什么是陣列
陣列(Array)是一種線性表資料結構,它用一組連續的記憶體空間,來存盤一組具有相同型別的資料,對于陣列,你要掌握兩個關鍵點,
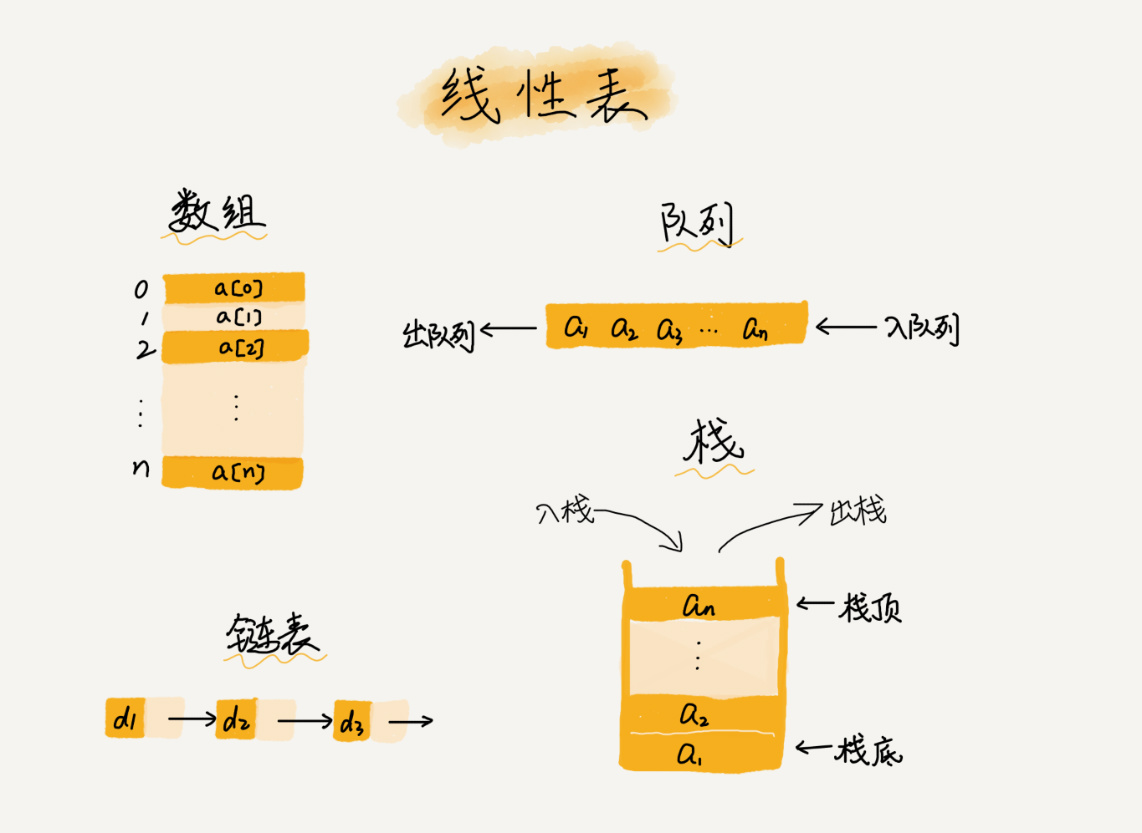
1. 線性表
線性表就是資料排成像一條線一樣的結構,每個線性表上的資料最多只有前和后兩個方向,其實除了陣列,鏈表、佇列、堆疊等也是線性表結構,
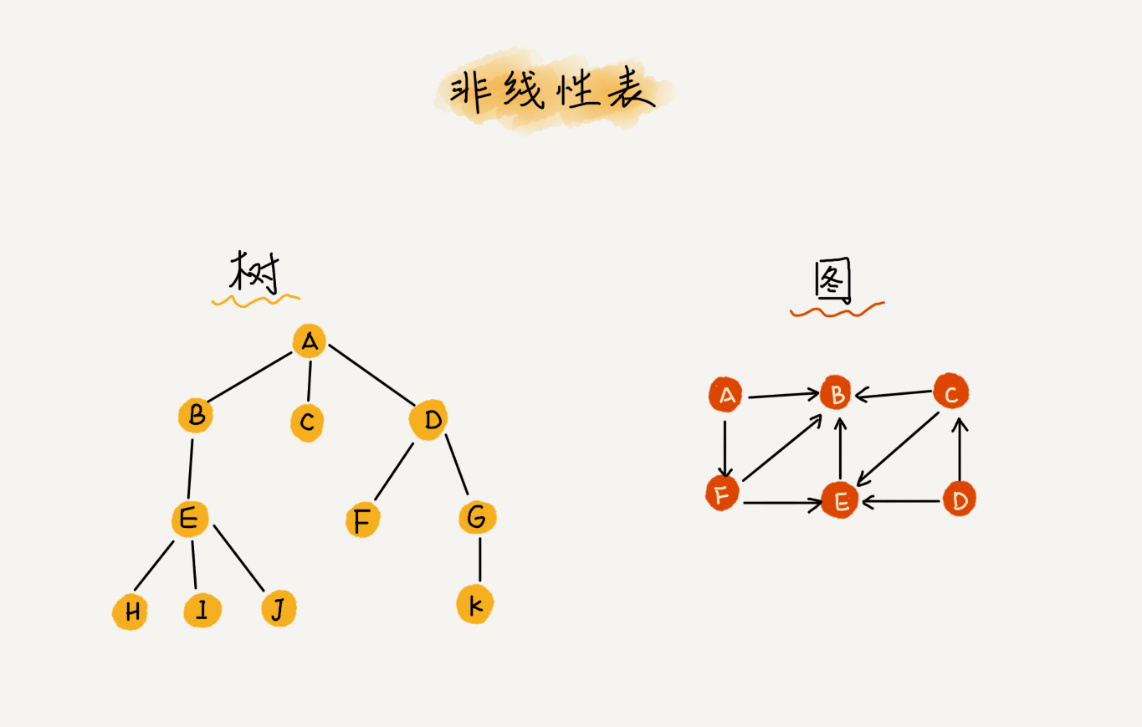
而與它相對立的概念是非線性表,比如二叉樹、堆、圖等,之所以叫非線性,是因為,在非線性表中,資料之間并不是簡單的前后關系,比如說下面樹形結構中的D節點就有三個方向的資料,
2. 連續的記憶體空間和相同型別的資料
陣列的存盤空間是連續的,而且必須存盤相同型別的資料,正是因為這兩個限制,它才有了一個堪稱“殺手锏”的特性:“隨機訪問”,但有利就有弊,這兩個限制也讓陣列的很多操作變得非常低效,比如要想在陣列中洗掉、插入一個資料,為了保證連續性,就需要做大量的資料搬移作業,
這邊解釋下隨機訪問的含義,隨機訪問是指通過元素的下標能立馬定位到元素在陣列中的位置,隨機查找的時間復雜度為O(1),
有的人可能把在陣列中查找元素和隨機訪問搞混了,在陣列中查找元素必須進行陣列遍歷,時間復雜度是O(n),即使是排序的陣列,通過二分查找,時間復雜度是O(logn),
低效的“插入”和“洗掉”
1. 插入操作
假設陣列的長度為 n,現在,如果我們需要將一個資料插入到陣列中的第 k 個位置,為了把第 k 個位置騰出來,給新來的資料,我們需要將第 k~n 這部分的元素都順序地往后挪一位,這個操作的時間復雜度是O(n),
如果陣列中的資料是有序的,我們在某個位置插入一個新的元素時,就必須按照剛才的方法搬移 k 之后的資料,但是,如果陣列中存盤的資料并沒有任何規律,陣列只是被當作一個存盤資料的集合,在這種情況下,如果要將某個資料插入到第 k 個位置,為了避免大規模的資料搬移,我們還有一個簡單的辦法就是,直接將第 k 位的資料搬移到陣列元素的最后,把新的元素直接放入第 k 個位置,
