三角網格去噪-DNF_Net論文解讀
用三維掃描儀或者深度相機獲取的原始三維模型,都不可避免的含有噪聲,這些含有噪聲的三維模型需要做去噪處理,以便后續應用,三維模型常見的表示形式是點云或者三角網格,對應的就是點云去噪、三角網格去噪,
本文講解一篇用深度學習方法做三角網格去噪的方法,
三角網格去噪方法可以分成兩類:第一類是直接移動三角網格中的頂點位置,達到去噪的目的,第二類是先對三角網格中每個三角面片的法向進行調整(也可以稱之為法向濾波或者法向域去噪),然后根據根據調整后的法向,移動頂點的位置,達到去噪的目的,
從目前來看,第二類方法占據了主流地位,很多論文也對其為啥占主流地位做了分析,
言歸正傳,本次分享的論文DNF_Net也是用深度學習方法在法向域里面進行濾波,然后根據濾波后的法向,移動頂點的位置,達到去噪的目的,
1 Training patch preparation(訓練樣本準備)
給定一對三角網格(mesh pair),即帶噪聲的網格 M M M和其對應的干凈無噪聲的 M G M^G MG,通過三步來對資料進行預處理,
-
隨機選取三角網格 M M M上的一些面作為種子面集合,同時上 M G M^G MG也選取相同的種子集合,即網格 M M M與網格 M G M^G MG的種子面集合是相同的,
-
對于每個種子面 F i F_i Fi?,根據這個面找到離其測地線距離(geodesic distance)最近的 N ? 1 N-1 N?1個面,將包括種子面在內的 N N N個面的法向量構成一個可訓練的資料塊 N i ∈ R N × 3 N_i \in \mathbb{R}^{N\times3} Ni?∈RN×3,(請注意,實際代碼中,是從種子面的n環鄰面中以此遍歷到的N個面,可參考代碼getNeighborFacets函式)
N i = [ n i 1 n i 2 ? n i N ] N_i = \left[\begin{matrix} n_{i1}\\ n_{i2}\\ \vdots\\ n_{iN} \end{matrix} \right] Ni?=??????ni1?ni2??niN???????? -
為了利用塊 N i N_i Ni?中每個面的區域資訊(或者可以稱為local structure),對于 N i N_i Ni?中的每個面 F i j F_{ij} Fij?,記 I i j I_{ij} Iij?為 F i j F_{ij} Fij?的 K K K個最鄰面的索引, I i ∈ R N × K I_i \in \mathbb{R}^{N\times K} Ii?∈RN×K,(不像二維規則的影像,三維曲面是不規則的,在三維空間中進行學習,一個重要的問題就是解決無序性,這里利用 I i j I_{ij} Iij?是一個解決方案,可以借鑒,)
2 Network architecture
框架圖:
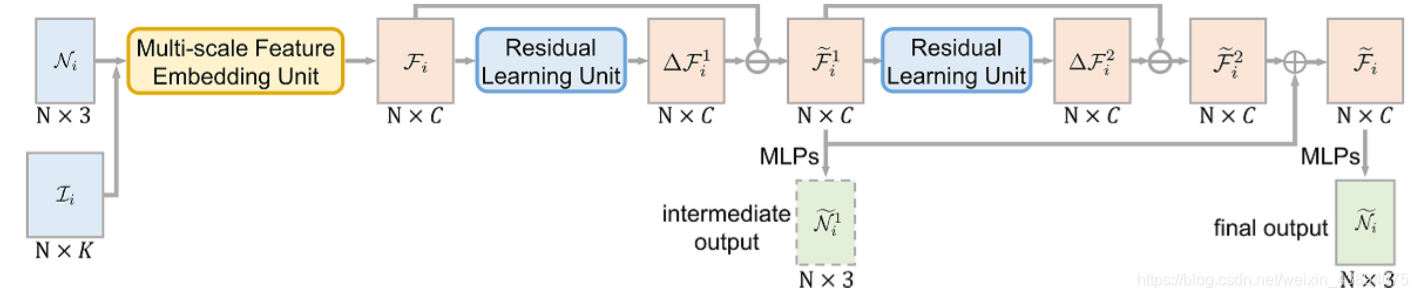
輸入:采集到的資料對,即 ( ( N i , I i ) ( N i G , I i ) ) ((N_i,I_i)(N_i^G,I_i)) ((Ni?,Ii?)(NiG?,Ii?)), 即學習$N_i 到 到 到N_i^G$的映射,達到Ni中法向去噪的目的,
-
N i N_i Ni?:有噪聲網格 M M M第 i i i片區域內所有三角面片的法向量,每一行代表一個片的法向量,
-
I i I_i Ii?:第 i i i片區域內所有面的 k k k個最鄰近面,
-
N i G N_i^G NiG?:無噪聲 M G M^G MG第 i i i片區域內所有三角面片的法向量,每一行代表一個面片的法向量,
2.1 Multi-scale feature embedding unit
目的:提取區域特征,以用于編碼區域背景關系,
建立一個三級框架從
N
i
N_i
Ni?和
I
i
I_i
Ii?中提取法向特征圖
F
i
∈
R
N
×
C
\mathcal{F}_i \in \mathbb{R}^{N \times C}
Fi?∈RN×C,這三級框架中第一級為法向聚合層(Normal grouping layer)+特性提取層(Feature extraction layer),后兩級均為特征聚合層(Feature grouping layer)+特征提取層,

2.1.1 Normal grouping layer
目的:提取輸入的每個面的區域空間特征,
為了更好地說明這一層是如何設計的,結合下圖進行分析,下面標號分別對應與圖中的標號,
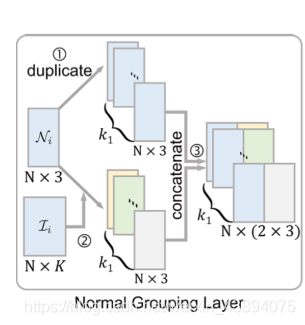
- 將 N i N_i Ni?復制 k 1 k_1 k1?份,
