廢話不多說,首先上個圖:

下面我們開始進入Spark RDD的部分學習,
1、RDD創建
首先我們要學會從哪里創建一個RDD,前面的我的文章已經說了,RDD是彈性分布式資料集,本質上是一個只讀的磁區記錄集合,每個RDD又被分成了若干個磁區,并且不同的磁區存在不同的節點上,從而可以進行分布式并行計算,提高程式的執行效率,
RDD提供了一種高度受限的共享記憶體模型,即RDD是只讀的記錄磁區的集合,不能直接修改,只能基于穩定的物理存盤中的資料集來創建RDD或者通過在其他的RDD上執行確定的轉換操作(map、join、groupBy)而創建的得到新的RDD,
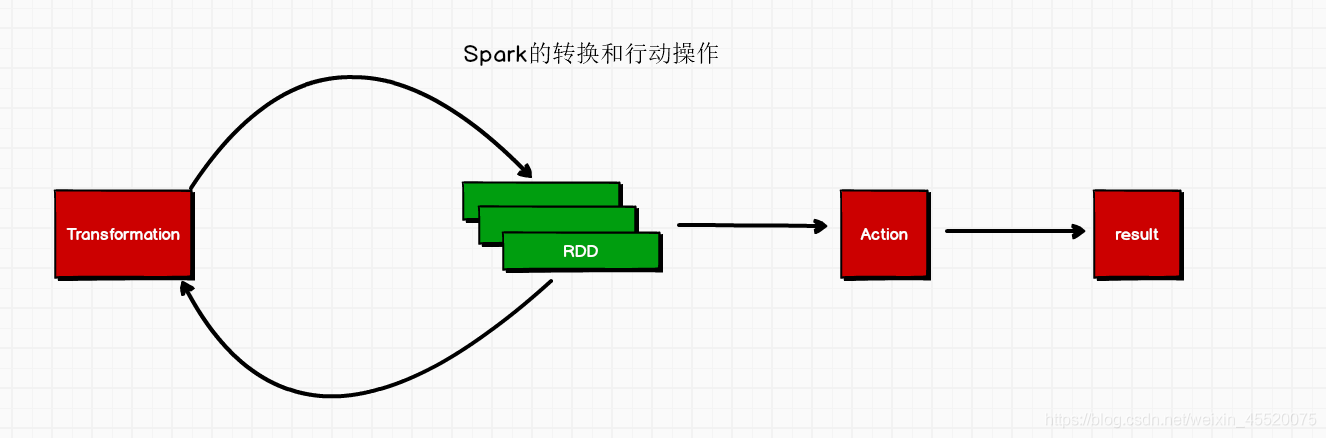
RDD有兩種資料運算形式:”行動“算子 和 “轉換”算子,其中“轉換”算子用于構建RDD之間的依賴關系,“行動”算子用于執行計算并指定輸出的形式,
RDD典型的執行程序如下:
- RDD從外部檔案讀取資料,或者通過記憶體中已經有的集合進行創建
- RDD經過一系列的轉換操作,每一次操作都會產生新的RDD,構建了依賴關系,并不會執行,
- RDD的執行操作需要Action算子去觸發從頭到尾的運算,結果輸出或者保存至檔案,
First: 一般在linux打開spark-shell互動環境,已經創建了SparkContext背景關系物件 sc
在SparkContext類中定義了一個textFile方法,看看下面的原始碼:
/**
* Read a text file from HDFS, a local file system (available on all nodes), or any
* Hadoop-supported file system URI, and return it as an RDD of Strings.
