
一、本次分享內容
脫敏概述
業務流程
硬體環境
技術鏈路
實作:代碼和腳本
總結:面試點
二、概述

三、脫敏功能實作中的例外情況
1. 合規審查


2. 安全
3. 脫敏演算法
- 是否可逆:加密演算法,散列演算法
- 破解概率
- 脫敏后的值是否需要關聯:長度
4. 客戶體驗:欄位多,以什么方式設定脫敏規則
5. 資料量
- 存盤格式
- 壓縮格式
- 跑批調度時間
6. 如何在hdfs之間傳輸資料,開啟kerberos、sentry、https是否有影響,中斷了咋辦,權限怎么解決,
7. 脫敏后的資料加載到hive表,修復磁區,遠程呼叫
8. Spark中呼叫linux腳本:異步
9. 如何監控程式的運行,日志
四、業務流程
1. 脫敏規則配置
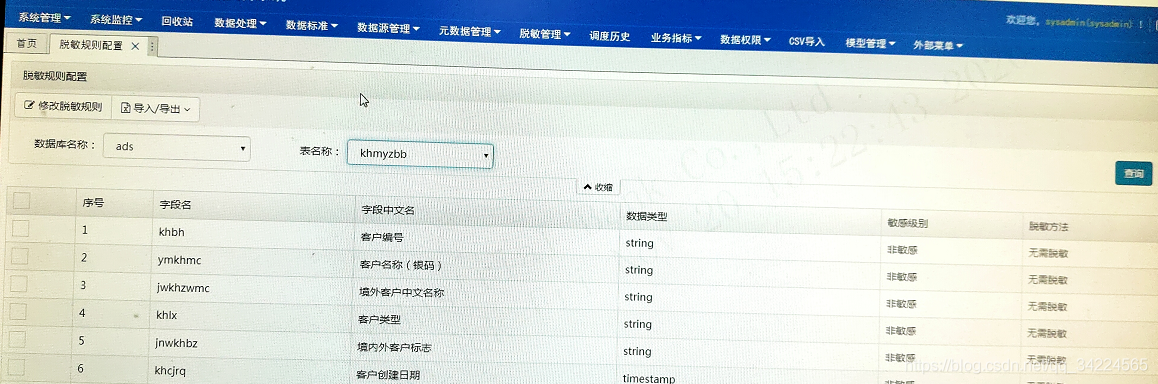
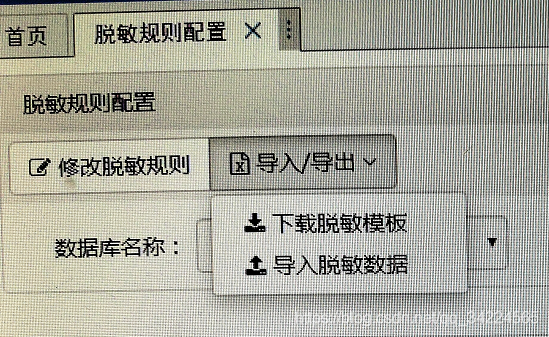
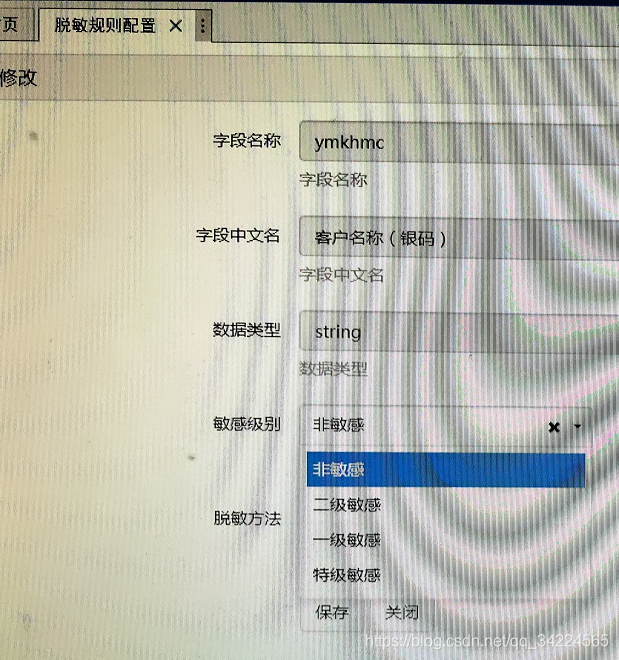
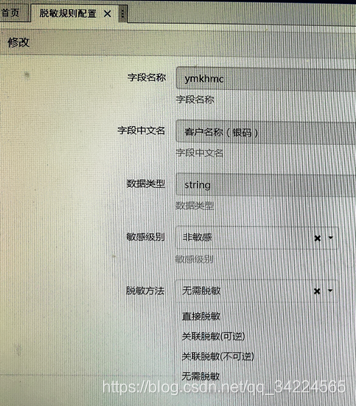
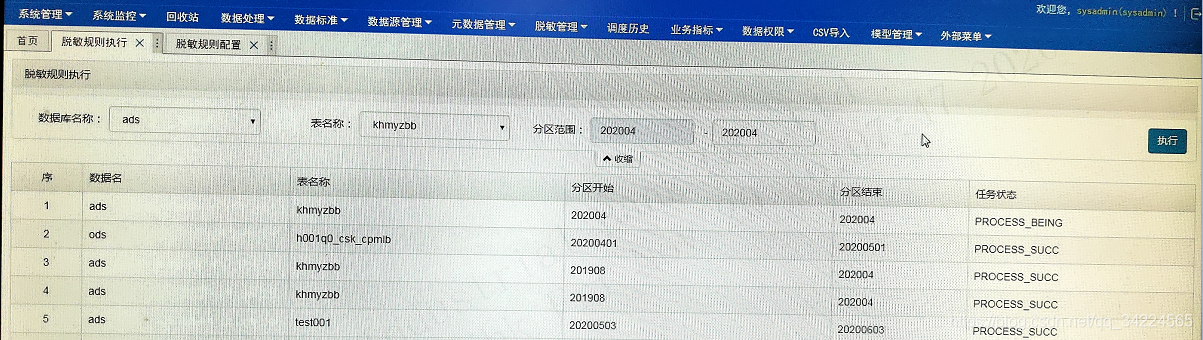
2. 脫敏規則執行
五、環境介紹
1. 生產環境
{1} 大資料集群:
- 15臺物理機,32核、320G記憶體
- 2臺應用虛擬機,2臺oracle虛擬機(16核,64G記憶體)
{2} AI模型跑批、測驗集群:
- 5臺物理機
