原理決議-過擬合與正則化
- 什么是過擬合
- 線性回歸中,正則化一般怎么實作?
- L0正則化決議
- L1正則化決議
- L1正則化為什么可以防止過擬合?
- 為什么L1正則化會使得引數稀疏,一部分引數的系數會變為0?
- L2正則化決議
- L2正則化為什么可以防止過擬合?
- 為什么L2正則化會使得引數接近0,而不會變為0?
- 總結
什么是過擬合
本來關于過擬合與正則化,我是不打算寫一篇文章的,今晚想了想,還是寫一篇吧,
一是直接寫帶正則化的線性回歸代碼,顯得有些突兀;
二是這個東西確實比較重要,我這里會盡量簡單的講清楚,
什么是過擬合?
我們都知道,目前我們在講的線性回歸,是監督學習里面的一種,通過對樣本的學習訓練,得出合適的引數,使得損失函式在這些樣本上最小,即在樣本上表現良好,但是我們之所以訓練模型,是為了讓它在未知樣本上,同樣表現良好(所以正常的我們做機器學習,會把樣本分成訓練集、測驗集,當模型在訓練集、測驗集表現穩定,效果也很好時,我們的這次機器學習訓練才算成功,這個模型才有泛化能力),
下面看一張很經典的圖:
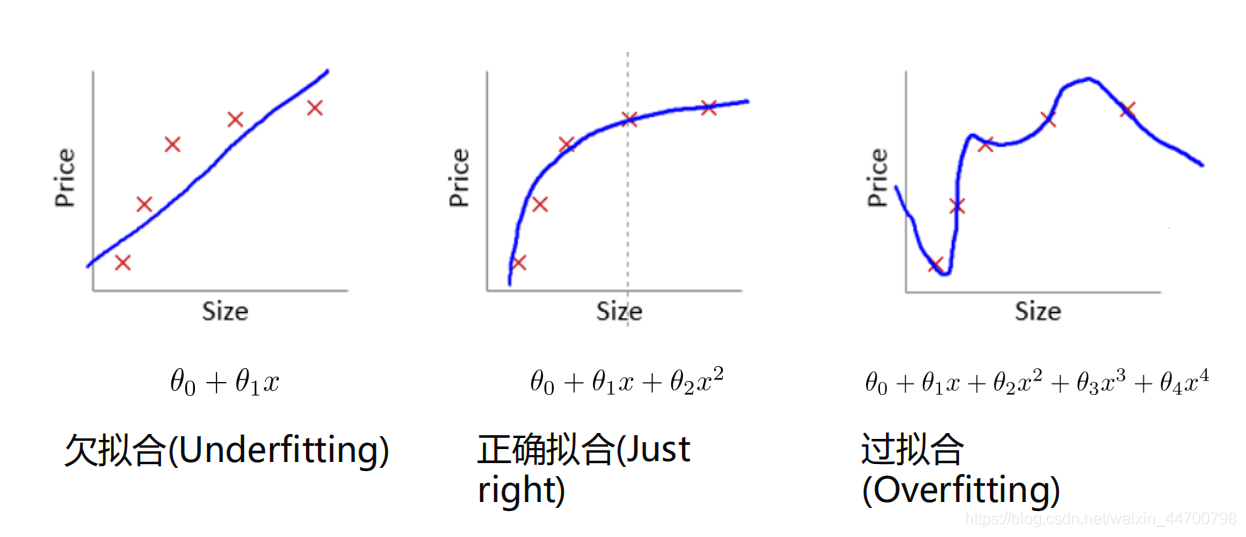
圖二就是正常擬合,符合資料的趨勢,
而圖三,雖然在訓練集上擬合得很好,但是出現未知資料時,比如Size很大時,根據目前擬合來看,可能得到的結果很小,與實際誤差會很大,
因此,我們僅僅使得損失函式在樣本上最小,是不夠的,我們來看監督機器學習的核心原理公式:(這個LaTeX 數學公式必須手打了,畢竟核心公式)
m i n 1 M ∑ i = 1 M L ( y i , f ( x i ) ) + λ J ( f ) min\frac{1}{M}\sum_{i=1}^{M} L(y_i,f(x_i)) + \lambda{J(f)} minM1?i=1∑M?L(yi?,f(xi?))+λJ(f)
以上才是監督演算法的損失函式的完整形式,
1
M
∑
i
=
1
M
L
(
y
i
,
f
(
x
i
)
)
\frac{1}{M}\sum_{i=1}^{M} L(y_i,f(x_i))
M1?i=1∑M?L(yi?,f(xi?))這個部分代表經驗誤差函式,即在樣本上訓練的損失,
而后面部分 λJ(f) 代表結構誤差函式,也稱為正則項,懲罰項,正則化引數的同時,最小化經驗誤差函式,最小化經驗誤差是為了極大程度的擬合訓練資料,正則化引數是為了防止過分的擬合訓練資料,因此對系數進行一定的懲罰,
OK,過擬合應該講得很清楚了,接下來講線性回歸三種形式的正則化,
線性回歸中,正則化一般怎么實作?