*/
def textFile(
path: String,
minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {
assertNotStopped()
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text],
minPartitions).map(pair => pair._2.toString).setName(path)
}
explain: 從HDFS檔案系統,本地檔案系統讀取一個檔案形成一個RDD,里面的RDD型別是一行一行的字串型別的元素,首先我們看第一個引數 path:String 毫無疑問這是指定檔案的路徑,第二個引數是最小磁區數,等會進行分析,
比如從HDFS檔案系統有個檔案people.txt,我們可以這樣寫:
object Spark02_Oper1 {
def main(args: Array[String]): Unit = {
//這里是創建sparkconf物件,傳入SparkContext構造方法中
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//創建sc
val sc = new SparkContext(config)
//從外部檔案中加載資料創建RDD
val wordRDD: RDD[String] = sc.textFile("/in/word.txt")
}
}
還可以通過陣列、集合創建RDD,sc.parallzlize(陣列或者串列)
Second: 下面介紹RDD轉換算子常用的操作API,檔案word.txt內容如下:

2、轉換算子
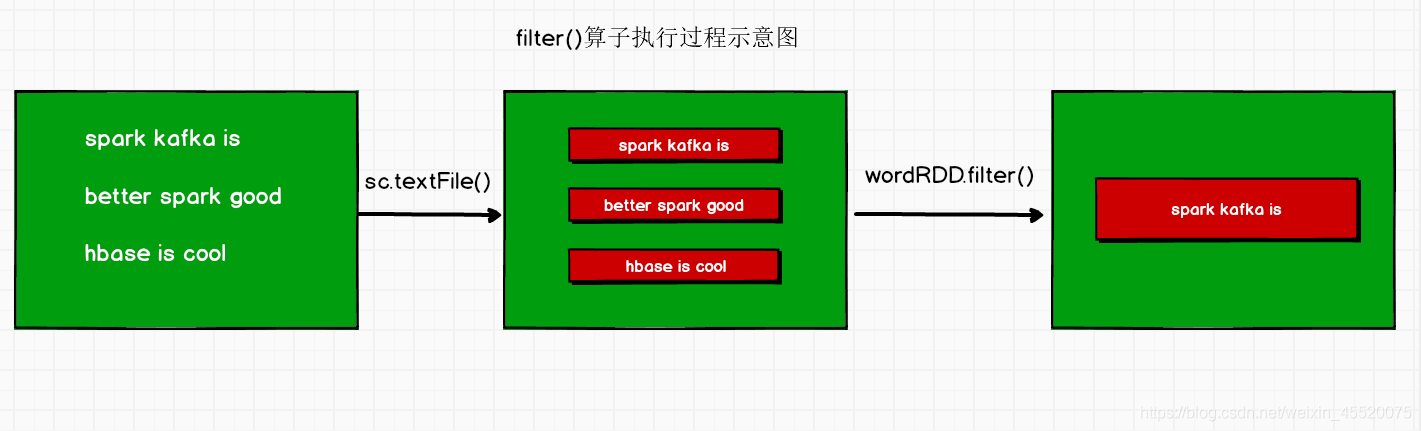
- filter(function)
val wordRDD: RDD[String] = sc.textFile("in/word.txt")
val linesRDD: RDD[String] = wordRDD.filter(line => line.contains("kafka"))
textFile方法會把word.txt這個檔案加載并且形成一個RDD,這個RDD中有很多元素,每個元素的型別都是String型別,每個RDD元素是一行文本內容,line=>line.contains(“kafka”)這是一個運算式,這代碼的意思就是依次取出RDD的每一個元素,過濾掉不包含"kafka"這個單詞的元素,把包含的加入到新的RDD中,最終形成了一個新的RDD,
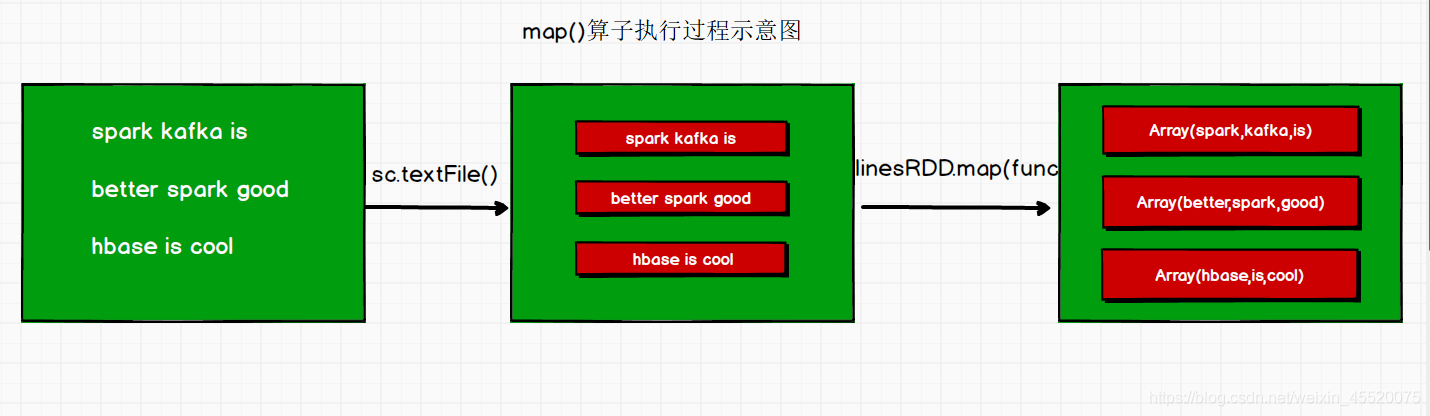
- map(function)
val lines: RDD[String] = sc.textFile("in/word.txt")
val lineRDD: RDD[Array[String]] = lines.map(line => line.split(" "))
