近期因相關課程需要完成一個關于指令級并行(ILP)的匯報,我的主題為“以動態調度、多發射和推測來開發ILP”,是教材《計算機體系結構——量化研究方法》的第三章第九節內容,這里記錄下來,用于以后回顧,
筆記分為以下幾個部分:
- 復習
- 流水線
- 流水線冒險
- 動態調度
- 推測
- 多發射
- 將它們結合起來
復習
首先來介紹一下什么是流水線以及使用流水線所產生的一些問題
流水線
流水線是一種用來將多個指令重疊執行的技術,
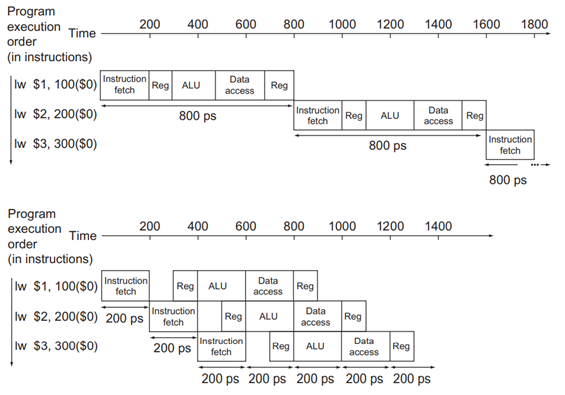
上圖是一個簡單的例子,不使用流水線技術時,處理器每800ps完成一條指令,為了提高執行指令的吞吐量,將指令的執行劃分為五個階段(取指、譯碼、執行、訪存、寫回)并添加相應的運算單元后,處理器就可以重疊執行指令了,如上圖中的第二張圖所示,修改后的流水線每200ps就可以執行完一條指令,提高了吞吐量,可以看到流水線只是提高了處理器執行指令的吞吐量,并沒有減小每天指令的執行周期,第二張圖中執行每條指令還是需要800ps,
這里插入簡單介紹一些經典五級流水線每個階段:
- 取指(IF),從指令存盤器中讀取指令
- 譯碼(ID),對指令進行決議,同時讀取暫存器
- 執行(EX),執行操作或者計算地址(對于載入/存盤指令)
- 訪存(MEM),從資料暫存器中讀取運算元(對于載入/存盤指令)
- 寫回(WB),將結果寫回暫存器
流水線冒險
但是指令之間會存在一些資料相關等問題,所以流水線技術也會有一些局限性,接下來介紹三種常見的流水線冒險
- 結構冒險,即硬體不支持多條指令在同一個時鐘周期中執行,
- 資料冒險,發生在由于一條指令必須等待另一條指令的完成而造成的流水線停頓的情況下,具體有兩個原因:
