Faiss簡介
Faiss是Facebook AI團隊開源的針對聚類和相似性搜索的開源庫,為稠密向量提供高效相似度搜索服務,支持十億級別向量的搜索,是目前最為成熟的近似近鄰搜索庫之一,Faiss提供了多種索引型別如L2距離,向量內積等,詳細介紹可參考Faiss Indexes,我們可以針對不同大小的向量集和聚類演算法選擇合適的索引型別,
在mx推薦服務中,目前主要借助Faiss做相似性召回和打分,我們將不同的演算法產出item和user的embedding資料,加載到Faiss的索引中,便可實作諸如item-based/user-based等演算法,同時,也可以根據業務場景需要,利用Faiss給相應的結果進行打分排序,
服務選型
最初,MX的Faiss server是根據一個開源的用flask框架開發的web server(faiss-web-service)改進而來的,為了盡快推上線做實驗,并沒有進行詳細地設計和優化,因此線上表現不算太好,平均回應時間大概為6ms左右,另外擴展性較差,在添加或洗掉索引時在很多方面受到框架限制,經充分調研和技術選型,最終決定用RPC框架進行重構,
目前開源的RPC框架有很多,例如Thrift,Dubbo,gRPC,rpcx等,由于mx推薦服務是用java語言開發的,而Faiss目前只支持C++和Python兩種語言,考慮到多語言支持的需求,只有gRPC和Thrift滿足要求,在調研中發現(參考《流行的rpc框架benchmark》),在處理10ms級業務時,在吞吐和延遲方面,gRPC較Thrift有一定的優勢,故最終選擇了gRPC框架,
需求分析
1、多型別向量加載