line => line.split(" ")是一個運算式,含義是:依次取出RDD中的每個元素,賦給line這個變數,然后對這個變數進行分割按照空格,作為函式的的回傳值,并作為一個元素放到新的RDD中,
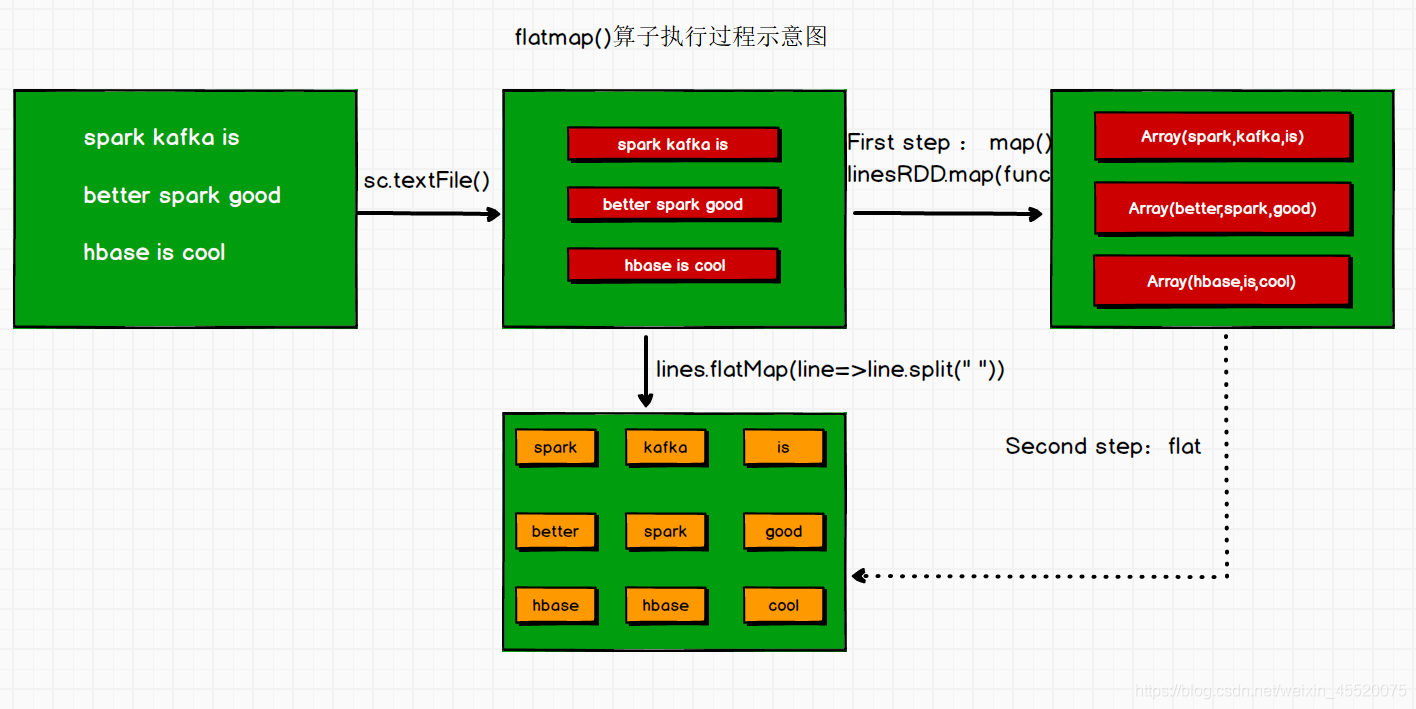
- flatMap(function) `
val lines: RDD[String] = sc.textFile("in/word.txt")
val wordsRDD: RDD[String] = lines.flatMap(line=>line.split(" "))
在上一步map()的基礎上將Array中的元素"拍扁"形成多個元素,最終被“拍扁”后的元素形成一個RDD,例如linesRDD中的第一個元素是Array(spark,kafka,is),拍扁之后會形成三個元即"spark",“kafka”,“is”,
所以就形成了9個String元素的RDD,
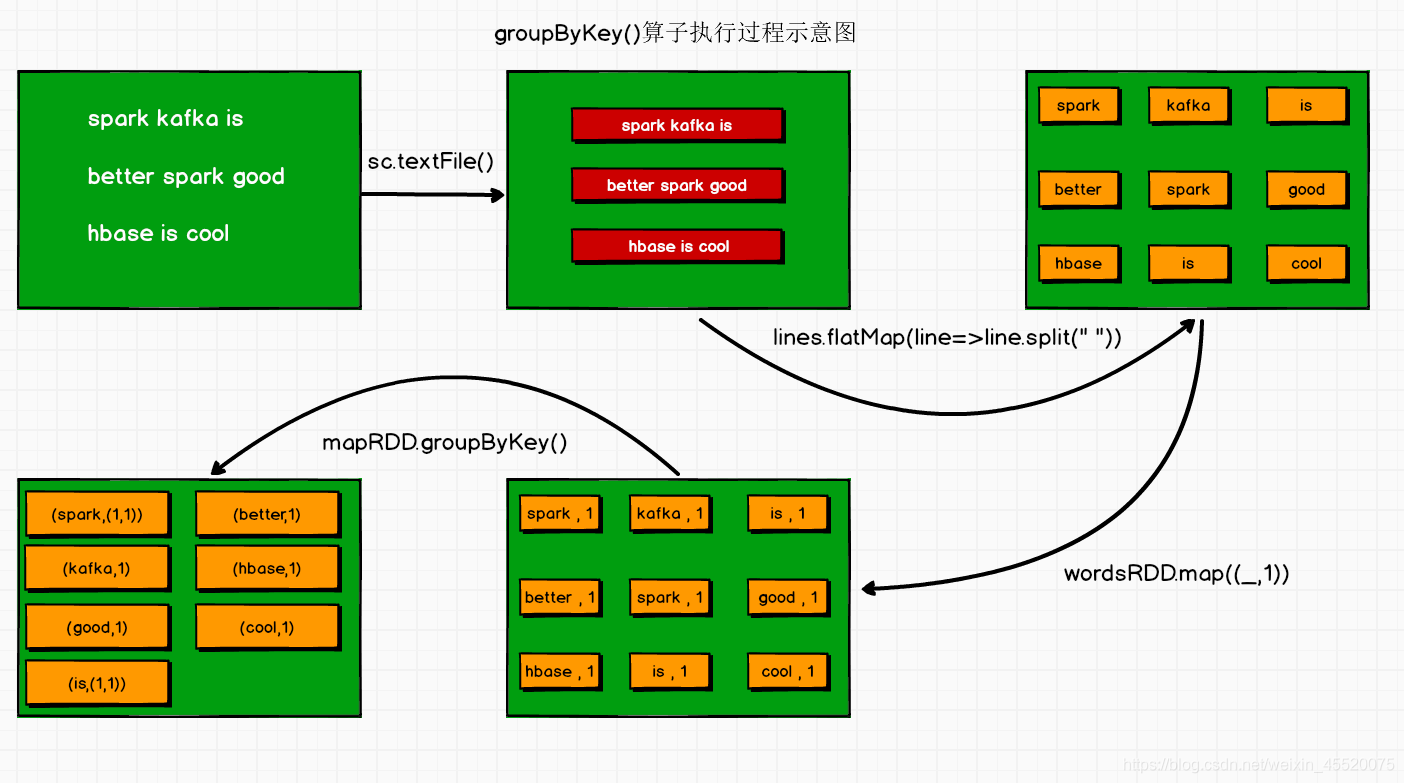
- groupByKey()
groupByKey()應用于(K,V)鍵值對的資料集時,回傳一個新的(K,Iterable)形式的資料集,首先將每個元素轉換成(_,1)的形式,然后將相同Key的value歸并到一起,value形成一個Iterable,
val lines: RDD[String] = sc.textFile("in/word.txt")