- 資料依賴,也叫做真資料相關,就是兩條指令間存在一個寫后讀(RAW)問題,也就是第一條指令要寫的資料,剛好要被第二條指令使用,而又因為第一條指令需要在流水線的第5個階段(寫回)才會真正將資料寫入暫存器中,而第二條指令在流水線第3個階段(執行)就需要這個資料了,所以產生了這種真資料相關,可以通過旁路(bypassing)技術和停頓(也稱為氣泡)方法來解決,
- 名稱依賴,也就是兩條指令對同一個暫存器進行讀后寫(WAR)或者寫后寫(WAW),和上面的寫后讀不一樣,讀后寫和寫后寫不會產生資料流動,也就是兩條指令之間其實不是真正的資料相關,只是因為要操作同一個暫存器而產生的依賴關系,可以通過暫存器重命名(register renaming)方法來解決,
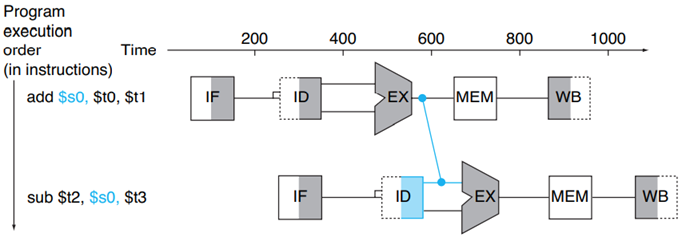
上圖是一個通過旁路技術來解決寫后讀問題的例子,第一條指令修改了暫存器s0的資料,第二條指令需要讀取s0的資料,旁路技術通過在得到s0資料的那個周期,直接將資料通過一個旁路送到需要這個資料的地方,可以看那條藍色的線路,正常情況下第一條指令需要在WB階段才能修改s0的值,但通過旁路,可以在EX階段獲得資料后直接送到第二條指令的譯碼(ID)階段,避免產生停頓,
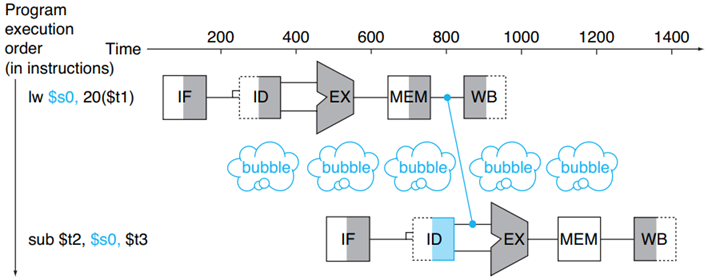
上圖是另外一個例子,由于這個例子中第一條指令是一個載入指令,必須要等到MEM階段才能得到資料,但是第二條指令在EX階段就要使用資料了,我們無法將未來的資料送給現在,所以這種情況下無法使用旁路技術,所以可以看見兩條指令間有一個停頓,即藍色的氣泡(bubble),
- 控制冒險,因為決策依賴于一條指令的結果,而這條指令正在執行中而發生,簡單來說就是因為條件判斷陳述句,在分支被決議前不能得知指令是否需要執行,會影響流水線的吞吐量,解決方法有停頓、分支預測(branch prediction)和延遲分支(delayed branch),
