論文地址:Towards Real-Time Multi-Object Tracking
Towards Real-Time Multi-Object Tracking
- 一、 摘要
- 二、 介紹
- 三、 檢測和嵌入的聯合學習(JDE)
- 1. 問題設定
- 2.結構
- 3.檢測學習
- 4.外貌嵌入學習
- 5.自動損失平衡
- 6.在線關聯
- 四、實驗
- 五、 思考與總結
一、 摘要
傳統的DBT范式下的MOT都是要經過兩步驟:1.監測模型進行目標位置檢測;2.外貌嵌入模型進行資料關聯,兩部分獨立運作,不共享一些結構,會導致效率問題,并且現在實時MOT上的研究主要集中于關聯階段,但是本質上這只是關聯的實時,但是MOT模型卻無法實時,
本論文提出了一個目標檢測和外貌嵌入可以共享學習的模型,方法上是將外貌嵌入模型整合進一個單階段的檢測,讓模型可以在檢測出目標的同時,輸出相應的目標外貌嵌入,在此基礎上,進一步提出了一種與聯合模型相結合的簡單、快速的關聯方法,與之前的兩階段相比,計算量大大降低,更加快速,接近實時,
主要創新點:引入JDE聯合檢測和Embedding學習,接近實時,并且準確率堪比SDE(檢測嵌入分離)模式,
二、 介紹
傳統的DBT范式,將MOT分為兩步:
- 檢測階段,用于檢測目標在單一視頻幀中的位置;
- 關聯階段,將檢測的目標關聯到之前的軌跡,
這意味著MOT存在兩個密集型計算部分,一個檢測網路,一個嵌入(Re-ID)網路,作者將這種檢測和嵌入分開進行的命名為SDE,由于SDE的計算量比較大,所以實時很困難,
為了解決計算問題,簡單思路是將檢測和嵌入整合入同一個model中,共享低級特征,避免了重復的計算量,作者首先想到使用改版的雙階段檢測器Faster-RCNN:
第一步,使用不變RPN網路,輸出檢測的邊界框;
第二步,修改Fast-RCNN,將其改變為一個嵌入模型,將分類監督改變為引數學習監督,
但是盡管節省了計算量,但是速度還是不夠實時,
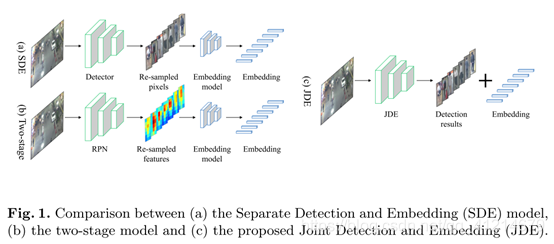
為了提升效果,在single-shot深度網路中引入JDE(聯合學習檢測和嵌入),JDE即在檢測出目標的同時輸出相應檢測框的外貌embedding,
對比下,SDE方法和雙階段方法分別重采樣像素(邊界框)和特征圖進行特征表示, 邊界框和特征圖被單獨喂到一個獨立的Re-ID網路中進行外貌特征提取(圖1),該論文提到的JDE方法不僅接近實時,且精度堪比SDE方法,
論文中建立的JDE方法程序:
- 首先,資料集方面,他選擇了帶有行人檢測和人物搜索的6個公開資料集組合成一個統一的大規模的多標簽資料集,資料集中所有行人邊界框都被標注,部分行人存在身份標簽,
- 其次,網路模型方面,選擇了FPN作為基礎結構,探討選擇能夠最好的學習嵌入資訊的損失函式,
- 然后,我們將訓練程序建模為一個多任務學習問題,包括錨分類、邊界框回歸和嵌入學習,為了平衡每個任務的重要性,我們使用獨立任務的不確定性來動態地衡量性損失,提出一個簡單的關聯演算法提升效率
- 最后,使用各種引數評估模型,
三、 檢測和嵌入的聯合學習(JDE)
1. 問題設定
假設訓練資料集 { I , B , y } i = 1 N \{I,B,y\}_{i=1}^N {I,B,y}i=1N?, I ∈ R c × h × w I∈R^{c×h×w} I∈Rc×h×w表示視頻影像幀, B ∈ R k × 4 B∈R^{k×4} B∈Rk×4當前幀中k個目標的邊界框注釋, y ∈ Z k y∈Z^k y∈Zk表示部分注釋的身份標簽, ? 1 -1 ?1表示沒有身份標簽,JDE的目的是輸出預測的邊界框 B ^ ∈ R k ^ × 4 \hat B∈R^{\hat k×4} B^∈Rk^×4以及外貌嵌入 F ^ ∈ R k ^ × D \hat F∈R^{\hat k×D} F^∈Rk^×D, D D D表示嵌入特征的維度.