不同演算法產出的向量以演算法名+item型別+產出的時間戳(版本號)的命名方式存盤在s3上,例如S3上鍵為deepwalk/movie/index.20190821_043002_64的檔案是用deepwalk演算法產出的movie型別的item的向量,Faiss server需要能加載各個型別的向量構建索引,并根據請求中的演算法型別和item型別從對應的索引中進行相似性搜索,
2、多型別索引試驗
Faiss提供了豐富的索引型別,我們可以將同一型別的向量加載成不同型別的索引來進行小流量試驗,由此來找出效果最好的一組向量型別與索引型別的映射,這里的效果包括推薦結果的指標,Faiss server記憶體占用率,CPU使用率以及回應時間等,
3、索引方便配置
因為每個索引的線上表現并不相同,隨著試驗的進行,有些索引需要被下掉,新的演算法產出的向量也需要及時做試驗,所以Faiss server需要能夠靈活地配置索引,
4、索引版本控制
我們在產出item向量的同時也會產出user的向量,推薦系統可以用user向量去召回同一向量空間下的item,但是user向量存盤在pika里,產出也會滯后于item向量,也有可能因為某些原因user向量的的寫入出現問題,導致推薦系統取出的是舊向量,而Faiss server已經更新成新的索引,因此Faiss server需要能加載同一型別多個版本的向量,這樣推薦系統就可以通過指定版本來獲取同一向量空間里與user向量近鄰的item,
5、索引熱更新
不同演算法產出的向量每天會不定時的進行更新,Faiss server除了在服務啟動時加載最新向量構建索引外,還需要及時用最新的向量更新索引,同時也要能夠正常回應請求,
設計與實作
1. Faiss Server
1.1 組織結構
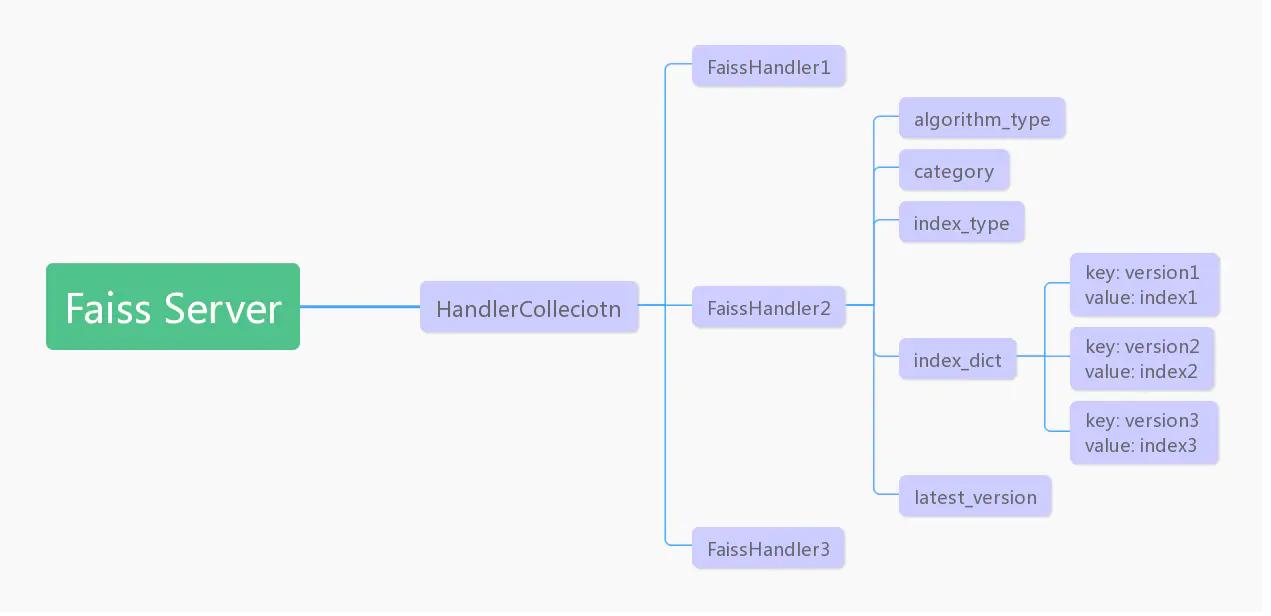