- 因為 I i I_i Ii?記錄了 N i N_i Ni?中每個面的 K K K個最鄰近面的索引,所以可以根據這些索引獲得每個面最鄰近的 k 1 k_1 k1?個面的法向量,通俗的描述,如上圖2右邊 k 1 k_1 k1?個塊所示,第一個塊就是 N i N_i Ni?,第二個塊就是由與 N i N_i Ni?中每個面的最鄰近的面的法向量構成的,第三個塊就是由與 N i N_i Ni?中每個面的第二鄰近的面的法向量構成的,……,第 k 1 k_1 k1?個塊就是由與 N i N_i Ni?中每個面的第 k 1 ? 1 k_1-1 k1??1鄰近的面的法向量構成的,
- 將1,2對應塊拼接起來,
代碼如下:
def normal_grouping_embedding(input, mlp, is_training, bn_decay, scope, local_size, bn=True, pooling='max'):
'''
:param input: [B, N, K, 3]
:param is_training:
:param bn_decay:
:param scope:
:param bn:
:param pooling:
:return: output: [B, N, 1, C']
'''
K = input.get_shape()[2].value
center = input[:, :, 0, :]
center = tf.expand_dims(center, axis=2) # [B, N, 1, C]
center_tile = tf.tile(center, [1, 1, K, 1]) # [B, N, K, C]
input_concat = tf.concat([center_tile, input], axis=-1) # [B, N, K, 2C]
input_local = input_concat[:, :, 0:local_size, :]
with tf.variable_scope(scope) as sc:
for i, num_out_channel in enumerate(mlp):
input_local = tf_util.conv2d(input_local, num_out_channel, [1,1],
padding='VALID', stride=[1,1],
bn=bn, is_training=is_training,
scope='conv%d' % (i), bn_decay=bn_decay)
if pooling=='max':
output = tf.reduce_max(input_local, axis=2, keep_dims=True, name='maxpool') # [B, N, 1, C']
elif pooling=='avg':
output = tf.reduce_mean(input_local, axis=2, keep_dims=True, name='avgpool')
output = cbam_module2(output, is_training=is_training, bn_decay=bn_decay, name="cbam")
return output
2.1.2 Feature grouping layer
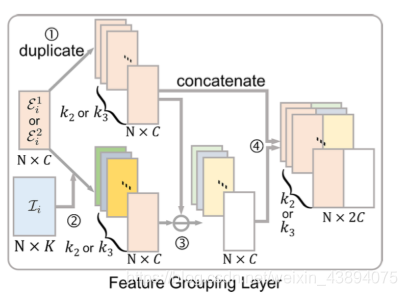
- 將 ε i 1 \varepsilon^1_i εi1?或 ε i 2 \varepsilon^2_i εi2?復制 k 2 k_2 k2?或 k 3 k_3 k3?份,
- 與 Normal grouping layer 中的2類似,
- 將1,2對應塊相減,
- 將1,3對應塊拼接起來,
代碼如下:
def feature_grouping_embedding(input, idx, mlp, is_training, bn_decay, scope, local_size, bn=True, pooling='max',size=50):
'''
:param input: [B, N, 1, C]
:param idx: [B, N, 50]
:param is_training:
:param bn_decay:
:param scope:
:param bn:
:param pooling:
:return: output: [B, N, 1, C']
'''
input_tile = tf.tile(input, [1, 1, size, 1]) # [B, N, 50, C]
# find local feature map according to topology indices
input = tf.squeeze(input, axis=2)
input_group = group_point(input, idx) # [B, N, 50, C]
input_concat = tf.concat([input_tile, input_group-input_tile], axis=-1) # [B, N, 50, 2C]
input_local = input_concat[:, :, 0:local_size, :]
