雙向鏈表簡介
單向鏈表只有一個方向,結點只有一個后繼指標 next 指向后面的結點,而雙向鏈表,顧名思義,它支持兩個方向,每個結點不止有一個后繼指標 next 指向后面的結點,還有一個前驅指標 prev 指向前面的結點,
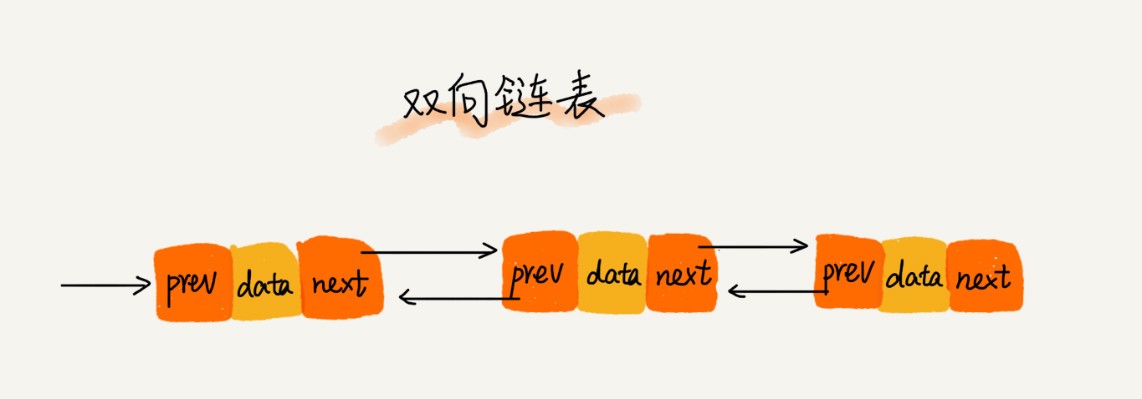
從上圖中可以看出來,雙向鏈表需要額外的兩個空間來存盤后繼結點和前驅結點的地址,所以,如果存盤同樣多的資料,雙向鏈表要比單鏈表占用更多的記憶體空間,雖然兩個指標比較浪費存盤空間,但可以支持雙向遍歷,這樣也帶來了雙向鏈表操作的靈活性,那相比單鏈表,雙向鏈表適合解決哪種問題呢?
從結構上來看,雙向鏈表可以支持 O(1) 時間復雜度的情況下找到前驅結點,正是這樣的特點,也使雙向鏈表在某些情況下的插入、洗掉等操作都要比單鏈表簡單、高效,
雙向鏈表的增刪改查操作
1. 插入操作
- 頭部插入:時間復雜度O(1)
- 尾部插入:時間復雜度O(1)
- 指定位置后面插入:時間復雜度O(1)
- 指定位置前面插入:時間復雜度O(1) ---注意和單向鏈表的區別
2. 洗掉操作
洗掉操作的時間復雜度和插入操作的時間復雜度類似,
- 洗掉頭部節點:時間復雜度O(1)
- 洗掉尾部節點:時間復雜度O(1)
- 洗掉值等于某個數的節點:時間復雜度O(n)
- 洗掉某個具體節點:O(1)
關于洗掉操作,這邊做下說明,
在實際的軟體開發中,從鏈表中洗掉一個資料無外乎這兩種情況:
-
洗掉結點中“值等于某個給定值”的結點;
-
洗掉給定指標指向的結點,
對于第一種情況,不管是單鏈表還是雙向鏈表,為了查找到值等于給定值的結點,都需要從頭結點開始一個一個依次遍歷對比,直到找到值等于給定值的結點,然后再通過我前面講的指標操作將其洗掉,
盡管單純的洗掉操作時間復雜度是 O(1),但遍歷查找的時間是主要的耗時點,對應的時間復雜度為 O(n),根據時間復雜度分析中的加法法則,洗掉值等于給定值的結點對應的鏈表操作的總時間復雜度為 O(n),
對于第二種情況,我們已經找到了要洗掉的結點,但是洗掉某個結點 q 需要知道其前驅結點,而單鏈表并不支持直接獲取前驅結點,所以,為了找到前驅結點,我們還是要從頭結點開始遍歷鏈表,直到 p->next=q,說明 p 是 q 的前驅結點,
但是對于雙向鏈表來說,這種情況就比較有優勢了,因為雙向鏈表中的結點已經保存了前驅結點的指標,不需要像單鏈表那樣遍歷,所以,針對第二種情況,單鏈表洗掉操作需要 O(n) 的時間復雜度,而雙向鏈表只需要在 O(1) 的時間復雜度內就搞定了!