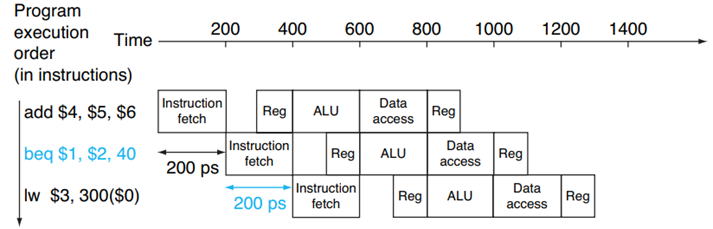
上圖是使用分支預測來解決分支冒險的例子,第二條指令需要一個判斷,而判斷的結果不能很快得到,為了不產生停頓,所以處理器預測這條指令不會跳轉,所以處理器繼續執行第三條指令而不是停頓等待結果,分支預測簡單的說就是為了不停頓,所以就預測一個結果,讓處理器先去執行那條預測的指令,分支預測技識訓有其他的細節,如果感興趣可以去閱讀教材,這里不是重點,
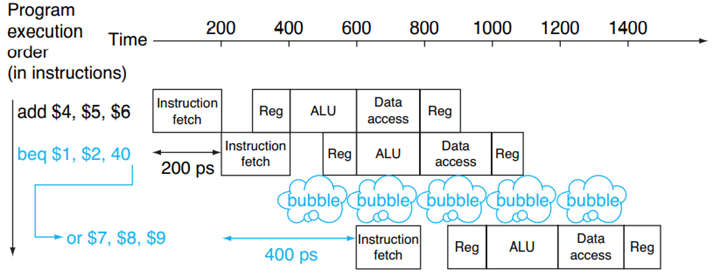
上圖中分支預測失敗,所以對停止執行之前預測得到的指令,即簡單的插入氣泡,然后去執行正確的指令,
關于延遲分支技術,簡單來說就是在分支決議的時候,去執行一條與分支無關的指令來避免流水線停頓,
動態調度
這里不會過多介紹動態調度,我的重點在推測和多發射,這里主要列舉動態調度的特點:
- 亂序執行
- 亂序完成
- 非精確例外,一種因為亂序完成而導致的問題,即在發生例外時,有一些本不應該被執行的指令已經被執行了,或一些本應該被執行的指令卻還未被執行,
- Tomasulo演算法,一種動態調度使用的演算法
動態調度的執行指令程序分為發射、執行、寫結果三個部分,
推測
推測技術主要是為了克服控制相關的限制,去開發更多的ILP,
思想:
- 同動態分支預測選擇要執行哪些指令
- 利用推測,可以在解決控制相關問題之前執行指令(能夠撤銷錯誤推測序列的影響)
- 進行動態調度,以應對基本模塊不同組合方式的調度
特點:
- 亂序執行
- 額外的指令提交
- 重排序緩沖區
- 順序提交
我們來看一下基于硬體推測的基本結構圖:
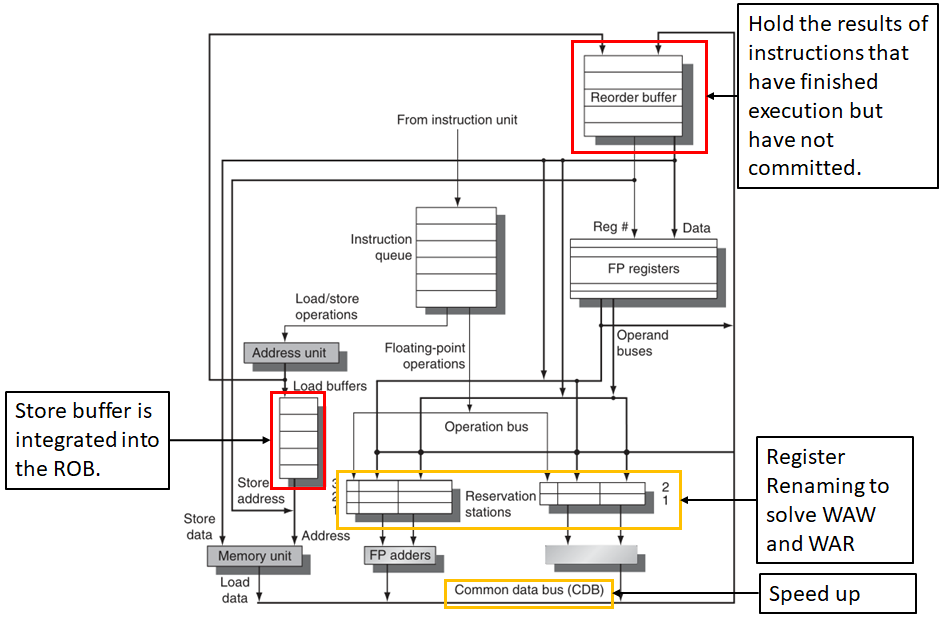
其中紅色框是在動態調度結構的基礎上進行改變的部分,黃色框是動態調度結構的重點部分,接下來進行解釋,