L0正則化決議
L0是指向量中非0的元素的個數,如果用L0來規則化一個引數矩陣W的話,就是希望W的大部分元素都是0,換句話說,讓引數W是稀疏的,
L0正則化的最優化問題是一個NP hard問題,L1正則化是L0正則化的最優凸近似,這里我們不展開L0的討論,大家知道有這么個東西就可以了,
L1正則化決議
帶L1正則化的線性回歸也叫Lasso回歸,其全稱是The Least Absolute Shrinkage and Selectionator operator,直譯過來就是最小絕對值收縮和選擇算子,表現形式為:
λ
∑
j
=
1
n
∣
∣
θ
j
∣
∣
\lambda{\sum_{j=1}^{n}}\vert\vert{\theta_j}\vert\vert
λj=1∑n?∣∣θj?∣∣
代表向量中各個元素絕對值之和,λ為正則化系數,
L1正則化為什么可以防止過擬合?
L1正則化之所以可以防止過擬合,是因為L1范數就是各個引數的絕對值相加得到的,引數值大小和模型復雜度是成正比的,因此如果擬合出一個復雜的模型(即出現了過擬合),其L1范數就大,這樣L1正則化懲罰就高,整體損失函式就沒有收斂,
所以最終不會選擇這些過擬合的引數,
同時,L1正則化會使得引數稀疏,一部分引數的系數會變為0,
問題:稀疏的引數代表模型越簡單嗎?
回答:是的,模型簡化,避免過擬合,因為一個模型中真正重要的引數可能并不多,如果考慮所有的引數起作用,
那么可以對訓練資料可以預測的很好,但是對測驗資料就很差了,引數變少也可以使整個模型獲得更好的可解釋性,
問題:引數值越小代表模型越簡單嗎?
回答:是的,為什么引數越小,說明模型越簡單呢,這是因為越復雜的模型,越是會嘗試對所有的樣本進行擬合,
甚至包括一些例外樣本點,這就容易造成在較小的區間里預測值產生較大的波動,這種較大的波動也反映了在這個區間里的導數很大,
而只有較大的引數值才能產生較大的導數,因此復雜的模型,其引數值會比較大,
為什么L1正則化會使得引數稀疏,一部分引數的系數會變為0?
