1.思考
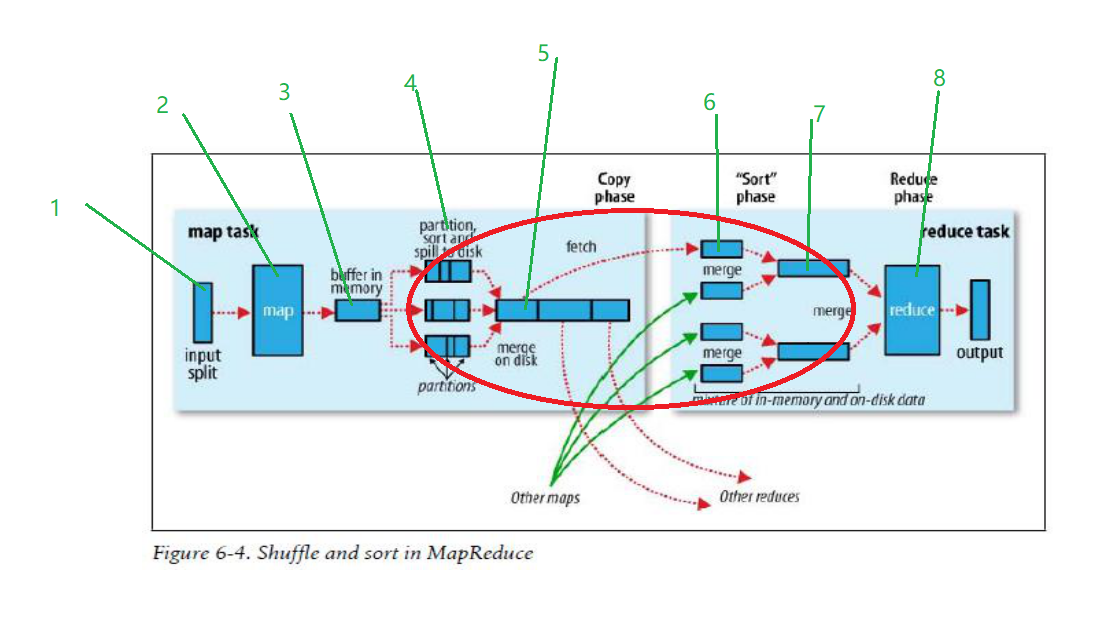
只要對hadoop中mapreduce的原理清楚的都熟知下面的整個流程運行原理,其中涉及到至少三次排序,分別是溢寫快速排序,溢寫歸并排序,reduce拉取歸并排序,而且排序是默認的,即天然排序的,那么為什么要這么做的,設計原因是什么,先給個結論,為了整體更穩定,輸出滿足多數需求,前者體現在不是采用hashShuffle而是sortShuffle ,后者體現在預計算,要知道排序后的資料,在后續資料使用時的會方便很多,比如體現索引的地方,如reduce拉取資料時候,
2.MapReduce原理分析
在分析設計原因之前,先理解一下整個程序,在map階段,根據預先定義的partition規則進行磁區,map首先將輸出寫到快取中,當快取內容達到閾值時,將結果spill到硬碟,每一次spill都會在硬碟產生一個spill檔案,因此一個map task可能會產生多個spill檔案,其中在每次spill的時候會對key進行排序,接下來進入shuffle階段,當map寫出最后一個輸出,需要在map端進行一次merge操作,按照partition和partition內的key進行歸并排序(合并+排序),此時每個partition內按照key值整體有序,然后開始第二次merge,這次是在reduce端,在此期間資料在記憶體和磁盤上都有,其實這個階段的merge并不是嚴格意義上的排序,也是跟前面類似的合并+排序,只是將多個整體有序的檔案merge成一個大的檔案,最終完成排序作業,分析完整個程序后,是不是覺得如果自己實作MapReduce框架的話,考慮用HashMap 輸出map內容即可,
2.1 MapTask運行機制詳解
整個流程圖如下:
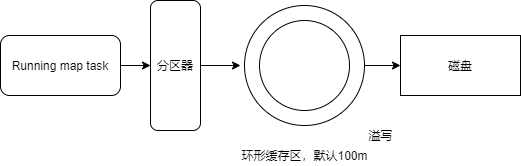
詳細步驟:
-
首先,讀取資料組件
InputFormat(默認TextInputFormat)會通過getSplits方法對輸?入?目錄中檔案進行邏輯切?片規劃得到splits,有多少個split就對應啟動多少個MapTask,split與block的對應關系默認是?對?, -
將輸入檔案切分為
splits之后,由RecordReader物件(默認LineRecordReader)進行讀取,以\n作為分隔符,讀取?行資料,回傳<key,value>,Key表示每?行行?首字符偏移值,value表示這?行文本內容, -
讀取
split回傳<key,value>,進?入?用戶自己繼承的Mapper類中,執行用戶重寫的map函式,RecordReader讀取?行這里呼叫一次, -
map邏輯完之后,將map的每條結果通過context.write進?行行collect資料收集,在collect中,會先對其進行磁區處理,默認使用HashPartitioner,MapReduce提供Partitioner介面,它的作用就是根據key或value及reduce的數量來決定當前的這對輸出資料最終應該交由哪個reduce task處理,默認對key hash后再以reduce task數量量取模,默認的取模方式只是為了平均reduce的處理能力,如果用戶自己對Partitioner有需求,可以訂制并設定到job上, -