重排序緩沖區(reorder buffer,簡稱ROB):這是推測新加入的一個硬體,因為有了ROB,在推測的指令執行程序中的寫結果后又多加了一個指令提交,所以推測下的指令執行有四部分,分別是發射、執行、寫結果和提交,ROB中擴展了暫存器集,會在一定時間內保存指令的結果,這段時間從完成該指令的相關運算算起,到該指令提交完畢為止,暫存器和存盤器只有在指令提交之后才會被更新(即我們非常確定該指令會被執行),因此ROB是在指令執行完畢到指令提交這段時間內提供運算元,ROB類似于Tomasulo演算法中的存盤器緩沖區,所以將載入緩沖區(load buffers,第二個紅色框)旁邊的存盤器緩沖區集成到ROB中了,
保留站(reservation stations,簡稱RS):保留站提供了暫存器重命名功能,解決了WAR和WAW問題,它為等待發射的指令緩沖運算元,基本思想是:保留站在一個運算元可用時馬上提取并緩沖它,這樣就不再需要從暫存器中獲取該運算元,此外,等待執行的指令會指定保留站,為自己提供輸入,最后,在對暫存器連續進行寫入操作并且重疊執行時,只會實際使用最后一個操作更新暫存器,在發射指令時,會將待用運算元的暫存器說明符更名,改為保留站的名字,這就實作了暫存器重命名功能,
公共資料總線(common data bus,簡稱CDB):CDB將運算元從保留站中傳遞給所有需要它的功能單元,而不需要經過暫存器,加快了指令的執行,
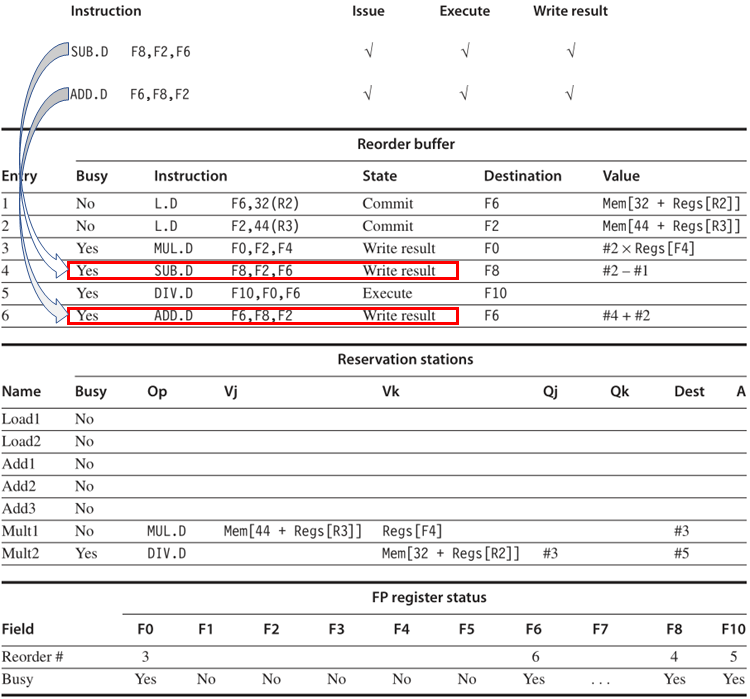
上圖是一些指令在執行程序中的某一個時刻的情況,其中最上面的兩條指令是在動態調度情況下的執行情況,它們分別指向在推測情況下的執行情況,可以看出,在動態調度下,因為亂序執行,這兩個指令已經執行結束并寫入暫存器了,而在推測下同樣的指令已經完成了執行,但由于這兩條指令之前的MUL.D指令還未完成指令提交,所以這兩條指令也不允許完成指令提交,