- 1億條資料、170個欄位、脫敏18個欄位、118G、25min
{3} Spark2.2.0,cdh5.16.2
{4} 均開啟kerberos和sentry
2. 演示環境
- 大集群:4個虛擬機,開啟kerberos、sentry
- 小集群:1個虛擬機
六、演示功能、看代碼 + 腳本
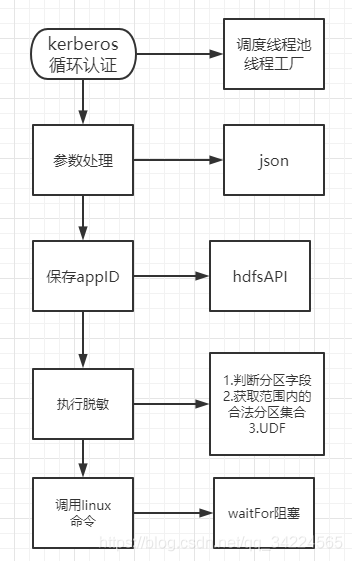


七、技術鏈路
1. Kerberos
https://blog.csdn.net/qq_34224565/article/details/104193770
- 作業模型
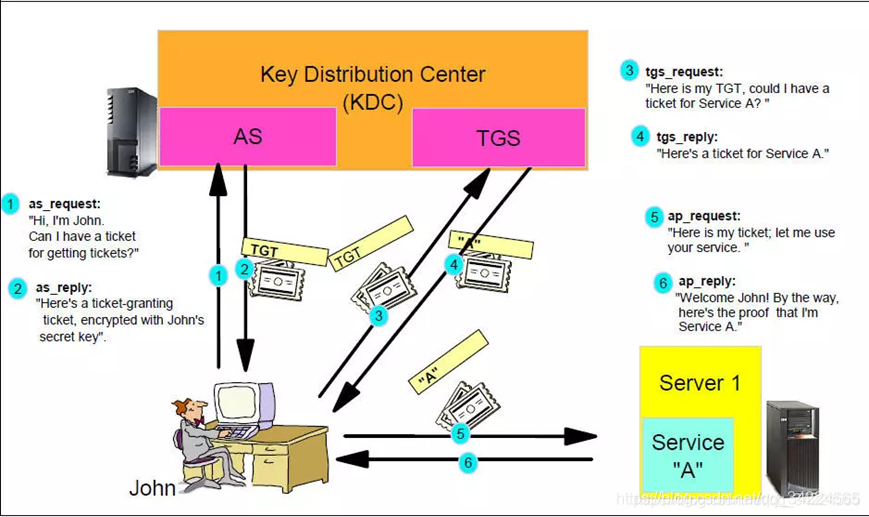
- Kerberos有認證有效期:過了有效期,需要重新認證
2. distcp
基于mapreduce的hdfs資料遷移工具
CDH官方檔案關于distcp的部分
https://blog.csdn.net/qq_34224565/article/details/106407978
支持大檔案的斷點續傳,通過設定-append引數
速度
權限
3. 脫敏演算法
{1} 可恢復脫敏使用加密演算法
- 加密型別分為兩種,對稱加密與非對稱加密,對稱加密就是加解密用相同的秘鑰,
- 面試官主要問非對稱加密,這種加密方式存在兩個密鑰,公鑰和私鑰,公鑰加密的資料只能由私鑰解密,私鑰加密的資料也只能由公鑰加密,
- 公鑰(正如其名,這是一個可以公開的密鑰值),
