C語言位元組對齊
什么是位元組對齊
現代計算機中記憶體空間都是按照byte劃分的,從理論上講似乎對任何型別的變數的訪問可以從任何地址開始,但實際情況是在訪問特定型別變數的時候經常在特定的記憶體地址訪問,這就需要各種型別資料按照一定的規則在空間上排列,而不是順序的一個接一個的排放,這就是對齊,
為什么要位元組對齊
■ 平臺原因(移植原因): 不是所有的硬體平臺都能訪問任意地址上的任意資料的;某些硬體平臺只能在某些地址處取某些特定型別的資料,否則拋出硬體例外,
■ 性能原因: 資料結構(尤其是堆疊)應該盡可能地在自然邊界上對齊, 原因在于,為了訪問未對齊的記憶體,處理器需要作兩次記憶體訪問;而對齊的記憶體訪問僅需要一次訪問,
總結:實際就是用
空間換時間,為了達到更快的對變數的訪問速度,
位元組對齊的四個關鍵概念
■ 基本資料型別的自身對齊值,
■ 程式的指定對齊值:即#pragma pack(value)時的指定對齊值value,(默認#pragma pack(8),其中value=2^n)
■ 自定義型別的自身對齊值:結構體或類的成員中自身對齊值最大的值,
■ 自定義型別的有效對齊值:自定義型別的自身對齊值和程式指定對齊值中較小的值,min=(程式指定對齊值,自定義型別對齊值)
注:自定義型別的有效對齊值最關鍵,
#pragma pack(4)
struct test
{
char a; // 1
short b;// 2
char c; // 1
};
//上述結構體test的自身對齊值為2(b的自身對齊值),而指定對齊值為4(32位編譯器默認值),故最終的有效對齊值為2.
當位元組沒有對齊時,我們會在記憶體中添加一些位元組(不使用)來達到位元組對齊的效果,添加要點:
■ 當前型別的位元組對齊值+添加位元組+之前所有型別大小總和=下一個基本資料型別的自身對齊值與程式的指定對齊值中的最小值的倍數(min=(下一個基本資料型別,程式指定的對齊值))
