簡介
浙江大學和達摩院前不久提出的一個 MOT 新方法,目前在 MOT Challenge 常用的幾個資料集上名列前茅,論文標題 Tracklets Predicting Based Adaptive Graph Tracking 其實已經表明本文最大的兩個創新點,基于軌跡預測的特征提取以及基于自適應圖網路的特征聚合,大多數現存的多目標跟蹤方法將當前幀的檢測結果鏈接到歷史軌跡段都是采用基于特征余弦距離和目標邊界框 IOU 的線性組合作為度量的,這其實有兩個問題:一是兩個不同幀(當前幀和上一幀)上同一個目標提取到的特征往往會出現不一致的問題;二是特征提取只考慮外觀而不考慮位置關系、軌跡段資訊是不合理的,
因此,論文提出了一種新的高精度端到端多目標跟蹤框架 TPAGT(上一個版本叫 FGAGT,感覺 TPAGT 更加貼合論文的作業),該方法解決了上述的兩個問題,在多個資料集上實作了新的 SOTA,
- 論文標題
Tracklets Predicting Based Adaptive Graph Tracking - 論文地址
http://arxiv.org/abs/2010.09015 - 論文原始碼
暫未開源
介紹
首先說明的是,TPAGT 按照一般 MOT 的方法劃分是一個二階段框架,也就是先完成檢測,再按照檢測結果到相應的位置提取目標特征,最后利用關聯演算法得到結果,關聯一般采用匈牙利演算法,單階段方法融合了檢測和特征提取,是為了速度做出的精度妥協,所以精度相比二階段有些低,所以,作為一個二階段方法,TPAGT 的精度應該有所創新,但是相應的速度比較慢,具體推理速度,論文沒有提及,只能等原始碼開放后測驗了,
先來說一說 MOT 現有方法沒解決的幾個問題,
- 特征不一致問題
這個問題怎么來的呢,其實是因為軌跡段(tracklet)上目標的特征都是來自于之前幀,而不是當前幀(這很容易理解,當前幀只有當前幀的檢測結果確定目標位置來提取特征嘛),但是呢,其實在移動程序中,目標的姿態、光強度、視角都可能發生變化,這導致來自不同影像的同一目標的特征即使檢測準確也會不太一致,這種不一致對資料關聯來說負面影響比較大, - 特征融合問題
事實上,從 DeepSORT 開始,特征提取器主要關注的就是外觀資訊,因為這對忽略了運動建模的一些 MOT 方法至關重要,因此特征提取分支也成為 ReID 分支,主要就是因為重識別模型關注的就是外觀資訊,但是,目標之間的位置關系、tracklet 的歷史資訊對 MOT 任務也是很重要的, - 樣本不平衡問題
一個 tracklet 只能匹配一個檢測框,那這個 tracklet 就是個連續的正例,沒有匹配上的 tracklet 就是連續的負例,顯然,正例數量是遠遠少于負例的,而且由于少量的新目標的產生和舊目標的消失,進一步加劇了不同型別的樣本的不均衡問題,
