1 方案介紹
大資料處理技術現今已廣泛應用于各個行業,為業務解決海量存盤和海量分析的需求,但資料量的爆發式增長,對資料處理能力提出了更大的挑戰,同時對時效性也提出了更高的要求,實時分析已成為企業大資料分析中最關鍵的術語,這意味企業可將所有資料用于大資料實時分析,實作在資料接受同時即刻為企業生成分析報告,從而在第一時間作出市場判斷與決策,典型的場景如電商大促和金融風控等,基于延遲資料的分析結果已經失去了價值,另外隨著云原生時代的到來,云原生天生具有的高效部署、敏捷迭代、云計算資源成本和彈性擴展等優勢,正在加速和縮短業務系統落地程序,云原生同樣可助力大資料這一程序,
本文主要介紹如何利用 Kubernetes 實作云原生大資料實時分析平臺,
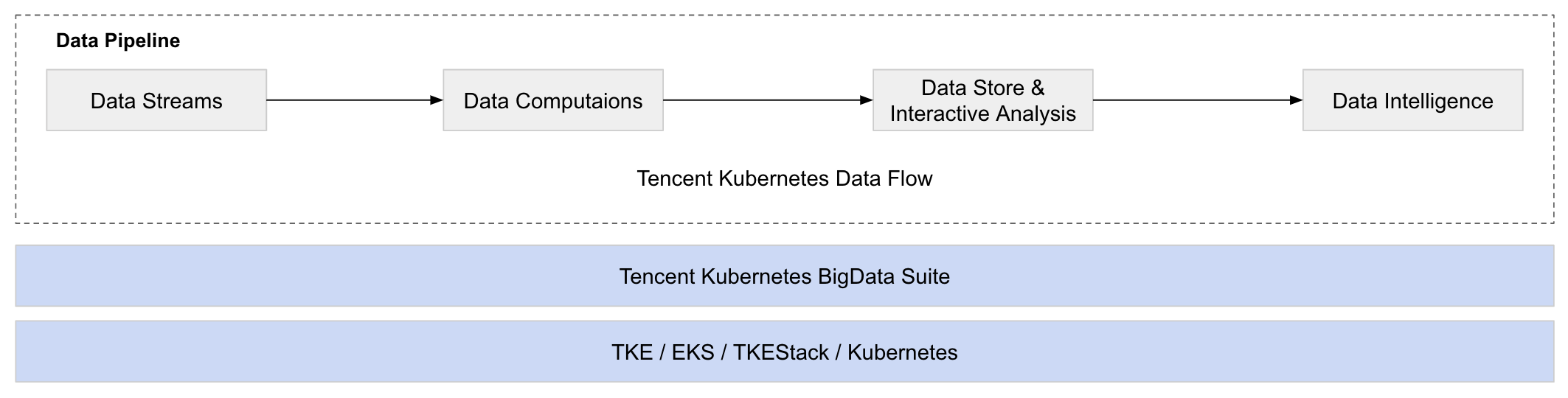
2 總體架構
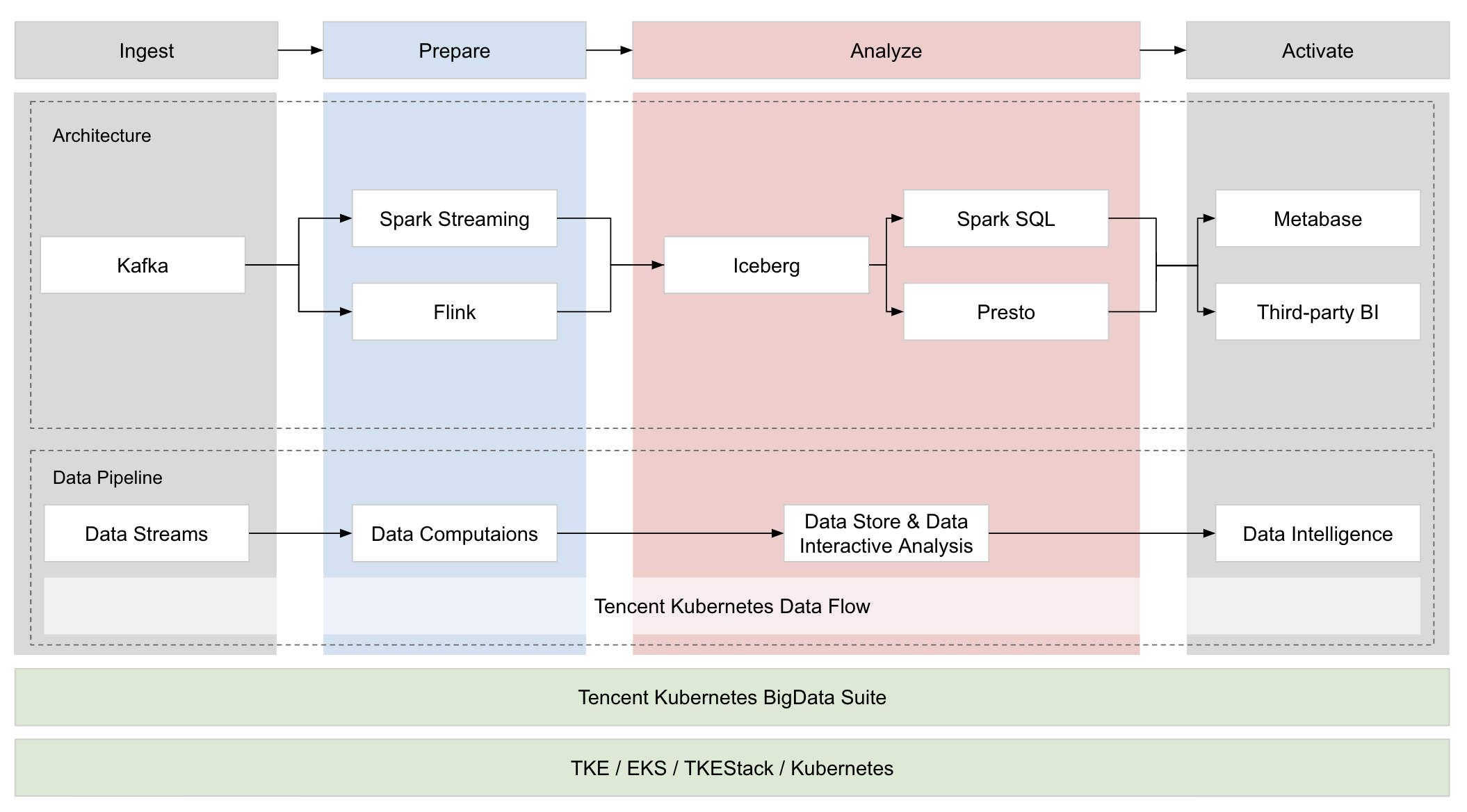
- Data Streams:基于 Kafka 的資料流接入方案
- Data Computations:基于 Spark Streaming 與 Flink 的流計算方案
- Data Pipeline:基于 TKDF(Tencent Kubernetes Data Flow) 的資料作業流方案
- Data Store:基于 Iceberg 與 HDFS 的資料湖方案
- Data Interactive Analysis:基于 Spark SQL 與 Presto 的 SQL 互動式分析方案