除了插入、洗掉操作有優勢之外,對于一個有序鏈表,雙向鏈表的按值查詢的效率也要比單鏈表高一些,因為,我們可以記錄上次查找的位置 p,每次查詢時,根據要查找的值與 p 的大小關系,決定是往前還是往后查找,所以平均只需要查找一半的資料,
現在,你有沒有覺得雙向鏈表要比單鏈表更加高效呢?這就是為什么在實際的軟體開發中,雙向鏈表盡管比較費記憶體,但還是比單鏈表的應用更加廣泛的原因,如果你熟悉 Java 語言,你肯定用過 LinkedHashMap 這個容器,如果你深入研究 LinkedHashMap 的實作原理,就會發現其中就用到了雙向鏈表這種資料結構,
3. 更新操作
- 更新指定節點:時間復雜度O(1)
- 將鏈表中值等于某個具體值的節點更新:時間復雜度O(n)
4. 查詢操作
- 時間復雜度:O(n)
雙向鏈表的Java代碼實作
public class TwoWayLinkedList<E> {
public static void main(String[] args) {
TwoWayLinkedList<Integer> list = new TwoWayLinkedList<>();
//尾部插入,遍歷鏈表輸出
System.out.println("尾部插入[1-10]");
for (int i = 1; i <= 10; i++) {
list.addLast(Integer.valueOf(i));
}
list.printList();
//頭部插入,遍歷鏈表輸出
System.out.println("頭部插入[1-10]");
for (int i = 1; i <= 10; i++) {
list.addFirst(Integer.valueOf(i));
}
list.printList();
//在指定節點后面插入
System.out.println("在頭節點后面插入[100]");
list.addAfter(100, list.head);
list.printList();
System.out.println("在頭節點前面插入[100]");
list.addBefore(100, list.head);
list.printList();
System.out.println("在尾節點前面插入[100]");
list.addBefore(100, list.tail);
list.printList();
System.out.println("在尾節點后面插入[100]");
list.addAfter(100, list.tail);
list.printList();
System.out.println("------------洗掉方法測驗-----------");
System.out.println("洗掉頭節點");
list.removeFirst();
list.printList();
System.out.println("洗掉尾節點");
list.removeLast();
list.printList();
System.out.println("洗掉指定節點");
list.removeNode(list.head.next);
list.printList();
}
private Node head;
private Node tail;
public TwoWayLinkedList() {
}
public TwoWayLinkedList(E data) {
Node node = new Node<>(data, null,null);
head = node;
tail = node;
}
public void printList() {
Node p = head;
while (p != null && p.next != null) {
System.out.print(p.data + "-->");
p = p.next;
}
if (p != null) {
System.out.println(p.data);
}
}
public void addFirst(E data) {
Node newNode = new Node(data,null ,head);
if(head!=null){
head.pre = newNode;
}
head = newNode;
if (tail == null) {
tail = newNode;
}
}
public void addLast(E data) {
Node newNode = new Node(data, tail,null);
if (tail == null) {
head = newNode;
tail = newNode;
} else {
tail.next = newNode;
tail = newNode;
}
}
/**
* @param data
* @param node node節點必須在鏈表中
*/
public void addAfter(E data, Node node) {
if (node == null) {
return;