再輸出預測的同時并且要滿足不同幀的帶相同身份標簽目標的嵌入特征距離應當足夠近,不同身份標簽的目標的特征嵌入差距足夠大,這個距離可以是歐式距離或者余弦距離,
如果檢測器足夠準,并且滿足上面提到的要求,那么即使是基礎的匈牙利也可以很好的進行追蹤,
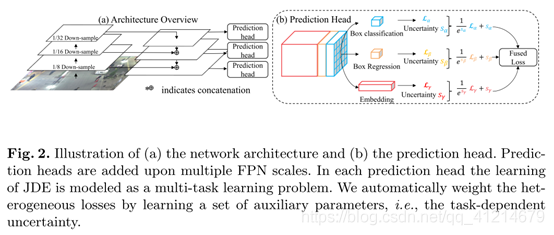
2.結構
使用了FPN的結構,保證不同尺度目標的檢測(本文生成了三種不同尺度的特征),不同尺度的特征圖送入多卷積層的預測頭,輸出一個
(
6
A
+
D
)
×
H
×
W
(6A+D) ×H×W
(6A+D)×H×W的預測,
A
A
A是分配給這個尺度的錨模板的數量,
D
D
D是特征嵌入維度,
具體將輸出分為三個部分送入是三個任務:
- 邊界框分類分支:2A×H×W
- 邊界框回歸分支:4A×H×W
- 密集嵌入特征圖分支:D×H×W
3.檢測學習
檢測分支類似于RPN,進行了兩點修改:
- 我們重新設計了錨的數量、比例和縱橫比,以便能夠適應目標;
- 對于前后景的分類使用雙閾值,設定IoU>0.5的為前景,IoU<0.4的為背景(并非傳統的0.3,實驗證明本實驗0.4效果更好),
檢測學習產生兩個損失,一個前后景分類損失L_α(交叉熵損失),一個邊界框回歸損失L_β(smooth L1損失),
4.外貌嵌入學習
作者經過推測,認為交叉熵損失比三元組損失、改進三元組損失進行外貌嵌入學習要更加適合本模型:
L
C
E
=
?
log
?
exp
?
(
f
?
g
+
)
exp
?
(
f
?
g
+
)
+
∑
i
exp
?
(
f
?
g
i
?
)
\mathcal{L}_{C E}=-\log \frac{\exp \left(f^{\top} g^{+}\right)}{\exp \left(f^{\top} g^{+}\right)+\sum_{i} \exp \left(f^{\top} g_{i}^{-}\right)}
LCE?=?logexp(f?g+)+∑i?exp(f?gi??)exp(f?g+)?
f
?
f^?
f?是一個mini-batch中被選為錨的實體,在這里,我們把正類(錨實體所屬的類)的權值表示為
g
+
g^+
g+,把負類的權值表示為
g
i
?
g_i^-
gi??