- 私鑰(對外保密), A發送資訊給B時,使用公共密鑰加密資訊, 一旦B收到A的加密資訊,B則使用私人密鑰破譯資訊密碼(被B的公鑰加密的資訊,只有B的唯一的私鑰可以解密,這樣,就在技術上保證了這封信只有B才能解讀——因為別人沒有B的私鑰),
- 使用私人密鑰加密的資訊只能使用公共密鑰解密(這一功能應用與數字簽名領域,我的私鑰加密的資料,只有我的公鑰可以解讀,具體內容參考數字簽名的資訊)反之亦然,以確保您的資訊安全,
- 常用的演算法
- 對稱:DES、3DES、TDEA、AES等
- 非對稱:RSA、Elgamal、背包演算法等
- 編碼base64
并不是加密,而是編碼,在某些場合也用來實作加密的功能
{2} 不可恢復脫敏使用散列演算法md5
- md5是一種散列演算法,不可逆,
并不是用來加密的,一開始是用于對比兩個食物是否為同一個,是一種簽名,每個人的簽名都應該是不一致的,因此需要對比兩個物件時,可以不對比物件本身,而對比他們的簽名(散列值)
長度固定,32個字符 - 它并不是絕對安全的,有一定的概率出現碰撞,也就是簽名重復,畢竟數是無限的,而md5值是有限的,但在一般場景應用很廣,比如密碼脫敏、檔案完整性的校驗,
在實際的專案開發中,用戶的密碼,一般會經過md5后存入資料庫,驗證的原理跟上文一致,樓上說的很對,一般存盤密碼是都會加salt后在計算md5值:md5(password + salt)或者多次md5:md5(md5(password)),這樣其實可保證密碼的安全性,
{3} 直接脫敏:回傳固定的3個星號即可