- Data Intelligence:基于 Metabase 的資料可視化方案以及若干資料接入方式
- Data Infrastructure:基于 TKBS(Tencent Kubernetes Bigdata Suite)的云原生大資料套件方案,可幫助用戶一鍵在 Kubernetes 上部署生產可用的大資料平臺;基于 TKE / EKS / TKEStack 的 Kubernetes 引擎方案,可為用戶提供生產、管控和使用 Kubernetes 集群服務
3 資料接入流
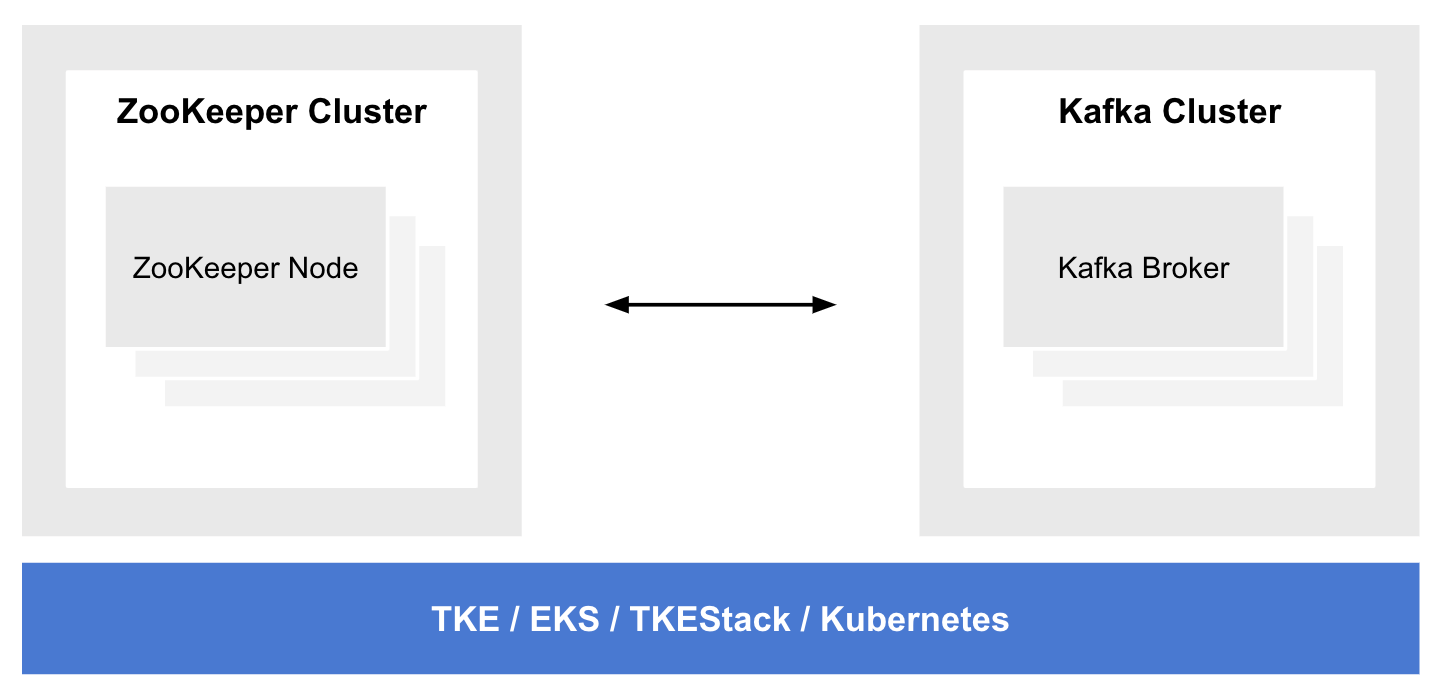
在實時分析中,需要持續、快速、實時地接受源源不斷的資料與事件,作為整個分析平臺的資料來源與入口,這個程序最好是基于流的、高吞吐、可擴展、可對接主流計算引擎,我們選擇 Apache Kafka 作為事件流處理的解決方案,
Apache Kafka 是一個分布式流處理平臺,被很多公司廣泛使用于資料管道、流分析、資料集成,訊息中間件等領域,Kafka 適合場景包括:
- 訊息佇列:構造實時流資料管道,它可以在系統或應用之間可靠地獲取資料
- 流處理:構建實時流式應用程式,對這些流資料進行轉換或者影響
Apache Kafka 可通過容器化部署在 Kubernetes,充分利用 Kubernetes 資源自動部署、自動擴展、一次配置任意運行等能力做到云原生賦能,
4 資料計算