val wordsRDD: RDD[String] = lines.flatMap(line=>line.split(" "))
val mapRDD: RDD[(String, Int)] = wordsRDD.map((_,1))
val groupwords: RDD[(String, Iterable[Int])] = mapRDD.groupByKey()
groupwords.collect().foreach(println)
直接結果如下:
(is,CompactBuffer(1, 1))
(better,CompactBuffer(1))
(kafka,CompactBuffer(1))
(cool,CompactBuffer(1))
(spark,CompactBuffer(1, 1))
(good,CompactBuffer(1))
(hbase,CompactBuffer(1))
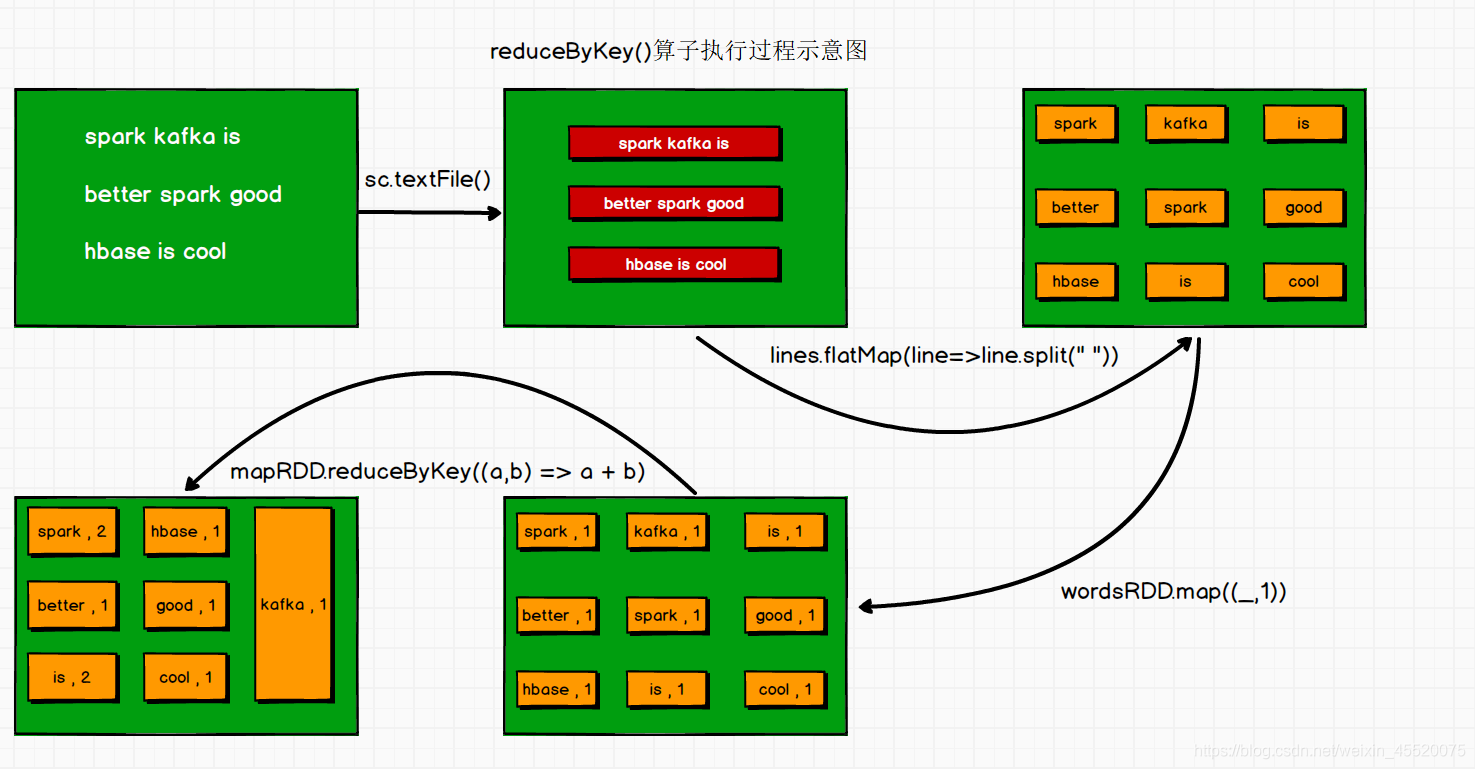
- reduceByKey(function)
reduceByKey(function)應用于(K,V)鍵值對的資料集時,回傳一個新的(K,V)形式的資料集,
val lines: RDD[String] = sc.textFile("in/word.txt")
val wordsRDD: RDD[String] = lines.flatMap(line=>line.split(" "))
val mapRDD: RDD[(String, Int)] = wordsRDD.map((_,1))
val resultRDD: RDD[(String, Int)] = mapRDD.reduceByKey((a,b) => a + b)
resultRDD.collect().foreach(println)
執行結果如下:
(is,2)
(better,1)
(kafka,1)
(cool,1)
(spark,2)
(good,1)
(hbase,1)
mapRDD.reduceByKey((a,b) => a + b)操作執行以后,所有key相同的鍵值對,他們的value就會被歸并到一起,value是一個value-list,通過運算式聚合到一起(a,b) => a + b的含義是:取出的value第一個值賦值給a,第二個value賦值給b,然后相加的結果賦值給引數a,再把第三個value賦值給b,依次執行下去,最后聚合的結果就是這個單詞出現個數的鍵值對型別,
3、行動算子
常用的RDD行動操作API

行動是真正觸發計算的地方,Spark應用程式只有執行到行動操作的時候,才會執行真正的計算,從檔案中加載讀取資料,完成一次又一次的轉換操作,最終,完成行動操作得到結果,
到這里一般的算子就結束了,畫了這么久的流程圖,會使自己更熟悉算子的各種功能,加深自己的印象,大家在學習框架的程序中,應該要多畫流程圖,加深自己的印象,
大家點個👍吧!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/229127.html
標籤:其他