上圖為Faiss server的組織結構圖,為了滿足需求1,2,4,我們將Faiss索引封裝在FaissHandler中,FaissHandler包含了5個欄位,algorithm_type, category和index_type唯一指定了一個index,由此可以方便支持多向量型別和多索引型別,而index_dict保存了真正的Faiss索引,以向量(索引)版本為key,Faiss索引為value,由此可以方便地支持指定版本的最近鄰搜索服務,另外還有一個latest_version欄位,用來保存index_dict中最新的版本號,當不指定向量版本進行搜索時將會使用最新版本的索引搜索,
我們可以在HandlerCollection里配置當前需要使用的FaissHandler,索引的更新程式可以通過遍歷collection逐個更新索引,另外也滿足了需求3,添加、更改或洗掉都只需要修改一行代碼即可,非常方便,而gRPC服務只需要將請求中的引數進行組裝,然后路由到對應的handler就行,剩下的操作都由handler完成,
1.2 介面設計
Faiss server需要提供一個搜索最近鄰item的RPC介面search,search介面的請求中需要指明具體使用哪個索引,以及目標item的id或者向量,請求體的主要欄位如下:
message SearcRequest {
string algorithmType = 1;
string category = 2;
int32 num = 3;
string indexType = 4;
repeated string itemId = 5;
repeated FloatArray vector = 6;
}SearchRequest中前四個欄位是必須的,因為依賴這四個欄位來查找handler,而itemId和vector至少需要一個存在,itemId和vector都用repeated修飾,是為了支持多item,多vector搜索,