在傳統的資料處理流程中,總是先收集資料,然后將資料放到資料庫中,當人們需要的時候通過資料庫對資料做查詢,得到答案或進行相關的處理,這樣看起來雖然非常合理,但是結果卻非常的緊湊,尤其是在一些實時搜索應用環境中的某些具體問題,類似于 MapReduce 方式的離線處理并不能很好地解決問題,這就引出了一種新的資料計算結構 - 流計算方式,它可以很好地對大規模流動資料在不斷變化的運動程序中實時地進行分析,捕捉到可能有用的資訊,并把結果發送到下一計算節點,
在云原生下,我們將流計算引擎容器化和遷移到 Kubernetes 上,利用 Kubernetes 自動化部署、HPA 等能力實作計算資源動態創建、調度與伸縮,云原生賦予了流計算即拿即用資源的能力,

當前主流的流計算引擎均可順暢的運行在 Kubernetes 之上,
4.1 Spark on Kubernetes
Spark 在 2.3 之后,支持將集群創建和托管到 Kubernetes 中,以 native 方式運行,
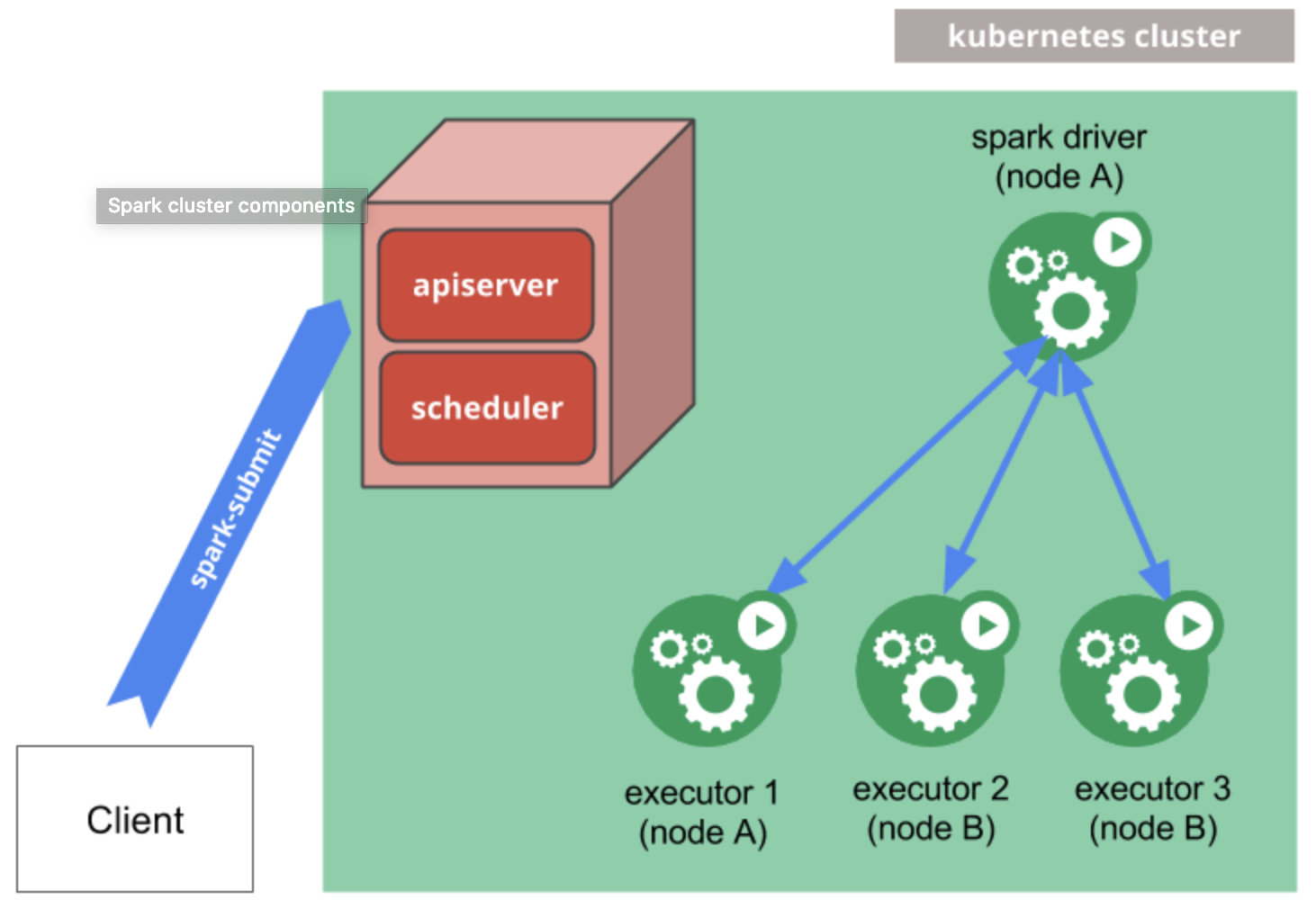
Kubernetes 可幫助 Spark 任務分配和管理計算資源,提供網路和存盤,管理任務生命周期,動態的橫向擴展能力,以及連接 Kubernetes 生態其他服務的能力,
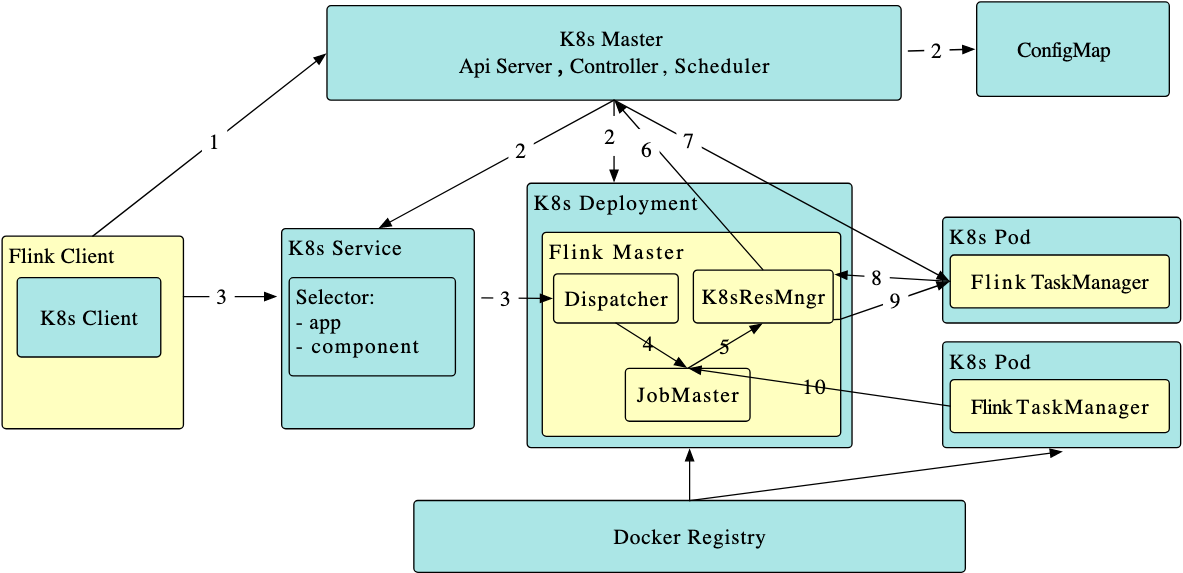
4.2 Flink on Kubernetes