4. 程式中呼叫linux腳本
{1} 執行方式
- 同步
- 異步
{2} 命令
- distcp
- msck repair table $tableName
脫敏后的資料加載到hive表
遠程呼叫hive命令
5. 監控程式運行,獲取程式運行狀態
- 將applicationID上傳到hdfs
- 呼叫yarn的api
http://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/ResourceManagerRest.html
6. parquet
{1} 資料結構
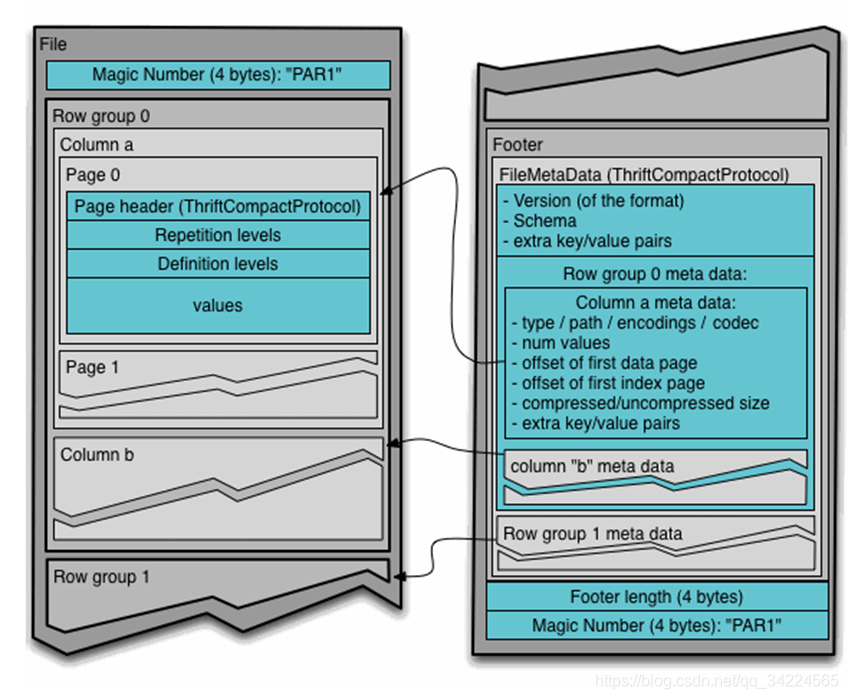
{2} 特點,為啥要選用它
- 支持嵌套資料結構
- 更高的壓縮比
parquet的gzip的壓縮比率最高,若不考慮備份可以達到27倍,spark parquet默認采用gzip壓縮, - 列式存盤
- 每一列中的資料型別相同,所以可以針對不同型別的列使用不同的編碼和壓縮方式,這樣可以增大壓縮效率,不壓縮、gzip、snappy分別能達到11/27/19的壓縮比
- 讀取資料的時候可以把映射(Project)下推,和謂詞下推,跳過不滿足條件的列,
- 由于每一列的資料型別相同,可以使用更加適合CPU pipeline的編碼方式,減小CPU的快取失效
- 自帶schema、包含如何決議的資訊
- 完美支持hive、impala、pig、spark,spark默認的存盤格式,parquet結合spark,可以完美實作磁區過濾