message SearchResponse {
message Str2FloatMap {
map<string, float> innerMap = 1;
}
map<string, Str2FloatMap> similarItems = 1;
} response很簡單,只有一個map,key為目標item或vector(SearchRequest中的),value則為最近鄰結果和對一個的分數,
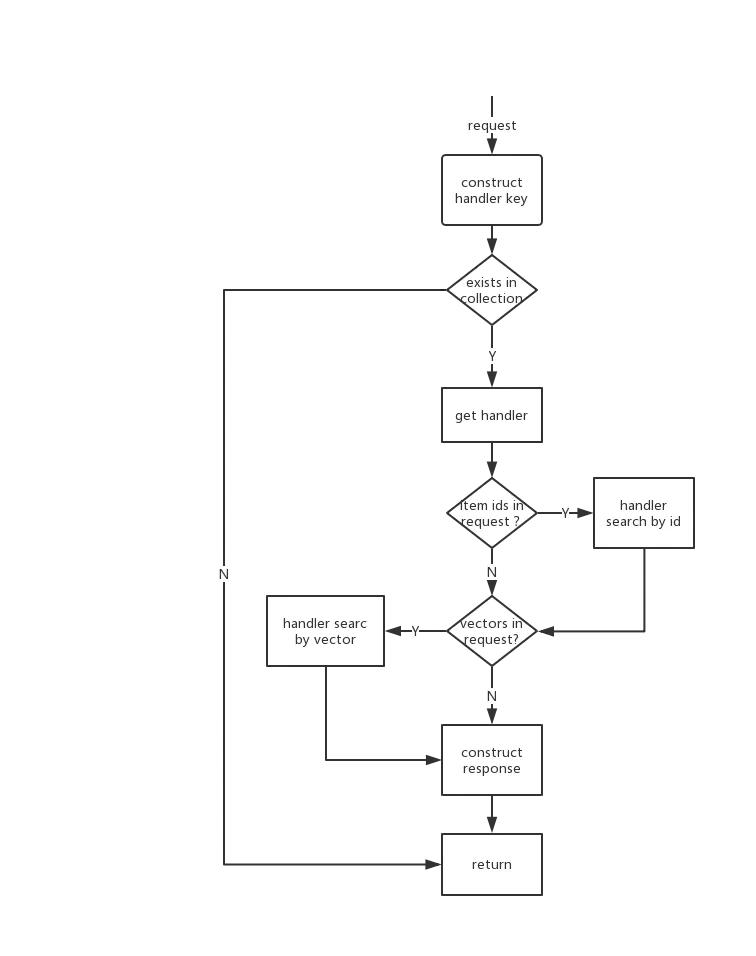
1.3 search流程
2. 索引更新
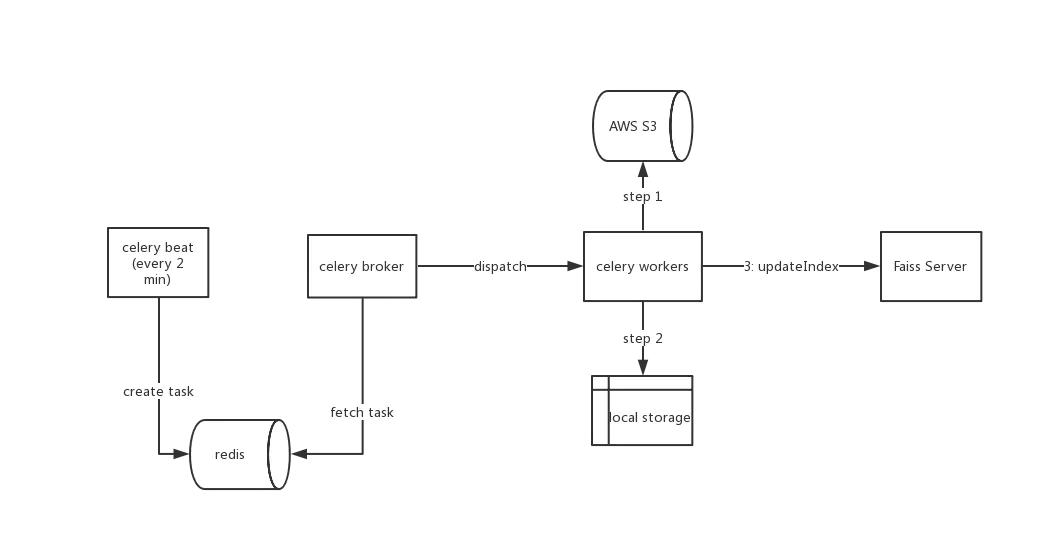
上圖為索引更新的架構圖,celery beat每隔2分鐘創建一個更新索引的task,要求更新HandlerCollection中的所有handler對應的索引,worker接收到task之后從AWS S3上下載對應的向量檔案,加載向量構建索引,然后將索引序列化到檔案,Faiss server提供gRPC介面來接收celery的通知(呼叫),接到通知后直接加載索引檔案更新索引,向量的下載和索引的構建都是非常耗時的操作,交由celery完成能夠節省server的資源,保證server穩定高效地運行,詳細的索引更新流程如下圖:
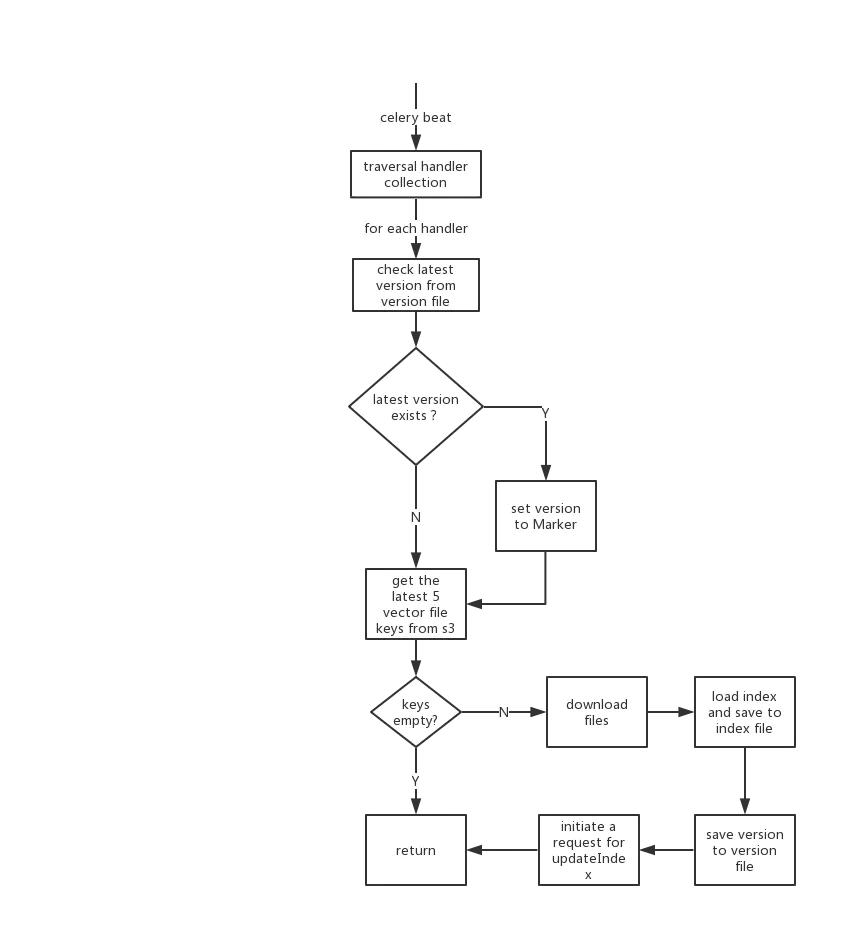
上圖講述了詳細的更新流程,但是為了流程的流暢性和可讀性隱藏了一些細節,更新操作并非是單執行緒一路走下來的,因為我們有很多索引,為了盡快更新索引提供服務,在遍歷handler collection時,會為每個handler創建一個檢查version的celery task,然后celery