上述的問題 TPAGT 都逐一解決了,其中最主要的一個問題就是 traklets 中的特征和當前幀是不一致的,那么如何解決呢,到當前幀上重提取特征就行,但是顯然不能直接把上一幀的 bbox(邊界框,包含目標的位置區域等資訊)用于當前幀,因為目標在影像上不可能靜止,使用上一時刻的位置很不合理,所以需要對上一幀進行運動估計得到目標在當前幀預測的 bbox 位置然后提取特征,然后是特征融合的問題,考慮到目標之間的聯系近似一個圖表示,作者采用了GNN(圖神經網路)來進行資訊的聚合,為了更好獲取全域時空資訊,GNN 的邊權自適應學習,最后,樣本不平衡的問題采用了Balanced MSE Loss,這是一個加權 MSE,屬于常用思路,
框架設計
Tracklets predicting based feature re-extracting
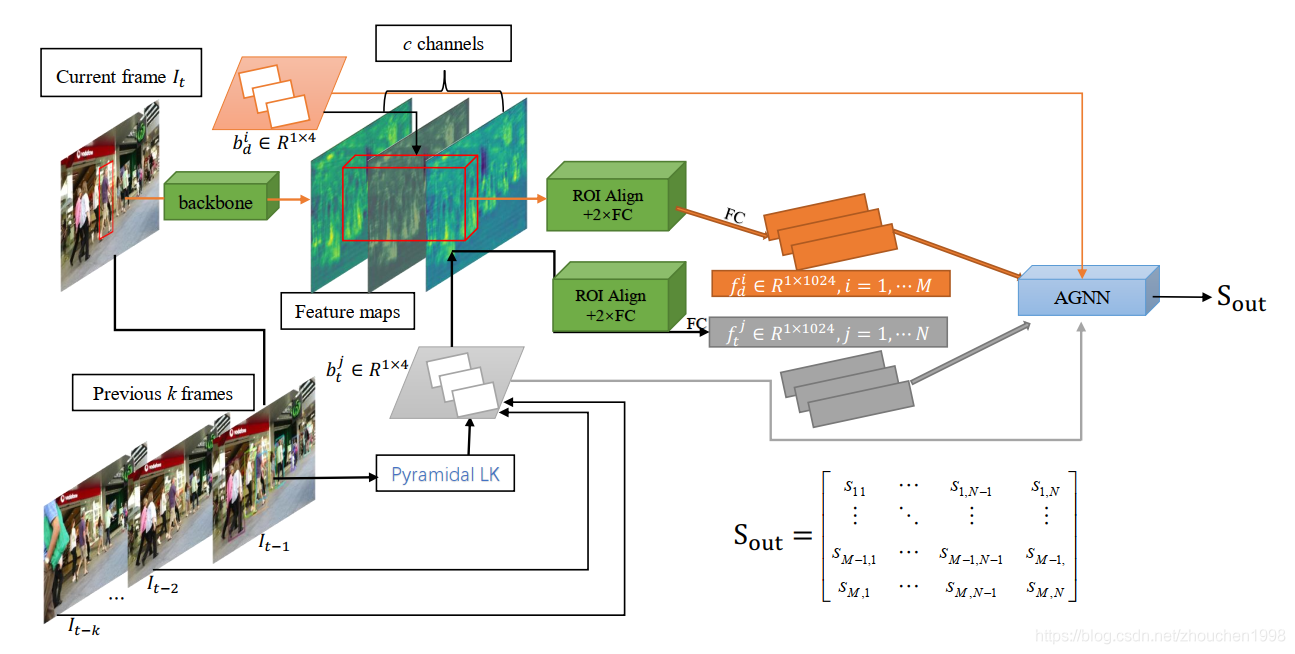
上面這個圖就是整體框架的設計,我先大體介紹一下網路的 pipeline,首先,網路的輸入有當前幀影像、當前幀檢測結果、歷史幀檢測結果;接著,影像被送入 backbone 中獲得特征圖(這里 backbone 最終采用 ResNet101+FPN 效果最好),然后將 bbox(這里當前幀用的是檢測的 bbox,上一幀用的光流預測的 bbox)映射到特征圖上通過 RoI Align 獲得 region 外觀特征繼而送入全連接(這個操作類似 Faster R-CNN 的 proposal 提取特征,不理解的可以查閱我的博客),然后結合當前幀的位置資訊、歷史幀資訊,讓圖網路自適應學習進行特征融合從而計算相似度,有了相似度矩陣匈牙利就能計算匹配結果了,
上面的敘述有個容易誤解的地方,它將過去一幀預測的 bbox 和歷史幀的非預測的 bbox 都在當前特征圖上提取了特征,事實上,不是的,一來實際上, t ? 2 t-2 t?2幀的特征在處理 t ? 1 t-1 t?1幀的時候已經重提取過了,在當前幀上用當時的 bbox 提取肯定存在嚴重的不對齊問題;二來,這樣會大大加大網路計算的復雜性,完全沒有必要,論文這個圖畫的稍微有些讓人誤解,等開源后可以再細細研究,
我們知道,此前的 MOT 方法對運動的建模主要采用卡爾曼濾波為代表的狀態估計方法、光流法和位移預測法,這篇論文使用稀疏光流法預測 bbox 的中心點運動,由于目標的運動有時候是高速的,為了應對這種運動模式,必須采用合適的光流方法,文章采用金字塔光流,該方法魯棒性很強,具體想了解的可以參考這篇博客,下圖是金字塔光流預測的目標當前幀位置(b 圖),c 圖是 GT 的框,可以看到,預測還是很準的,

Adapted Graph Neural Network
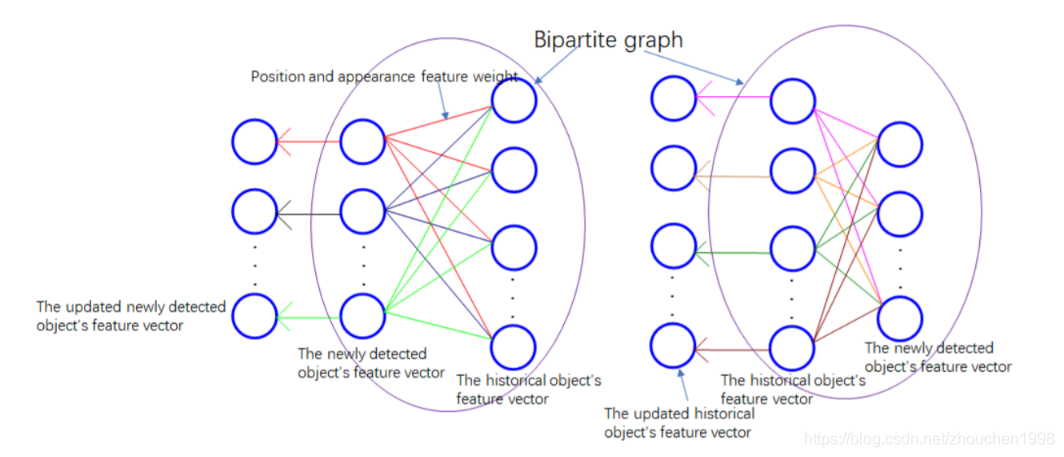