接下來,會將資料寫入記憶體,記憶體中這?片區域叫做環形緩沖區,緩沖區的作用是批量量收集
map結果,減少磁盤IO的影響,我們的key/value對以及Partition的結果都會被寫?入緩沖區,當然寫?入之前,key與value值都會被序列列化成位元組陣列-
環形緩沖區其實是一個陣列,陣列中存放著
key、value的序列化資料和key、value的元資料資訊,包括partition、key的起始位置、value的起始位置以及value的長度,環形結構是一個抽象概念, -
緩沖區是有大小限制,默認是
100MB,當map task的輸出結果很多時,就可能會撐爆記憶體,所以需要在一定條件下將緩沖區中的資料臨時寫?入磁盤,然后重新利利?用這塊緩沖區,這個從記憶體往磁盤寫資料的程序被稱為Spill,中文可譯為溢寫,這個溢寫是由單獨執行緒來完成,不影響往緩沖區寫map結果的執行緒,溢寫執行緒啟動時不不應該阻?止map的結果輸出,所以整個緩沖區有個溢寫的?比例例spill.percent,這個?比例例默認是0.8,也就是當緩沖區的資料已經達到閾值(buffer size * spillpercent = 100MB * 0.8 = 80MB),溢寫執行緒啟動,鎖定這80MB的記憶體,執行溢寫程序Maptask的輸出結果還可以往剩下的20MB記憶體中寫,互不不影響、
-
-
當溢寫執行緒啟動后,需要對這
80MB空間內的key做排序(Sort),排序是MapReduce模型默認的?行行為!-
如果
job設定過Combiner,那么現在就是使?用Combiner的時候了了,將有相同key的key/value對的value加起來,減少溢寫到磁盤的資料量量,Combiner會優化MapReduce的中間結果,所以它在整個模型中會多次使用, -
那哪些場景才能使?用
Combiner呢?從這?里里分析,Combiner的輸出是Reducer的輸?,Combiner絕不不能改變最終的計算結果,Combiner只應該?用于那種Reduce的輸入key/value與輸出key/value型別完全一致,且不不影響最終結果的場景,?比如累加,最?大值等,Combiner的使?用一定得慎重如果用的好,它對job執?行行效率有幫助,反之會影響reduce的最終結果
-
-
合并溢寫檔案:每次溢寫會在磁盤上生成一個臨時檔案(寫之前判斷是否有
combiner),如果map的輸出結果真的很大,有多次這樣的溢寫發生,磁盤上相應的就會有多個臨時檔案存在,當整個資料處理理結束之后開始對磁盤中的臨時檔案進?行行merge合并,因為最終檔案只有一個,寫?磁盤,并且為這個檔案提供了一個索檔案,以記錄每個reduce對應資料的偏移量量,
2.2 ReduceTask運行機制詳解
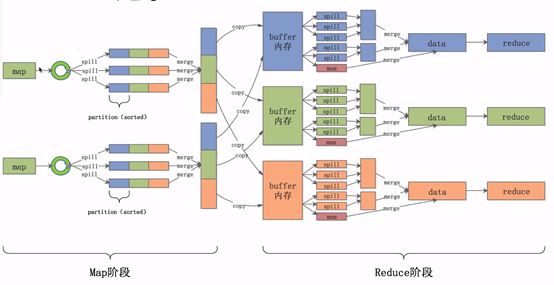
Reduce?大致分為copy、sort、reduce三個階段,重點在前兩個階段,copy階段包含?一個
