本篇以hive sql決議器來討論問題,spark sql 的處理方法類似,大家可自行測驗,
本篇不分析各種會造成資料傾斜的原因,資料傾斜形成的原因也只是簡單提及,本篇主要分析在sql中進行join操作時,會造成資料傾斜的常見兩大原因,以及解決方法,我認為這兩種情況,在作業中出現的幾率較高,所以單獨拿出來討論,
資料傾斜造成的原因(懂的可以跳過不看):
這個問題簡單來說,就是分布式處理中,每個節點處理的資料量差距較大,而導致單節點負擔過重,處理時間過長,而拖慢整個作業的執行時間,在hive中,常見的處理引擎有mapreduce(簡稱mr)和spark,mr中,有reduce階段,spark中有磁區,都可能存在資料傾斜,
在進行join操作時,有mapjoin和hashjoin兩個大類,mapjoin需要的是一個大表和一個小表進行join,小表存于記憶體中,對大表進行遍歷,不會產生資料傾斜,
如果是大表join大表,在記憶體中放不下,便會對兩張表join的欄位求hash值,然后將hash值相同的資料放入同一個reduce或者同一個spark磁區進行處理,這樣join條件相同的內容就能放在一起處理了,若得到的某個hash值比例過大,全部進入一個磁區,資料傾斜就形成了,
join時資料型別不一致導致的傾斜:
有這樣兩張表大表A 、B ,兩張表里都有pid欄位,但A表中的pid欄位為bigint型別,而B表中的pid欄位為string型別,
執行的sql為:
select pid from A join B on A.pid = B.pid;
正常情況下,這樣一條簡單的sql并不會產生資料傾斜,但如果在B表中,有大量的pid是超過bigint范圍的資料,如:‘10000000000000000000000000001’,‘10000000000000000000000000002’ … 這時就可能產生資料傾斜問題,
我們在上面講到過,2個大表進行join時,會將join的內容求hash值,這樣才能將join上的資料放在一起處理,但A表和B表中join的欄位,資料型別是不同的,這時hive會先進行型別轉換,再求hash值,那hive會將資料型別都轉成bigint還是string呢,這個還要看hive的版本,不同的版本處理方式也不同,在一些版本中,hive會將兩個欄位都轉換為bigint,這時,B表中那些超過范圍的資料,轉換就會出問題,
我們來看看在hive中不同版本的測驗結果:
2.x

3.x
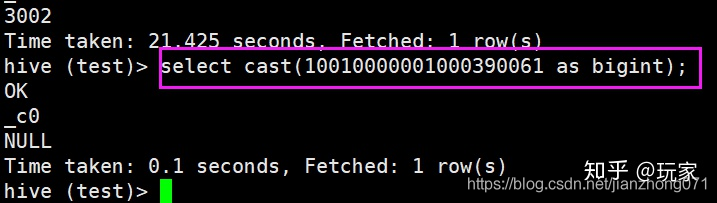
我們發現,不管是哪個版本,超過范圍的數值在轉換為bigint時,都會變成相同的結果,如果對這些資料求hash值,得出的結果也都是一樣的,這樣的資料會被分配到同一個磁區進行處理,資料傾斜就可能形成,
解決方法1:
手動將資料型別不一致的欄位轉換為string型別
select pid from A join B on cast(A.pid as string) = B.pid;
解決方法2:
參考下面的復雜join條件傾斜解決,
復雜join條件傾斜解決:
下面這個問題,我是轉載過來,然后將一些不是很明白的地方又做了說明**(用黑體字標出),**
轉自:Hive資料傾斜(大表join大表)
業務背景
trackinfo與pm_info兩張表均為GB級別,左關聯代碼塊如下:
from trackinfo a
left outer join pm_info b
on (a.ext_field7 = b.id)
使用以上代碼塊需要耗時1.5小時,
優化流程
第一次優化 (這就是上面說到的資料型別不一致的問題)
考慮到pm_info表的id是bigint型別,trackinfo表的ext_field7是string型別,其關聯時資料型別不一致,默認的hash操作會按bigint型的id進行分配,這樣會導致所有string型別的ext_field7集中到一個reduce里面,因此,改為如下:
from trackinfo a
left outer join pm_info b
on (cast(a.ext_field7 as bigint) = b.id)
改動為上面代碼后,效果仍然不理想,耗時為1.5小時,
第二次優化 (平時我們可能也就考慮到null值問題,對null進行過濾,進一步也可以像他這樣進行更加細致的過濾)
考慮到trackinfo表的ext_field7欄位缺失率很高(為空、欄位長度為零、欄位填充了非整數)情況,做進行左關聯時空欄位的關聯操作實際上沒有意義,因此,如果左表關聯欄位ext_field7為無效欄位,則不需要關聯,因此,改為如下:
from trackinfo a
left outer join pm_info b
on (a.ext_field7 is not null
and length(a.ext_field7) > 0
and a.ext_field7 rlike ‘1+$’
and a.ext_field7 = b.id)
上面代碼塊的作用是,如果左表關聯欄位ext_field7為無效欄位時(為空、欄位長度為零、欄位填充了非整數),不去關聯右表,由于空欄位左關聯以后取到的右表欄位仍然為null,所以不會影響結果,
改動為上面代碼后,效果仍然不理想,耗時為50分鐘,
第三次優化
想了很久,第二次優化效果效果不理想的原因,其實是在左關聯中,雖然設定了左表關聯欄位為空不去關聯右表,但是這樣做,左表中未關聯的記錄(ext_field7為空)將會全部聚集在一個reduce中進行處理,體現為reduce進度長時間處在99%,
這里可能很多人不太明白,我做個簡單的解釋:
為了保證能join上的資料放在一個磁區或一個reduce進行處理,不會簡單的只對欄位進行求hash值,而是會對join的條件求hash值,
比如:on (A.id+1) = (b.id+1) 就會對a.id+1 和 b.id+1 的結果求hash值
在第二次優化時,采用了復雜的join條件,將對trackinfo表的ext_field7的欄位過濾放在了前面,如果該欄位被過濾掉,都不用再判斷最后是否相等的邏輯,所以被過濾掉的欄位,回傳的hash值也是相同的,會進入同一個磁區,
換一種思路,解決辦法的突破點就在于如何把左表的未關聯記錄的key盡可能打散,因此可以這么做:若左表關聯欄位無效(為空、欄位長度為零、欄位填充了非整數),則在關聯前將左表關聯欄位設定為一個亂數,再去關聯右表,這么做的目的是即使是左表的未關聯記錄,它的key也分布得十分均勻
from trackinfo a
left outer join pm_info b
on (
case when (a.ext_field7 is not null
and length(a.ext_field7) > 0
and a.ext_field7 rlike ‘2+$’)
then
cast(a.ext_field7 as bigint)
else
cast(ceiling(rand() * -65535) as bigint)
end = b.id
)
第三次改動后,耗時從50分鐘降為了1分鐘32秒,效果顯著!
0-9 ??
0-9 ??
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/231115.html
標籤:其他
上一篇:美麗的陶溪川