with tf.variable_scope(scope) as sc:
for i, num_out_channel in enumerate(mlp):
input_local = tf_util.conv2d(input_local, num_out_channel, [1,1],
padding='VALID', stride=[1,1],
bn=bn, is_training=is_training,
scope='conv%d' % (i), bn_decay=bn_decay)
if pooling=='max':
output = tf.reduce_max(input_local, axis=2, keep_dims=True, name='maxpool') # [B, N, 1, C']
elif pooling=='avg':
output = tf.reduce_mean(input_local, axis=2, keep_dims=True, name='avgpool')
output = cbam_module2(output, is_training=is_training, bn_decay=bn_decay, name="cbam")
return output
2.1.3 Feature extraction layer
提取額外特征的方法有很多,比如PointNet++、PCN、圖卷積神經網路等,本文作者采用CBAM,
之所以采用CBAM,是因為可以學習每個通道的權重,然后用這些權重來調整每個通道的重要程度,
2.2 Residual learning unit
提取噪聲特征 Δ F i \Delta\mathcal{F}_i ΔFi?,以便獲得去噪后的特征圖 F i ~ = F i ? Δ F \tilde{\mathcal{F}_i}=\mathcal{F}_i- \Delta\mathcal{F} Fi?~?=Fi??ΔF
為了更好地提取用于去噪的特征,需要對區域特征進行編碼,
框架如圖所示:
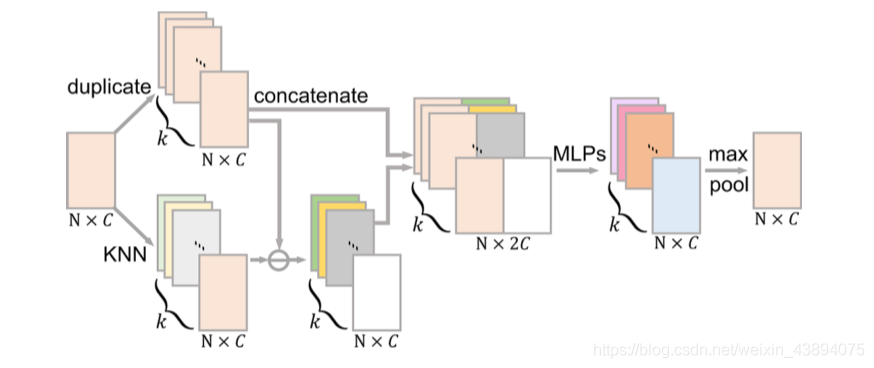
框架圖基本上 Feature grouping layer 層類似,不同的是:
- 在特征空間中,不再使用 I i I_i Ii?,而是使用KNN(文中 k k k取20),(實際代碼中使用的是DGCNN)
- 在 concat 后使用了兩次MLP,然后使用 max pooling 獲得殘差特征圖 Δ F i ∈ R N × C \Delta\mathcal{F}_i\in\mathbb{R}^{N\times C} ΔFi?∈RN×C,
部分代碼如下:
########### denoise level 1 ###############
res_coarse = model_util.dgcnn(net_noisy, [128, 128], is_training, bn_decay, 'res_coarse', bn=True) # [B, N, 1, 128]
net_clean_coarse = tf.subtract(net_noisy, res_coarse) # [B, N, 1, 128]
## regress to three normal vectors
normal_coarse = tf_util.conv2d(net_clean_coarse, 128, [1, 1], padding='VALID', stride=[1, 1], bn=True,
is_training=is_training, bn_decay=bn_decay, scope='regress_coarse_1')
normal_coarse = tf_util.conv2d(normal_coarse, 64, [1, 1], padding='VALID', stride=[1, 1], bn=True,
is_training=is_training, bn_decay=bn_decay, scope='regress_coarse_2')
normal_coarse = tf_util.conv2d(normal_coarse, 3, [1, 1], padding='VALID', stride=[1, 1],
activation_fn=None, scope='regress_coarse_3')
normal_coarse = tf.squeeze(normal_coarse, axis=2) # [B, N, 3]
## magnitude of the normal vector should be 1
normal_coarse = tf.nn.l2_normalize(normal_coarse, dim=2)
############################################
########### denoise level 2 ###############