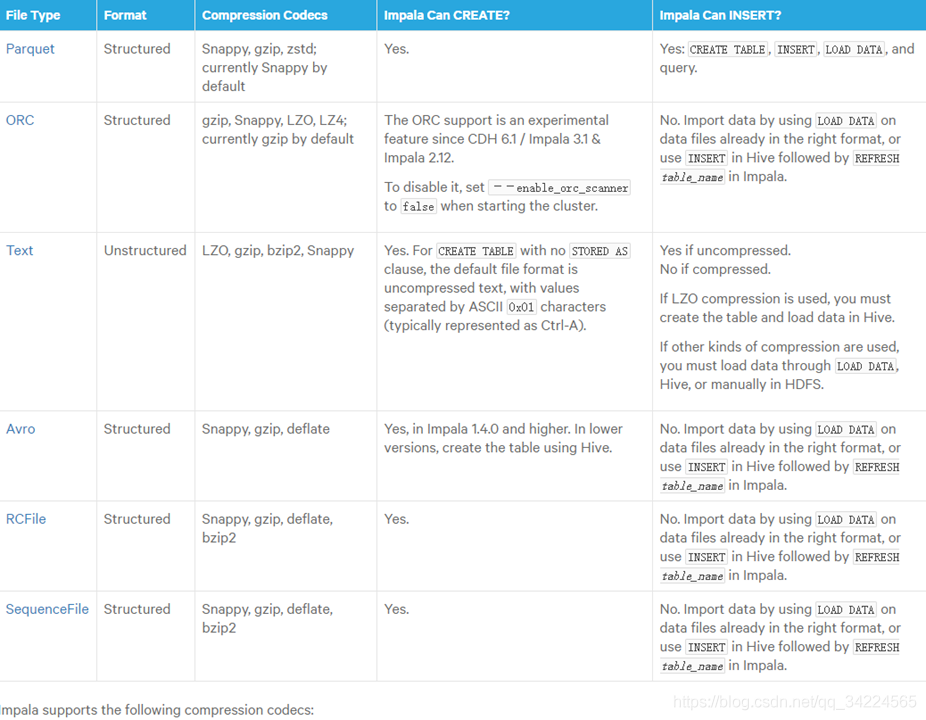
{3} 同其他存盤格式的區別
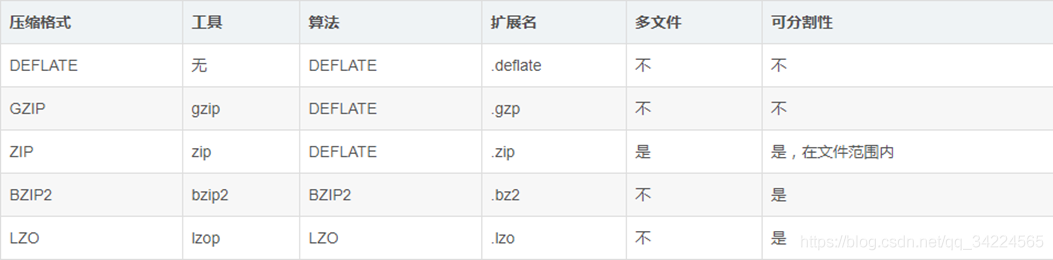
{4} 壓縮格式之間的區別
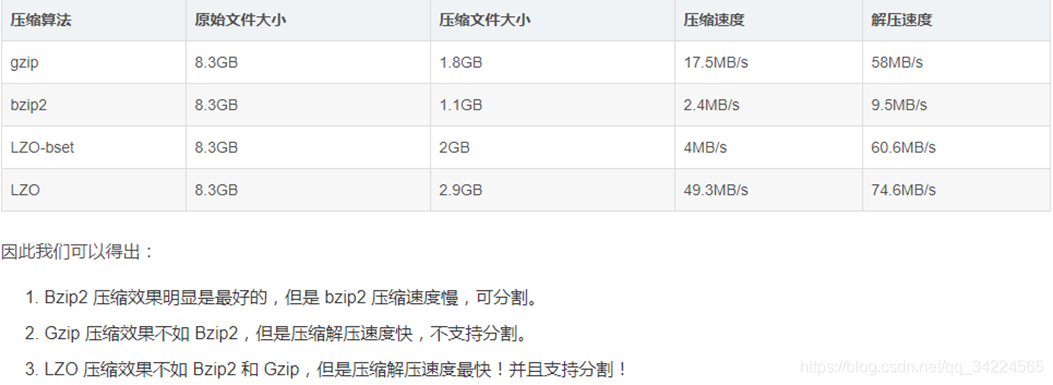
總結:知識(面試)點
實際面試中,這一個題目實際上就能占用半小時左右的時間,如果就某個問題深入一下,估計一個小時就沒了,所以大家要盡量把面試官帶到自己的節奏,讓他問你自己想讓他問的問題,
1. 業務
{1} 脫敏規則,敏感級別
{2} 配置、執行
2. 技術
{1} 硬體環境:cdh
- 節點數量、配置
- 2個集群
{2} distcp
- 斷點續傳
- namenode掛掉
- 速度
- 權限:kerberos互信
{3} kerberos
- 概念、作業模型
- 使用:有效期,執行緒工廠和調度池的使用
{4} 脫敏演算法
- 跟脫敏規則結合、場景
{5} 編程相關:
- spark UDF、
- 腳本呼叫、
- hive資料加載
{6} parquet
- 資料結構
- 特點
- 存盤格式、壓縮格式
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/230396.html
標籤:其他
上一篇:微信退款回呼解密req_info資訊資料踩坑記錄Illegal key size or default parameters