具體的,如果一個錨框標記為前景,就會從密集嵌入圖中提取他相應的嵌入,提取的嵌入喂入一個共享引數的全連接層,生成類級得分,對得分使用交叉熵損失,通過這種方式,來自多個尺度的嵌入共享同一空間,跨尺度的關聯是可行的,如果嵌入的標簽 y y y為 ? 1 -1 ?1即沒有身份標簽,則直接忽略這個嵌入的損失,
5.自動損失平衡
JDE的每個預測頭可以認為是一個多任務學習問題,損失函式可以定義為如下:
L
total
=
∑
i
M
∑
j
=
α
,
β
,
γ
w
j
i
L
j
i
\mathcal{L}_{\text {total}}=\sum_{i}^{M} \sum_{j=\alpha, \beta, \gamma} w_{j}^{i} \mathcal{L}_{j}^{i}
Ltotal?=i∑M?j=α,β,γ∑?wji?Lji?
M
M
M代表預測頭數,
w
j
i
(
i
=
1
…
M
,
j
=
α
,
β
,
γ
)
w_j^i (i=1…M,j=α,β,γ)
wji?(i=1…M,j=α,β,γ)代表損失權重,
如果采用列舉搜索的權重可能并不會產生最優解,這樣的結果甚至會遠離優化,因此選擇一種使用獨立任務不確定性進行自動搜索辦法選擇權重:
L
total
=
∑
i
M
∑
j
=
α
,
β
,
γ
1
2
(
1
e
s
j
i
L
j
i
+
s
j
i
)
\mathcal{L}_{\text {total}}=\sum_{i}^{M} \sum_{j=\alpha, \beta, \gamma} \frac{1}{2}\left(\frac{1}{e^{s_{j}^{i}}} \mathcal{L}_{j}^{i}+s_{j}^{i}\right)
Ltotal?=i∑M?j=α,β,γ∑?21?(esji?1?Lji?+sji?)
s
j
i
s_j^i
sji?表示每個體損失的獨立任務不確定性,定義為可學習的引數,
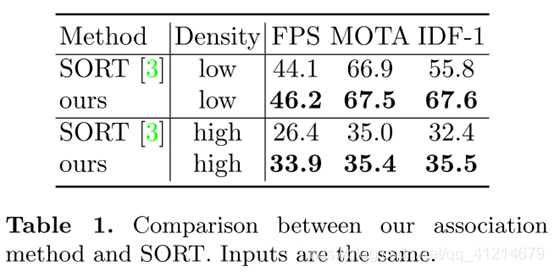
6.在線關聯
提出一種簡單的關聯方法,一個軌跡被描述為一個外貌狀態 e i e_i ei?和一個運動狀態 m i = ( x , y , γ , h , x ˙ , y ˙ , γ ˙ , h ˙ ) m_i = (x,y,γ,h,\dot x,\dot y,\dot γ , \dot h) mi?=(x,y,γ,h,x˙,y˙?,γ˙?,h˙),其中 x , y x,y x,y表示邊界框中心位置, h h h表示邊界框的高, γ γ γ表示寬高比, x ˙ \dot x x˙表示沿著 x x x方向的速度,軌跡外貌特征 e i e_i ei?初始化為第一次檢測該目標的外貌嵌入,
所有可能參與匹配的軌跡集中存放于軌跡池,對于一個輸入的幀,我們計算所有觀測j檢測值與池中軌跡之間的成對運動關聯矩陣
A
m
A_m
Am?和外觀關聯矩陣
A
e
A_e
Ae?,利用余弦相似度計算外觀親和力,運動親和力的計算使用馬氏距離,利用這兩個矩陣計算代價矩陣
C
=
λ
A
e
+
(
1
?
λ
)
A
m
C=λA_e+(1-λ)A_m
C=λAe?+(1?λ)Am?,利用匈牙利演算法進行匹配,所有匹配的軌跡的運動狀態
m
i
m_i
mi?使用卡爾曼濾波更新,外貌狀態
e
i
e_i
ei?如下更新:
e
i
t
=
α
e
i
t
?
1
+
(
1
?