■ 對于最后一個型別的位元組對齊值+添加位元組+之前所有型別大小總和=自定義型別的有效對齊值的倍數
【舉例】
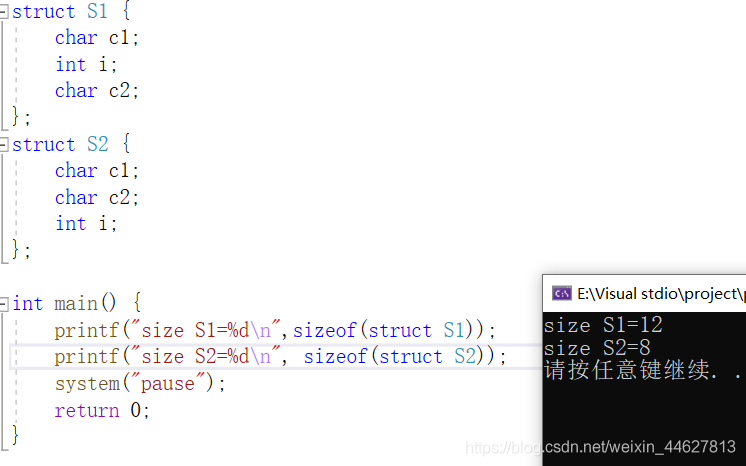
S1和S2型別的成員一模一樣,但是S1和S2所占空間的大小有了一些區別,
//舉例說明
struct S1 {
char c1; //1+3 注:當前型別(char)自身對齊值為1要是下一個型別的有效值4(min=(#pragma pack(8),int))的倍數所以最少要補3個位元組
int i; //4 注:因為當前型別自身對齊值為4是下一個型別的有效值1(min=(#pragma pack(8),char))的倍數所以不用補位元組
char c2; //1+3 注:要滿足S1的整體大小滿足自定義型別的有效對齊值(4=min(8,4)) 默認#pragma pack(8)的倍數所以還需要補3個位元組
};
struct S2 {
char c1;//1 注:當前型別(char)自身對齊值為1是下一個型別(char)的自身對齊值1的倍數所以不用添加
char c2;//1+2 注:當前型別自身對齊值為1+之前所有型別大小1+添加位元組總和是下一個型別的自身對齊值4的倍數所以最少要補2個位元組
int i;//4
};
int main() {
printf("%d\n",sizeof(struct S1));//12
printf("%d\n", sizeof(struct S2));//8
system("pause");
return 0;
}
記憶體分配效果:
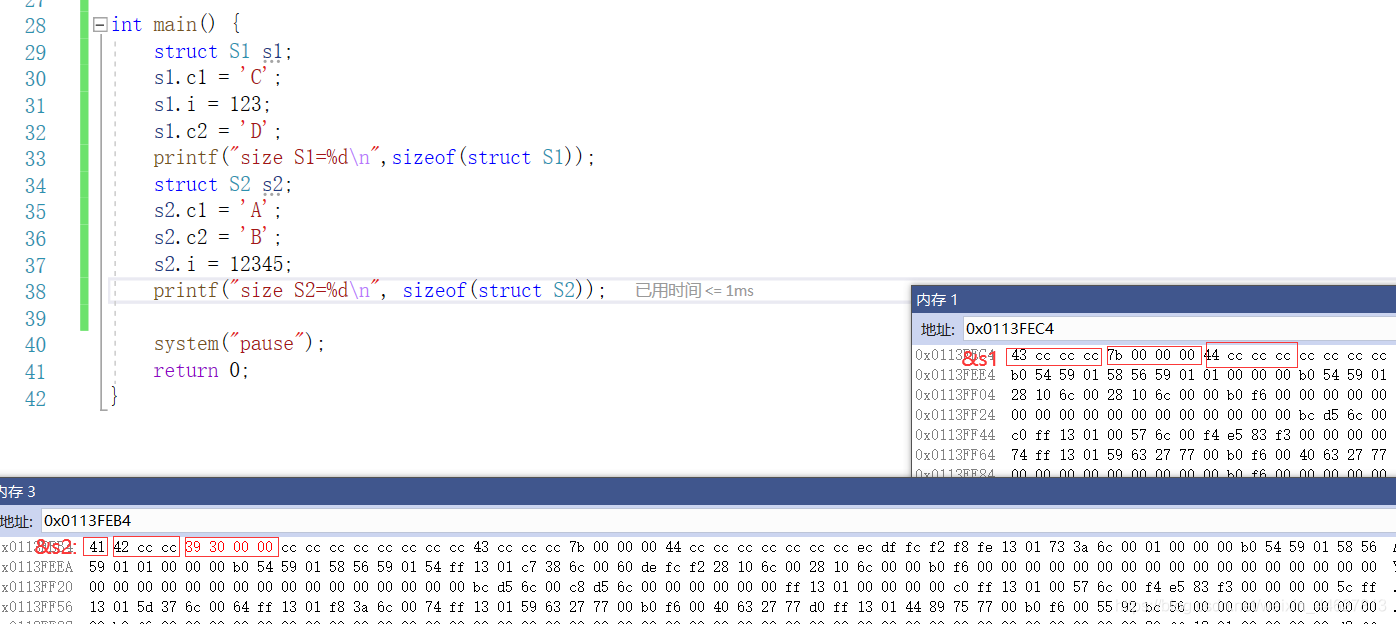
結論:讓占用空間小的成員盡量集中在一起,
修改默認對齊數
#pragma pack(1)
struct S1 {
char c1;
int i;
char c2;
};
struct S2 {
char c1;
char c2;
int i;
};
int main()
{
//輸出的結果是什么?