為了更好地理解,我們舉一個例子,假設陣列 a[10]中存盤了如下 5 個元素:a,b,c,d,e,我們現在需要將元素 x 插入到第 3 個位置,我們只需要將 c 放入到 a[5],將 a[2]賦值為 x 即可,最后,陣列中的元素如下: a,b,x,d,e,c,
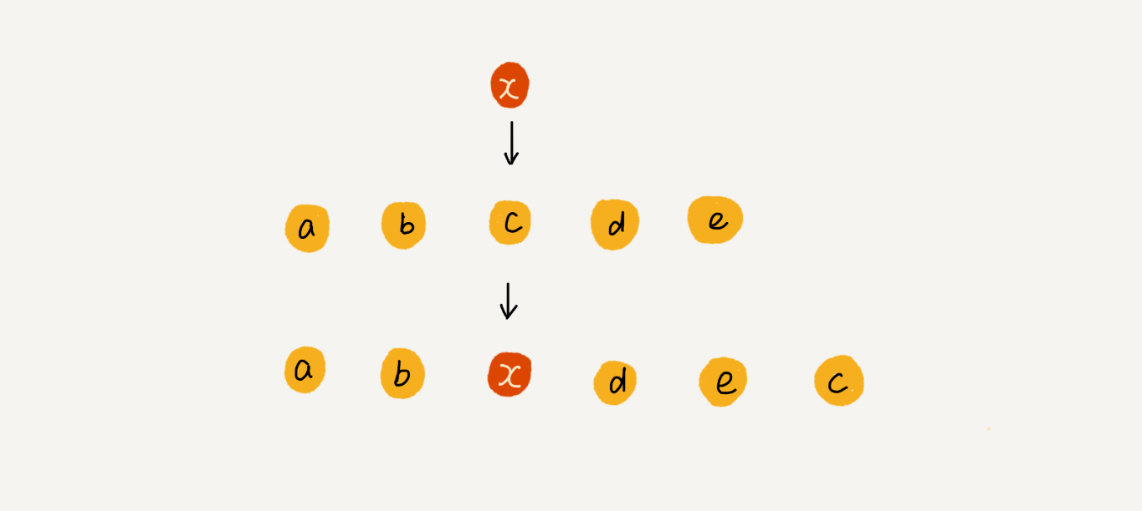
利用這種處理技巧,在特定場景下,在第 k 個位置插入一個元素的時間復雜度就會降為 O(1),(直接將指定位置的元素放到陣列最后一位后面array[array.length]=k)
2. 洗掉操作
跟插入資料類似,如果我們要洗掉第 k 個位置的資料,為了記憶體的連續性,也需要搬移資料,不然中間就會出現空洞,記憶體就不連續了,洗掉操作的時間復雜度也是O(n),
實際上,在某些特殊場景下,我們并不一定非得追求陣列中資料的連續性,如果我們將多次洗掉操作集中在一起執行,洗掉的效率是不是會提高很多呢?
我們繼續來看例子,陣列 a[10]中存盤了 8 個元素:a,b,c,d,e,f,g,h,現在,我們要依次洗掉 a,b,c 三個元素,
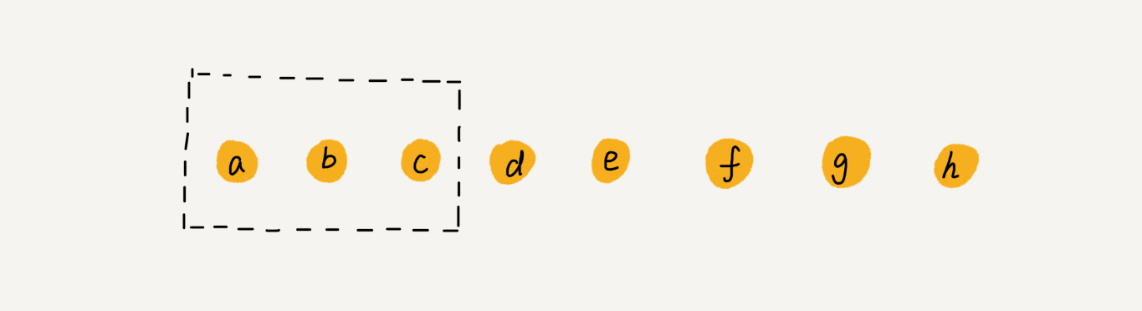
為了避免 d,e,f,g,h 這幾個資料會被搬移三次,我們可以先記錄下已經洗掉的資料,每次的洗掉操作并不是真正地搬移資料,只是記錄資料已經被洗掉,當陣列沒有更多空間存盤資料時,我們再觸發執行一次真正的洗掉操作,這樣就大大減少了洗掉操作導致的資料搬移,
如果你了解 JVM,你會發現,這不就是 JVM 標記清除垃圾回收演算法的核心思想,
關于陣列使用的幾個注意點
- 小心陣列越界訪問(一般在陣列的長度范圍內訪問陣列元素是沒什么問題的);
- 小心陣列元素為空,陣列某個下標位置上的值可能是空的,如果不做判斷的話可能會發生空指標例外,
怎么實作陣列這種資料結構
陣列是每個編程語言都會直接提供的資料結構,而且很多語言提供了更高級的容器實作,比如Java中的ArrayList,ArrayList 最大的優勢就是可以將很多陣列操作的細節封裝起來,比如前面提到的陣列插入、洗掉資料時需要搬移其他資料等,另外,它還有一個優勢,就是支持動態擴容,
陣列本身在定義的時候需要預先指定大小,因為需要分配連續的記憶體空間,如果我們申請了大小為 10 的陣列,當第 11 個資料需要存盤到陣列中時,我們就需要重新分配一塊更大的空間,將原來的資料復制過去,然后再將新的資料插入,