Flink 在 Kubernetes 上支持 standalone 與 native 兩種模式,standalone 相當于利用 Kubernetes Deployment、Service、Configmap 等在 Kubernetes 上創建一個完整 Flink 集群,native 方式類似 Spark native,是通過內置于 Flink Client 的 K8s Client 與 Kubernetes 集群互動,負責組件資源的創建和銷毀,Flink 新引入的 Application 模式,更是可以在提交 Job 的同時動態創建 Flink 集群,
5 資料作業流
資料作業流(Data Pipeline)可以理解為一個貫穿資料產品或資料系統的管道,而資料就是管道載體的運輸物件,資料作業流連接了資料處理分析的各個環節,將整個龐雜的系統變得井然有序,便于管理和擴展,
我們根據生產經驗,設計和研發了基于云原生的資料作業流方案 TKDF,以幫助用戶集中精力從資料中獲取所需要的資訊,而不是把精力花費在管理日常資料和管理資料庫方面,
TKDF 有以下優勢:
- 基于云原生
- YAML 宣告式定義
- 支持主流資料源
- 介面式封裝,可插件化增加新的資料源實作
- 完整的資料生命周期管理
- 原生支持 Spark Streaming
- 計算模型抽象,支持基數統計近似、漏斗模型、模糊計算、產品運營指標等
6 資料湖
現今大資料存盤和處理需求越來越多樣化,在后 Hadoop 時代,如何構建一個統一的資料湖存盤,并在其上進行多種形式的資料分析,成了企業構建大資料生態的一個重要方向,怎樣快速、一致、原子性地在資料湖存盤上構建起 Data Pipeline,成了亟待解決的問題,并且伴隨云原生時代到來,云原生天生具有的自動化部署和交付能力也正催化這一程序,
基于 Hadoop 的云原生資料湖
傳統方式下,用戶在部署和運維大資料平臺時通常采用手動或半自動化方式,這往往消耗大量人力,穩定性也無法保證,Kubernetes 的出現,革新了這一程序,Kubernetes 提供了應用部署和運維標準化能力,用戶業務在實施 Kubernetes 化改造后,可運行在其他所有標準 Kubernetes 集群中,在大資料領域,這種能力可幫助用戶快速部署和交付大資料平臺(大資料組件部署尤為復雜),尤其在大資料計算存盤分離的架構中,Kubernetes 集群提供的 Serverless 能力,可幫助用戶即拿即用的運行計算任務,并且再配合離在線混部方案,除了可做到資源統一管控降低復雜度和風險外,集群利用率也會進一步提升,大幅降低成本,
我們使用 TKBS 在 Kubernetes 上構建 Hadoop 資料湖:

基于 Iceberg 的云原生實時資料湖
Apache Iceberg is an open table format for huge analytic datasets. Iceberg adds tables to Presto and Spark that use a high-performance format that works just like a SQL table.