printf("%d\n", sizeof(struct S1));
printf("%d\n", sizeof(struct S2));
return 0;
}
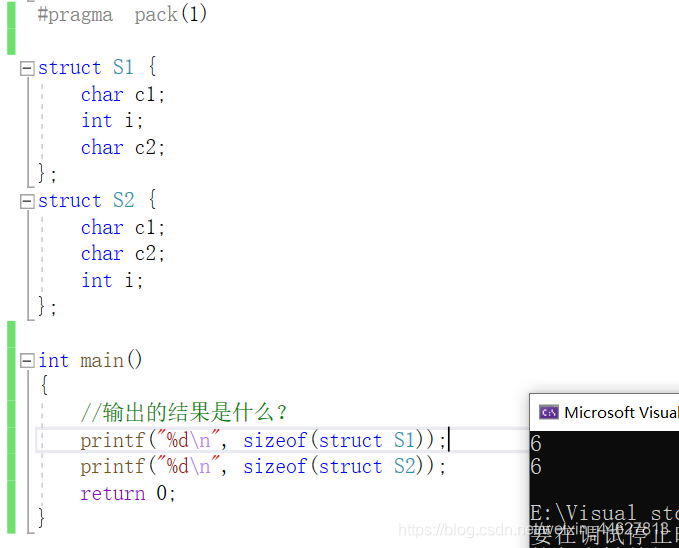
結論:結構在對齊方式不合適的時候,我們可以自己更改默認對齊數,當指定#pragma pack(1),結構體的不管怎么排列有效值都為1,這時結構體大小就是各個型別的位元組大小相加,
【練習】
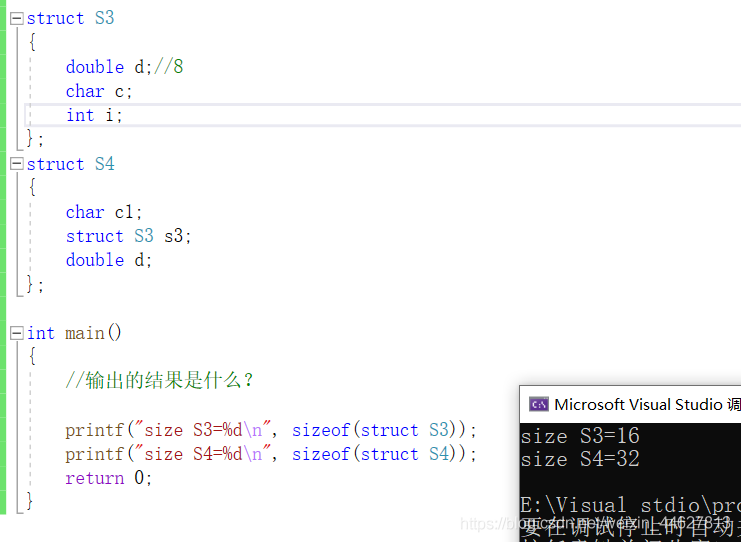
struct S3
{
double d;//8
char c; //1+3 注:自身型別(char)對齊值為1+之前型別大小8=下一個型別的有效值4(min=(int,默認#pragma pack(8)))的倍數所以添加3個位元組
int i; //4 注:當前型別(int)對齊值4+之前所有型別12+添加位元組=自定義有效值對齊值(8)的倍數,因此不用添加
};
//自定義型別的自身對齊值:結構體或類的成員中自身對齊值最大的值,
struct S4
{
char c1;//1+7 注:自身型別(char)對齊值1要是下一個自定義型別的對齊值(S3成員中的自身對齊值最大的(double)=8)的倍數所以需要補7個位元組的空間,
struct S3 s3;//16
double d; //8
};
int main()
{
//輸出的結果是什么?