}
Node newNode = new Node(data, node,node.next);
if(node.next!=null){
node.next.pre = newNode;
}
node.next = newNode;
if (tail == node) {
tail = newNode;
}
}
public void addBefore(E data, Node node) {
if (node == null) {
return;
}
if(node==head){
addFirst(data);
}else {
Node newNode = new Node(data,node.pre,node);
node.pre.next = newNode;
node.pre = newNode;
}
}
public void removeFirst() {
if (head == null) {
return;
}
if (head == tail) {
head = null;
tail = null;
} else {
if(head.next!=null){
head.next.pre = null;
}
head = head.next;
}
}
public void removeLast() {
if (tail == null) {
return;
}
if (head == tail) {
head = null;
tail = null;
} else {
if(tail.pre!=null){
tail.pre.next = null;
Node p = tail.pre;
tail.pre = null;
tail = p;
}
}
}
public void removeNode(Node node) {
if (node == null) {
return;
}
if(node==head){
removeFirst();
}
if(node==tail){
removeLast();
}
node.pre.next = node.next;
node.next.pre = node.pre;
}
private static class Node<E> {
E data;
Node pre;
Node next;
public Node(E data, Node pre, Node next) {
this.data = https://www.cnblogs.com/54chensongxia/p/data;
this.pre = pre;
this.next = next;
}
}
}
雙向鏈表的JDK實作
JDK中的LinkedList就是一個雙向鏈表,我們可以直接拿來使用,或者做簡單的封裝,
package com.csx.algorithm.link;
import java.util.Collection;
import java.util.Collections;
import java.util.LinkedList;
import java.util.Set;
import java.util.function.Predicate;
public class SinglyLinkedList2<E> {
private LinkedList<E> list;
public SinglyLinkedList2() {
this.list = new LinkedList<>();
}
public SinglyLinkedList2(E data){
Set<E> singleton = Collections.singleton(data);
this.list = new LinkedList<>(singleton);
}
public SinglyLinkedList2(Collection<? extends E> c){
this.list = new LinkedList<>(c);
}
// ----------------------------------新增方法---------------------------------------
public void addFirst(E data){
list.addFirst(data);
}
public void addLast(E data){
list.addLast(data);
}
// 在鏈表末尾添加
public boolean add(E date){
return list.add(date);
}
public boolean addAll(Collection<? extends E> collection){
return list.addAll(collection);
}
public boolean addBefore(E data,E succ){
int i = list.indexOf(succ);
if(i<0){
return false;
}
list.add(i,data);
return true;
}