如果使用 ArrayList,我們就完全不需要關心底層的擴容邏輯,ArrayList 已經幫我們實作好了,每次存盤空間不夠的時候,它都會將空間自動擴容為 1.5 倍大小,
不過,這里需要注意一點,因為擴容操作涉及記憶體申請和資料搬移,是比較耗時的,所以,如果事先能確定需要存盤的資料大小,最好在創建 ArrayList 的時候事先指定資料大小,
作為高級語言編程者,是不是陣列就無用武之地了呢?當然不是,有些時候,用陣列會更合適些,我總結了幾點自己的經驗:
- Java ArrayList 無法存盤基本型別,比如 int、long,需要封裝為 Integer、Long 類,而 Autoboxing、Unboxing 則有一定的性能消耗,所以如果特別關注性能,或者希望使用基本型別,就可以選用陣列,
- 如果資料大小事先已知,并且對資料的操作非常簡單,用不到 ArrayList 提供的大部分方法,也可以直接使用陣列;
- 還有一個是我個人的喜好,當要表示多維陣列時,用陣列往往會更加直觀,比如 Object[][] array;而用容器的話則需要這樣定義:ArrayList > array;
對于業務開發,直接使用容器就足夠了,省時省力,畢竟損耗一丟丟性能,完全不會影響到系統整體的性能,但如果你是做一些非常底層的開發,比如開發網路框架,性能的優化需要做到極致,這個時候陣列就會優于容器,成為首選,
有趣的知識點
陣列的下標為什么從0開始?
其實陣列的下標更確切的表述是相對于首地址的偏移量,這樣更容易尋址,
從陣列存盤的記憶體模型上來看,“下標”最確切的定義應該是“偏移(offset)”,前面也講到,如果用 a 來表示陣列的首地址,a[0]就是偏移為 0 的位置,也就是首地址,a[k]就表示偏移 k 個 type_size 的位置,所以計算 a[k]的記憶體地址只需要用這個公式: a[k]_address = base_address + k * type_size 但是,如果陣列從 1 開始計數,那我們計算陣列元素 a[k]的記憶體地址就會變為: a[k]_address = base_address + (k-1)*type_size