printf("size S3=%d\n", sizeof(struct S3)); //16
printf("size S4=%d\n", sizeof(struct S4)); //32
return 0;
}
結論:自定義型別的自身對齊值:結構體或類的成員中自身對齊值最大的值,
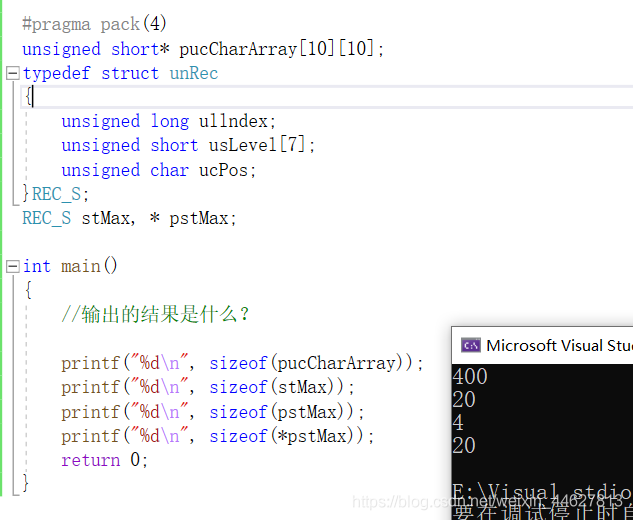
#pragma pack(4)
unsigned short* pucCharArray[10][10];
typedef struct unRec
{
unsigned long ullndex; //4 注:自身型別(long)對齊值4是下一個型別有效值(min=(short,#pragma pack(4)))的倍數因此不用添加位元組
unsigned short usLevel[7]; //14
unsigned char ucPos; //1 + 1 注:要達到結構體有效值4(min=(#pragma pack(4),long))的倍數所以還需要補一個位元組,
}REC_S;
REC_S stMax, * pstMax;
int main()
{
//輸出的結果是什么
printf("%d\n", sizeof(pucCharArray));//400 注:一個二維陣列,這個陣列有100個short *的指標,每個指標大小是4
printf("%d\n", sizeof(stMax)); //20
printf("%d\n", sizeof(pstMax)); //4
printf("%d\n", sizeof(*pstMax));//20
return 0;
}
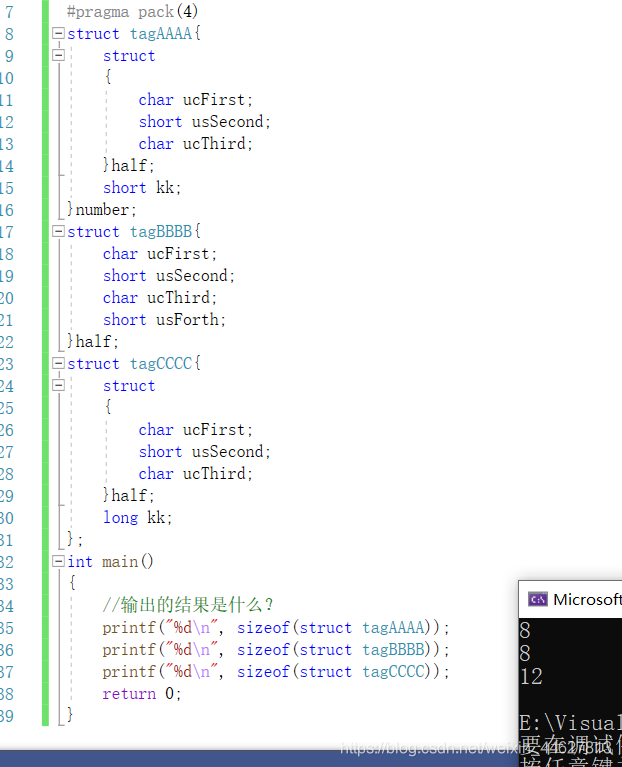
#pragma pack(4)
struct tagAAAA{
struct
{
char ucFirst; //1+1 注:自身型別(char)的對齊值1要是下一個型別有效值的2(min=(#pragma pack(4),short))倍數 因此補一個位元組
short usSecond; //2 注:自身型別(short)的對齊值2+之前所有的型別大小(2)+添加位元組=下一個型別有效值的1(min=(#pragma pack(4),char))倍數 所以不用添加位元組
char ucThird; //1+1 注:自身型別(char)的對齊值1+添加位元組+之前所有型別的大小4=該結構體有效值對齊值2(min=(short,#pragma pack(4)))的倍數 所以還需要添加一個位元組
}half;
short kk; //2 注: 自身型別(short)的對齊值2+之前所有型別的大小6+添加位元組=外層結構體有效值2(min=(short,#pragma pack(4)))的倍數所以不用添加位元組
}number;
struct tagBBBB{
char ucFirst; //1+1
short usSecond; //2
char ucThird; //1+1
short usForth; //2
}half;
struct tagCCCC{
struct
{
char ucFirst; //1+1
short usSecond; //2
char ucThird; //1+1
}half;
long kk; //4+2 注: 自身型別(long)的對齊值4+之前所有型別的大小6+添加位元組=外層結構體有效值4(min(max(long,short),#pragma pack(4)))的倍數所以所以還需要添加兩個位元組
};
int main()
{
//輸出的結果是什么?