α
)
f
i
t
e_{i}^{t}=\alpha e_{i}^{t-1}+(1-\alpha) f_{i}^{t}
eit?=αeit?1?+(1?α)fit?
α
=
0.9
α = 0.9
α=0.9為動量,
f
i
t
f_i^t
fit?為當前幀匹配的檢測的外貌嵌入,最后,如果連續出現在2幀中,未分配給任何軌跡的檢測將被初始化為新的軌跡,如果軌跡沒有在當前的30幀中更新,它將被終止,
對比SORT的根據時間的級聯關聯方法:
四、實驗
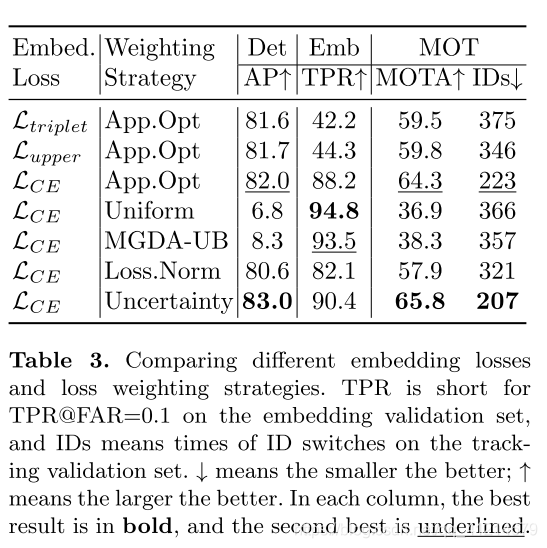
1.對比不同損失函式之間的差距:
2.對比其他SDE模型:
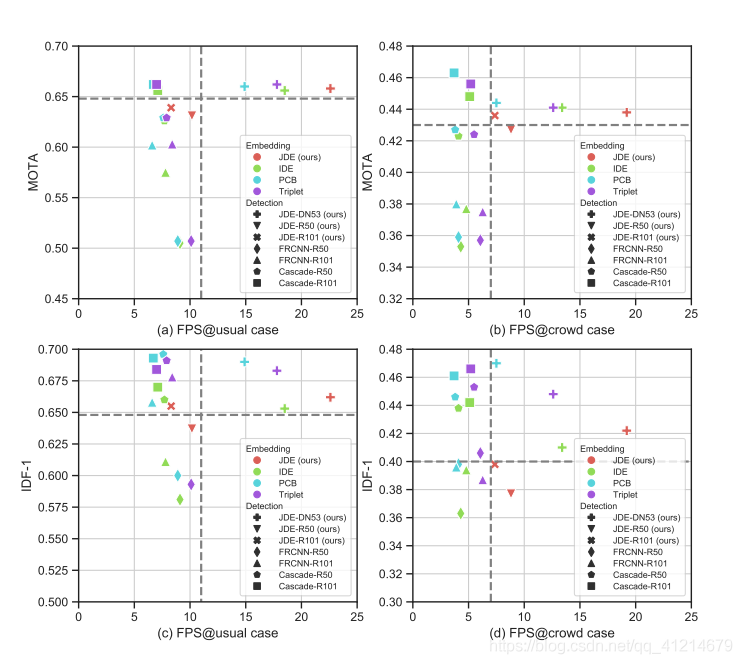