下面聊一聊這個自適應圖神經網路,將 tracklets 和 detections 作為二分圖處理不是什么新鮮的事情,但是用來聚合特征 TPAGT 應該是為數不多的作業,要知道此前我們聚合運動和外觀特征只是人工設計的組合,作者這種借助圖網路自適應聚合特征是很超前的思路, 每個檢測目標和每個 tracklet 都是節點,如上圖所示,detection 之間沒有聯系,tracklet 之間也沒有聯系,但是每個 tracklet 和每個 detection 之間都有連接,圖網路的學習目的就是每個節點的狀態嵌入 h v \mathbf{h}_{v} hv?,或者說聚合其他資訊后的特征向量,最終,這個 h v \mathbf{h}_{v} hv?包含了鄰居節點的資訊,
需要學習的狀態嵌入通過下面的公式更新,第一行表示 detections 的節點更新,第二行表示 tracklets 的節點更新,共有 N N N個 detection 和 M M M個 tracklet,下面講解第一行的幾個符號含義,第二行類似, f f f表示神經網路運算,可以理解為網路擬合函式; h t , c j h_{t, c}^{j} ht,cj?表示第 c c c層第 i i i個 detection 的狀態嵌入,在一開始, c = 0 , h d , 0 i = f d i , h t , 0 i = f t j c=0, h_{d, 0}^{i}=f_{d}^{i}, h_{t, 0}^{i}=f_{t}^{j} c=0,hd,0i?=fdi?,ht,0i?=ftj?, e d , c i , j e_{d, c}^{i, j} ed,ci,j?則表示第 i i i個檢測和第 j j j個 tracklet 在第 c c c層的圖上的邊權,本文作者只使用添加自適應的單層 GNN,所以下面具體闡述單層學習的情況,
h d , c + 1 i = f ( h d , c i , { h t , c j , e d , c i , j } j = 1 N ) , i = 1 , 2 , ? ? , M h t , c + 1 j = f ( h t , c j , { h d , c i , e t , c j , i } i = 1 M ) j = 1 , 2 , ? ? , N \begin{aligned} h_{d, c+1}^{i} &=f\left(h_{d, c}^{i},\left\{h_{t, c}^{j}, e_{d, c}^{i, j}\right\}_{j=1}^{N}\right), i=1,2, \cdots, M \\ h_{t, c+1}^{j} &=f\left(h_{t, c}^{j},\left\{h_{d, c}^{i}, e_{t, c}^{j, i}\right\}_{i=1}^{M}\right) j=1,2, \cdots, N \end{aligned} hd,c+1i?ht,c+1j??=f(hd,ci?,{ht,cj?,ed,ci,j?}j=1N?),i=1,2,?,M=f(ht,cj?,{hd,ci?,et,cj,i?}i=1M?)j=1,2,?,N?