printf("%d\n", sizeof(struct tagAAAA)); //8
printf("%d\n", sizeof(struct tagBBBB)); //8
printf("%d\n", sizeof(struct tagCCCC)); //12
return 0;
}
C語言位域
位域是指資訊在存盤時,并不需要占用一個完整的位元組, 而只需占幾個或一個二進制位,例如在存放一個開關量時,只有0和1 兩種狀態, 用一位二進位即可,為了節省存盤空間,并使處理簡便,C語言又提供了一種資料結構,稱為“位域”或“位段”,所謂“位域”是把一個位元組中的二進位劃分為幾個不同的區域, 并說明每個區域的位數,每個域有一個域名,允許在程式中按域名進行操作, 這樣就可以把幾個不同的物件用一個位元組的二進制位域來表示,
在結構內宣告位域的形式如下
struct
{
type [member_name] : width ;
};
下面是有關位域中變數元素的描述:
| 元素 | 描述 |
|---|---|
| type | 只能為 int(整型),unsigned int(無符號整型),signed int(有符號整型)或者是 char (屬于整形家族) 四種型別,決定了如何解釋位域的值, |
| member_name | 位域的名稱 |
| width | 位域中位的數量,寬度必須小于或等于指定型別的位寬度, |
上段代碼在記憶體中的存盤形式是:

位域存盤需要注意
■ 一個位域必須存盤在同一個位元組中,不能跨兩個位元組
■ 不能跨型別存盤,若跨型別需要考慮位元組對齊,這就違背了原本節約空間的本意了
■ 位域的長度不能大于指定型別固有長度,比如說int的位域長度不能超過32,char的位域長度不能超過8
■ 位域可以無位域名,這時它只用來作填充或調整位置,無名的位域是不能使用的
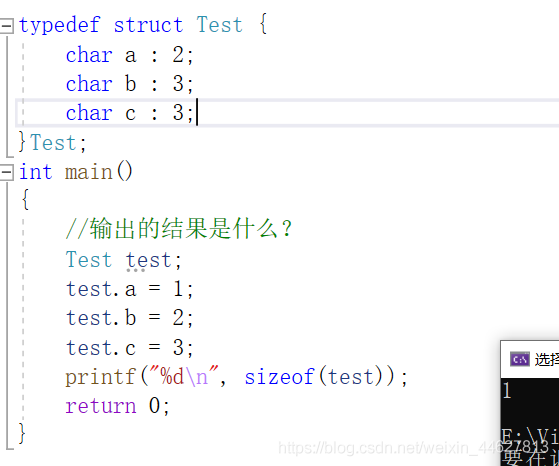
不能跨位元組存盤
typedef struct Test {
char a : 1;
char b : 6;
char c : 3; //存放在下一個位元組位元組
}Test;
Test test;
sizeof(test)=2;
不能跨型別存盤,若跨型別存盤要考慮位元組對齊