public boolean addAfter(E data,E succ){
int i = list.indexOf(succ);
if(i<0){
return false;
}
if((i+1)==list.size()){
list.addLast(data);
return true;
}else {
list.add(i+1,data);
return true;
}
}
// ---------------------------------- 洗掉方法---------------------------------------
// 洗掉方法,默認洗掉鏈表頭部元素
public E remove(){
return list.remove();
}
// 洗掉方法,洗掉鏈表第一個元素
public E removeFirst(){
return list.removeFirst();
}
// 洗掉方法,洗掉鏈表最后一個元素
public E removeLast(){
return list.removeLast();
}
// 洗掉鏈表中第一次出現的元素,成功洗掉回傳true
// 物件相等的標準是呼叫equals方法相等
public boolean remove(E data){
return list.remove(data);
}
// 邏輯和remove(E data)方法相同
public boolean removeFirstOccur(E data){
return list.removeFirstOccurrence(data);
}
// 因為LinkedList內部是雙向鏈表,所以時間復雜度和removeFirstOccur相同
public boolean removeLastOccur(E data){
return list.removeLastOccurrence(data);
}
// 批量洗掉方法
public boolean removeAll(Collection<?> collection){
return list.removeAll(collection);
}
// 按照條件洗掉
public boolean re(Predicate<? super E> filter){
return list.removeIf(filter);
}
// ----------------------------- 查詢方法----------------------------
// 查詢鏈表頭部元素
public E getFirst(){
return list.getFirst();
}
// 查詢鏈表尾部元素
public E getLast(){
return list.getLast();
}
// 查詢鏈表是否包含某個元素
// 支持null判斷
// 相等的標準是data.equals(item)
public boolean contains(E data){
return list.contains(data);
}
public boolean containsAll(Collection<?> var){
return list.containsAll(var);
}
}
還是做下提醒,LinkedList并不是執行緒安全的,如果需要保證執行緒安全,需要你自己做同步控制,
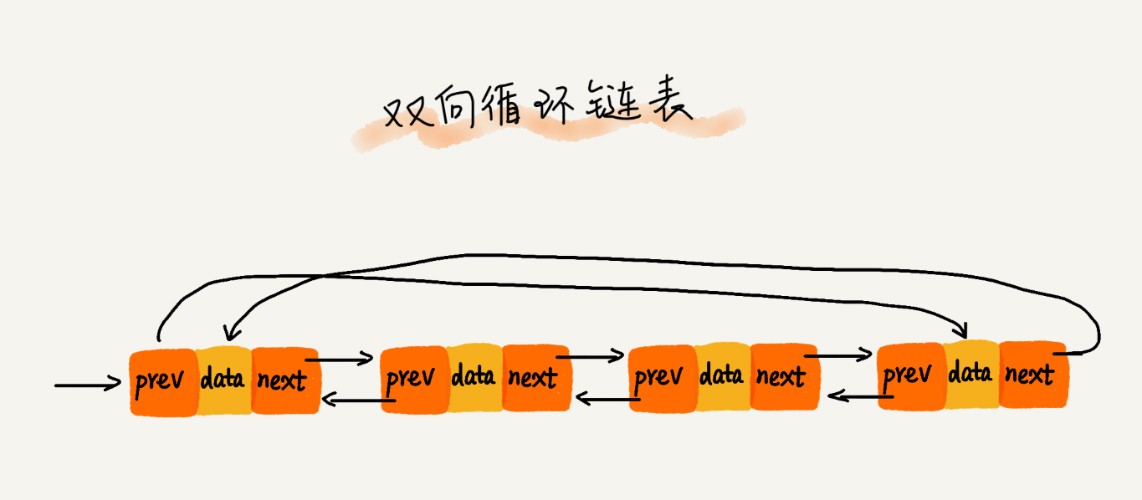
雙向回圈鏈表
其實就是將頭節點的前趨指標指向尾節點,將尾節點的后驅指標指向頭節點,
陣列和鏈表的比較
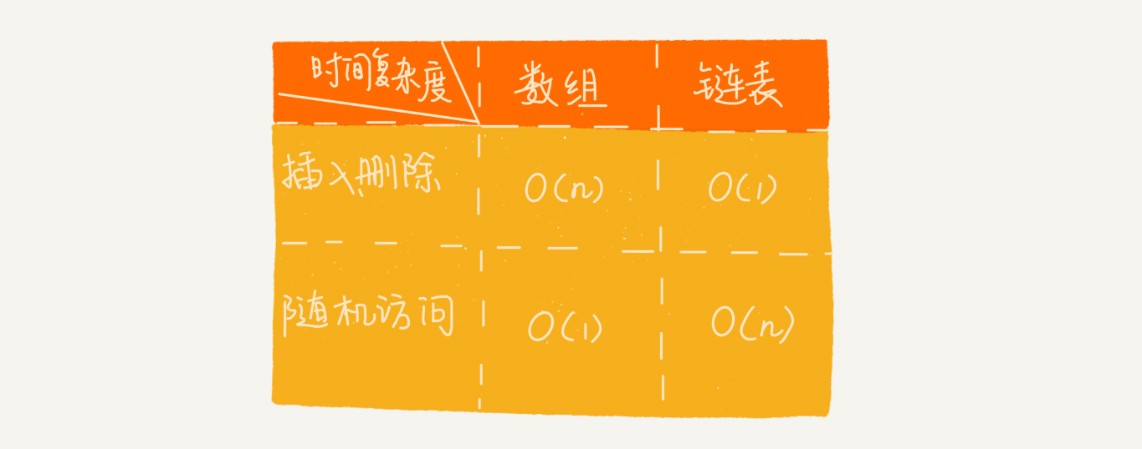
不過,陣列和鏈表的對比,并不能局限于時間復雜度,而且,在實際的軟體開發中,不能僅僅利用復雜度分析就決定使用哪個資料結構來存盤資料,
陣列簡單易用,在實作上使用的是連續的記憶體空間,可以借助 CPU 的快取機制,預讀陣列中的資料,所以訪問效率更高,而鏈表在記憶體中并不是連續存盤,所以對 CPU 快取不友好,沒辦法有效預讀,
陣列的缺點是大小固定,一經宣告就要占用整塊連續記憶體空間,如果宣告的陣列過大,系統可能沒有足夠的連續記憶體空間分配給它,導致“記憶體不足(out of memory)”,如果宣告的陣列過小,則可能出現不夠用的情況,這時只能再申請一個更大的記憶體空間,把原陣列拷貝進去,非常費時,鏈表本身沒有大小的限制,天然地支持動態擴容,我覺得這也是它與陣列最大的區別,
除此之外,如果你的代碼對記憶體的使用非常苛刻,那陣列就更適合你,因為鏈表中的每個結點都需要消耗額外的存盤空間去存盤一份指向下一個結點的指標,所以記憶體消耗會翻倍,而且,對鏈表進行頻繁的插入、洗掉操作,還會導致頻繁的記憶體申請和釋放,容易造成記憶體碎片,如果是 Java 語言,就有可能會導致頻繁的 GC(Garbage Collection,垃圾回收),所以,在我們實際的開發中,針對不同型別的專案,要根據具體情況,權衡究竟是選擇陣列還是鏈表,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/230536.html
標籤:其他