首先,邊權的初始化不采用隨機初始化,而是采用節點的特征和位置先驗資訊,具體如下,主要是計算每個節點特征向量之間的歸一化距離相似度,具體圖資訊聚合步驟如下,
- 計算初始相似度
s i , j = 1 ∥ f d i ? f t j ∥ 2 + 1 × 1 0 ? 16 s i , j = s i , j s i , 1 2 + s i , 2 2 + ? s i , j 2 + ? + s i , N 2 S f t = [ s i , j ] M × N , i = 1 , ? M , j = 1 , ? N \begin{array}{c} s_{i, j}=\frac{1}{\left\|f_{d}^{i}-f_{t}^{j}\right\|_{2}+1 \times 10^{-16}} \\ s_{i, j}=\frac{s_{i, j}}{\sqrt{s_{i, 1}^{2}+s_{i, 2}^{2}+\cdots s_{i, j}^{2}+\cdots+s_{i, N}^{2}}}\\ \mathbf{S}_{\mathrm{ft}}=\left[s_{i, j}\right]_{M \times N}, i=1, \cdots M, j=1, \cdots N \end{array} si,j?=∥fdi??ftj?∥2?+1×10?161?si,j?=si,12?+si,22?+?si,j2?+?+si,N2? ?si,j??Sft?=[si,j?]M×N?,i=1,?M,j=1,?N? - 通過 IOU 和上面的初始相似度組成邊權( w w w可學習,表示位置和外觀資訊的相對重要性)
E = w × I O U + ( 1 ? w ) × S f t \mathrm{E}=w \times \mathrm{IOU}+(1-w) \times \mathrm{S}_{\mathrm{ft}} E=w×IOU+(1?w)×Sft?
- 根據上述的自適應權重聚合節點特征( ⊙ \odot ⊙表示點積)
F t a g = E F t = E [ f t 1 , f t 2 , ? ? , f t N ] T \mathbf{F}_{\mathrm{t}}^{\mathrm{ag}}=\mathrm{EF}_{t}=\mathrm{E}\left[f_{t}^{1}, f_{t}^{2}, \cdots, f_{t}^{N}\right]^{T} Ftag?=EFt?=E[ft1?,ft2?,?,ftN?]T
H d = σ ( F d W 1 + Sigmoid ? ( F d W a ) ⊙ F t a g W 2 ) \mathbf{H}_{\mathrm{d}}=\sigma\left(\mathbf{F}_{d} W_{1}+\operatorname{Sigmoid}\left(\mathbf{F}_{d} W_{a}\right) \odot \mathbf{F}_{\mathrm{t}}^{\mathbf{a g}} W_{2}\right) Hd?=σ(Fd?W1?+Sigmoid(Fd?Wa?)⊙Ftag?W2?)
H t = σ ( F t W 1 + Sigmoid ? ( F t W a ) ⊙ F d a g W 2 ) \mathbf{H}_{\mathrm{t}}=\sigma\left(\mathbf{F}_{t} W_{1}+\operatorname{Sigmoid}\left(\mathbf{F}_{t} W_{a}\right) \odot \mathbf{F}_{\mathrm{d}}^{\mathbf{a g}} W_{2}\right) Ht?=σ(Ft?W1?+Sigmoid(Ft?Wa?)⊙Fdag?W2?)
現有的圖跟蹤方法需要額外的全連接層降維特征向量,然后通過歐式距離計算相似度,TPAGT 的方法只要標準化來自單隱層圖網路的特征,然后矩乘它們即可得到相似度決戰,如下式,最終得到的相似度矩陣值介于 0 和 1 之間,越大代表兩個目標越相似,學習的目的是使得同一個目標的特征向量盡量接近,不同目標的特征向量盡量垂直,這等價于三元組損失,但是更加簡單,
h d i = h d i ∥ h d i ∥ 2 , h t j = h t j ∥ h t j ∥ 2 , S o u t = H d H t T h_{d}^{i}=\frac{h_{d}^{i}}{\left\|h_{d}^{i}\right\|_{2}}, h_{t}^{j}=\frac{h_{t}^{j}}{\left\|h_{t}^{j}\right\|_{2}}, \mathbf{S}_{\mathrm{out}=\mathbf{H}_{\mathrm{d}} \mathbf{H}_{\mathbf{t}}^{\mathrm{T}}} hdi?=∥hdi?∥2?hdi??,htj?=∥htj?∥2?htj??,Sout=Hd?HtT??