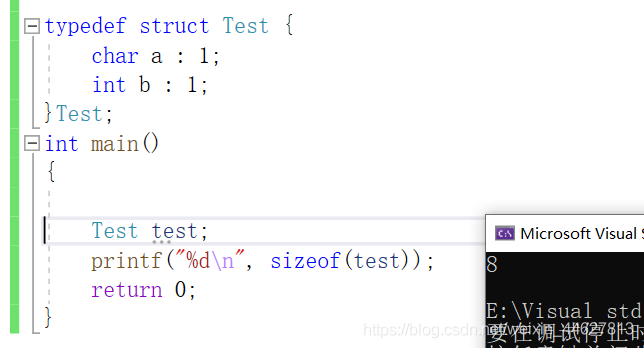
typedef struct Test {
char a : 1;
int b : 1;
}Test;
int main()
{
Test test;
printf("%d\n", sizeof(test));//8
return 0;
}
位域可以無位域名,這時它只用來作填充或調整位置,無名的位域是不能使用的,
struct k
{
int a : 1;
int : 2; /*該2位不能使用*/
int b : 3;
int c : 2;
};
【練習】
練習一:
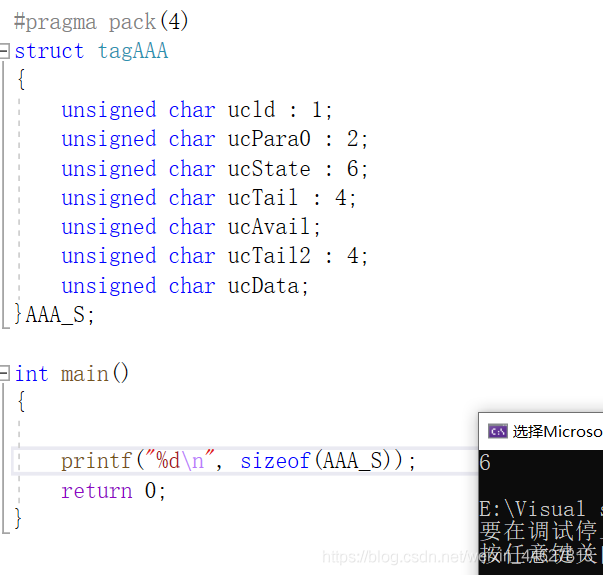
#pragma pack(4)
struct tagAAA
{
unsigned char ucld : 1;
unsigned char ucPara0 : 2; //1 注: ucld和ucPara0總共占一個位元組
unsigned char ucState : 6; //1
unsigned char ucTail : 4; //1
unsigned char ucAvail; //1
unsigned char ucTail2 : 4; //1
unsigned char ucData; //1
}AAA_S;
int main()
{
printf("%d\n", sizeof(AAA_S)); //6
return 0;
}
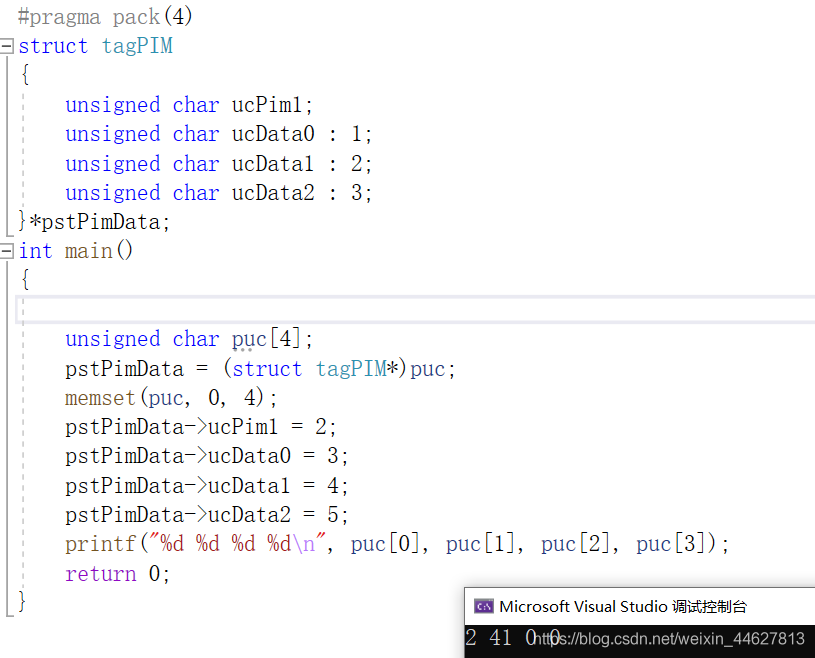
練習二:
#pragma pack(4)
struct tagPIM
{
unsigned char ucPim1;
unsigned char ucData0 : 1;
unsigned char ucData1 : 2;
unsigned char ucData2 : 3;
}*pstPimData;
int main()
{
int a = 1;
char* b = &a;
printf("%p\n", &a);
printf("%d\n", *b);
unsigned char puc[4];
pstPimData = (struct tagPIM*)puc;