eventFetcher來獲取已完成的map列串列,由Fetcher執行緒去copy資料,在此程序中會啟動兩個merge執行緒,分別為inMemoryMerger和onDiskMerger,分別將記憶體中的資料merge到磁盤和將磁盤中的資料進?merge,待資料copy完成之后,copy階段就完成了,開始進?行行sort階段,sort階段主要是執?finalMerge操作,純粹的sort階段,完成之后就是reduce階段,調?用?用戶定義的reduce函式進?處理,
詳細步驟
2.2.1 Copy階段
簡單地拉取資料,Reduce行程啟動一些資料copy執行緒(Fetcher),通過HTTP方式請求maptask獲取屬于自己的檔案,
2.2.2 Merge階段
Merge階段,這?里里的merge如map端的merge動作,只是陣列中存放的是不不同map端copy來的數值,Copy過來的資料會先放入記憶體緩沖區中,這?里里的緩沖區大小要?比map端的更更為靈活,merge有三種形式:記憶體到記憶體;記憶體到磁盤;磁盤到磁盤,默認情況下第?一種形式不不啟?用,當記憶體中的資料量量到達一定閾值,就啟動記憶體到磁盤的merge,與map 端類似,這也是溢寫的程序,這個程序中如果你設定有Combiner,也是會啟?用的,然后在磁盤中生成了了眾多的溢寫檔案,第二種merge方式?一直在運?行行,直到沒有map端的資料時才結束,然后啟動第三種磁盤到磁盤的merge方式生成最終的檔案,
2.2.3 合并排序
把分散的資料合并成一個?大的資料后,還會再對合并后的資料排序,對排序后的鍵值對調?用reduce方法,鍵相等的鍵值對調?用一次reduce方法,每次調?用會產生零個或者多個鍵值對,最后把這些輸出的鍵值對寫入到HDFS檔案中,
3.總結
從MapReduce的執行程序中,我們再來看為什么要排序,以及為什么在Shuffle時候采用SortShuffle,從設計上來看,MapTask和ReduceTask就是完全不同的跑在Yarn上的兩個行程,行程的互動方式是通過記憶體或者磁盤,為了兩個程式不耦合,更好地實作失敗重試等機制,那么就不能像Kafka一樣,生產者生產訊息和消費者消費訊息的時候,會有阻塞等問題,不能讓集群卡住,MapReduce跑的資料都是大批量的資料,所以要盡可能讓Map端處理完成的資料落盤但又要保證盡可能加快整個速度,所以在map結束時候,給reduce的是排序好的資料外加一份索引檔案,這樣雖然犧牲了一定的cpu,但是對落盤后的資料,讓Reduce來拉取時候可以盡可能地快,Map如何結束執行完,理論上可以在停機后,繼續跑ReduceTask,來完成整個任務同時為什么不是HashShuffe呢,是因為大資料情況下HashShuffle占用的記憶體很大,很可能會爆記憶體,導致集群計算不穩定,
吳邪,小三爺,混跡于后臺,大資料,人工智能領域的小菜鳥,
更多請關注

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/230927.html
標籤:其他
上一篇:演算法-雙指標問題解決思路