Blanced MSE Loss
得到最終的相似度矩陣就可以進行監督訓練了,不過 GT 的標簽為相同目標為 1,不同的目標為 0,下圖是作者做的可視化,每行代表一個 detection,每列代表一個 tracklet,綠行表示 detection 沒有匹配上任何 tracklet,所以是新目標;相對的,紅串列示消失的目標,1 表示正例,0 表示負例,顯然正負例嚴重不均衡,所以這里對 MSE 按照目標型別進行了加權(超參),如下式,
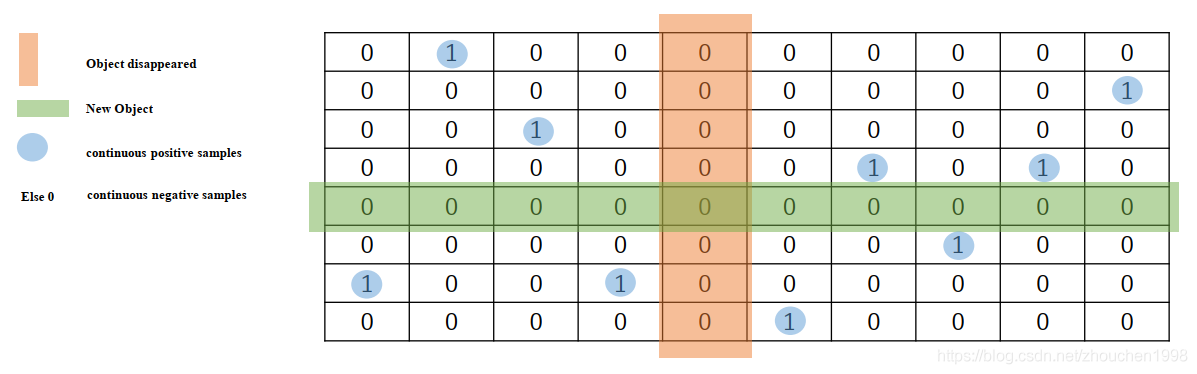
L = α E c 0 + β E c 1 + γ E n e + δ E d + ε E w = ∑ i = 1 M ∑ j = 1 N [ α ( S ^ i , j ? S i , j ) 2 ? I continue ? I S i , j = 0 + β ( S ^ i , j ? S i , j ) 2 ? I continue ? I S i , j = 1 + γ ( S ^ i , j ? S i , j ) 2 ? I n e w + δ ( S ^ i , j ? S i , j ) 2 ? I disap + ε ∥ W ∥ 2 2 ] \begin{aligned} \mathcal{L} &=\alpha E_{c 0}+\beta E_{c 1}+\gamma E_{n e}+\delta E_{d}+\varepsilon E_{w} \\ &=\sum_{i=1}^{M} \sum_{j=1}^{N}\left[\begin{array}{c} \alpha\left(\hat{S}_{i, j}-S_{i, j}\right)^{2} \cdot \mathbb{I}_{\text {continue }} \cdot \mathbb{I}_{S_{i, j}=0}+\beta\left(\hat{S}_{i, j}-S_{i, j}\right)^{2} \cdot \mathbb{I}_{\text {continue }} \cdot \mathbb{I}_{S_{i, j}=1} \\ +\gamma\left(\hat{S}_{i, j}-S_{i, j}\right)^{2} \cdot \mathbb{I}_{n e w}+\delta\left(\hat{S}_{i, j}-S_{i, j}\right)^{2} \cdot \mathbb{I}_{\text {disap }}+\varepsilon\|W\|_{2}^{2} \end{array}\right] \end{aligned} L?=αEc0?+βEc1?+γEne?+δEd?+εEw?=i=1∑M?j=1∑N?????α(S^i,j??Si,j?)2?Icontinue ??ISi,j?=0?+β(S^i,j??Si,j?)2?Icontinue ??ISi,j?=1?+γ(S^i,j??Si,j?)2?Inew?+δ(S^i,j??Si,j?)2?Idisap ?+ε∥W∥22???????