memset(puc, 0, 4);
pstPimData->ucPim1 = 2;
pstPimData->ucData0 = 3;
pstPimData->ucData1 = 4;
pstPimData->ucData2 = 5;
printf("%d %d %d %d\n", puc[0], puc[1], puc[2], puc[3]);//2 41 0 0
return 0;
}
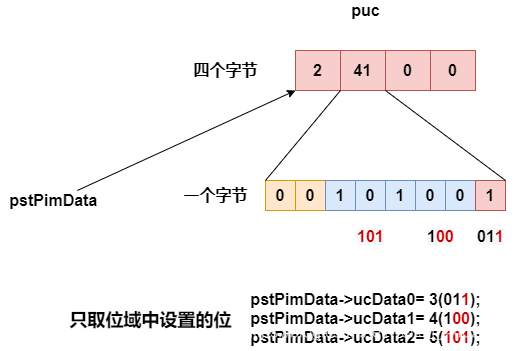
我們在取資料時,只取我們在位域中設定的位數,把多的位數去掉,
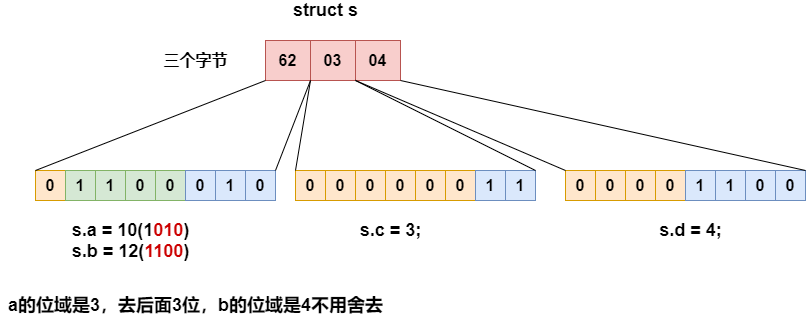
練習三:
struct S
{
char a : 3;
char b : 4; //1 注:a和b占一個位元組
char c : 5; //1 注:無法裝下c c占一個位元組
char d : 4; //1
};
int main()
{
struct S s = { 0 };
s.a = 10;
s.b = 12;
s.c = 3;
s.d = 4;
printf("size s=%d",sizeof(s));//3
return 0;
}
記憶體存盤
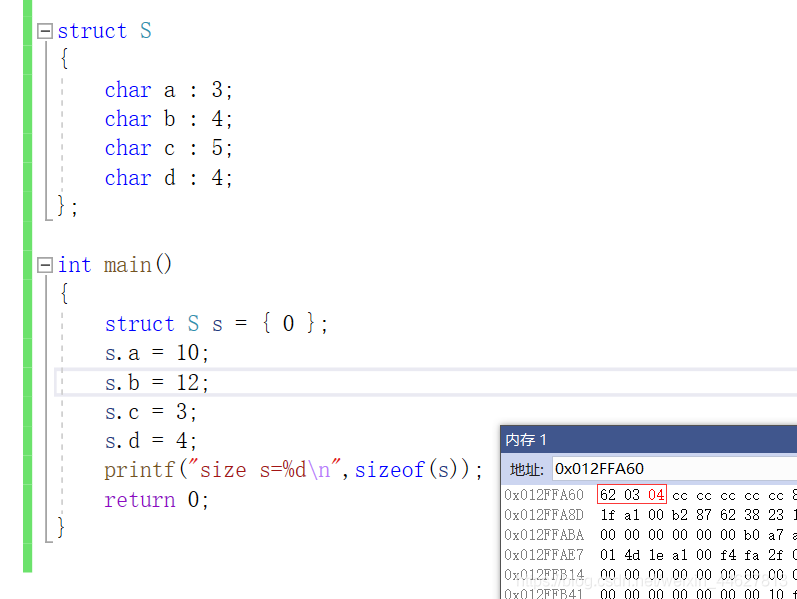
解釋:
列舉
列舉顧名思義就是一一列舉,把可能的取值一一列舉,
列舉的定義
列舉型別的定義
enum Day//星期
{
Mon,
Tues,
Wed,
Thur,
Fri,
Sat,
Sun
};//其中各個變數用逗號隔開,而結構體中的每個變數同分號隔開,
//以上定義的 enum Day是列舉型別, {}中的內容是列舉型別的可能取值,也叫列舉常量,
列舉型別的兩個特點
■列舉型別中的可能取值都是有值的,默認從0開始,一次遞增1,當然在定義的時候也可以賦初值,
■列舉型別的大小是4個位元組
【說明】
typedef enum Color//顏色
{
RED,
GREEN,
BLUE=10,
YELLOW,
BLACK
}Color;
int main()
{
printf("%d\n",RED);
printf("%d\n", GREEN);
