for word in df2.loc[:,['word']]:#遍歷word列里所有單元格
for i in range(len(df2.loc[:,['word']])):
if str(df2.iloc[i][3]) == '<p>' and str(df2.iloc[i+1][3]) != '<p>':#通過iloc索引進行,單元格內判斷是否為<p>,
p +=1
if df2.iloc[i][3] != '.':#判斷單元格內是否為句號。
words +=str(df2.iloc[i][3])+' '
poss += str(df2.iloc[i][5])+' '
prot += str(df2.iloc[i][4])+' '
先上代碼。自己寫的遍歷跑的很慢,處理一個100M的TXT大概需要100分鐘的時間,請可以使用iterrows(),itertuples(),iteritems(),這三種方法遍歷,并索引到單元格內的元素么?具體怎么操作。
uj5u.com熱心網友回復:
有老哥來點提示不~uj5u.com熱心網友回復:
給出資料及要實作的目的,感覺你的內層回圈沒必要uj5u.com熱心網友回復:

這是我的資料,這個資料是由句子切分成單詞和符號的文本,還有對應的(第4列)詞性和(第3列)單詞原型。我首先把他們組合成句子,對分配好每一個單詞對應的詞性和原型。并為每個句子分配id。我做出的效果如下
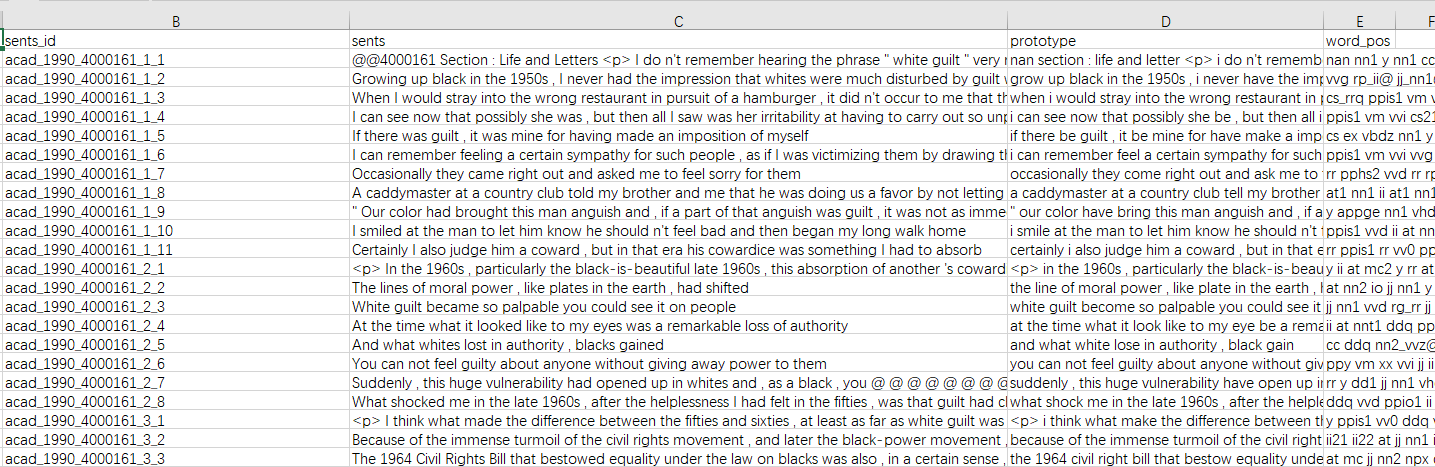
uj5u.com熱心網友回復:
df2是什么樣子的uj5u.com熱心網友回復:
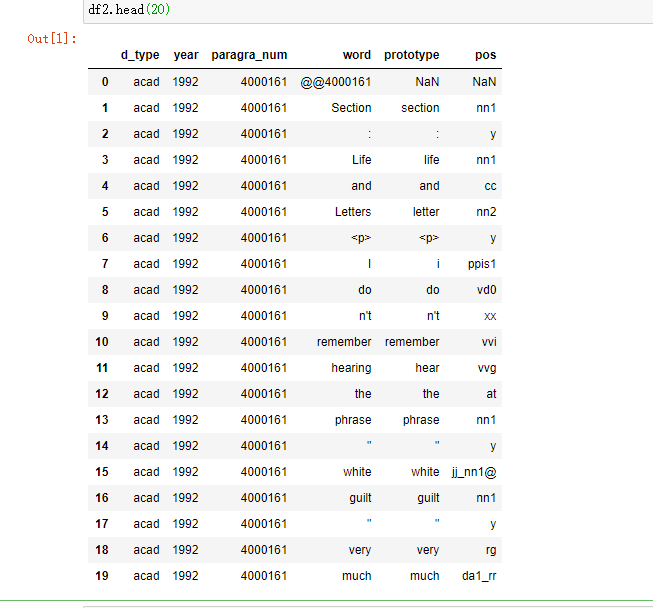
這是df2
uj5u.com熱心網友回復:
感覺這個應該可以是下面這樣的:for i in df2.index:
df2.iloc[i][各列]
uj5u.com熱心網友回復:
可以使用iteritems()這一類的方法么,老哥你這代碼我沒看明白啥意思。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/229532.html
上一篇:python爬取網頁資料,沒有顯示報錯,但是也爬取不了網站內容的原因是什么
下一篇:使用xlrd和xlutils寫了兩個excel函式,執行時總是報Can't load sheets after releasing resources,求助大神