推理設計
推理時,我們會得到相似度矩陣,那么如何利用這個矩陣呢?假設有 N N N個 detection 和 M M M個 tracklet,矩陣就是 M × N M\times N M×N的,此時在后面補充一個 M × M M\times M M×M的增廣矩陣,矩陣中每個值都是一個閾值,如下圖,匈牙利演算法就成了帶篩選的匹配方法,下圖由于第 3 行和第 8 行沒有高于閾值(0.2)的相似度,所以成為了新目標,

實驗及分析
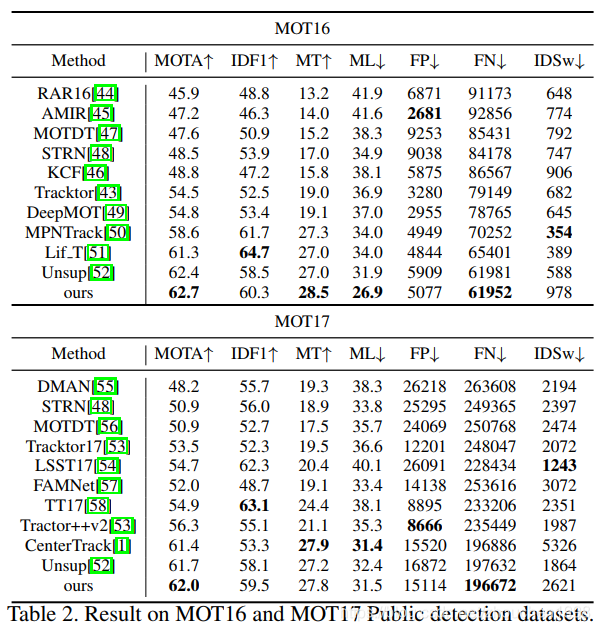
檢測部分采用 FairMOT 的檢測結果,也就是采用 CenterNet 作為檢測器,特征提取部分,文章使用 ResNet101-FPN 作為 backbone,在 COCO 上預訓練過,然后在 MOT 資料集上 fine tune 30 輪,其他訓練細節可以自行查閱論文,我這里就不多說了,在 Public 和 private 兩個賽道進行了測驗,結果分別如下,超越了之前的 SOTA 方法如 FairMOT 等,精度突破很大,速度比較慢,
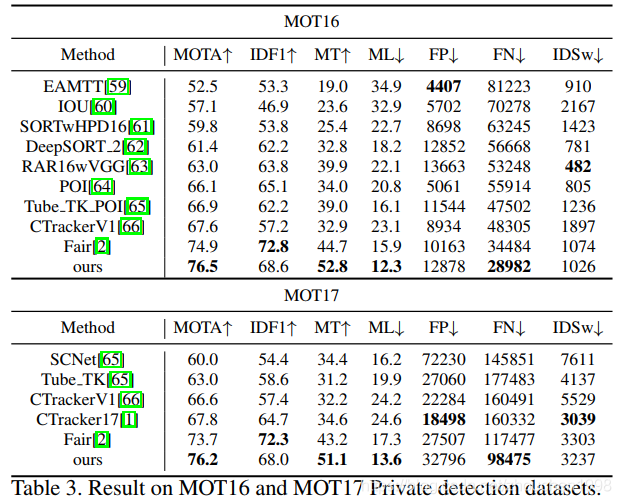
此外,作者還進行了豐富的消融實驗,證明了 TPAGT 的魯棒性,
總結
開創性地提出了特征重提取策略,并引入 AGNN 進行特征融合,從而構建了 TPAGT 框架,這是一個端到端的學習框架,可以直接輸出相似度矩陣,在 MOT Challenge 兩個賽道都獲得了 SOTA 表現,
參考文獻
[1]Shan C, Wei C, Deng B, et al. Tracklets Predicting Based Adaptive Graph Tracking[J]. arXiv:2010.09015 [cs], 2020.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/230386.html
標籤:AI