Apache Iceberg 是由 Netflix 開發開源的,其于2018年11月16日進入 Apache 范訓器,是 Netflix 公司資料倉庫基礎,Iceberg 本質上是一種專為海量分析設計的表格式標準,可為主流計算引擎如 Presto、Spark 等提供高性能的讀寫和元資料管理能力,Iceberg 不關注底層存盤(如 HDFS)與表結構(業務定義),它為兩者之間提供了一個抽象層,將資料與元資料組織了起來,
Iceberg 主要特性包括:
- ACID:具備 ACID 能力,支持 row level update/delete;支持 serializable isolation 與 multiple concurrent writers
- Table Evolution:支持 inplace table evolution(schema & partition),可像 SQL 一樣操作 table schema;支持 hidden partitioning,用戶無需顯示指定
- 介面通用化:為上層資料處理引擎提供豐富的表操作介面;屏蔽底層資料存盤格式差異,提供對 Parquet、ORC 和 Avro 格式支持
依賴以上特性,Iceberg 可幫助用戶低成本的實作 T+0 級資料湖,我們使用 Iceberg + HDFS 的方式在 Kubernetes 上構建云原生資料湖,

我們使用 Kubernetes 負責應用自動化部署與資源管理調度,為上層屏蔽底層環境復雜性,通過 TKBS 一鍵式部署云原生資料湖,Iceberg + HDFS 實作了基于 Hadoop 生態的實時資料湖,為大資料應用提供資料訪問及存盤能力,Spark、Flink、Presto 等計算引擎以 native 或 standalone 方式運行于 Kubernetes 集群中,資源可隨提交任務即拿即用,與在線業務混部后,更能大幅提升集群資源利用率,
- Resource Layer:使用 Kubernetes 提供資源管控能力
- Data Access Layer:使用 Iceberg 提供 ACID、table 等資料集訪問操作能力
- Data Storage Layer:使用 HDFS 提供資料存盤能力
- Data Computation Layer:使用 Spark / Flink / Presto on Kubernetes 提供流批計算能力或實作 SQL 引擎
7 互動式分析
實時分析除了持續實時分析外(Continuous real-time analytics),還包括互動式分析(On-demand real-time analytics),互動式分析是一種反應式分析方法,用戶通過查詢獲取分析結果(比如輸入 SQL 陳述句),我們采用 SQL 陳述句作為互動式查詢陳述句,支持 Spark SQL 與 Presto 兩種 SQL 查詢引擎,