res_fine = model_util.dgcnn(net_clean_coarse, [128, 128], is_training, bn_decay, 'res_fine',
bn=True) # [B, N, 1, 128]
net_clean_fine = tf.subtract(net_clean_coarse, res_fine) # [B, N, 1, 128]
net_clean = tf.add(net_clean_coarse, net_clean_fine)
## regress to three normal vectors
normal_fine = tf_util.conv2d(net_clean, 128, [1, 1], padding='VALID', stride=[1, 1], bn=True,
is_training=is_training, bn_decay=bn_decay, scope='regress_fine_1')
normal_fine = tf_util.conv2d(normal_fine, 64, [1, 1], padding='VALID', stride=[1, 1], bn=True,
is_training=is_training, bn_decay=bn_decay, scope='regress_fine_2')
normal_fine = tf_util.conv2d(normal_fine, 3, [1, 1], padding='VALID', stride=[1, 1],
activation_fn=None, scope='regress_fine_3')
normal_fine = tf.squeeze(normal_fine, axis=2) # [B, N, 3]
## magnitude of the normal vector should be 1
normal_fine = tf.nn.l2_normalize(normal_fine, dim=2)
3 Deeply-supervised end-to-end training
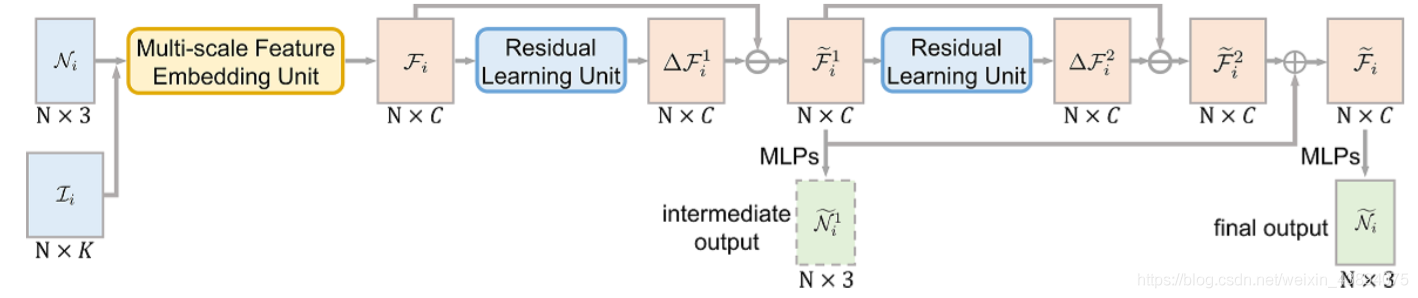
3.1 Deeply-supervised normal recovery loss
使用中間輸出
N
~
i
1
\tilde{N}^1_i
N~i1?和最終輸出
N
~
i
\tilde{N}_i
N~i?來進行雙重監督,
L
d
e
e
p
=
1
N
p
∑
i
=
1
N
P
(
∥
N
i
G
?
N
i
~
∥
2
+
∥
N
i
G
?
N
i
1
~
∥
2
)
L_{deep} = \frac{1}{N_p}\sum^{N_P}_{i=1}(\parallel\mathcal{N}^G_i-\tilde{\mathcal{N}_i}\parallel^2+ \parallel\mathcal{N}^G_i-\tilde{\mathcal{N}^1_i} \parallel^2)
Ldeep?=Np?1?i=1∑NP??(∥NiG??Ni?~?∥2+∥NiG??Ni1?~?∥2)
其中,
N
p
N_p
Np?是訓練的塊數,
3.2Residual regularization loss
從理論上說,
Δ
F
i
1
\Delta\mathcal{F}^1_i
ΔFi1?和
Δ
F
i
2
\Delta\mathcal{F}^2_i
ΔFi2?是
F
i
\mathcal{F}_i
Fi?的小部分,所以這兩個值不應該太大,
L
r
e
s
i
f
u
a
l
=
1
N
p
∑
i
=
1
N
p
(
∥
Δ
F
i
1
∥
2
+
∥
Δ
F
i
2
∥
2
)
L_{resifual} =\frac{1}{N_p}\sum^{N_p}_{i=1}(\parallel\Delta\mathcal{F}^1_i\parallel^2+\parallel\Delta\mathcal{F}^2_i\parallel^2)
Lresifual?=Np?1?i=1∑Np??(∥ΔFi1?∥2+∥ΔFi2?∥2)
3.3 Joint loss
聯合損失函式:
L
=
L
d
e
e
p
+
α
L
r
e
s
i
d
u
a
l
L=L_{deep}+\alpha L_{residual}
L=Ldeep?+αLresidual?
文中
α
\alpha
α取0.5,
4 優缺點
4.1 優點
- 將三角網格分成多個面數相等的塊,能夠直接輸入網路中進行訓練,
- 提出了一個DNF_Net,可以訓練三角網格資料,
4.2 缺點
產生的結果對資料的依賴性較強
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/230392.html
標籤:AI
上一篇:愛了!騰訊前晚最新爆出的“JVM學習筆記”,GitHub已評“鉆級”,熬夜啃完拿到阿里P7崗offer!
下一篇:golang下檔案鎖的使用