printf("%d\n", BLUE);
printf("%d\n", YELLOW);
printf("%d\n", BLACK);
return 0;
}
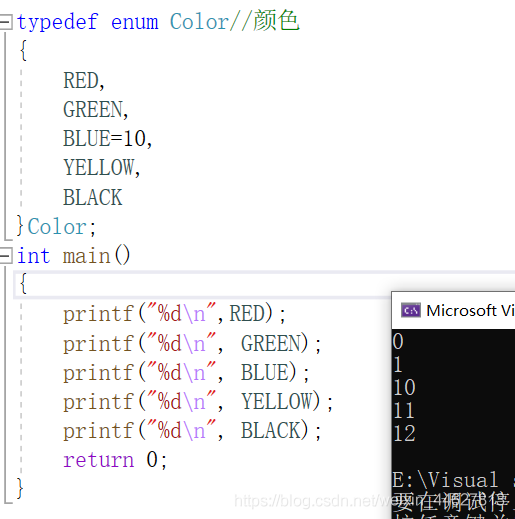
總:可能取值若定義了則取定義值,若未定義則是上一個值加1,第一個值若未定義則為0,
聯合(共用體)
共用體是一種特殊的資料型別,允許您在相同的記憶體位置存盤不同的資料型別,您可以定義一個帶有多成員的共用體,但是任何時候只能有一個成員帶有值,共用體提供了一種使用相同的記憶體位置的有效方式,
聯合型別的定義
//聯合型別的宣告
union Un
{
char c;
int i;
};//共用一個空間
聯合的特點
■ 聯合的成員是共用同一塊記憶體空間的,這樣一個聯合變數的大小,至少是最大成員的大小(因為聯合至少得有能力保存最大的那個成員),
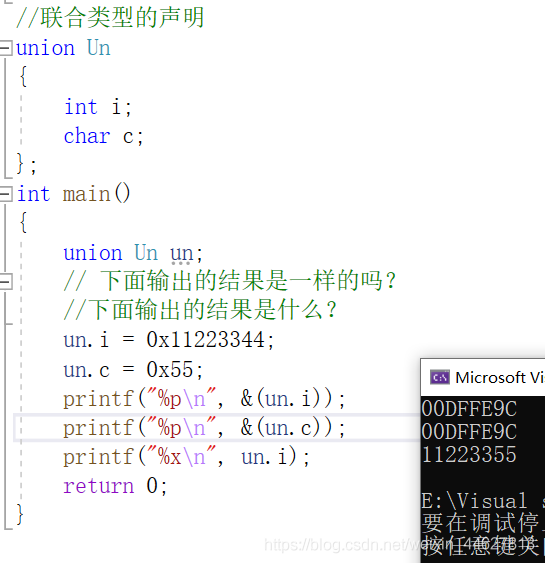
//聯合型別的宣告
union Un
{
int i;
char c;
};
int main()
{
union Un un;
// 下面輸出的結果是一樣的嗎?
//下面輸出的結果是什么?
un.i = 0x11223344;
un.c = 0x55;
printf("%p\n", &(un.i));
printf("%p\n", &(un.c));
printf("%x\n", un.i); //0x11223355
return 0;
}
程式執行的程序:

聯合的計算
■ 聯合的大小至少是最大成員的大小,
■ 當最大成員大小不是最大對齊值的整數倍的時候,就要對齊到最大對齊數的整數倍,
union Un1
{
char c[5];
int i;
};
union Un2
{
short c[7];
int i;
};
//下面輸出的結果是什么?
printf("%d\n", sizeof(union Un1)); //12
printf("%d\n", sizeof(union Un2)); //20
小伙伴覺得寫得還不錯的來個三連!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/229182.html
標籤:其他