7.1 Presto on Kubernetes
Presto 是由 Facebook 開源的分布式 SQL 查詢引擎,專門為互動式查詢所設計,提供分鐘級乃至亞秒級低延時的查詢性能,它既可支持非關系資料源,例如 HDFS、Amazon S3、Cassandra、MongoDB 和 HBase,又可支持關系資料源,例如 MySQL、PostgreSQL、Amazon Redshift、Microsoft SQL Server 和 Teradata,
Presto 查詢引擎是 Master-Slave 架構,由一個 Coordinator節點,一個 Discovery Server 節點,多個 Worker 節點組成,
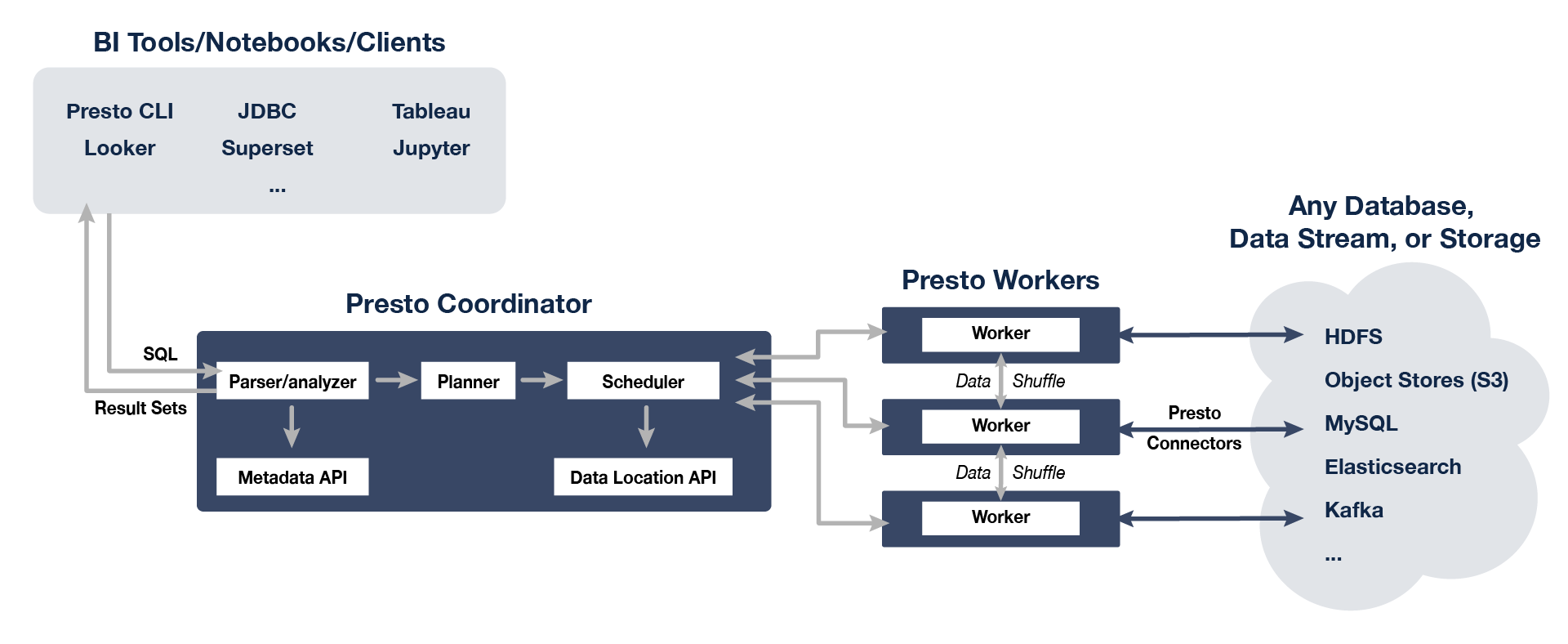
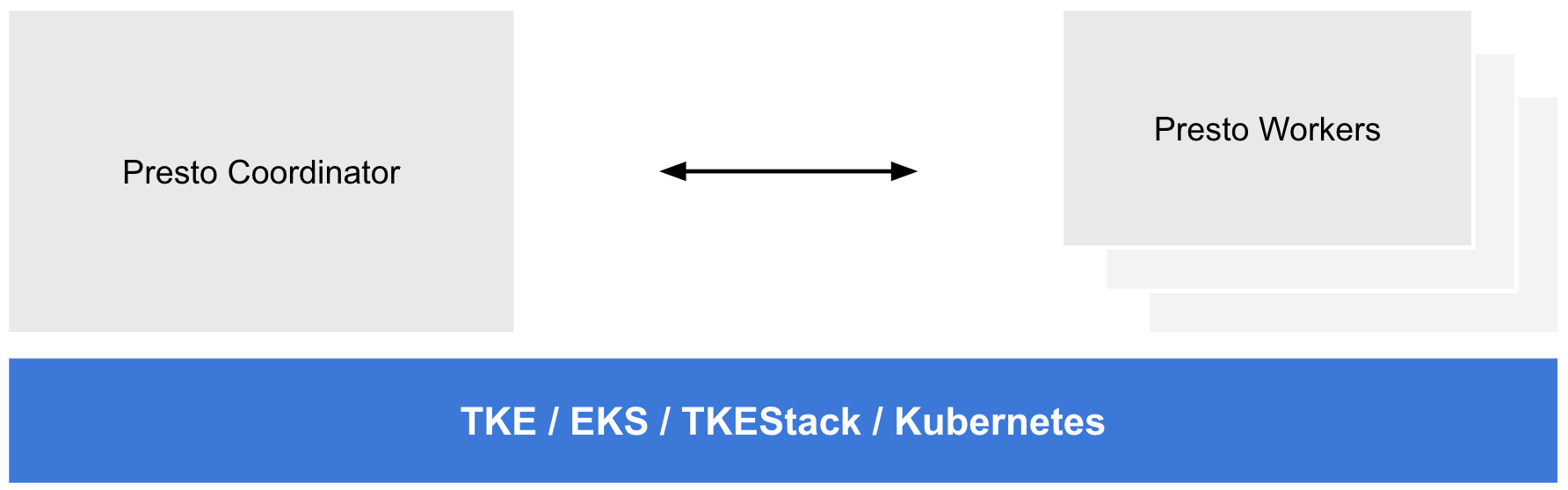
我們通過 standalone 方式將 Presto 集群部署在 Kubernetes 上:
7.2 Spark SQL on Kubernetes
Spark SQL 是 Spark 結構化資料的執行模塊,可支持使用 SQL 在 Spark 查詢分析結構化資料 DataFrames、Datasets,我們同樣支持使用 Spark SQL 作為互動式分析引擎,將執行的 Spark 任務以 native 方式運行在 Kubernetes 上,
8 資料智能分析
我們正處于大資料和數字化轉型的時代,資料無處不在,運用資料驅動的思想和策略在實踐中逐漸成為共識,資料的價值已在科學研究和工商業的不同領域得到充分展現,資料智能工具和技術的應用可以幫助決策者更好地理解所收集的資訊,從而開發出更好的業務流程,我們通過提供資料介面與接入外部 BI 來達成這一目的,
8.1 資料介面
我們通過以下方式提供互動式入口或資料介面,以幫助用戶使用或接入第三方系統:
- 圖形化界面:基于 Metabase 的開源 BI 系統
- JDBC 介面:通過 Spark Thrift Server 或 Presto JDBC Driver 的連接
- 命令列介面:通過 Spark SQL CLI 或 Presto CLI 連接
8.2 資料可視化
Metabase 是一個開源的商業智能工具,你可以向它提出關于資料的問題(資料查詢),而獲取有意義的格式化結果(圖形化視圖),我們可通過它理解資料、分析資料,以資料驅動決策,
Metabase 支持諸多資料源及計算引擎接入:

我們利用官方提供的 Helm 包,可以方便的將 Metabase 部署于 Kubernetes 上,