這一區別意味著具有ROB的處理器可以在維持精確例外的同時動態執行代碼,
多發射
多發射處理器的目標就是允許在一個時鐘周期中發射多條指令,分為以下三類:
- 靜態調度超標量處理器
- 動態調度超標量處理器
- VLIW(超長指令字)處理器
它們的區別在于,靜態調度采用循序(也就是順序)執行,動態調度采用亂序執行,它們在每個周期發射的指令數是可變的,而VLIW處理器每個時鐘周期發射固定數目的指令,

上圖是一個簡單的回圈例子,在不使用任何技術的情況下,執行一次回圈并得到一個結果需要9個周期,

上圖代碼使用了回圈展開和靜態調度技術,得到一個結果需要3.5個周期,
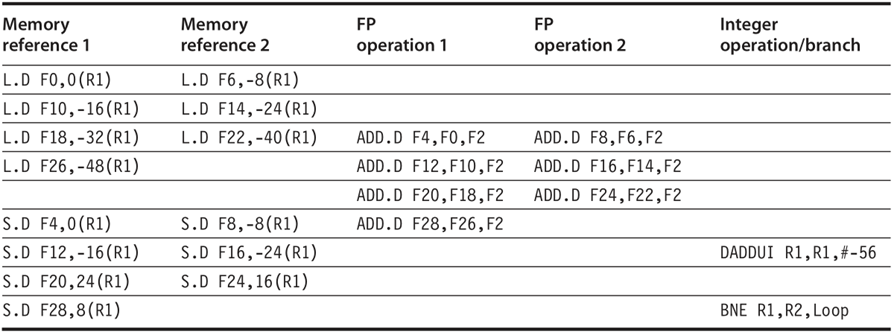
上圖代碼使用了回圈展開、靜態調度和VLIW技術,得到一個結果需要1.29個周期,
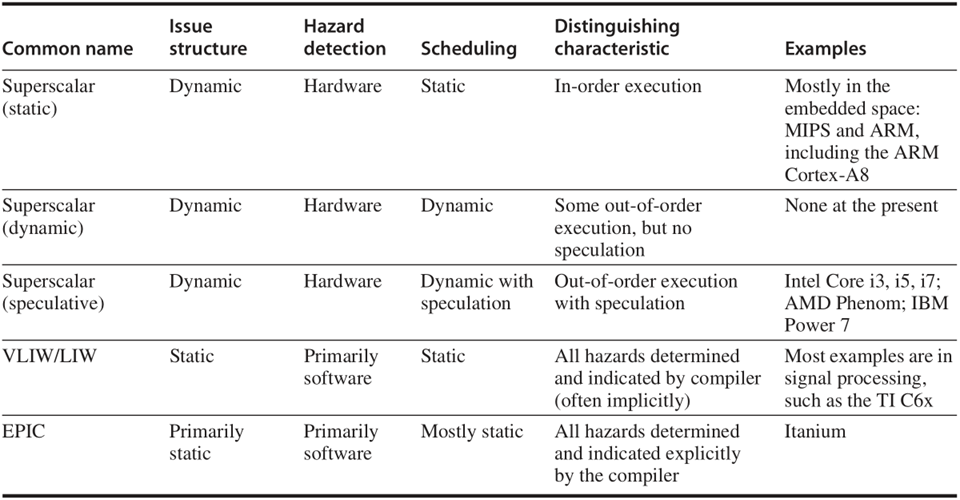
上圖對幾種不同處理器所使用的技術和各自的應用進行了總結,
將它們結合起來
最后我們將動態調度、推測和多發射技術結合起來,基本結構如下:
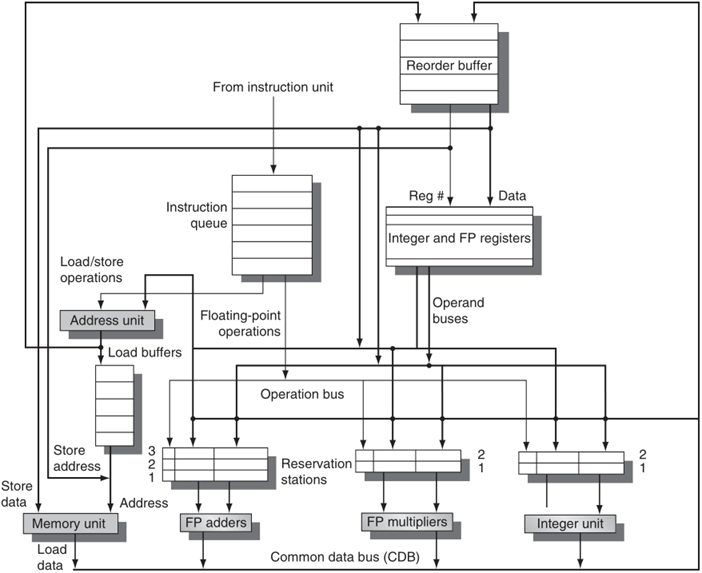
可以看到這個結構在推測的結構的基礎上增添了浮點乘法單元和整數單元,支持了具有分離整數、載入/存盤和浮點單元的多發射超標量流水線,
這篇文章大致介紹了以動態調度、推測和多發射技術來開發ILP的基本概念,需要讀者了解基本的五級流水線和動態調度技術,更多的細節可以參考我在文章開頭說到的教材,
參考:
- 《計算機體系結構——量化研究方法》
- 《計算機組成與設計——硬體/軟體介面》
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/230917.html
標籤:其他
上一篇:博客園寫作技巧-排版和seo優化