/core/base_vertex.h> #include<g2o/core/base_unary_edge.h> #include<g2o/core/block_solver.h> #include<g2o/core/optimization_algorithm_levenberg.h> #include<g2o/core/optimization_algorithm_gauss_newton.h> #include<g2o/core/optimization_algorithm_dogleg.h> #include<g2o/solvers/dense/linear_solver_dense.h> #include<Eigen/Core> #include<opencv2/core/core.hpp> #include<cmath> #include<chrono> using namespace std; class CurveFittingVertex: public g2o::BaseVertex<3, Eigen::Vector3d> { public: EIGEN_MAKE_ALIGNED_OPERATOR_NEW virtual void setToOriginImpl() { _estimate<< 0,0,0; } virtual void oplusImpl(const double* update) { _estimate+=Eigen::Vector3d(update); } virtual bool read(istream& in) {} virtual bool write(ostream& out) const {} }; class CurveFittingEdge:public g2o::BaseUnaryEdge<1, double, CurveFittingVertex> { public: EIGEN_MAKE_ALIGNED_OPERATOR_NEW CurveFittingEdge(double x):BaseUnaryEdge(), _x(x) {} void computeError(){ const CurveFittingVertex* v=static_cast<const CurveFittingVertex*>(_vertices[0]); const Eigen::Vector3d abc = v->estimate(); _error(0,0) = _measurement - std::exp(abc(0,0)*_x*_x + abc(1,0)*_x + abc(2,0)); } virtual bool read(istream& in) {} virtual bool write(ostream& out) const {} public: double _x; }; int main(int argc, char** argv) { double a=1.0, b=2.0, c=1.0; int N=100; double w_sigma=1.0; cv::RNG rng; double abc[3]={0,0,0}; vector<double> x_data, y_data; cout<<"generate data:"<<endl; for(int i=0; i<N; i++){ double x= i/100.0; x_data.push_back(x); y_data.push_back(exp(a*x*x+b*x+c)+rng.gaussian(w_sigma)); cout<<x_data[i]<<" "<<y_data[i]<<endl; } typedef g2o::BlockSolver<g2o::BlockSolverTraits<3,1>> Block; std::unique_ptr<Block::LinearSolverType> linearSolver(new g2o::LinearSolverDense<Block::PoseMatrixType>()); std::unique_ptr<Block> solver_ptr(new Block(std::move(linearSolver))); g2o::OptimizationAlgorithmLevenberg* solver=new g2o::OptimizationAlgorithmLevenberg(std::move(solver_ptr)); //g2o::OptimizationAlgorithmGaussNewton* solver= new g2o::OptimizationAlgorithmGaussNewton(std::move(solver_ptr)); //g2o::OptimizationAlgorithmDogleg* solver= new g2o::OptimizationAlgorithmDogleg(std::move(solver_ptr)); g2o::SparseOptimizer optimizer; optimizer.setAlgorithm(solver); optimizer.setVerbose(true); CurveFittingVertex* v=new CurveFittingVertex(); v->setEstimate(Eigen::Vector3d(0,0,0)); v->setId(0); optimizer.addVertex(v); for(int i=0; i<N; i++){ CurveFittingEdge* edge = new CurveFittingEdge(x_data[i]); edge->setId(i); edge->setVertex(0,v); edge->setMeasurement(y_data[i]); edge->setInformation(Eigen::Matrix<double, 1, 1>::Identity()*1/(w_sigma*w_sigma)); optimizer.addEdge(edge); } cout<<"start optimization"<<endl; chrono::steady_clock::time_point t1=chrono::steady_clock::now(); optimizer.initializeOptimization(); optimizer.optimize(100); chrono::steady_clock::time_point t2=chrono::steady_clock::now(); chrono::duration<double> time_used =chrono::duration_cast<chrono::duration<double>> (t2-t1); cout<<"solve time cost="<<time_used.count()<<"seconds."<<endl; Eigen::Vector3d abc_estimate = v->estimate(); cout<<"estimate model="<<abc_estimate.transpose()<<endl; return 0; }View Code
class CurveFittingVertex: public g2o::BaseVertex<3, Eigen::Vector3d> { public: EIGEN_MAKE_ALIGNED_OPERATOR_NEW virtual void setToOriginImpl() { _estimate<< 0,0,0; } virtual void oplusImpl(const double* update) { _estimate+=Eigen::Vector3d(update); } virtual bool read(istream& in) {} virtual bool write(ostream& out) const {} }; class CurveFittingEdge:public g2o::BaseUnaryEdge<1, double, CurveFittingVertex> { public: EIGEN_MAKE_ALIGNED_OPERATOR_NEW CurveFittingEdge(double x):BaseUnaryEdge(), _x(x) {} void computeError(){ const CurveFittingVertex* v=static_cast<const CurveFittingVertex*>(_vertices[0]); const Eigen::Vector3d abc = v->estimate(); _error(0,0) = _measurement - std::exp(abc(0,0)*_x*_x + abc(1,0)*_x + abc(2,0)); } virtual bool read(istream& in) {} virtual bool write(ostream& out) const {} public: double _x; };
可以看到,這里首先是構建了邊以及對應的點的型別,方便后面使用,實質上擴展了g2o的使用方法,
主要是重寫了oplusImpl(!!!一定要寫對)頂點的更新函式,我們知道要去計算Δx,而對應的函式就要進行頂點偏移的操作,我們需要重新定義這個程序的主要原因是當我們這個優化變數abc不處于向量空間中,比如說相機位姿,他不一定具有加法運算,就需要重新定義增量如何加到現有的估計上,就要用左乘或右乘,
setToOriginImpl頂點的重設函式,computeError是邊的誤差計算,該函式需要提取邊與所連線的頂點估計當前估計值,根據曲線模型與觀測點進行比較,和最小二乘問題一致,
這里提供了三種方法,
L-M: estimate model=0.890912 2.1719 0.943629
G-M: estimate model=0.890911 2.1719 0.943629
Dogleg: estimate model=0.890911 2.1719 0.943629
差距不大,可能要面對不同的問題才有結果,
總算是寫完啦,還需要繼續加油,感謝您看到這里,Cheers!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/228502.html
標籤:其他