9 資料基礎設施
9.1 TKBS
TKBS(Tencent Kubernetes Bigdata Suite)是我們根據生產經驗開發的云原生大資料套件專案,用戶可使用 TKBS 一鍵在 Kubernetes 上部署生產可用的大資料平臺,TKBS 當前已支持 Hadoop 主要組件以及主流大資料組件的部署,
TKBS 主要特點如下:
- 兼容社區:支持原生 Kubernetes
- 一鍵部署:采用 Helm 應用化封裝
- 云原生增強:與騰訊云 TKE、EKS、CBS、CLB、COS 和 CHDFS 等云服務深度整合;支持開源 TKEStack
- 存算分離:支持存盤計算分離架構
- 自動擴縮容:支持自動 HPA 和 CA,節省運營成本
- 離在線混部:支持與在線業務混合部署,提升資源利用率
9.2 TKE / EKS / TKEStack
我們使用騰訊云 TKE / EKS 或開源 TKEStack 幫助我們生產和管理 Kubernetes 集群,
- TKE:騰訊云容器服務(Tencent Kubernetes Engine ,TKE)基于原生 kubernetes 提供以容器為核心的、高度可擴展的高性能容器管理服務
- EKS:騰訊云彈性容器服務(Elastic Kubernetes Service,EKS)是騰訊云容器服務推出的無須用戶購買節點即可部署作業負載的服務模式
- TKEStack:騰訊云 TKE 團隊開源的一款集強壯性和易用性于一身的企業級容器編排引擎,以極簡的向導式界面提供了容器應用的全生命周期管理能力,幫助用戶在私有云環境中敏捷、高效地構建和發布應用程式
10 結尾
云原生的到來不止為大資料部署和交付帶來了變革,它更是幫助大資料連接了一個生態,利用云原生生態,真正做到了為大資料賦予云的能力,使得大資料可以“生長在云端”,另外,云原生在大資料領域的應用,也同樣幫助云原生拓展了能力邊界,豐富了落地場景,為未來“Everything native on Cloud”打下夯實基礎,
TKBS 已上線騰訊云 TKE 應用市場,下個版本會加入對實時分析完整方案與 TKDF 的支持,我們希望憑借基于 TKBS 與 TKDF 的大資料實時分析方案,可以幫助用戶縮短大資料交付程序,簡化大資料系統部署與運維復雜度,讓用戶聚焦在挖掘資料價值本身,另一方面,借助云原生架構,我們希望能幫助用戶的大資料業務與云發生聯系,為用戶帶來更多的可能性,幫助用戶創造更多的價值,
生于云上,為云而生!
【騰訊云原生】云說新品、云研新術、云游新活、云賞資訊,掃碼關注同名公眾號,及時獲取更多干貨!!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/228765.html
標籤:其他