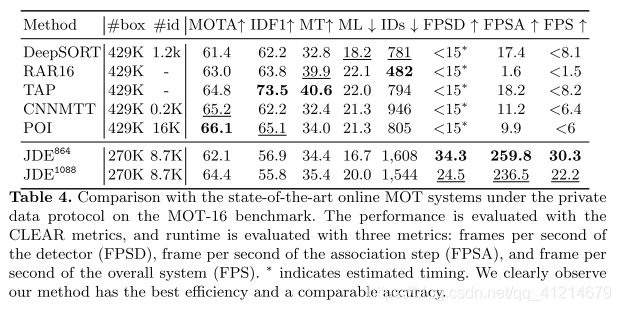
3.在MOT-16基準測驗中與采用私有資料的SOTA在線MOT模型進行比較:
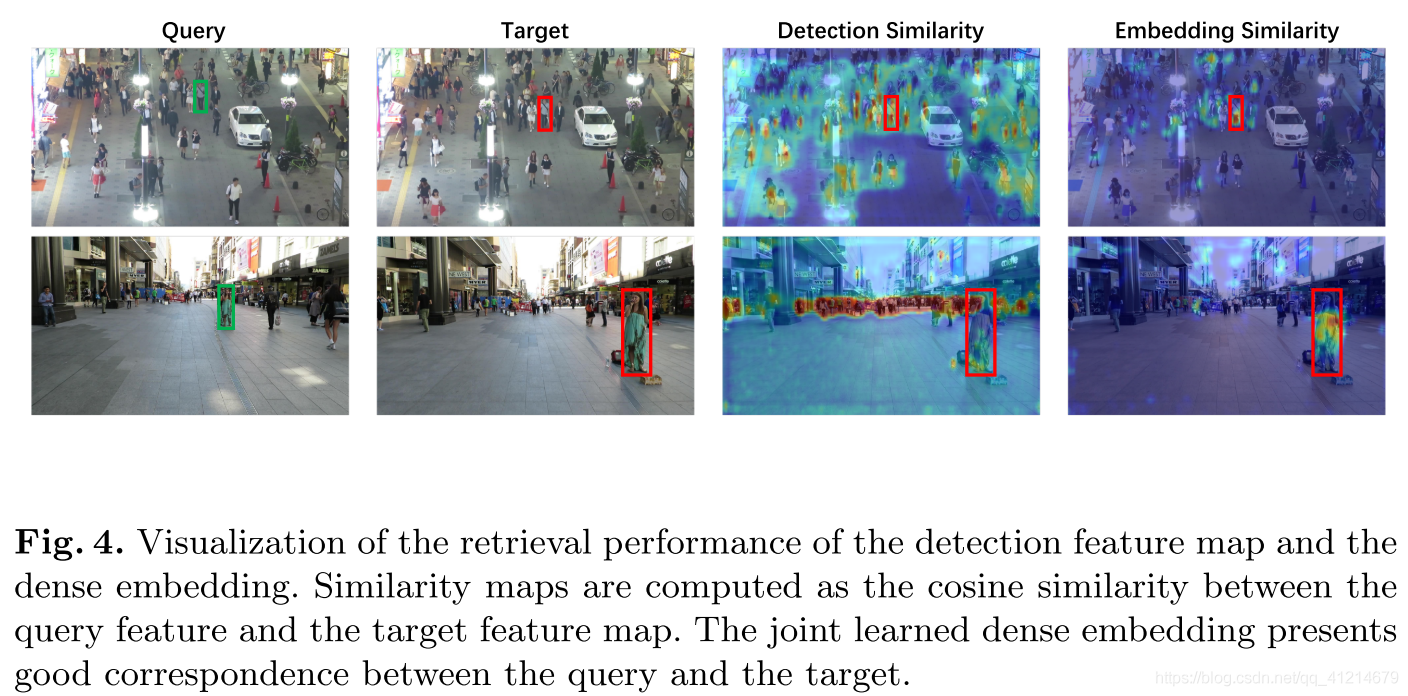
4.可視化
五、 思考與總結
該方法擁有一個低的IDF1得分卻存在一個很高的IDSW,主要原因是由于當多個行人重疊的不精準的檢測造成的,大多發生在軌跡路線的中間時刻,因此IDF1很低,
論文引入JDE,聯合目標檢測和外貌嵌入進一個共享模型,極大減少了MOT模型的運行時間,使他接近實時,同時,追蹤的準確率也達到了當時的SOTA,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/230383.html
標籤:AI