
思路:
設tx為t類別字符的個數,
①對于長度小于2的t明顯是"YES"
②對于字符類別只有1個的t明顯是"YES"
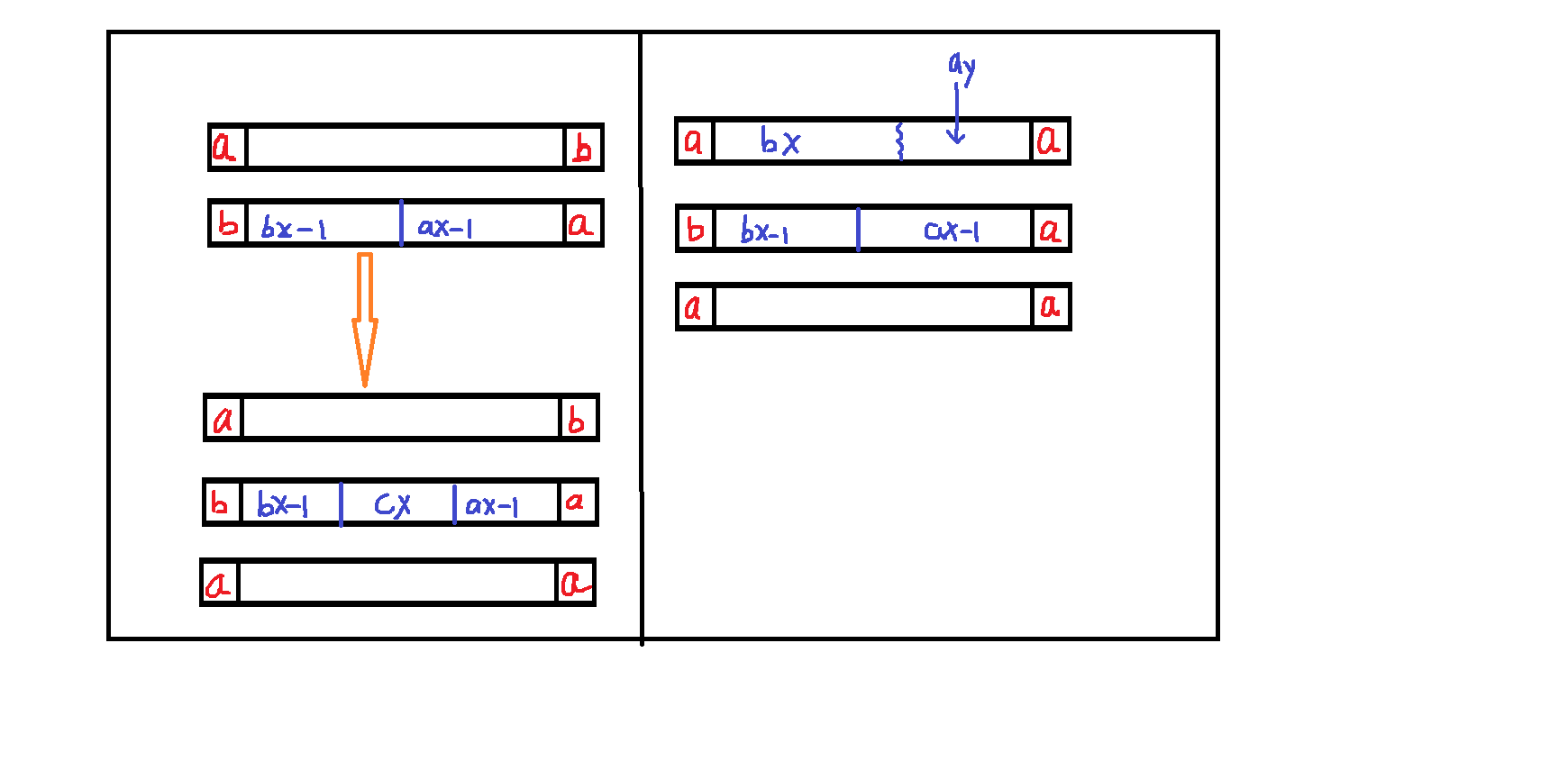
③對于字符類別有2個的t,如左上圖:如果str[l] != str[r],那么我們構造的t也應該是str[l] != str[r],且s字串和t的str[l]和str[r]是相反的,即如圖所示,繼續,如圖構造,即bbb..a...a這樣,我們發現第一個圖片除去str[l] = a和str[r]=b之外,中間怎么放置字符,都會出現"Irreducible Anagrams"的情況,所以"YES",
④對于字符類別有2個的t,如果str[l] == str[r],如右邊的圖,總有k = 2,讓s1包含一個a和bx個b,s2包含剩余的ay個a使得滿足"reducible Anagrams",所以"NO",
④對于字符類別有3個的t,按著左上的圖也無法構造出"Irreducible Anagrams" 情況,說明字符類別為3的t,說明不論字符排列都存在"reducible Anagrams",所以"NO",
⑤對于字符類別大于3個的t,由④推出是"NO",
#include <iostream> #include <cstdio> #include <algorithm> #include <cstring> using namespace std; const int N = 2e5 + 10; int dp[30][N]; char str[N]; void solve() { scanf("%s", str); int n = strlen(str); for(int i = 1; i <= n; ++i) { dp[str[i - 1] - 'a'][i]++; for(int c = 0; c < 26; ++c) { dp[c][i] += dp[c][i - 1]; } } /* for(int c = 0; c < 26; ++c) { printf("%c :\n", 'a' + c); for(int i = 1; i <= n; ++i) { printf("%d ", dp[c][i]); } printf("\n"); } */ int q; scanf("%d", &q); vector<pair<int ,int > > vp; for(int i = 0; i < q; ++i) { int l, r; scanf("%d%d", &l, &r); vp.push_back(make_pair(l, r)); } ///vector<int > ans; for(auto info : vp) { int l = info.first; int r = info.second; int kinds = 0; int sum = 0; for(int c = 0; c < 26; ++c) { kinds += (dp[c][r] - dp[c][l - 1]) > 0; sum += dp[c][r] - dp[c][l - 1]; } ///cout << "tot = " << kinds << endl; if(sum == 1 || (kinds == 2 && str[l - 1] != str[r - 1]) || kinds > 2) { printf("YES\n"); } else printf("NO\n"); } } int main() { solve(); return 0; }
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/229715.html
標籤:其他
上一篇:0897. Increasing Order Search Tree (M)
下一篇:Unity全域呼叫非靜態函式