worker會并發地去執行這些task,針對每一個task,如果真的需要更新,同樣創建一個download vector的task并發執行,但是這里有一個問題,就是celery beat每隔2分鐘創建一條更新索引的task,但是下載向量是非常耗時的操作,因為向量檔案可能很大,如果上一次的更新操作還處于download vector執行中,而這一次也走到了download vector這一步,這樣就造成了同時有多個worker在下載相同的向量,這樣不僅造成了worker資源的浪費,還造成了網路IO的浪費,所以,在真正下載向量之前,會先嘗試獲取一個針對具體向量的鎖,如果無法獲得鎖,說明有worker正在執行download vector task,當前worker直接return,結束任務,等待接收其他task,下載完向量之后也是并發的加載索引和通知server更新,
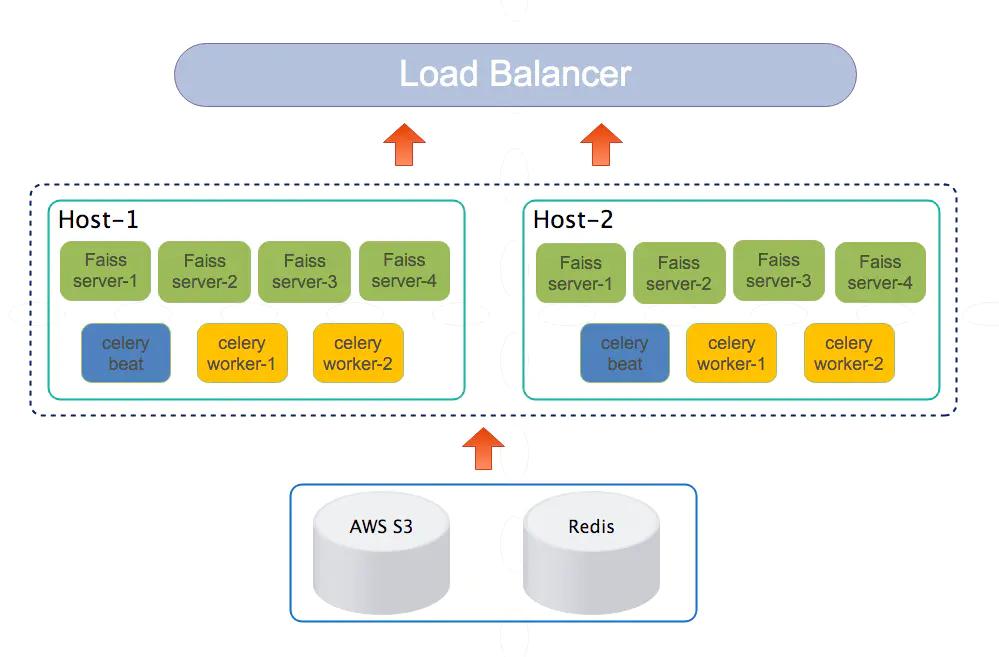
部署
Faiss server是用python語言開發的,由于python具有全域解釋器鎖無法有效地利用多核CPU,所以我們采用了單機多服務實體的模式進行部署,
線上表現
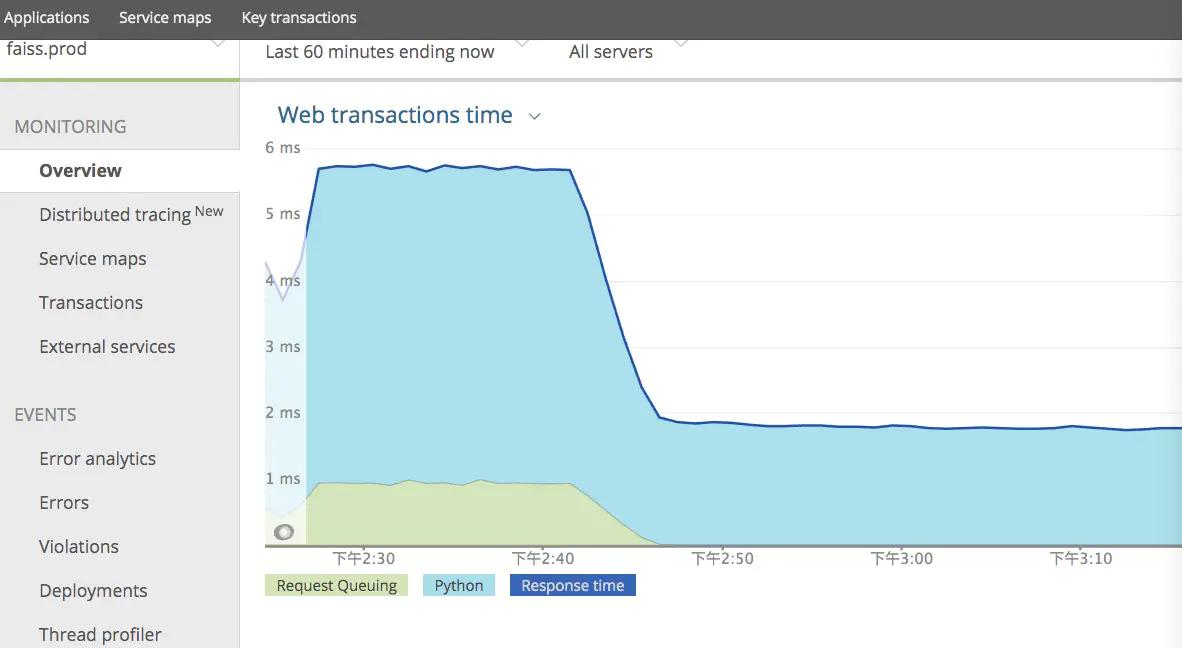
在上線之前進行了充分的壓力測驗,結果表明單機QPS比之前高了2倍以上,回應時間降低了大約67%,新服務上線前后在newrelic上的回應時間對比如下圖:
總結
基于gRPC的Faiss server是針對業務需求高度定制化的服務,有效地解決了原有服務所存在的各種問題,具有高效率,高可擴展性等特點,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/229411.html
標籤:AI