一些網友留言
1. 陣列的一些其他應用
陣列的應用真的很多,比如redis的內部實作,壓縮鏈表,快速鏈表,還有后來搞出一個緊湊串列來替代壓縮串列,而且很多自定義協議都是用陣列做的,比如rocketmq的協議,前面幾位代表什么,后面幾位代表什么,
2. 標記清除法
標記清除具體步驟如下:
- 開始標記并程式暫停(stop the world);
- 找到所有可達物件,并做上標記;
- 標記完成后開始清除未標記的物件;
- 清除完成;
其實所有的垃圾收集演算法都可以分為:標記階段和收集階段,只是不同的垃圾回識訓制在這兩個階段使用的演算法不一樣,
標記清除法帶來的問題
- STW (stop the world) 標記物件的時候程式需要暫停,導致程式出現卡頓,如果經常進行STW操作,程式性能將大幅下降;
- 標記需要掃描整個堆;
- 清除物件會產生堆碎片,
STW指的是JVM把所有執行緒都暫停了,這樣所有的物件都不會被修改,這個時候去掃描是絕對安全的,
3. 畫圖軟體推薦
ipad Paper
4.分代收集法
分代收集演算法(針對JDK1.8以下):
根據物件的存活周期分為老年代,新生代,永久代
a、在新生代中,每次GC時都發現有大批物件死去,只有少量存活,使用復制演算法,即在垃圾回收時,將正在使用的記憶體中存活物件復制到另一塊未使用的記憶體中,之后清理正在使用的記憶體中所有物件,交換兩塊記憶體角色,反復進行,完成垃圾回收,
b、在老年代中,因為物件存活率高、沒有額外空間對他進行分配擔保,使用“標記-清理”/“標記-整理”演算法,即在標記階段,遍歷所有的GC Roots,然后將所有GC Roots可達的物件標記為存活的物件,清除階段,清除的程序將遍歷堆中所有的物件,將沒有標記的物件全部清除掉,
c、永久代(Permanet Generation)/ 元空間(Metaspace)
永久代用于存盤已被虛擬機加載的類資訊、常量、靜態變數、即時編譯后的代碼等資料,是JVM規范中方法區的具體實作,
是Hotspot虛擬機特有的概念,方法區/永久代是非堆記憶體,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/228727.html
標籤:其他
上一篇:四因數