1.從數學角度來看,我們手寫一下

2、從影像來看,
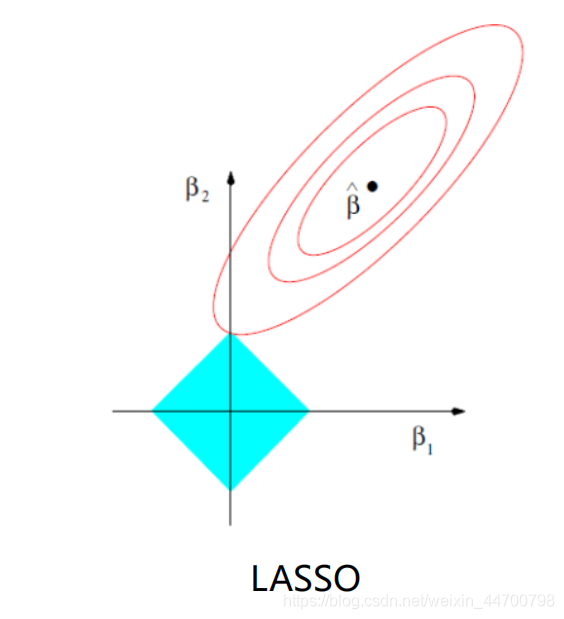
假設有2個引數,暫且用w1,w2來表示,y = |w1| + |w2| ,函式影像如上圖的四邊形,圓圈表示w1,w2取不同值時整個正則化項的值的等高線,很明顯很容易在頂點處相交,此時w1=0
后面會用實體來展示L1可以防止過擬合,也會使系數稀疏,
鏈接: 手寫演算法-python代碼實作Lasso回歸與實體展示
L2正則化決議
帶L2正則化的線性回歸也叫嶺回歸,Ridge回歸,也叫它“權值衰減weight decay”,表現形式為:
λ
∑
j
=
1
n
θ
j
2
\lambda{\sum_{j=1}^{n}}{\theta_j}^2
λj=1∑n?θj?2
代表向量中各個元素平方之和,λ為正則化系數,
L2正則化為什么可以防止過擬合?
L2正則化會使得引數接近于0,越小的引數說明模型越簡單,越簡單的模型越不容易產生過擬合現象,
同樣的,如果擬合出一個復雜的模型(即出現了過擬合),其L2范數就大,這樣L2正則化懲罰就高,整體損失函式就沒有收斂,
所以最終不會選擇這些過擬合的引數,
為什么L2正則化會使得引數接近0,而不會變為0?
1、從數學角度來看,

2、從影像來看,
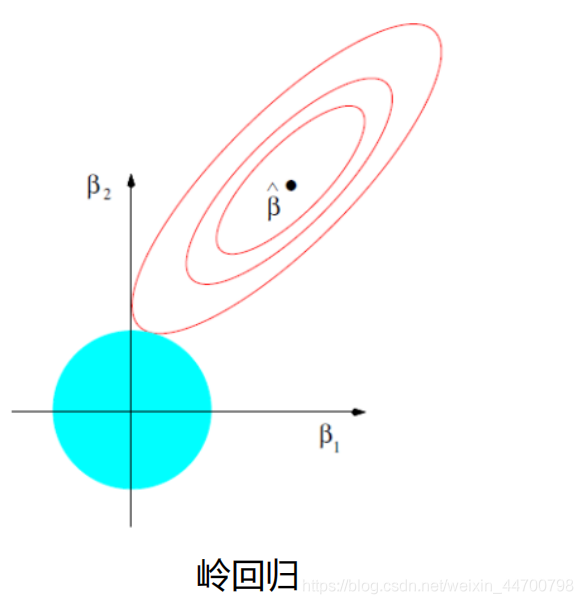
假設有2個引數,暫且用w1,w2來表示,y = w1^2 + w2^2 ,函式影像就是一個圓形,圓圈表示w1,w2取不同值時整個正則化項的值的等高線,很明顯不容易在頂點處相交,因此引數不會變為0,只會接近0,
后面會用實體來展示L2可以防止過擬合,也會使系數趨近于0,
鏈接: 實體展示-L2防止過擬合,也會使得系數趨近于0
總結
L1、L2應該講清楚了,其實還有一種正則化,彈性網Elastic Net,就是L1和L2結合在一起,L1、l2理解了,彈性網就能理解,介于兩者之間
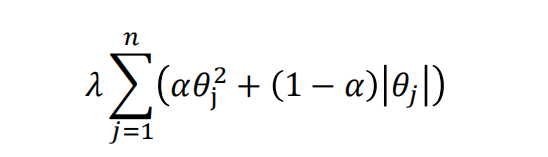
接下來會寫2種正則化回歸Python代碼,里面會用實體展示效果,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/230669.html
標籤:AI
上一篇:Hive資料倉庫實戰